In the figure mentioned in the previous section, we know that you can use the type and encoding attributes of redisObject objects. It can determine the main underlying data structures of Redis: SDS, QuickList, ZipList, HashTable, IntSet and ZskipList.
1, Simple dynamic string (SDS)
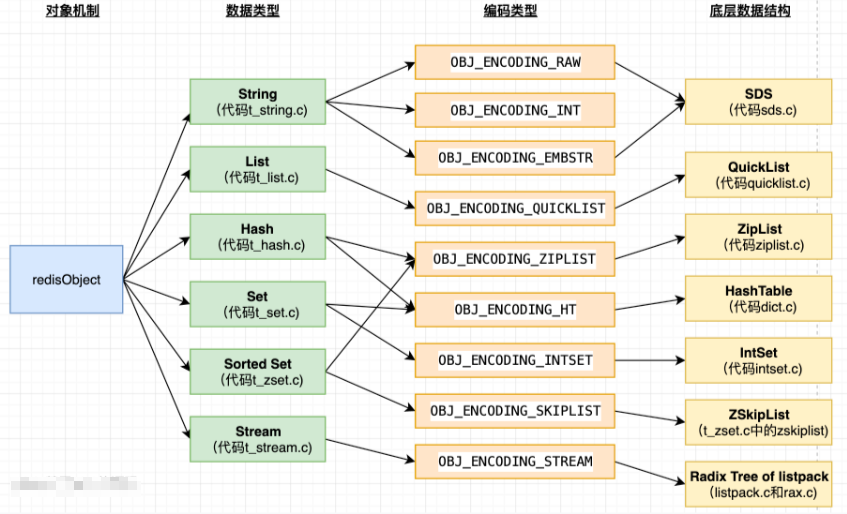
Let's first look at how the traditional C language stores strings: for example, a "Redis" string:
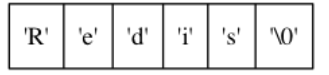
Why not use the traditional C language method, because we know that the array method has defects in obtaining the string length or capacity expansion: for example, the complexity of obtaining the length of an array is O(N), and the capacity expansion of the array is not very convenient. So I built an abstract data type called simple dynamic String.
- sdshdr: indicates the SDS type. There are five types. The number of each type represents unit
- alloc: space that has not been used. Here it is 0
- len: a string indicating that the SDS stores 5 units
- buf: an array of char type, used to hold characters
1.1 definition of SDS
SDS is located in Src / SDS H and Src / SDS In C, there are five structures (redis 6.0.6)
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
//The length of the saved string
uint8_t len; /* used */
//The number of bytes remaining except \ 0 at the head and end
uint8_t alloc; /* excluding the header and null terminator */
//Only 1 byte, the first five bits are unused, and the last three bits represent the type of header (sdshdr5)
unsigned char flags; /* 3 lsb of type, 5 unused bits */
//The element used to hold the string
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
1.2 difference between SDS and C string
-
SDS can obtain the string length with O(1) complexity: SDS has len attribute, while C string does not
-
SDS can prevent buffer overflow:
- Buffer overflow: for example, before the program performs the splicing operation, it needs to expand the space size of the underlying array through memory reallocation - forgetting will cause buffer overflow
- SDS records its own length, so corresponding space expansion and modification will be carried out during operation, so there will be no buffer overflow
-
SDS can reduce the number of memory reallocation when modifying strings:
- Space pre allocation: when expanding the space of a string, the expanded memory is more than what is actually needed, which can reduce the number of memory reallocations required for continuous string growth operations.
- Inert space release: when shortening a string, the program does not immediately use memory reallocation to recover the shortened excess bytes, but uses the alloc attribute to record these bytes for future use.
-
SDS can realize binary security:
- The characters in the C string must conform to the encoding format, and can not contain empty characters except the end, otherwise it will be mistaken for the end of the empty string. This will make the C string can only save text data, but not pictures, videos and other binary data
- The buf attribute of SDS can store a variety of binary data, and the length represented by len attribute can be used to judge whether the string ends
-
SDS compatible Part C string function:
- Following the convention that every string ends with an empty string, you can reuse the C language library < string h> Some functions in
2, Dictionary (Dict)
Redis dictionary uses hash table as the underlying implementation, and the code is located in src/dict.h
2.1 implementation of dictionary
2.1.1 structure definition of hash table
typedef struct dictht {
//Hash table array
dictEntry **table;
//Hash table size
unsigned long size;
//Hash table size mask used to calculate index values
unsigned long sizemask;
//Indicates the number of existing nodes in the hash table
unsigned long used;
} dictht;
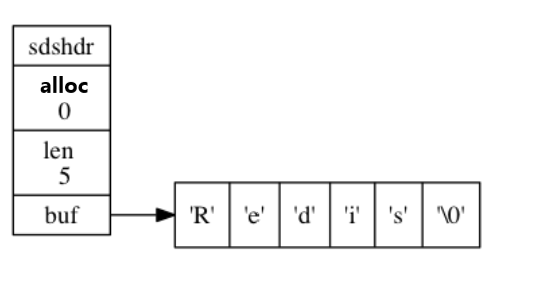
As shown in the figure, an empty hash table with a size of 4:
-
table attribute: it is an array. Each element of the array points to a pointer to the dictEntry structure. Each dictEntry structure holds a key value pair. Its structure is:
typedef struct dictEntry { //Key key void *key; //value, which can be pointer, int64, double, etc union { void *val; uint64_t u64; int64_t s64; double d; } v; //Pointer to the next dictEntry, zipper method to resolve hash conflict struct dictEntry *next; } dictEntry; -
Size attribute: the size of the record hash table
-
sizemask attribute: always equal to size - 1
-
used attribute: records the number of existing nodes (key value pairs) in the hash table
2.1.2 dictionary structure definition
The dictionary code in Redis is in src/dict.h
typedef struct dict {
//Pointer to dictType structure
dictType *type;
//Private data
void *privdata;
//Hashtable
dictht ht[2];
//Index. When rehash is not in progress, the value is 01
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
A dictionary without rehash
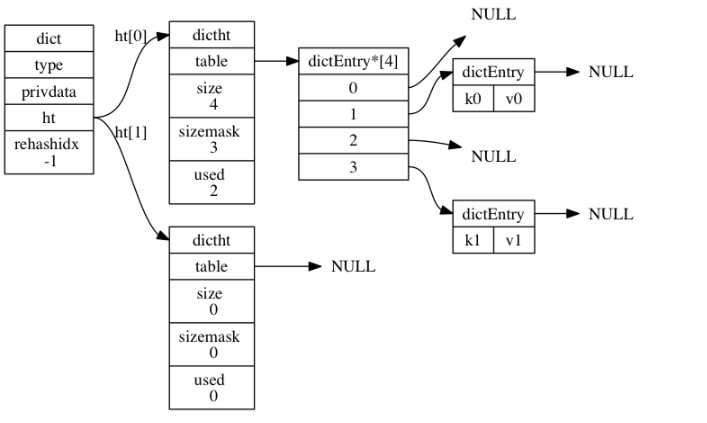
-
Type attribute: pointer to dictType structure. Each dictType structure holds a cluster of functions used to operate key value pairs of a specific type
typedef struct dictType { // Function to calculate hash value unsigned int (*hashFunction)(const void *key); // Copy key function void *(*keyDup)(void *privdata, const void *key); // Functions that copy values void *(*valDup)(void *privdata, const void *obj); // Function of comparison key int (*keyCompare)(void *privdata, const void *key1, const void *key2); // Function to destroy key void (*keyDestructor)(void *privdata, void *key); // Function to destroy values void (*valDestructor)(void *privdata, void *obj); } dictType; -
privdata attribute: holds the optional parameters that need to be passed to those type specific functions
-
ht attribute: an array containing two items. Each item in the array is a dictht hash table. Generally, the dictionary only uses the ht[0] hash table, and the ht[1] hash table is used when rehash the ht[0] hash table.
-
rehashidx attribute: if rehash is not performed, its value is - 1.
2.2 Hash conflict
2.2.1 hash algorithm
The method of calculating hash value and index value in Redis is as follows:
# Use the hash function set in the dictionary to calculate the hash value of the key hash = dict->type->hashFunction(key); # Use the sizemask attribute and hash value of the hash table to calculate the index value (h[x] refers to ht[0] or ht[1]) index = hash & dict->ht[x].sizemask;
The hashFunction(key) here uses MurmurHash algorithm to calculate the hash value of the key. The advantage of this algorithm is that even if the input key is regular, the algorithm can still give a good random distribution. The calculation speed of the algorithm is also very fast.
2.2.2 hash conflict
As mentioned earlier, Redis uses the zipper method to solve hash conflicts. Each hash table node has a next pointer. Multiple hash table nodes can use the next pointer to form a one-way linked list to solve the problem of hash key conflicts. The code is in src/dict.c/dictAddRaw
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 1. Execute rehash
//If the index is equal to - 1, the same key already exists in the dictionary
if ((index = _dictKeyIndex(d, key)) == -1) // 2. Index location
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // 3. Select the hash table according to whether to rehash
entry = zmalloc(sizeof(*entry)); // 4. Allocate memory space and perform insertion
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
dictSetKey(d, entry, key); // 5. Set key
return entry;
}
The specific code of the hash algorithm is in the function_ In dictKeyIndex()
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
if (_dictExpandIfNeeded(d) == DICT_ERR) // 1. rehash judgment
return -1;
h = dictHashKey(d, key); // 2. The hash function calculates the hash value
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask; // 3. Hash algorithm calculates index value
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) // 4. Find whether the key already exists
return -1;
he = he->next;
}
if (!dictIsRehashing(d)) break; // 5. rehash judgment
}
return idx;
}
2.2.3 rehash
Like the underlying data structure of HashMap in Java, the key value pairs stored in the hash table will increase or decrease. In Redis, the expansion and contraction of the table are completed by executing rehash. That is to maintain the load factor in the hash table in a reasonable range. The load factor here is: load_factor = ht[0].used / ht[0].size
-
Extension: 1 When the server is executing the BGSAVE or BGREWRITEAOF command and the load factor of the hash table is greater than or equal to 5; 2. The server does not execute the BGSAVE or BGREWRITEAOF command at present, and when the load factor of the hash table is greater than or equal to 1, allocate space for ht[1], and the size is greater than twice the power of the original ht[0]
-
When moving from the value of ht[0] to ht[1], it is necessary to recalculate the hash value and index of the elements in the original ht[0]; Insert into ht[1], insert one and delete one
-
After all the elements in ht[0] are migrated, release ht[0], set the new ht[1] to ht[0], and call dict.c/_dictExpandIfNeeded function:
static int _dictExpandIfNeeded(dict *d) { if (dictIsRehashing(d)) return DICT_OK; if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); // If the size is 0, you need to set the initial hash table size to 4 if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) // If the load factor exceeds 5, execute dictExpand { return dictExpand(d, d->ht[0].used*2); } return DICT_OK; }
-
-
Shrink: when the load factor of the hash table is less than 0.1, the shrink operation will be performed on the hash table, and ht[1] will also be allocated, with a size equal to max (HT [0]. Used, dict_ht_internal_size). It is also necessary to migrate elements. The specific operations and extensions are the same
2.2.4 progressive rehash
To expand or shrink the hash table, you need to rehash the key value pairs in ht[0] into ht[1]. Because when the number of key value pairs is very large, if a large number of rehash actions are completed at one time and centrally, it is likely to lead to server downtime. Therefore, a progressive rehash is required to complete the task. The steps of progressive rehash are as follows:
-
Allocate space for ht[1], and set the rehashidx variable in the dictionary to 0. This code is implemented in dict.c/dictExpand
int dictExpand(dict *d, unsigned long size) { dictht n; unsigned long realsize = _dictNextPower(size); // Find the power of the smallest 2 greater than size if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR; if (realsize == d->ht[0].size) return DICT_ERR; n.size = realsize; // realsize space allocated to ht[1] n.sizemask = realsize-1; n.table = zcalloc(realsize*sizeof(dictEntry*)); n.used = 0; if (d->ht[0].table == NULL) { // In initialization phase d->ht[0] = n; return DICT_OK; } d->ht[1] = n; d->rehashidx = 0; // rehashidx is set to 0 to start progressive rehash return DICT_OK; } -
During the CRUD operation of the dictionary in rehash, in addition to these specified operations. All key value pairs of ht[0] will also be rehash into ht[1]. After rehash is completed, the value of rehashidx attribute will be increased by 1.
- The CRUD operation during rehash will be performed in two hash tables, such as searching in two tables respectively and adding elements in ht[1]
-
When all key value pairs in ht[0] are rehash to ht[1], set the rehashidx attribute value to - 1, and the rehash operation is completed.
3, Compressed list (ZipList)
As can be seen from the figure at the beginning of this article, ZipList is the underlying implementation principle of list key and hash key. It is developed to save memory. Generally, when a list contains only a few elements or the elements in it are small integers and short strings, Redis will use ZipList as the underlying implementation of the list key.
3.1 composition of compressed list
Compressed list is a sequential data structure composed of a series of specially encoded continuous memory blocks. A compressed list can contain multiple nodes, and each node can store the corresponding data type (byte array or an integer value). As shown below

| attribute | type | length | purpose |
|---|---|---|---|
| zlbytes | uint32_t | 4 bytes | Record the memory bytes occupied by the whole compressed list: used when reallocating memory for the compressed list or calculating the location of zlend. |
| zltail | uint32_t | 4 bytes | Record the number of bytes from the end node of the compressed list to the starting address of the compressed list: through this offset, the program can determine the address of the end node without traversing the whole compressed list. |
| zllen | uint16_t | 2 bytes | The number of nodes contained in the compressed list is recorded: when the value of this attribute is less than UINT16_MAX (65535), the value of this attribute is the number of nodes contained in the compressed list; When this value is equal to UINT16_MAX, the real number of nodes needs to traverse the whole compressed list to calculate. |
| entryX | List node | Uncertain | The length of each node contained in the compressed list is determined by the content saved by the node. |
| zlend | uint8_t | 1 byte | The special value 0xFF (255 decimal) marks the end of the compressed list |
The figure below shows an example of a compressed list:
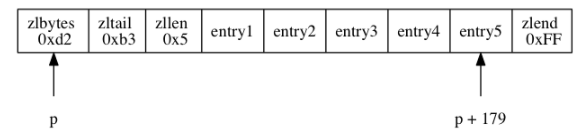
- The zlbytes attribute value is 0xd2 (decimal 210), indicating that the total length of the compressed list is 210 bytes
- The zltail attribute value is 0xb3 (decimal 179), indicating that the offset from the start pointer p to the end pointer is 179
- The value of zilen attribute is 0x5 (decimal 5), indicating that the compressed list contains five entry nodes
- entry1~entry5: indicates each list
- The zlend attribute value represents the end of the compressed list
3.2 composition of compressed list nodes
Each compressed list node can hold a byte array or an integer value. Its nodes are composed of previous_entry_length, encoding and content are three attributes. As shown below:

-
previous_entry_length attribute: records the length of the previous byte in the compressed list in bytes.
- If the length of the previous byte is less than 254 bytes, then previous_ entry_ The value of length is 1 byte
- If the length of the previous byte is greater than or equal to 254 bytes, then previous_ entry_ The value of length is 5 bytes: the first byte of this attribute is set to 254, and the next four bytes are used to store the remaining length of more than 1 byte.
-
encoding attribute: records the type and length of data saved by the content attribute of the node
-
When 1 byte, 2 bytes or 5 bytes, the highest value of 00, 01 or 10 is the byte array code: this code indicates that the content attribute of the node stores the byte array.
code Coding length Value saved by content attribute 00bbbbbb 1 byte A byte array with a length of 63 bytes or less. 01bbbbbb xxxxxxxx 2 bytes Byte array with length less than or equal to 16383 bytes. 10______ aaaaaaaa bbbbbbbb cccccccc dddddddd 5 bytes Byte array with length less than or equal to 4294967295. -
1 byte, integer encoding with the highest bit of the value starting with 11: the type and length of the integer value are recorded by the other bits after the highest two bits are removed from the encoding.
code Coding length Value saved by content attribute 11000000 1 byte int16_ Integer of type T. 11010000 1 byte int32_ Integer of type T. 11100000 1 byte int64_ Integer of type T. 11110000 1 byte 24 bit signed integer. 11111110 1 byte 8-bit signed integer. 1111xxxx 1 byte The node using this code has no corresponding content attribute. Because the four bits of xxxx of the code itself have saved a value between 0 and 12, it does not need the content attribute.
-
-
content attribute: it is responsible for saving the value of the node. The node value can be a byte array or an integer. The type and length of the value are determined by the encoding attribute of the node.
Take an example of saving integer nodes:

- encoding starts with 11, indicating that the stored is an integer type
- content indicates that the value of the saved node is 10086
Why can ZipList save memory?
- Compared with ordinary list s, the encoding attribute is added to selectively store byte and integer types
- With previous_entry_length attribute, which can locate the exact position of the next element when traversing the element, reducing the time complexity of the search
4, Skip table (ZSkipList)
Jump table is an ordered data structure, which is used as an ordered list (Zset). Moreover, compared with the balanced tree, it is more elegant and can be completed in logarithmic expected time in CRUD and other operations.
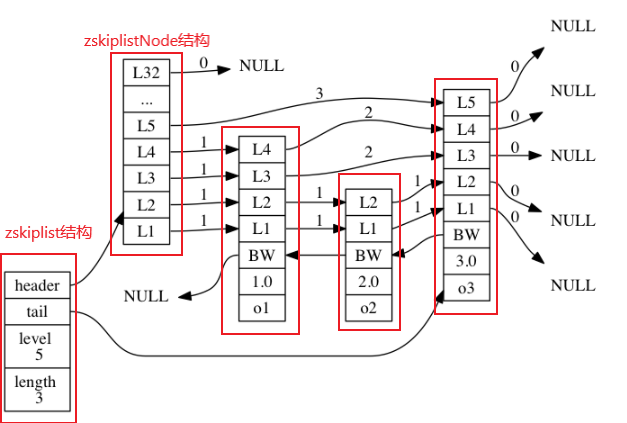
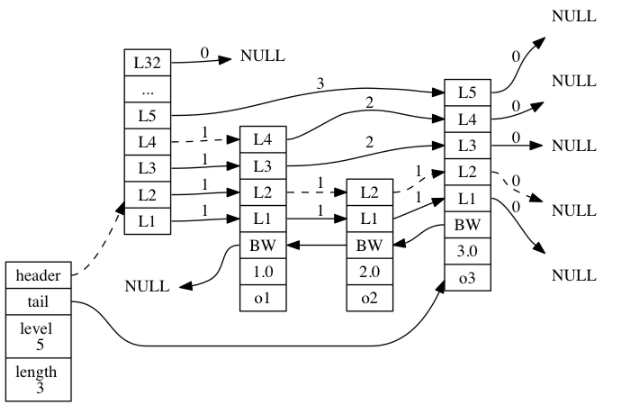
As shown in the above figure, it is a jump table instance. The leftmost is the zskiplist structure, which contains the following attributes:
- Header attribute: points to the header node of the jump table
- tail attribute: refers to the footer node of the jump table
- level attribute: records the number of layers of the node with the largest number of layers in the jump table
- Length attribute: records the length of the jump table, that is, the number of nodes currently contained in the jump table
The four on the right are the zskiplistNode structure, which contains the following attributes:
- level attribute: mark each layer of the node with words such as L1, L2, L3, etc
- Backward attribute: the backward pointer of the node marked with BW in the node. It refers to the previous node of the current node
- score attribute: scores such as 1.0 and 2.0 saved in the node
- obj attribute: o1, o2, etc. in the node are the member objects saved by the node
4.1 jump table structure definition
4.1.1 structure of jump table
As shown in the figure at the beginning, the zskiplist structure code is in redis In H / zskiplist, it is defined as follows:
typedef struct zskiplist {
//Header node and footer node
structz skiplistNode *header, *tail;
//Number of nodes in the table
unsigned long length;
//The number of layers of the node with the largest number of layers in the table
int level;
} zskiplist;
4.1.2 structure of jump table nodes
The zskiplistNode structure is used to represent the jump table node. The code is in redis H / zskiplistNode.
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
//Object property, pointing to a string object
sds ele;
//Score
double score;
//Backward pointer
struct zskiplistNode *backward;
//Layer level
struct zskiplistLevel {
//Forward pointer
struct zskiplistNode *forward;
//span
unsigned int span;
} level[];
} zskiplistNode;
-
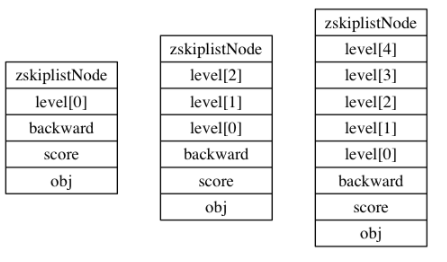
Level attribute: the level layer can contain multiple elements. The more layers, the faster you can access other nodes. The program randomly generates a value between 1 and 32 through the power law (the greater the number, the smaller the probability of occurrence). The size of the level array is used as the floor height: the following figure shows the nodes with different floor heights
-
Forward and backward pointers (* forward and * backforward): used to access the path traversing all nodes in the jump table
-
Span attribute: the span of a layer is used to record the distance between two nodes: as shown in the figure above, the number on the arrow indicates the distance between nodes
-
Score and members (score, SDS, ELE):
- The score is a double type floating-point number, and all nodes in the jump table are sorted from small to large according to the score
- Member object (such as o1, o2, etc.), which is a pointer to a string object that holds an SDS value
- In the same jump table, the member objects saved by each node must be unique, and the scores can be the same. Small member objects will be in the front (header) and large member objects will be in the back (footer). In this figure, the same integer value 10086.0 is saved for o1, o2 and o3 nodes. However, the sorting of member objects is o1 - > o2 - > o3
5, Integer set (IntSet)
When there are only integer value elements in a set and the number of elements in the set is small, Redis will use the integer set as the underlying implementation of the set key
5.1 definition of integer set structure
Intset can be saved as int16_t,int32_t or Int64_ The integer value of T, and ensure that there are no duplicate elements in the set. Its structure code is in intset In H / intset, take 32 as an example:
typedef struct intset {
//Coding mode
uint32_t encoding;
//Number of elements contained in the collection
uint32_t length;
//Save an array of elements
int8_t contents[];
} intset;
Take a specific set of integers as an example:
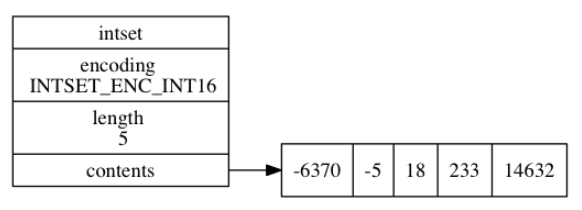
- The encoding attribute value is INTSET_ENC_INT16: indicates that the contents array is a 16 bit array
- The value of the length attribute is 5, indicating that the contents array contains five elements
- contents array, indicating that five elements are stored in the array from small to large
5.2 upgrade of integer set
The type of the new element is longer than the existing type. For example, 16 bits become 32 bits, which is called upgrade in the integer set. After upgrading, new elements can be added to the integer set. The steps of upgrading the integer set and adding new elements are as follows:
- According to the type of the new element, expand the space size of the underlying array and allocate space for the new element
- Convert all existing elements of the underlying array into the same type as the new element, and place the elements after type conversion in the correct position.
- Add a new element to the contents array
The set will not be degraded. For example, after adding a 32-bit element to the original 16 bit array and deleting the newly added element, the integer set will not be degraded.
6, Quick list
quicklist structure is a double ended linked list structure with ziplist as nodes. It is a linked list as a whole, but each node in the linked list is a ziplist
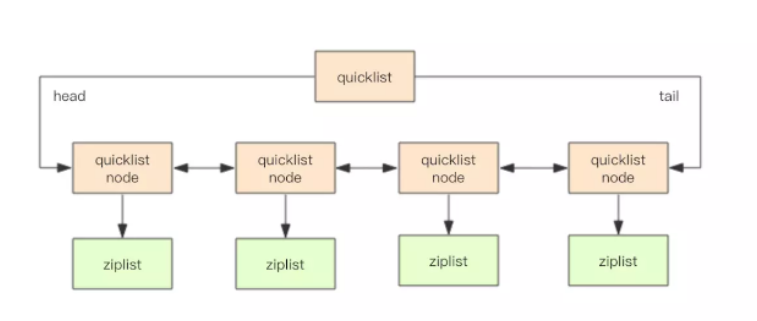
6.1 structure of quick linked list
The code structure is in Src / QuickList H medium
Let's first look at the structure of quicklistNode node:
typedef struct quicklistNode {
//Previous quicklistNode node
struct quicklistNode *prev;
//Next quicklistNode node
struct quicklistNode *next;
//Data pointer,
unsigned char *zl;
//Indicates the total size of zl pointing to the ziplost
unsigned int sz; /* ziplist size in bytes */
//Indicates the number of data items contained in the ziplost
unsigned int count : 16; /* count of items in ziplist */
//Whether the ziplost is compressed, 1 is not, 2 is compressed
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//The reserved field, which is currently a fixed value, indicates that ziplost is used as the data container
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//The data needs to be decompressed temporarily. At this time, set recompress = 1 and have the opportunity to recompress the data again
unsigned int recompress : 1; /* was this node previous compressed? */
//For Redis automatic test
unsigned int attempted_compress : 1; /* node can't compress; too small */
//Extended field, not used at present
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
Let's take another look at the quicklistLZF structure, which represents a compressed ziplost. Its structure is:
typedef struct quicklistLZF {
//Size of zip list after compression
unsigned int sz; /* LZF size in bytes*/
//Flexible array to store compressed ziplist byte array
char compressed[];
} quicklistLZF;
Let's look at the final quicklist structure
typedef struct quicklist {
//Point to the header node (quicklistnode)
quicklistNode *head;
//Point to the tail node (rightmost node)
quicklistNode *tail;
//Number of all ziplist s
unsigned long count; /* total count of all entries in all ziplists */
//Number of quicklist nodes
unsigned long len; /* number of quicklistNodes */
//Set the size of ziplist and store the value of list Max ziplist size parameter
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
//Set the node compression depth, store the value of the list comless depth parameter, and close it when it is 0
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
//Bookmarks added at the tail can be iterated in batches only when the excess memory usage of a large number of nodes is negligible. When they are not used, the memory overhead will not be increased
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
6.2 internal operation of quick linked list
6.2.1 insertion operation
- You can choose to insert in the head or tail:
- The size of the ziplost does not exceed the limit, and the new data is directly inserted into the ziplost
- If the zip list exceeds the limit, create a new quicklistNode node, and then insert the new node into the quicklist two-way linked list
- Insert from middle position:
- You need to split the current zip list into two nodes, and then insert data on one of them
6.2.2 search operation
Find the corresponding ziplost according to the number of node s, and then call the index of ziplost to find it successfully
6.2.3 delete
Using quicklistDelRange function: when 1 is returned, it indicates that the specified interval elements have been deleted successfully, and when 0 is returned, it indicates that no elements have been deleted
When deleting an interval, you will first find the quicklistNode where start is located and calculate whether the deleted elements are less than the deleted count. If the number of deleted elements is not satisfied, you will move to the next quicklistNode to continue deletion, and cycle in turn until the deletion is completed.
reference material:
Redis design and Implementation
Redis development and operation and maintenance
Redis data structure - QuickList
https://pdai.tech/md/db/nosql-redis/db-redis-x-redis-ds.html