Redis learning notes - the underlying data structure of redis
1.Redis as a key value storage system

- Redis is written in ANSI and c,
- The key in Redis is of string type. Of course, there are other types, but they will be converted to string type
- The data types of value are:
- Commonly used: string type, list type, set set type, sortedset (zset) ordered set type, hash type.
- Uncommon: bitmap type, geo location type.
- Redis5.0 added a new type: stream type
- In Redis, the command ignores case, (set), but the key does not ignore case (name)
- Redis does not have the concept of a table. The db corresponding to the redis instance is distinguished by number. The db itself is the namespace of the key.
- For example, user:1000 as the key value represents the element with ID 1000 in the user namespace, which is similar to the row with id=1000 in the user table.
2.RedisDB structure
- The concept of "database" exists in Redis, which is composed of Redis redisDb definition in H.
- When the redis server is initialized, 16 databases will be allocated in advance, and all databases will be saved to a redisServer member of the redisServer structure DB array
- A pointer named db in redisClient points to the currently used database. redisClient receives commands and sends them to redisServer
- RedisDB structure source code:
typedef struct redisDb { //id is the database serial number, 0-15 (Redis has 16 databases by default) int id; //The average ttl (time to live) of stored database objects, which is used for statistics long avg_ttl; //All storage in redis is dict (Dictionary, hash), which stores all key values in the database dict *dict; //Expiration time of stored key dict *expires; //blpop stores blocking key s and client objects dict *blocking_keys; //Post blocking push response the blocking client stores the key and client object of the post blocking push dict *ready_keys; //Store the key and client object monitored by the watch dict *watched_keys; } redisDb;
redisDb is a heavier attribute
- id: id is the database serial number, 0-15 (Redis has 16 databases by default)
- dict: stores all key values in the database
- expires: the expiration time of the stored key
3.RedisObject structure
-
RedisObject, that is, Value, is an object that contains string objects, list objects, hash objects, collection objects, and ordered collection objects
-
Structure information overview:
typedef struct redisObject { unsigned type:4;//Type object type unsigned encoding:4;//code void *ptr;//Pointer to the underlying implementation data structure //... int refcount;//Reference count //... unsigned lru:LRU_BITS; //LRU_BITS is 24bit, which records the time of the last access by the command program //... }robj; -
Type: indicates the type of the object, accounting for 4 bits;
- REDIS_ String (string)
- REDIS_LIST
- REDIS_ Hash (hash)
- REDIS_ Set (set)
- REDIS_ Zset (ordered set)
-
When we execute the type command, we obtain the type of RedisObject by reading the type field of RedisObject
-
encoding: represents the internal code of the object, accounting for 4 bits
- Each object has a different implementation code
- Redis can set different codes for objects according to different usage scenarios, which greatly improves redis's flexibility and efficiency and storage efficiency.
- Through the object encoding command, you can view the encoding method adopted by the Value of the object
-
LRU: 24 bit
- lru: records the last time the object was accessed by the command program (version 4.0 accounts for 24 bits and version 2.6 accounts for 22 bits).
- The upper 16 bits store a time stamp of one minute level, and the lower 8 bits store the access count (lfu: recent access times)
- LRU - > high 16 bits: the last accessed time
- LFU ------ > lower 8 bits: recent visits
-
refcount: records the number of times the object is referenced. The type is integer.
- refcount is mainly used for object reference counting and memory recycling.
- When the refcount of an object is greater than 1, it is called a shared object
- Redis to save memory, when some objects appear repeatedly, the new program will not create new objects, but still use the original objects.
-
ptr
- ptr pointer points to specific data,
- For example: set hello world, ptr points to the SDS containing the string world.
4. Seven types of redisobject - String objects, which are stored in SDS structure
- SDS structure is as follows:
struct sdshdr{
//Records the number of bytes used in the buf array
int len;
//Records the number of unused bytes in the buf array
int free;
//An array of characters used to hold strings
char buf[];
}
- SDS type: Redis does not directly use strings, but SDS(Simple Dynamic String). Used to store string and integer data.
- The structure diagram is as follows:
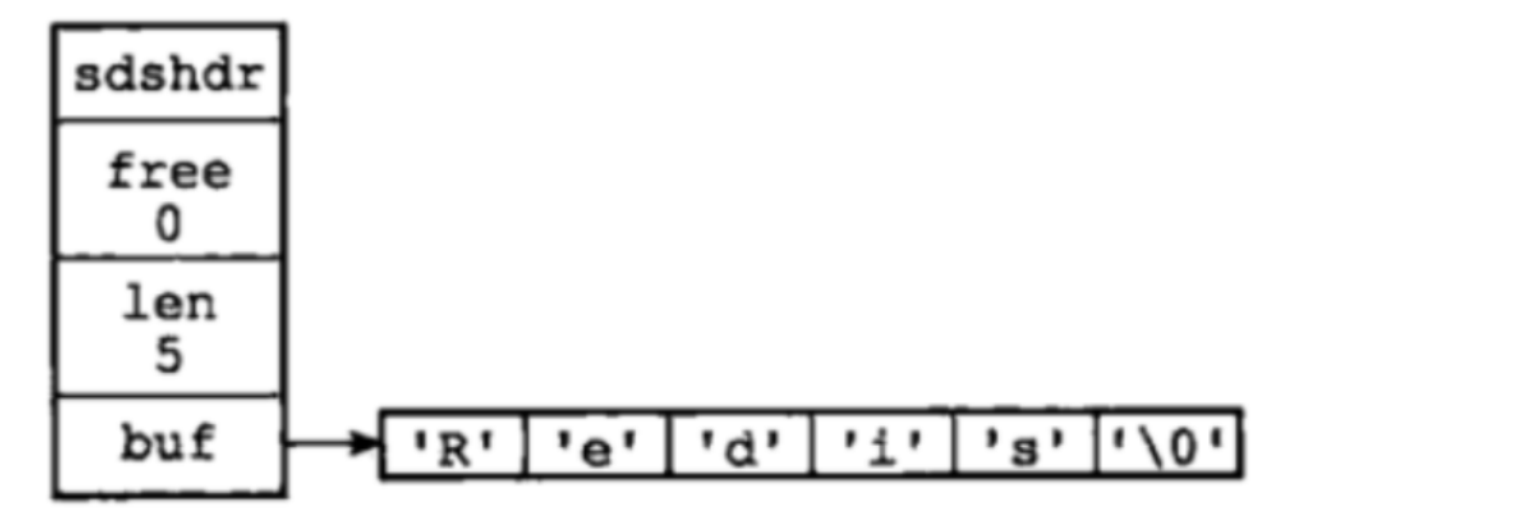
- Length of buf [] = len+free+1
Advantages of SDS:
- SDS adds free and len fields to the C string to obtain the string length: SDS is O(1) and C string is O(n).
- Because SDS records the length, it will automatically reallocate memory when buffer overflow may occur, so as to eliminate buffer overflow.
- Binary data can be accessed, and the string length len is used as the end identifier
5. 7 types of redisobject - jump table
- Jump table is the bottom implementation of ordered set, which is efficient and simple to implement.
- The basic idea of jump list: layer some nodes in the ordered linked list, and each layer is an ordered linked list.
- Search: when searching, it is preferred to start from the highest level and search backward. When reaching a node, if the value of the next node is greater than the value to be searched or the next pointer points to null, it will drop one level from the current node and continue to search backward.
- give an example:
- To find element 9, we need to traverse from the beginning of the node, traversing a total of 8 nodes to find element 9 (start a query at the bottom).
- The first layer: traverse 5 times to find element 9 (starting from the penultimate layer: 0, 2, 6, 8, 9)
- Second layer: traverse 4 times to find element 9 (start of second layer: 0, 6, 8, 9)
- Layer 3: traverse 4 times to find element 9 (start of layer 1: 0, 6, 8, 9)

- This data structure is the jump table, which has the function of binary search.
- Insert:
- In the above example, 9 nodes, a total of 4 layers, are ideal jump tables.
- Determine the number of layers crossed by the new insertion node by flipping a coin (probability 1 / 2): Front: insert the upper layer, back: do not insert, reaching 1 / 2 probability (calculation times)
- Delete: find the specified element and delete the element of each layer
- Jump table features:
- Each layer is an ordered linked list
- The search times are approximate to the number of layers (1 / 2)
- The bottom layer contains all elements
- The space complexity O(n) is doubled
- Implementation of Redis hop table:
//Jump table node
typedef struct zskiplistNode {
/* Store string type data redis3 The robj type is used in version 0, but in redis4 0.1 is directly represented by sds type */
sds ele;
//Store sorted scores
double score;
//Backward pointer, pointing to the previous node / * layer at the bottom of the current node, flexible array, randomly generating values of 1-64*/
struct zskiplistNode *backward;
struct zskiplistLevel {
//Point to the next node in this layer
struct zskiplistNode *forward;
//Number of elements from the next node of this layer to this node
unsigned int span;
} level[];
} zskiplistNode;
//Linked list
typedef struct zskiplist{
//Header node and footer node
structz skiplistNode *header, *tail;
//Number of nodes in the table
unsigned long length;
//The number of layers of the node with the largest number of layers in the table
int level;
}zskiplist;
- Complete jump table structure:

- Advantages of jump table:
- You can quickly find the required node O(logn)
- The head node, tail node, length and height of the jump table can be obtained quickly under the time complexity of O(1).
- Application scenario: implementation of ordered collection
6. Seven types of redisobject - Dictionary
- Dictionary dict, also known as hash, is a data structure used to store key value pairs.
- The entire Redis database is stored in a dictionary. (K-V structure)
- CURD operation on Redis is actually CURD operation on the data in the dictionary.
- Redis dictionary implementation includes Dictionary (dict), Hash table (dictht) and Hash table node (dictEntry).
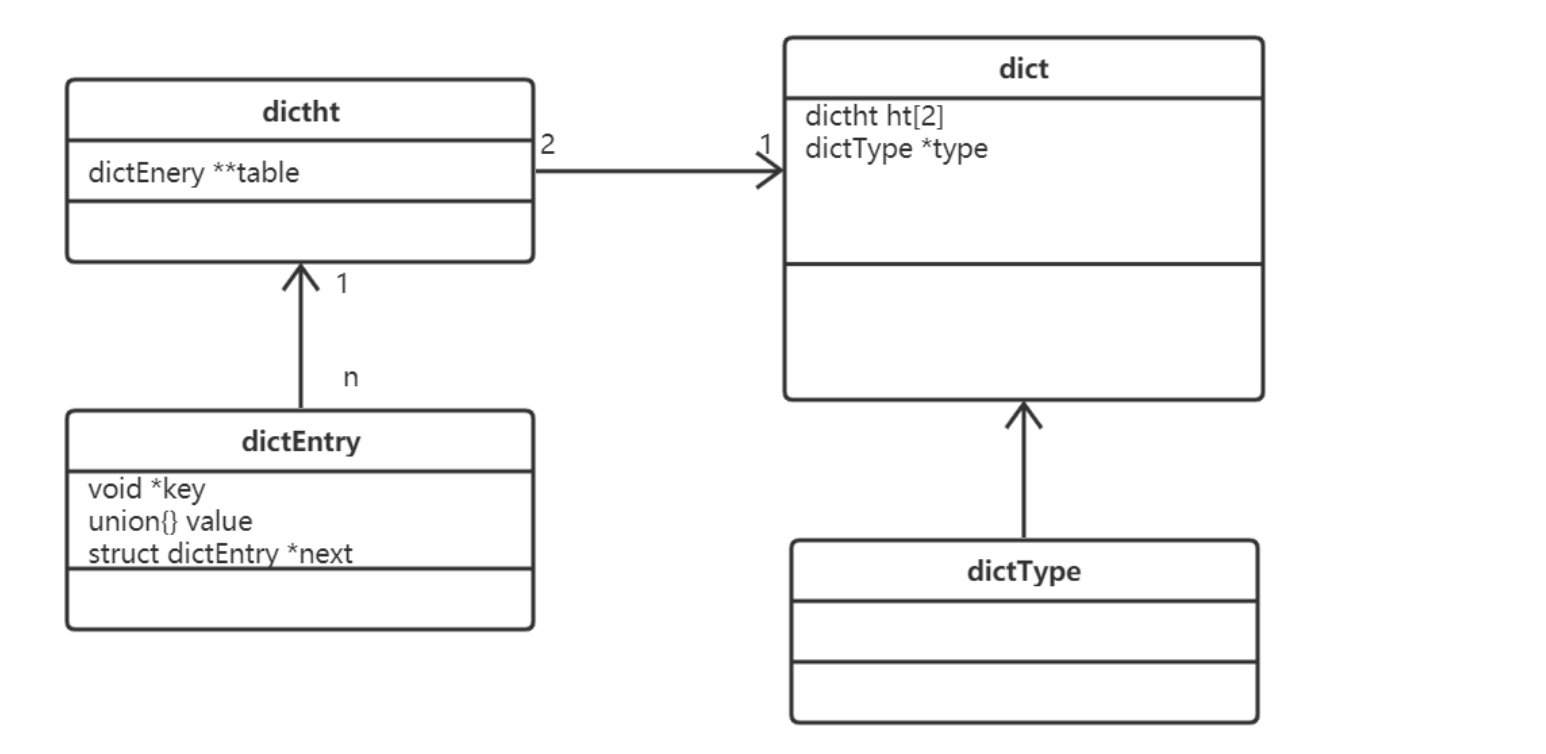
- Data structure of Dictionary:
typedef struct dict {
// The specific operation function corresponding to the dictionary
dictType *type;
// Optional parameters corresponding to functions of the above types
void *privdata;
/* Two hash tables store key value pair data. ht[0] is the native hash table and ht[1] is the rehash hash table */
dictht ht[2];
/*rehash When it is equal to - 1, it indicates that there is no rehash, otherwise it indicates that rehash operation is in progress, and the stored value indicates the index value (array subscript) to which rehash of the hash table ht[0] is going*/
long rehashidx;
// Number of iterators currently running
int iterators;
} dict;
- The type field points to the dictType structure, which includes the function pointer for the dictionary operation
typedef struct dictType {
// Function to calculate hash value
unsigned int (*hashFunction)(const void *key);
// Copy key function
void *(*keyDup)(void *privdata, const void *key);
// Functions that copy values
void *(*valDup)(void *privdata, const void *obj);
// Compare key functions
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// Function to destroy key
void (*keyDestructor)(void *privdata, void *key);
// Function to destroy values
void (*valDestructor)(void *privdata, void *obj);
} dictType;
- In addition to the K-V data storage of the master database, Redis dictionary can also be used for hash table objects, master-slave node management in sentinel mode, etc. in different applications, the forms of dictionaries may be different. dictType is an operating function (polymorphic) abstracted to realize various forms of dictionaries.
- Complete Redis dictionary data structure:

- Dictionary expansion: the dictionary reaches the upper storage limit (threshold 0.75), and rehash is required
- Capacity expansion process:
- The default capacity of the initial application is 4 dictentries, and the capacity of the non initial application is twice that of the current hash table.
- rehashidx=0 means rehash operation is required.
- The newly added data is in the new hash table h[1]
- Modify, delete and query in old hash table h[0] and new hash table h[1] (in rehash)
- After recalculating the index value of the old hash table h[0], all the data are migrated to the new hash table h[1]. This process is called rehash.
- Expansion process diagram:

- Progressive rehash:
- When the amount of data is huge, the rehash process is very slow, so it needs to be optimized.
- If the server is busy, rehash only one node
- Server idle, batch rehash(100 nodes)
- Application scenario:
- K-V data storage of master database
- hash 3. Master-slave node management in sentinel mode
7. Seven types of redisobject - hash table of the underlying implementation of the dictionary
- hash table: array + linked list
- Array: a finite, same type, ordered collection, a container used to store data. It can locate the memory address of the data with the time complexity of O(1) by using the method of header pointer + offset.
- Linked list:
- The initial capacity of the hash table array is 4. With the increase of k-v storage capacity, the hash table array needs to be expanded. The newly expanded capacity is twice the current capacity, i.e. 4,8,16,32
- Index value = Hash value & mask value (Hash value and Hash table capacity remainder)
typedef struct dictht {
// Hash table array
dictEntry **table;
// Size of hash table array
unsigned long size;
// The mask used to map the location. The value is always equal to (size-1)
unsigned long sizemask;
// The number of existing nodes in the hash table, including the next single linked list data
unsigned long used;
} dictht;
- hash() function:
- Hash (hash) is used to convert input of any length into hash value of fixed type and fixed length through hash algorithm.
- The hash function can uniformly convert the keys in Redis, including strings, integers and floating-point numbers, into integers. For example: key=100.1 String "100.1" 5-bit string
- Array subscript = hash(key)% array capacity (remainder of hash value% array capacity)
- Hash conflict
- The array subscripts of different key s are consistent after calculation, which is called Hash conflict.
- A single linked list is used to store the original key and value at the same subscript position
- When finding a value based on the key, find the array subscript, and traverse the single linked list to find the value with the same key
- Hash table node structure:
- The key field stores the key in the key value pair
- The v field is a union that stores the values in the key value pair.
- Next points to the next hash table node, which is used to resolve hash conflicts
typedef struct dictEntry {
void *key; // key
// The value v can be of the following four types
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// Point to the next hash table node to form a one-way linked list to solve hash conflicts
struct dictEntry *next;
} dictEntry;
- The hash structure of the dictionary in Redis: dictEntry indicates the hash table array node, dictEntry*[8], indicating that the hhash table is 8 in length

7. Seven types of redisobject - compressed list
- Zip list: a sequential data structure consisting of a series of specially encoded contiguous memory blocks
- Is a byte array that can contain multiple entries. Each node can hold a byte array or an integer.
- The data structure of the compressed list is as follows:

- zlbytes: the byte length of the compressed list
- zltail: the offset of the tail element of the compressed list relative to the starting address of the compressed list
- zllen: number of elements in the compressed list
- entry1... entryX: compress the nodes of the list
- zlend: the end of the compressed list, accounting for one byte, constant 0xFF (255)
- Encoding structure of entryX element:

- previous_entry_length: the byte length of the previous element
- Encoding: indicates the encoding of the current element
- Content: data content
- Compressed list data structure:
struct ziplist<T>{
unsigned int zlbytes; // The length of the ziplost is the number of bytes, including the header, all entries, and zip end.
unsigned int zloffset; // The offset from the header pointer of ziplost to the last entry is used for fast reverse query
unsigned short int zllength; // Number of entry elements
T[] entry; // Element value
unsigned char zlend; // Ziplost terminator, fixed to 0xFF
}
typedef struct zlentry {
unsigned int prevrawlensize; //previous_ entry_ The length of the length field
unsigned int prevrawlen; //previous_ entry_ What the length field stores
unsigned int lensize; //Length of encoding field
unsigned int len; //Data content length
//The header length of the current element, that is, previous_ entry_ The sum of the length of the length field and the length of the encoding field.
unsigned int headersize;
unsigned char encoding; //Data type unsigned char
*p; //First address of current element
} zlentry;
8. 7 types of redisobject - quick list
- quicklist is an important data structure at the bottom of Redis. Is the underlying implementation of the list. (before Redis 3.2, Redis was implemented with two-way linked list (adlist) and compressed list (ziplist) On Redis3 2 later, Redis designed quicklist by combining the advantages of adlist and ziplist.
- The bottom implementation of the quick list is a two-way linked list, so the list can be lpush (insert on the left) and rpush (insert on the right)
- Two way list (adlist): it can be traversed from two directions
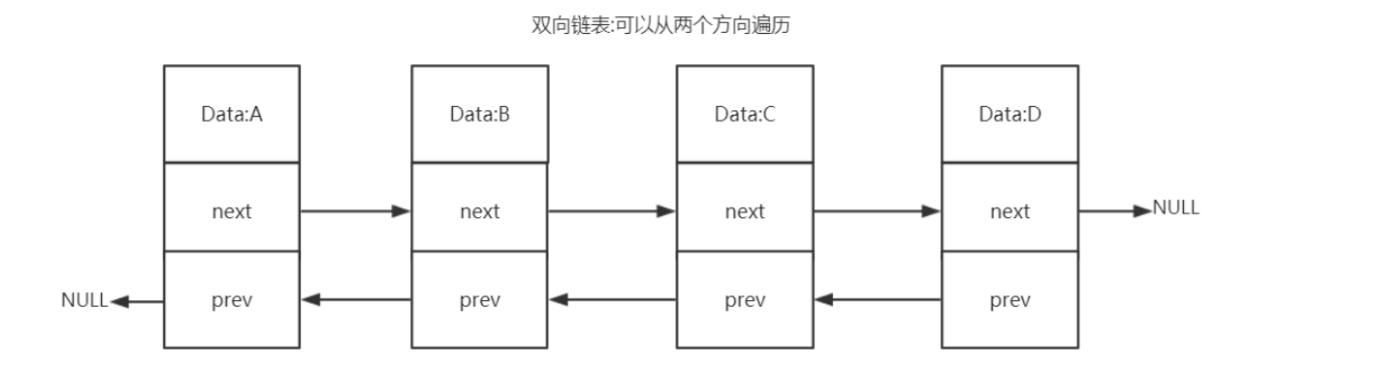
- Advantages of two-way linked list:
- Bi directional: the linked list has references to the pre node and post node. The time complexity of obtaining these two nodes is O(1).
- Common linked list (single linked list): the node class retains the reference of the next node. The linked list class only retains the reference of the head node and can only be inserted and deleted from the head node
- Acyclic: the prev pointer of the header node and the next pointer of the footer node point to NULL, and the access to the linked list ends with NULL.
Ring: the previous node of the head points to the tail node - With linked list length counter: the time complexity of obtaining the linked list length through len attribute is O(1).
- Polymorphism: linked list nodes use void * pointer to save node values, which can save various types of values.
- Quick list: quicklist is a two-way linked list. Each node in the linked list is a ziplost structure. Each node in quicklist ziplost can store multiple data elements.

- The structure of quicklist header is defined as follows:
typedef struct quicklist {
quicklistNode *head; // Point to the header of the quicklist
quicklistNode *tail; // Points to the tail of the quicklist
unsigned long count; // The sum of the number of all data items in the list
unsigned int len; // The number of quicklist nodes, that is, the number of ziplist s
// Ziplist size limit, given by list Max ziplist size (Redis setting)
int fill : 16;
// Node compression depth setting, given by list compress depth (Redis setting)
unsigned int compress : 16;
} quicklist;
- The structure of the quicklist node is defined as follows:
typedef struct quicklistNode {
struct quicklistNode *prev; //Precursor node pointer
struct quicklistNode *next; //Successor node pointer
//When the compressed data parameter recompress is not set, it points to a ziplost structure
//Set the compressed data parameter recompress to point to the quicklistLZF structure
unsigned char *zl;
//Total length of zip list
unsigned int sz; /* ziplist size in bytes */
//The number of nodes in the ziplost package, accounting for 16 bits in length
unsigned int count : 16; /* count of items in ziplist */
//Indicates whether LZF compression algorithm is used to compress quicklist nodes. 1 indicates compressed, 2 indicates not compressed, accounting for 2 bits
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//Indicates whether a quicklistNode uses the ziplost structure to save data. 2 means compressed, 1 means not compressed. The default is 2, accounting for 2 bits
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//Mark whether the ziplost of the quicklist node has been decompressed before, accounting for 1 bit
//If recompress is 1, wait to be compressed again
unsigned int recompress : 1; /* was this node previous compressed? */
//Used during testing
unsigned int attempted_compress : 1; /* node can't compress; too small */
//Additional extension bits, accounting for 10bits
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
- data compression
- The actual data storage structure of each node of quicklist is ziplist. The advantage of this structure is to save storage space.
- In order to further reduce the storage space of ziplist, ziplist can also be compressed.
- The compression algorithm adopted by Redis is LZF. Its basic idea is: the data and the previous repeated records repeat the position and length, and the original data is recorded without repetition.
- The compressed data can be divided into multiple segments, and each segment has two parts: interpretation field and data field. The structure of quicklistLZF is as follows:
typedef struct quicklistLZF { unsigned int sz; // Bytes occupied after LZF compression char compressed[]; // Flexible array, pointing to the data part } quicklistLZF; - Application scenario: the underlying implementation of list, publish and subscribe, slow query, monitor and other functions.
9. 10 encoding s of redisobject
-
encoding represents the internal code of the object, accounting for 4 bits.
-
Redis sets different codes for objects through the encoding attribute
-
String
- int: REDIS_ENCODING_INT (integer of type int)
- embstr: REDIS_ ENCODING_ Embstr (encoded simple dynamic string). The length of small string is less than 44 bytes (one byte is 8 bits)
- raw: REDIS_ENCODING_RAW (simple dynamic string) large string length is greater than 44 bytes
-
list
- The code of the list is quicklist: REDIS_ENCODING_QUICKLIST (quick list)
-
Hash: the encoding of hash is dictionary and compressed list
-
dict: REDIS_ENCODING_HT (Dictionary), when the number of hash table elements is large or the elements are not small integers or short strings. When the elements of Redis collection type are non integers or are outside the range of 64 bit signed integers (> 18446744073709551616)
-
ziplist: REDIS_ENCODING_ZIPLIST (compressed list), when the number of hash table elements is relatively small and the elements are small integers or short strings.
-
Set: the encoding of a set is an integer set and a dictionary
-
intset: REDIS_ENCODING_INTSET (integer set), when all elements of Redis set type are integers and are within the range of 64 bit signed integers (< 18446744073709551616)
-
zset: the encoding of ordered set is compressed list and jump table + dictionary
-
ziplist: REDIS_ENCODING_ZIPLIST (compressed list), when the number of elements is relatively small and the elements are small integers or short strings.
-
skiplist + dict: REDIS_ENCODING_SKIPLIST (jump table + Dictionary), when the number of elements is relatively large or the elements are not small integers or short strings