Redis detailed notes
Notes: the Redis course of crazy talking about Java in station B: https://www.bilibili.com/video/BV1S54y1R7SB
1, NoSQL overview
1. Why use NoSQL
-
Now is the era of big data (data that cannot be solved by ordinary databases: big data (mass storage and parallel computing))
SQL => NoSQL
1. Bottleneck in stand-alone era (such as MySQL)
- The amount of data is too large for one machine to store
- The index of data < B + tree > (3 million pieces of data in a single MySQL table must be indexed), and there is no room for one machine memory
- A server can't afford a large number of visits (MySQL mixed reading and writing - performance degradation)
2. Memcached cache (reducing the pressure on the server) + MySQL + vertical splitting (read-write separation, multiple MySQL servers, some values are responsible for reading and some values are responsible for writing)
Development process: ① optimize data structure and index = > ② file cache (involving IO operations) = > ③ Memcached
3. Sub database and sub table + horizontal split + MySQL Cluster
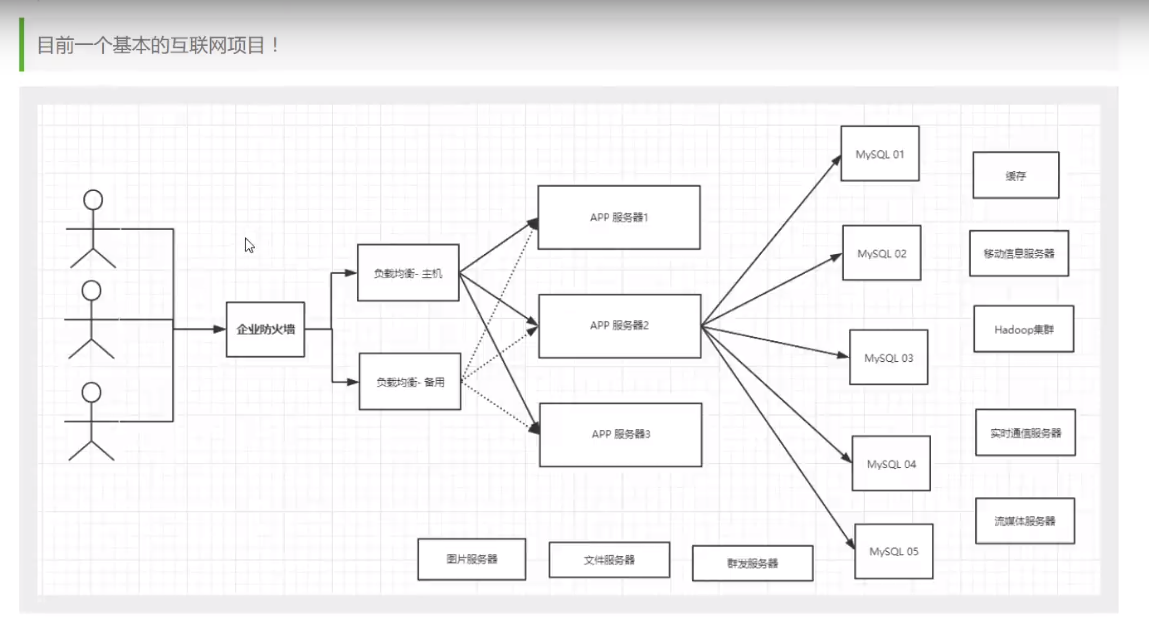
- The user's personal information (social network, geographical location, user log, etc.) is growing and cannot be stored in relational database, so NoSQL database is required
2. What is NoSQL
Not Only SQL - > non relational database

NoSQL features
- Easy to expand (no relationship between data)
- High performance of big data (Redis writes 80000 times and reads 110000 times a second. NoSQL's cache record level is a fine-grained cache with high performance)
- The data types are diverse (there is no need to design the database in advance (because of the large amount of data, it is available at any time)
- Traditional RDBMS and NoSQL
- Traditional RDBMS
- Structured organization
- SQL
- Data and relationships exist in separate tables
- Operation, data definition language
- Strict consistency
- Basic transaction
- ...
- NoSQL
- Not just SQL
- No fixed query statement
- Key value pair storage, column storage, document storage, graphic database (social relationship)
- Final consistency
- CAP theorem and BASE
- High performance, high availability and high scalability
- ...
- Traditional RDBMS
Understanding: 3V + 3 high
3V in the era of big data: it mainly describes problems
- Massive Volume
- Diversity
- Real time Velocity
Three highs in the era of big data: mainly the requirements for procedures
- High concurrency
- High extension (cluster)
- High performance
E-commerce website:
# 1. Basic information of goods
Name, price and merchant information:
Relational database: MySQL / Oracle (Wang Jian: Ali IOE(IBM Minicomputer, Oracle database EMC Memory))
# 2. Description and comments of goods (many words)
Document database: MongoDB
# 3. Picture
Distributed file system: FastDFS,TFS(Taobao) GFS(Google),HDFS(Hadoop),OSS Cloud storage (alicloud)
# 4. Keywords for items (search)
Search Engines: solr,ElasticSearch,ISearch(Ali: Dolon)
# 5. Popular band information
In memory database: Redis,Tair,Memcached,...
# 6. Commodity transaction and external interface
Third party application
3. Four categories of NoSQL
1.KV key value pair
- Sina: Redis
- Meituan: Redis + Tair
- Alibaba, baidu: Redis + Memcached
2. Document database (bson format)
- MongoDB (must master)
- Database based on distributed file storage (written in C + +)
- It is mainly used to process a large number of documents
- Intermediate product between relational database and non relational database
- ConthDB
3. In line storage
- HBase
- distributed file system
4. Graph relational database
- Relationships, not pictures (for example, circle of friends, social networks, advertising recommendations)
- Neo4j,InfoGrid
contrast
| classification | Examples examples | Typical application scenarios | data model | advantage | shortcoming |
|---|---|---|---|---|---|
| Key value | Tokyo Cabine/Tyrant Redis Voldemort Oracle BDB | Content caching is mainly used to handle the high access load of a large amount of data, as well as some log systems | The Key Value pair from Key to Value is usually implemented with hashtable | Fast search speed | Data is unstructured and is usually only treated as string or binary data |
| Column storage database | Cassandra HBase Riak | Distributed file system | It is stored in column clusters to store the same column of data together | Fast search speed, strong scalability and easier distributed expansion | Relatively limited functions |
| Document database | CouchDB MongoDB | Web application (similar to key Value, Value is structured, but the database can understand the content of Value) | The key value pair corresponding to key value. Value is structured data | The data structure requirements are not rigorous, the table structure is variable, and the table structure does not need to be defined in advance like the relational database | The query performance is not high, and there is a lack of unified query syntax |
| Graphic database | Neo4J InfoGrid Infinite Graph | Social networks, recommendation systems, etc. Focus on building relationship maps | Figure structure | Using graph structure correlation algorithm. For example, shortest path addressing, N-degree relationship search, etc | In many cases, it is necessary to calculate the whole graph to get the required information, and this structure is not good for distributed clustering scheme |
2, Getting started with Redis
1. What is redis
Official website: redis.io
Chinese website: http://www.redis.cn/
Redis is an open source (BSD licensed) in memory data structure storage system, which can be used as database, cache and message middleware. It supports many types of data structures, such as strings, hashes, lists, sets, sorted sets And range query, bitmaps, hyperloglogs and geospatial Index radius query. Redis has built-in replication,Lua scripting, LRU event,transactions And different levels of Disk persistence , and passed Redis Sentinel And automatic Partition (Cluster) Provide high availability.
Redis and other key - value caching products have the following three characteristics:
- Redis supports data persistence. It can save the data in memory on disk and can be loaded again for use when restarting.
- Redis not only supports simple key value data, but also provides storage of list, set, zset, hash and other data structures (various data structures).
- Redis supports data backup, that is, data backup in master slave mode.
Redis advantages
- Extremely high performance – Redis can read 110000 times / s and write 81000 times / s.
- Rich data types – Redis supports string, lists, hashes, sets and Ordered Sets data type operations for binary cases.
- Atomic – all Redis operations are atomic, which means that they are either executed successfully or not executed at all. A single operation is atomic. Multiple operations also support transactions, that is, atomicity, which are packaged through MULTI and EXEC instructions. (however, Redis transaction MULTI operations do not support atomicity - when we execute a statement with errors, other statements can still be executed normally. See transaction for details.)
- Rich features – Redis also supports publish/subscribe, notification, key expiration and other features.
- Redis runs in memory but can be persisted to disk. Therefore, it is necessary to weigh the memory when reading and writing different data sets at high speed, because the amount of data cannot be greater than the hardware memory. Another advantage of in memory database is that compared with the same complex data structure on disk, it is very simple to operate in memory, so redis can do many things with strong internal complexity. At the same time, in terms of disk format, they are compact and generated in an additional way, because they do not need random access.
2. What can you do?
- Memory storage, persistence (rdb, aof)
- Efficient and can be used for caching
- Publish subscribe system
- Map information analysis
- Timer, counter (Views)
- ...
3. Characteristics
- Diverse data structures
- Persistence
- colony
- affair
- ...
4. Installation (because Redis is more suitable for linux, only the installed version of linux is available)
linux uses Centos 7.3
You can use virtual machine or cloud server (student machine is not expensive). Because I have a server, I will install and learn Redis on the server
① Download installation package
http://www.redis.cn/

② Pressurized installation package (upload the compressed package to the server using xshell and xftp in advance)
The compressed package is in the / app / directory
Create the redis folder under / usr/local / and enter it

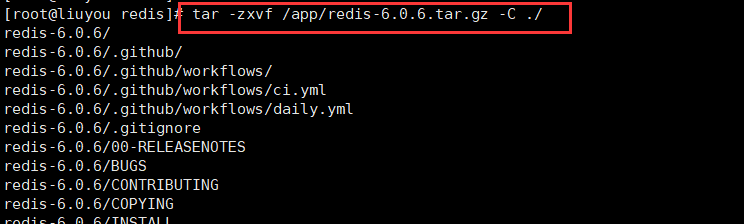
Unzip the compressed package to this folder
tar -zxvf /app/redis-6.0.6.tar.gz -C ./
③ Compile and install (ensure that the compilation environment is installed)
The compilation environment is not installed. yum install gcc-c is required++
If the following operation reports an error: you need to upgrade the version of GCC (redis6 requires 5.3 +)
//Upgrade gcc to above 9 yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils //Temporarily change the gcc version to 9 scl enable devtoolset-9 bash //Or permanent change echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
cd redis-6.0.6make && make install

After compilation, the default installation path is / usr/local/bin

④ Install system services and start in the background
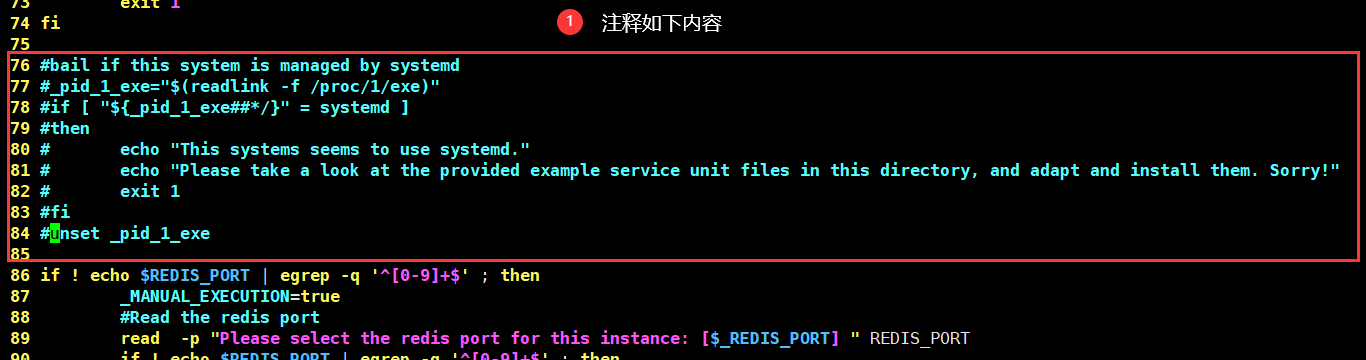
Errors may be reported:

Solution: vim install_server.sh, the notes are shown in the following figure
Install system services (you can specify options, which are the default below)
cd utils./install_server.sh
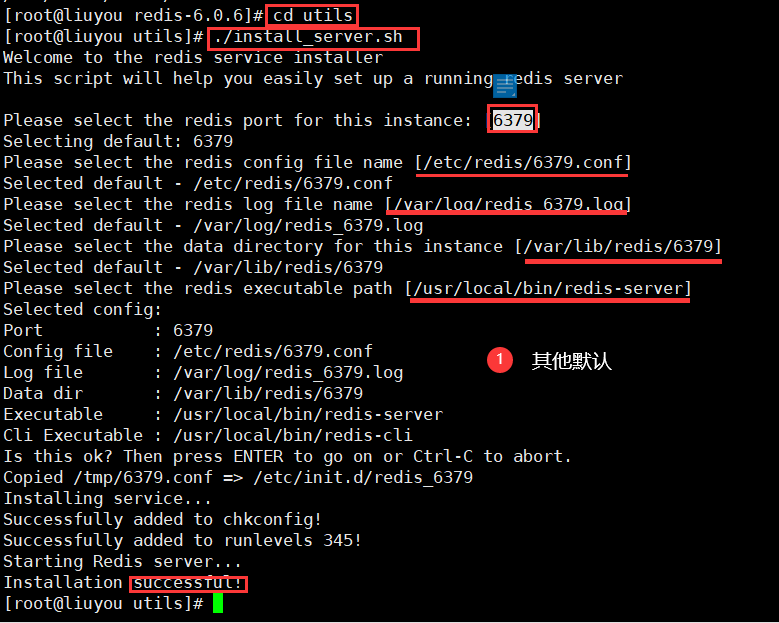
The default configuration file is: / etc / redis / 6379 Conf (after successful installation, the default background starts automatically)
⑤ Enable redis service
You can use a custom configuration file to open it. systemctl is used here
/redis Installation directory/redis-server /Profile directory/redis.conf# Shut down the service / redis installation directory / redis cli shutdown
systemctl start redis_6379.service
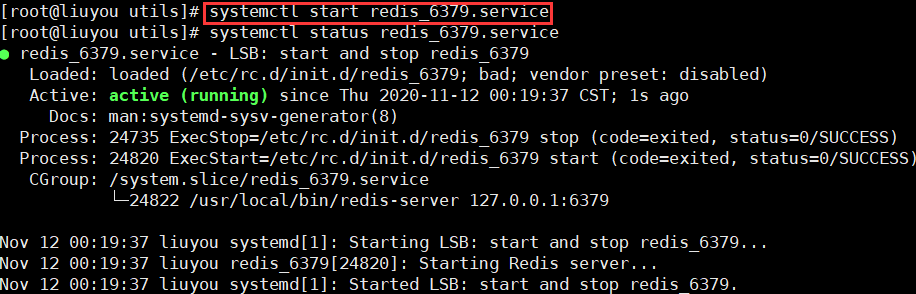
⑥ Client connection test
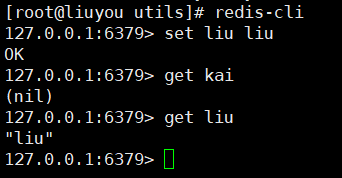
⑦ Set up remote connection
vim /etc/redis/6379.conf
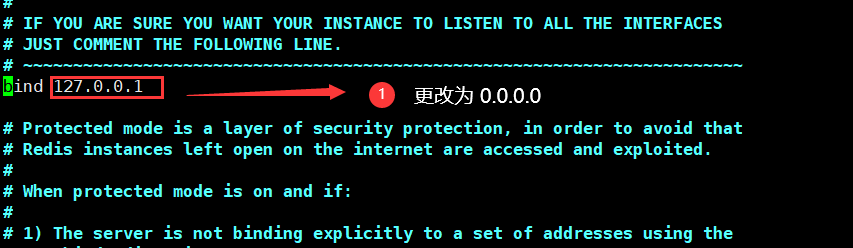
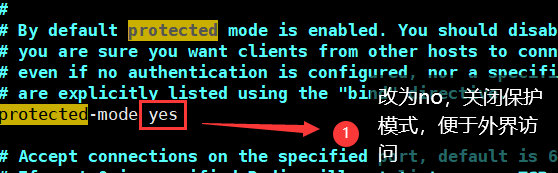
Then restart the service:
systemctl restart redis_6379.service
⑧ Configure access password
vim /etc/redis/6379.conf
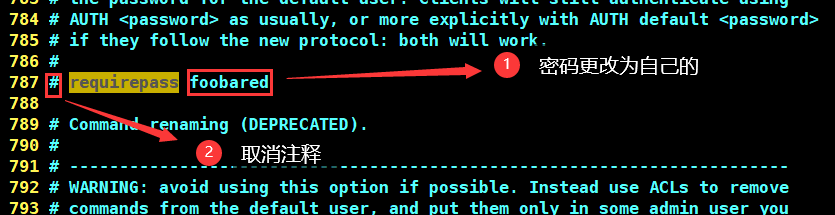
Restart service
systemctl restart redis_6379.service
Client connection test
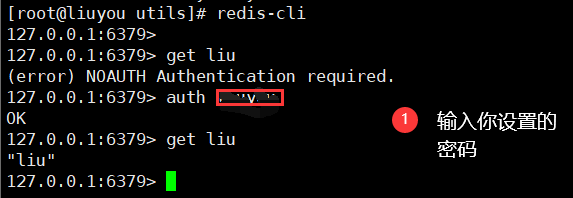
Close connection

5. Performance test
Use the built-in redis benchmark tool to test
redis-benchmark [option] [option value]
Optional parameters of performance test tool:
| Serial number | option | describe | Default value |
|---|---|---|---|
| 1 | -h | Specify the server host name | 127.0.0.1 |
| 2 | -p | Specify server port | 6379 |
| 3 | -s | Specify server socket | |
| 4 | -c | Specifies the number of concurrent connections | 50 |
| 5 | -n | Specify the number of requests | 10000 |
| 6 | -d | Specifies the data size of the SET/GET value in bytes | 3 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR uses random keys and Sadd uses random values | |
| 9 | -P | Pipe < numreq > requests | 1 |
| 10 | -q | Force to exit redis. Show only query/sec values | |
| 11 | —csv | Export in CSV format | |
| 12 | -l | Generate a loop and permanently execute the test | |
| 13 | -t | Run only a comma separated list of test commands. | |
| 14 | -I | Idle mode. Open only N idle connections and wait. |
test
# Test: 100 concurrent connection requests redis benchmark - C 100 - N 100000

6. Basic knowledge description (basic command)
If you think the command here is not very good-looking, go to this blog https://www.cnblogs.com/wlandwl/p/redis.html , or official website: http://www.redis.cn/commands.html
Note: all the following keys represent the names of the keys of the corresponding data types; Value indicates the stored value (unless otherwise specified in the note)
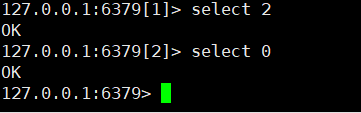
1.Redis has 16 databases (0 ~ 15), and the 0 database is used by default
You can use select to switch
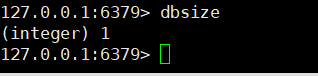
2. View database size
Use dbsize to view the database size
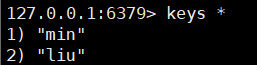
3. View all key s (Current Library)
Using keys*
4. Clear the current database
flushdb
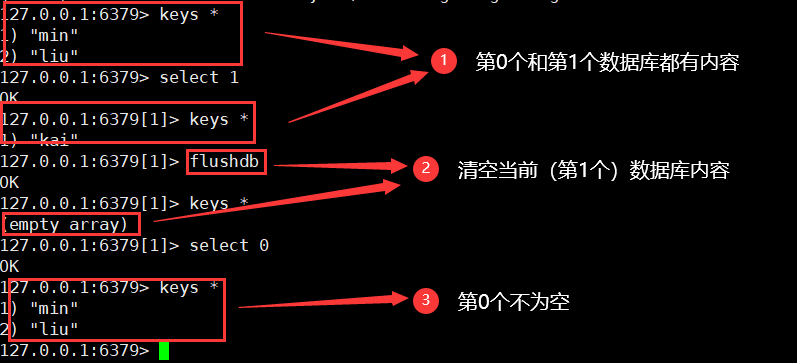
5. Clear all databases
flushall
slightly
6. Is redis single threaded?
- Redis is fast. Officials say that redis is based on memory operation. CPU is not redis's performance bottleneck. Redis's performance bottleneck is based on the machine's memory and network bandwidth. Since single thread can be used, multithreading is not necessary. (multithreading is supported after 6.0)
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG azzxg8ea-1642752175414)( https://www.kuangstudy.com/bbs/2020-11-2-Redis%E8%AF%A6%E7%BB%86%E7%AC%94%E8%AE%B0.assets/image -20201112020411584. png)]
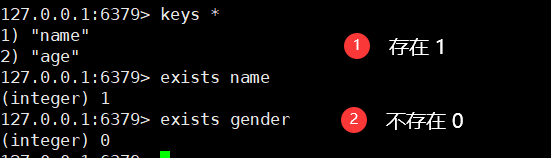
7. Determine whether the key exists
exists key
8. Remove key
move key 1 // 1 indicates the current database
del key / / delete the key of the current database (multiple keys are allowed)
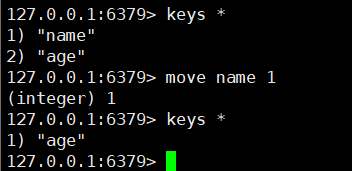
9. Set the expiration time of the key
expire key time / / the unit time is s
ttl key / / view the remaining survival time
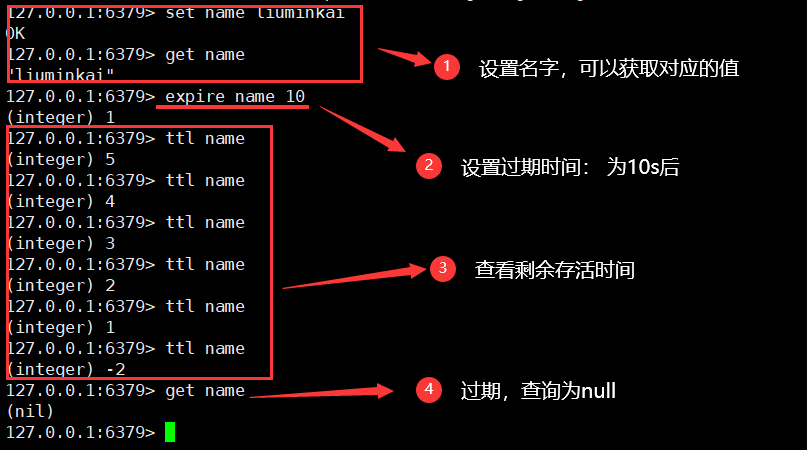
10. View the type of the current key
type key
11. String append (string)
append key appendValue
- If the current key does not exist, it is equivalent to set key
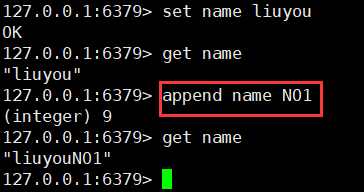
12. Get String length (String)
strlen key
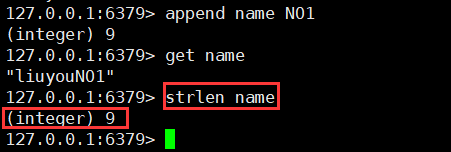
13. String i + + operation (can be used for reading volume Implementation) (string)
incr key
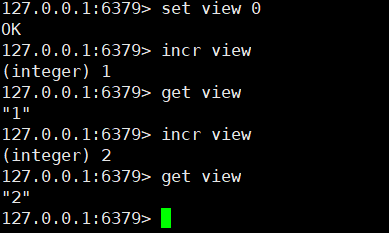
Similarly, i -
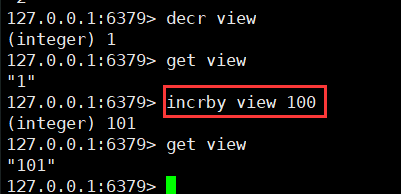
decr key
Step size setting
incrby key step
decrby key step
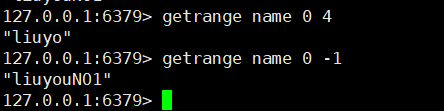
14. String fragment Range (string)
getrange key startIndex endIndex
- Corresponding to substring in java (but endIndex here is a closed interval)
- Special case: when endIndex = -1, it means from startIndex to the last
15. String substitution (string)
setrange key index replaceString
- Corresponding to replace in java
- Note that if replaceString is a string, the fragment of replaceString length after index in the source string will be replaced. The results are as follows

16. Special set setting (String)
setex(set with expire)
setex key value / / set value with expiration time
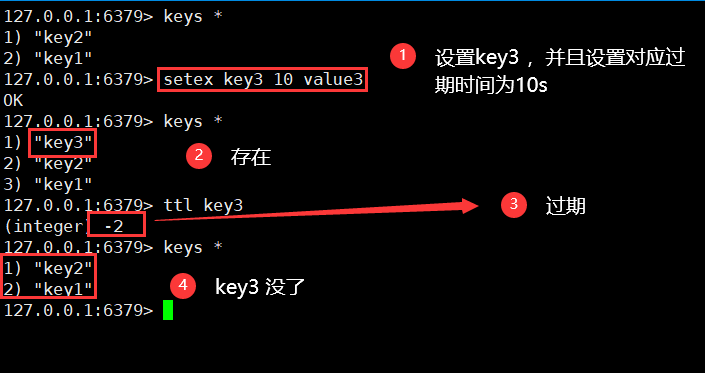
setnx(set if not exist)
setnx key value / / if it does not exist, set

17. Batch setting and batch acquisition (atomic operation) (String)
mset k1 v1 k2 v2 ...
mget k1 k2 ...
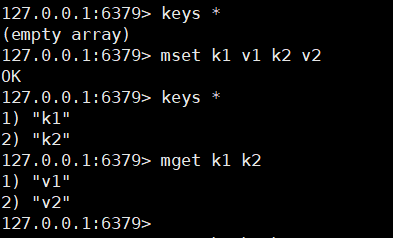
- special
- msetnx batch setup
18. Set high order (String)
1)getset
getset key value / / get first and then set (if it does not exist, return nil first and set the value in the; if it does exist, return the original value first and then set the new value)

19. Rename key
rename key newName
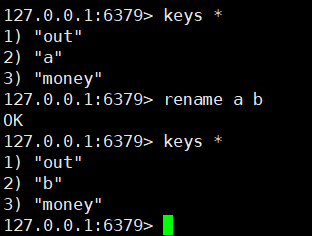
20. Return a random key
randomKey
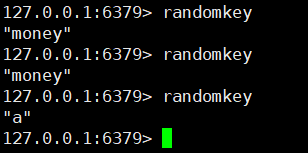
21. Manual persistence operation
save blocking
- SAVE directly calls rdbSave and blocks the Redis main process until the SAVE is completed. During the main process blocking, the server cannot process any requests from the client.
bgsave non blocking
- BGSAVE fork s out a sub process. The sub process is responsible for calling rdbSave and sending a signal to the main process after saving to notify that the saving has been completed. Redis server can still continue to process client requests during BGSAVE execution.
| command | save | bgsave |
|---|---|---|
| IO type | synchronization | asynchronous |
| Blocking? | yes | Yes (blocking occurs in fock(), usually very fast) |
| Complexity | O(n) | O(n) |
| advantage | No additional memory is consumed | Do not block client commands |
| shortcoming | Blocking client commands | A fock subprocess is required, which consumes memory |
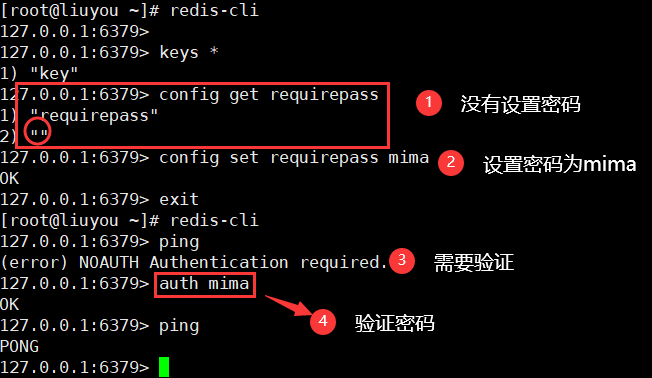
22. Obtain the user password in the configuration file
config get requirepass
23. Set the user password in the configuration file (temporary restart, service failure)
config set requirepass password
24. Password authentication
auth password after setting the password, you must authenticate to use the client function
25. Turn off redis service
shutdown
26. View the directory where rdb files are stored
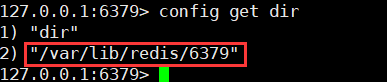

27. View server information
info parameter
Parameter list:
- Server: general information of redis server
- clients: the connection part of the client
- Memory: information about memory consumption
- persistence: RDB and AOF related information
- stats: General Statistics
- Replication: Master / slave replication information
- CPU: counts CPU consumption
- commandstats: Redis command statistics
- cluster: Redis cluster information
- keyspace: database related statistics
It can also take the following values:
- All: return all information
- Default: the value returns information about the default settings
If no parameters are used, the default is default.
3, Five data types
Redis is an open source (BSD licensed) in memory data structure storage system, which can be used as database, cache and message middleware. It supports many types of data structures, such as strings, hashes, lists, sets, sorted sets And range query, bitmaps, hyperloglogs and geospatial Index radius query. Redis has built-in replication,Lua scripting, LRU event,transactions And different levels of Disk persistence , and passed Redis Sentinel And automatic Partition (Cluster) Provide high availability.
Single sign on
String (string)
Slightly, see the front for details
Usage scenario:
- Counter
- Count the number of multiple units (uid:122:follow 10)
- Number of fans
- Object cache storage
List
1. Insert data from head / tail and data display
lpush key value
rpush key value
lrange key 0 -1
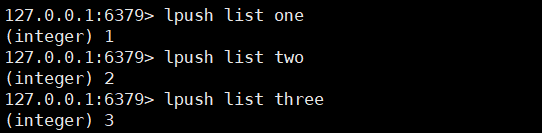
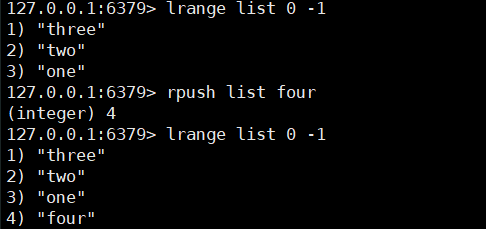
2. Remove data from head / tail
lpop key
rpop key
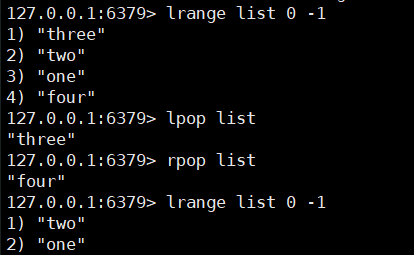
3. Get the value of the specified index
lindex key index

4. Get list length
llen key

5. Remove the specified value
Lrem key count element
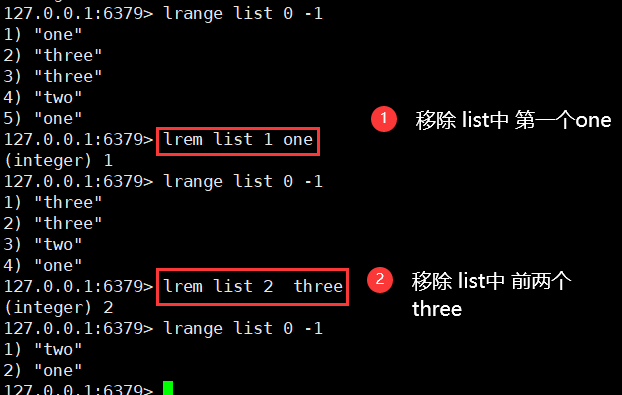
6. Trim trim list
ltrim key startIndex endIndex
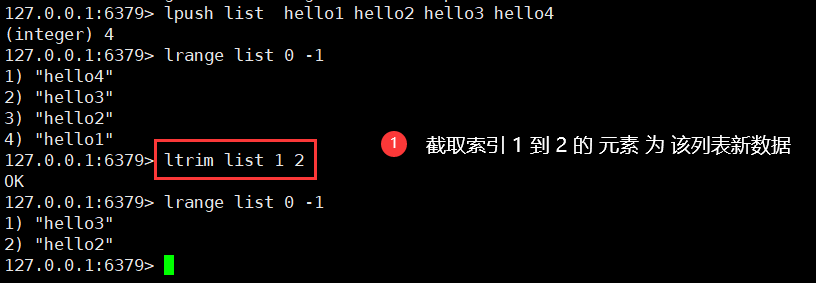
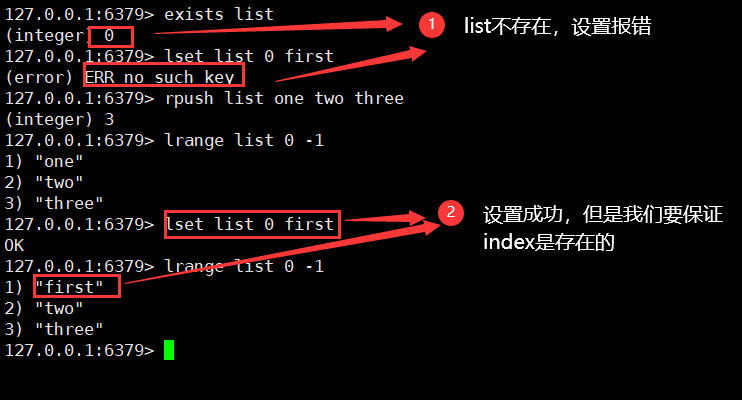
7. You can also use set
lset key index value / / replace the value of the index specified in the list with the corresponding value
- Ensure that both key and index exist, or an error will be reported
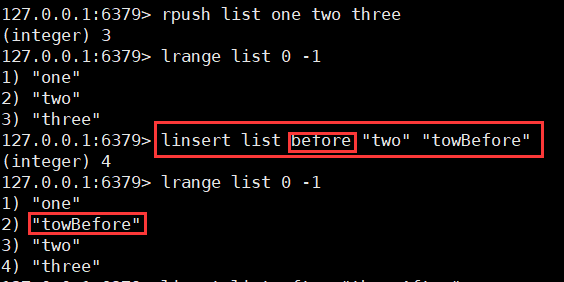
8. Insert the specified value
Linsert key before | after pivot (after that word) value
9. Complex operation
1)rpoplpush
rpoplpush source destination(newList) / / remove the last element of the source first, and then add the element to the newList
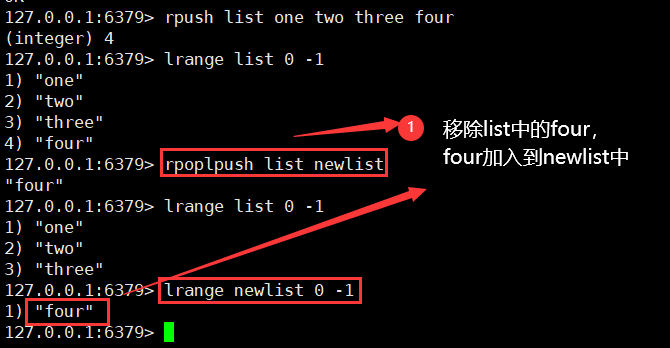
Usage scenario:
- Stack (lpush, lpop)
- Queue (lpush, rpop)
- Message queue
- Blocking queue
Set
Values in the collection cannot be duplicated (unordered)
1. Add members to the collection and view all members
sadd key member
smembers key
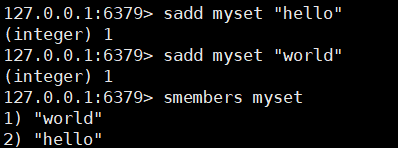
2. Determine whether members exist
sismember key member
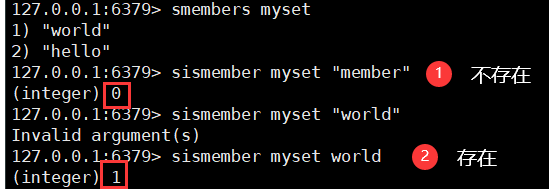
3. View set length (special)
scard key

4. Remove the designated member
srem key member
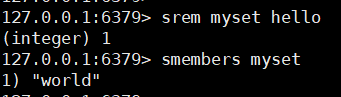
5. Get random members in the set
srandmember key [count]
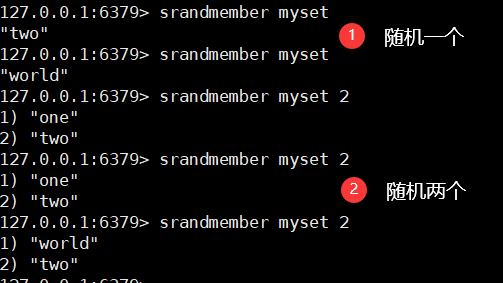
6. Remove members randomly
spop key [count]
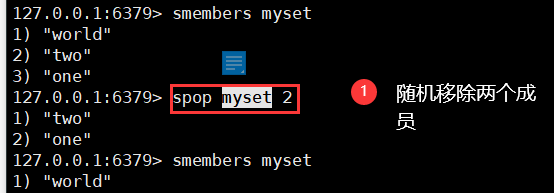
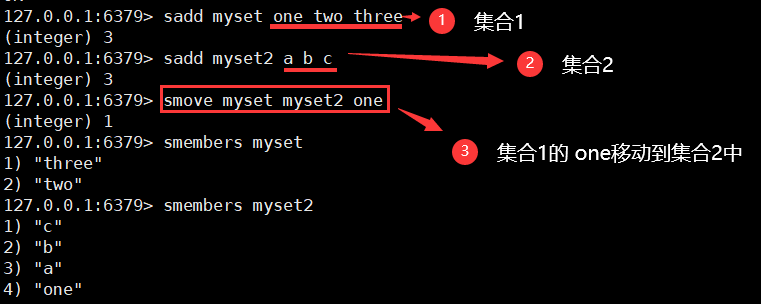
7. Move collection members to other collections
Smove source destination member
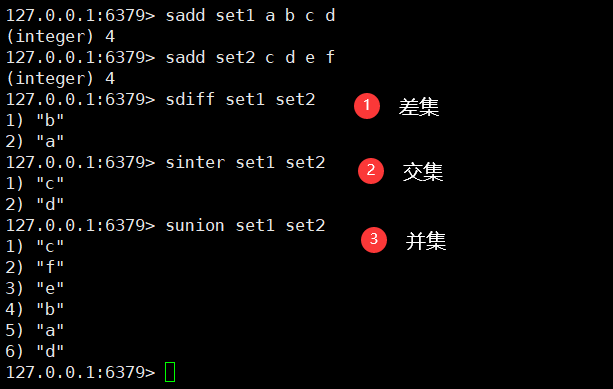
8. Digital collection class:
- Difference set sdiff key1, key2
- Intersection (common friend) sinter key1, key2
- Union sunion key1, key2
Hash (hash)
Key Map or key - < K, V >, value is a Map
The essence of hash is no different from hash, but value becomes a Map
User information storage, frequently changing information, suitable for object storage
1. Simply store and obtain maps
hset key field value [k1 v1 [k2 v2 ...]]
hget key field


2. Get all Map fields and values
hgetall key
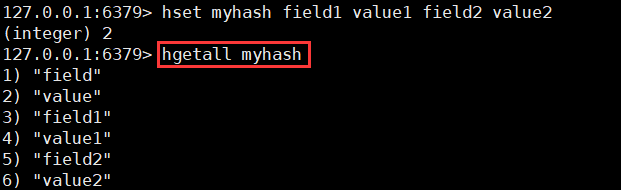
3. Delete the fields in the Map
hdel key field
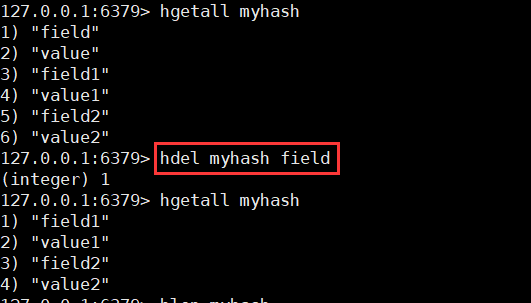
4. Check whether a field exists in the Map
hexists key field

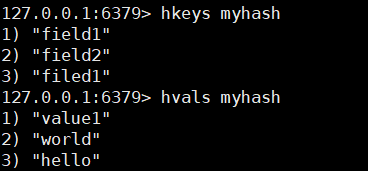
5. Obtain all fields or the corresponding values of all fields
hkeys key / / the key here is the Map name
hvals key
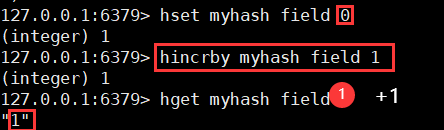
6. Increment i++
hincrby key field value
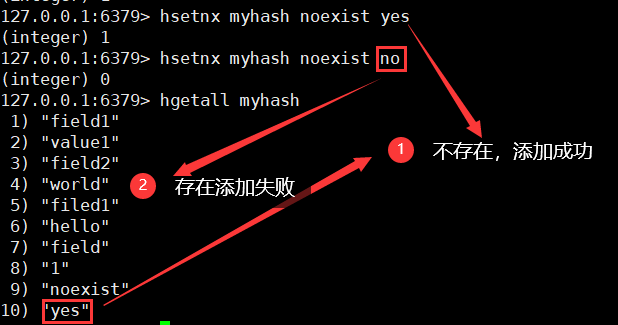
7. If it does not exist, it will be added successfully
Hsetnx key field value / / if the field does not exist in the map, add the value. Otherwise, do not change it
8. Suitable for storage objects

Zset (ordered set)
A value (the value used for sorting) is added to the Set
Store class grade sheet, payroll sorting,
Ordinary message = 1, important message = 2, judgment with weight
Leaderboard application implementation
1. Add and get
zadd key n value
zrange key startIndex endIndex
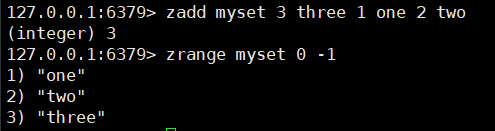
2. Sorting implementation (ascending and descending)
Zrangebyscore key - inf + inf [WithCores] / / ascending
zrange key 0 -1
Zrevrangebyscore key + inf - inf [WithCores] / / descending order
zrevrange key 0 -1
zrangebyscore key -inf any value n / / ascending + display interval [- inf, n]
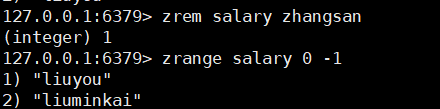
3. Remove the specified value
zrem key value
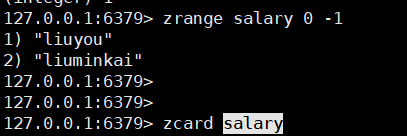
4. Length of set
zcard key
5. Specify the set length of the interval
zcount key startIndex endIndex

4, Three special data types
Geospatial
Location of friends, nearby people, taxi distance calculation
The bottom layer is Zset, that is, Geospatial can be operated with Zset commands
Redis3.2 I support it
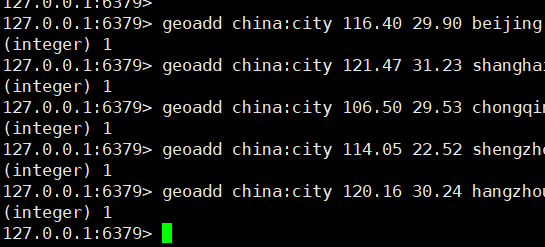
1. Add geographic location
- Cannot add
- Longitude: - 180 ~ 180 (degrees)
- Latitude: - 85.05112878 ~ 85.05112878 (degrees)
geoadd key longitude latitude name
2. Obtain the geographic location of the specified location
geopos key name

3. Return the distance between two given positions (linear distance)
- Company:
- m: Meters
- km: kilometers
- mi: miles
- ft: feet
geodist key

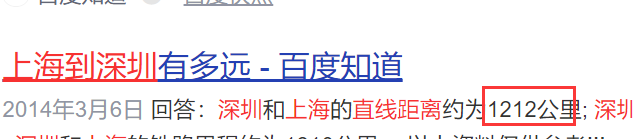
4. Take the given value as the radius and longitude and dimension as the center to find
- Nearby people (get the addresses of all nearby people (turn on positioning)) query through the radius
georadius key longitude latitude radius unit
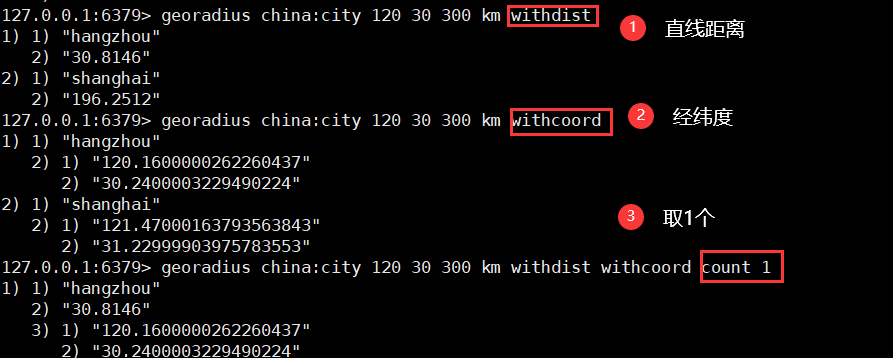
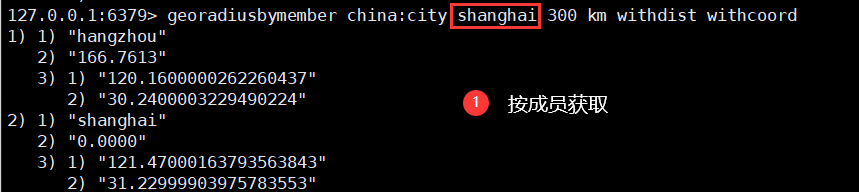
5. Take the given value as the radius and the member (city name) as the center to find
georadiusbymember key member name radius unit
6. Return the geohash representation of one or more location elements
- If the two strings are more similar, it means that the two places are closer
geohash key member 1 member 2

Hyperloglog
Algorithm of cardinality statistics
- advantage
- The occupied memory is fixed. The cardinality of 264 different elements only needs 12KB of memory. (in the case of big data, there is an error rate of 0.81%)
Cardinality: the number of elements in the set (de duplication first). For example, the cardinality of {1,2,2,3} is 3 (the set has 3 elements after de duplication)
UV of web page (a person visits a website many times, but still counts as a person)
The traditional implementation of UV: set saves the user's ID, and then counts the number of elements in the set as the standard judgment (this needs to save a large number of user IDs)
Redis2.8.9
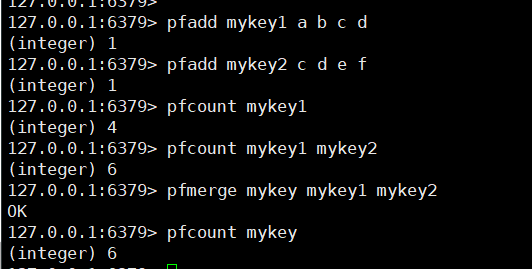
1. Test
Create a set of elements: pfadd key ele1 ele2 ele3
Count the cardinality of the corresponding key: pfcount key1 [key2...] / / multiple keys are the cardinality of the union of these keys
Merge: pfmerge destkey sourceKey1 sourceKey2 [sourceKey3...]
Bitmaps
Bit storage, bitmap (operation binary)
Statistics user information, active, inactive! Logged in, not logged in! Punch in, 365 punch in! (both states can be used)
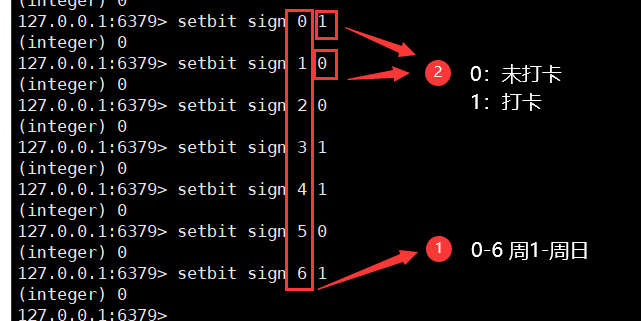
1. Case: clock in a week
A week passed
setbit key offset bit
Check the clock out of a single day
getbit key offset
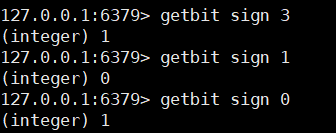
Count all clocking days
bitcount key

5, Business
Note: a single Redis command is atomic; But transactions do not guarantee atomicity!
Redis transactions do not have the concept of isolation level. All commands are not directly executed in the transaction, but only when the execution command is initiated
**Redis transaction essence: * * a set of commands. All commands in a transaction will be serialized separately. During transaction execution, they will be executed in order!
--- queue set set set implement ---
One time, sequential and exclusive! Execute some column commands
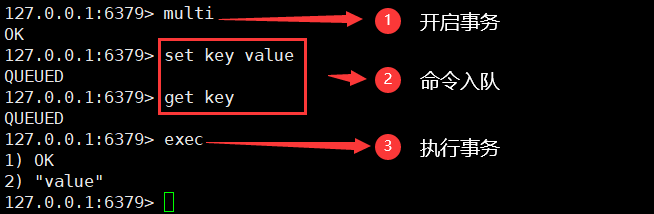
Redis transactions:
- Open transaction (multi)
- Order to join the team (other orders)
- Execute transaction (exec)
Execution of normal transactions
Cancel transaction
discard

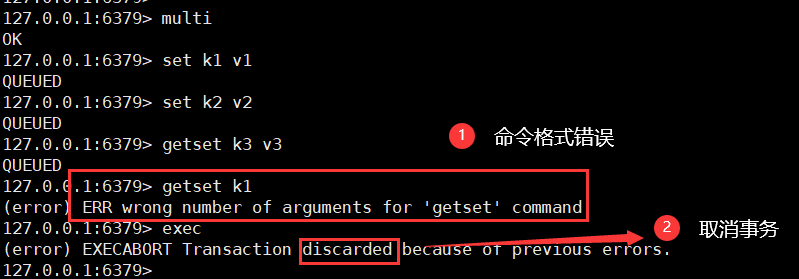
Abnormal execution
1. Compile time (wrong command)
The entire command queue is not executed
2. During operation
An error statement will throw an exception; Other statements run as usual
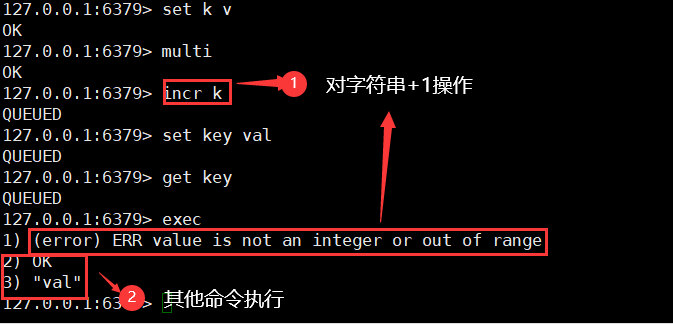
Monitor Watch (frequently asked in interview)
Optimistic lock: achieve second kill
- As the name suggests, I am optimistic that there will be no problem at any time, so I won't lock it! (when updating the data, judge whether anyone has modified the data during this period)
- Get version
- Compare version when updating
Pessimistic lock
- As the name suggests, I'm very pessimistic. I think there will be problems at any time. No matter what I do, I'll lock it!

Redis implements optimistic lock
Successful execution (single thread without interference)
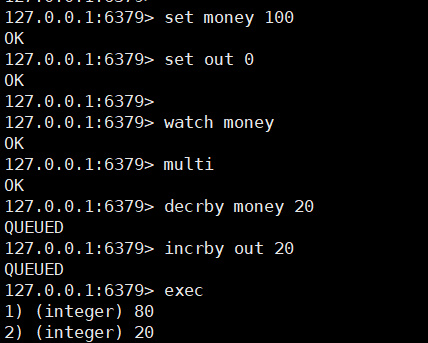
Test multithreading to modify the value, and use watch as an optimistic lock operation of redis
Demonstration‘
① Open two clients to simulate multithreading
② Spend 20 yuan on the left (but do not execute transactions), and then modify the value of money on the right
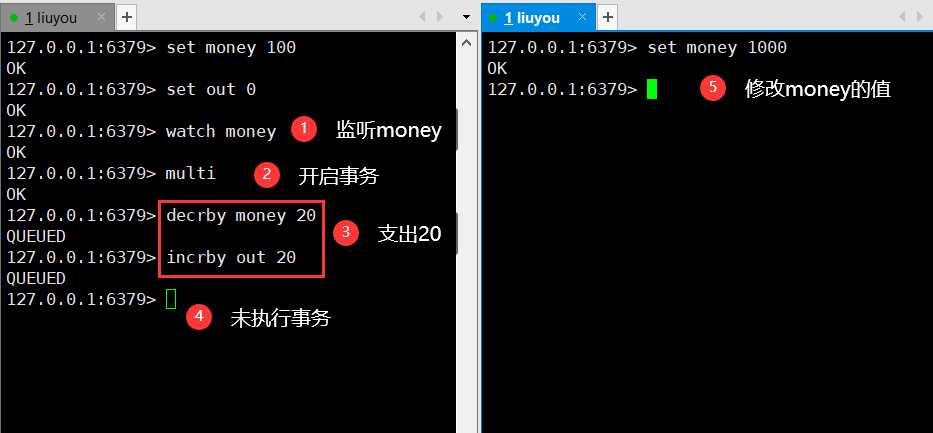
③ Execute the transaction on the left and find that the execution operation returns nil. Check money and out and find that the transaction has not been executed (it does have the effect of optimistic locking)
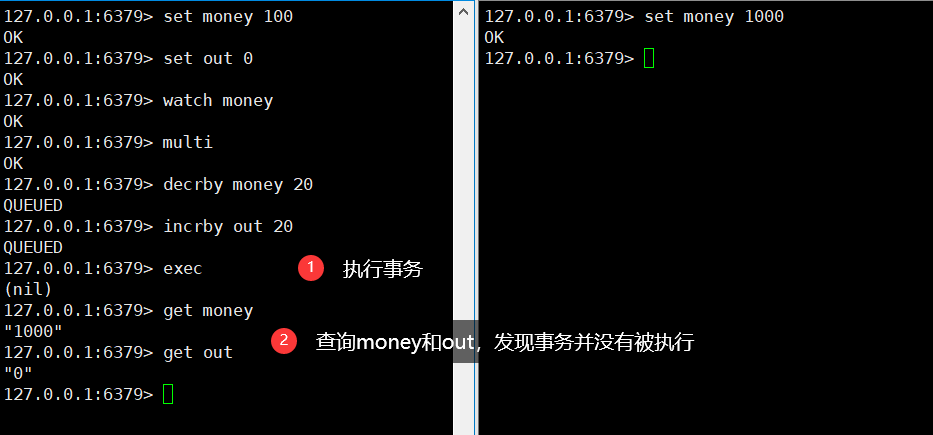
If the modification fails, just get the latest value (exec, unwatch and ` ` discard 'can clear all monitoring during connection)
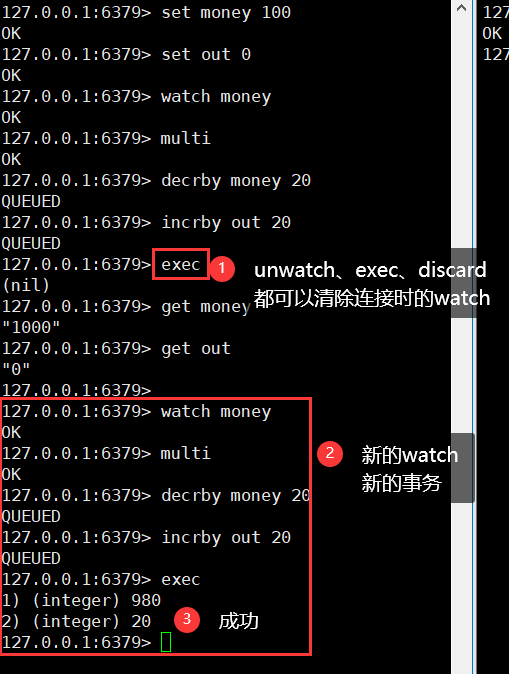
Summary
- Use Redis to implement optimistic locking (watch listens to a key and gets its latest value)
- When the transaction is committed, if the value of the key does not change, it will be executed successfully
- When committing a transaction, if the value of the key changes, it cannot be executed successfully
6, Jedis
1. What is Jedis
Jedis is a redis database operation client written in java. Through jedis, you can easily operate the redis database
2. Use
① New empty maven project
② Import dependency
<!--Import jedis package Redis client--><dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.3.0</version></dependency><!--Import fastjson--><dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.70</version></dependency>
③ Code
The following actions are required to use a remote connection: https://blog.csdn.net/weixin_43423864/article/details/109087670
- Connect to database
public class PingTest { public static void main(String[] args) { // 1. new Jedis object Jedis jedis = new Jedis("ip address", 6379)// If the password setting requires authentication, ignore the following statement jedis Auth ("password")/// All commands (Methods) of jedis are the previously learned command system out. println(jedis.ping());// Test connection}
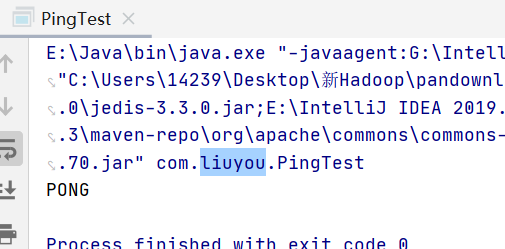
-
operation
// Connected Jedis jedis = new Jedis("ip address", 6379);jedis.auth("password")// Basic operation system out. Println ("empty data:" + jedis. Flush all()); System.out.println("judge whether the key (name) exists:" + jedis exists("name")); System.out.println("set value of Name:" + jedis.setnx("name", "liuyou"));System.out.println("set pwd value:" + jedis.setnx("pwd", "password")); System.out.println("print all keys:" + jedis.keys("*"));System.out.println("get the value of the name:" + jedis.get("name"));System.out.println("delete pwd:" + jedis.del("pwd"));System.out.println("Rename name to Username:" + jedis.rename("name", "username"));System.out.println("print all keys:" + jedis.keys("*"));System.out.println("return the number of keys in the current database:" + jedis.dbSize());Clear data: OK judge key(name)Is there: false set up name of value: 1 set up pwd of value: 1 Print all key: [pwd, name]Get the name of value: liuyou delete pwd: 1 rename name by username: OK Print all key: [username]Return to the current database key Number of: 1
-
Close connection
jedis.close()
- affair
// Connected Jedis jedis = new Jedis("IP address", 6379);jedis.auth("password"); JSONObject jsonObject = new JSONObject();jsonObject.put("hello","world");jsonObject.put("name","liuyou");jsonObject.put("pwd", "password"); String s = jsonObject.toJSONString();jedis.flushAll();/// Add monitoring watch / / jedis watch("user");// Open transaction multi = jedis multi(); Try {multi. Set ("user", s); / / other statements / / execute the transaction multi.exec();} catch (Exception e) {/ / cancel transaction multi. Discard(); e. printstacktrace();} Finally {system. Out. Println (jedis. Get ("user"); / / close the connection jedis.close();}
7, SpringBoot integration
In springboot 2 After X, the original jedis is replaced by lettuce
- jedis
- Direct connection and multi thread operation are not safe. If you want to avoid insecurity, use jedis pool connection pool! BIO
- lettuce
- With netty, instances can be shared in multiple threads * *, there is no thread insecurity problem, and thread data can be reduced. With high performance, NIO
① New springboot project
② RedisAutoConfiguration source code analysis

③ Integration test
1. Import dependency
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId></dependency>
2. Configure Redis (application.xml)
# Spring boot integrates redispring redis. host=xxxspring. redis. port=6379spring. redis. password=liuyou
3. Writing test classes
@SpringBootTestclass Redis02SpringbootApplicationTests { @Autowired RedisTemplate redisTemplate; @Test void contextLoads() { //redisTemplate // 1. Use redistemplate The data structure corresponding to opsforxxx operation / / 2 Redistemplate can be used for simple key operations, such as multi, move, watch and keys / / 3 You can use to obtain a connection and perform more operations through the connection. / / redisconnection connection = redistemplate getConnectionFactory(). getConnection(); // RedisZSetCommands redisZSetCommands = connection. zSetCommands(); // Only 1.0 is used here Demonstrate valueoperations STR = redistemplate opsForValue(); Str.set ("name", "Liu minkai"); System.out.println(str.get("name")); }}
However, there is a problem. Without serialization, the Chinese stored in Redis will be escaped, as shown in the following figure

Why did this happen? RedisTemplate serialization uses JDK by default, and we need to use JSON format
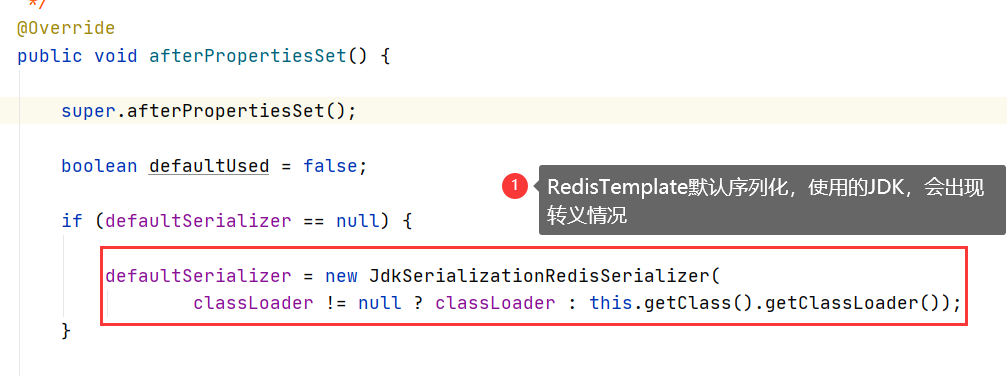
How to solve it? We need to write a custom Redis configuration class and a custom RedisTemplate
④ Customize RedisTemplate
@Configurationpublic class MyRedisConfig { // Change key: object = = > String to meet daily use. / / you have defined a redistemplate @ bean @ suppresswarnings ("all") public redistemplate < String, Object > redistemplate (redisconnectionfactory) {/ / for the convenience of our own development, we generally use < String, Object > redistemplate < String, Object > template = new redistemplate < String, Object > (); template.setconnectionfactory (factory) ; // Jackson serialization configuration jackson2jsonredisserializer jackson2jsonredisserializer = new jackson2jsonredisserializer (object. Class); ObjectMapper om = new ObjectMapper(); om. setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om. enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer. setObjectMapper(om); // Serialization of String stringredisserializer stringredisserializer = new stringredisserializer()// Key adopts the serialization method of String template setKeySerializer(stringRedisSerializer); // The key of hash also adopts the serialization method of String template setHashKeySerializer(stringRedisSerializer); // Value is serialized in Jackson template setValueSerializer(jackson2JsonRedisSerializer); // The value serialization method of hash adopts Jackson template setHashValueSerializer(jackson2JsonRedisSerializer); template. afterPropertiesSet(); return template; }}
After customizing RedisTemplate, start the test class of ③, and the results are displayed normally in Redis

⑤ RedisUtils tool class
We will not use the original RedisTemplate for daily development, but will encapsulate a RedisUtils tool class for ease of use
package com.liuyou.utils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.stereotype.Component;import org.springframework.util.CollectionUtils;import java.util.Map;import java.util.Set;import java.util.List;import java.util.concurrent.TimeUnit;@Componentpublic final class RedisUtils { @Autowired private RedisTemplate<String, Object> redisTemplate; // =============================common ====================================================================================================================== / * * specify cache expiration time * @ param key * @ param time (seconds) * / public Boolean expire (string return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * Get the expiration time according to the key * @ param key can't be null * @ return time (seconds) returns 0, which means it is permanently valid * / public long getexpire (string key) {return redistemplate.getexpire (key, timeunit. Seconds);} / * ** Judge whether the key exists * @ param key * @ return true exists false does not exist * / public Boolean Haskey (string key) {try {return redistemplate.haskey (key);} catch (Exception e) { e.printStackTrace(); return false; } } /** * Delete cache * @ param key can pass one or more * / @ suppresswarnings ("unchecked") public void del (string... Key) {if (key! = null & & key. Length > 0) {if (key. Length = = 1) {redistemplate. Delete (key [0]);} else { redisTemplate.delete(CollectionUtils.arrayToList(key)); } } } // ============================ String ==============================================================================================================================* Put * @ param key * @ param value value * @ return true success false failure * / public Boolean set (string key, object value) {try {redistemplate. Opsforvalue(). Set (key, value); return true;} catch (Exception e) { e.printStackTrace(); return false; } } /** * Normal cache put and set time * @ param key * @ param value value * @ param time time (seconds) time should be greater than 0. If time is less than or equal to 0, it will be set indefinitely * @ return true success false failure * / public Boolean set (string key, object value, long time) {try {if (time > 0) { redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS); } else { set(key, value); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * Increment * @ param key * @ param delta how much to increase (greater than 0) * / public long incr (string key, long delta) {if (delta < 0) {throw new runtimeException ("increment factor must be greater than 0");} return redisTemplate. opsForValue(). increment(key, delta); } /** * Decrement * @ param key * @ param delta how much to reduce (less than 0) * / public long Dec (string key, long delta) {if (delta < 0) {throw new runtimeException ("decrement factor must be greater than 0");} return redisTemplate. opsForValue(). increment(key, -delta); } // ================================ Map ===========================================================/ * * hashget * @ param key cannot be null * @ param item item cannot be null * / public object hget (string key, string item) {return redistemplate. Opsforhash(). Get (key, item);} / * ** Get all key values corresponding to hashKey * @ param key * @ return multiple key values corresponding to public map < object, Object > hmget (string key) {return redistemplate. Opsforhash(). Entries (key);} / * ** HashSet * @ param key * @ param map corresponds to multiple key values * / public Boolean hmset (string key, map < string, Object > map) {try {redistemplate. Opsforhash(). Putall (key, map); return true;} catch (Exception e) { e.printStackTrace(); return false; } } /** * HashSet and set time * @ param key * @ param map corresponds to multiple key values * @ param time (seconds) * @ return true success false failure * / public Boolean hmset (string key, map < string, Object > map, long time) {try {redistemplate. Opsforhash(). Putall (key, map); if (time > 0) {expire (key, time); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * Put data into a hash table. If it does not exist, create * * @ param key * @ param item * @ param value * @ return true success false failure * / public Boolean hset (string key, string item, object value) {try {redistemplate. Opsforhash(). Put (key, item, value); return true;} catch (Exception e) { e.printStackTrace(); return false; } } /** * Put data into a hash table. If it does not exist, create a * * @ param key * @ param item * @ param value * @ param time time (seconds). Note: if the existing hash table has time, The original time will be replaced here * @ return true success false failure * / public Boolean hset (string key, string item, object value, long time) {try {redistemplate. Opsforhash(). Put (key, item, value); if (time > 0) {expire (key, time);} return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * Delete the value in the hash table * * @ param key cannot be null * @ param item item can make multiple non null * / public void HDEL (string key, object... Item) {redistemplate. Opsforhash(). Delete (key, item);} / * ** Judge whether there is a value of this item in the hash table * * @ param key cannot be null * @ param item cannot be null * @ return true exists false does not exist * / public Boolean hashKey (string key, string item) {return redistemplate. Opsforhash(). Haskey (key, item);} / * ** Hash increment if it does not exist, it will create a new value and return it to * * @ param key * @ param item item * @ param by how much to increase (greater than 0) * / public double hincr (string key, string item, double by) {return redistemplate. Opsforhash(). Increment (key, item, by);} / * ** Hash decrement * * @ param key key * @ param item item * @ param by to decrement (less than 0) * / public double hdecr (string key, string item, double by) {return redistemplate. Opsforhash(). Increment (key, item, - by);} / /============================ Set ============================================================================================================ / * * get all the values in the set according to the key * @ param key catch (Exception e) { e.printStackTrace(); return null; } } /** * Query from a set according to value to see if there is a * * @ param key * @ param value * @ return true or false * / public Boolean shaskey (string key, object value) {try {return redistemplate. Opsforset(). Ismember (key, value);} catch (Exception e) { e.printStackTrace(); return false; } } /** * Put the data into the set cache * * @ param key * @ param values the value can be multiple * @ return the number of successes * / public long SSET (string key, object... Values) {try {return redistemplate. Opsforset(). Add (key, values);} catch (Exception e) { e.printStackTrace(); return 0; } } /** * Put the set data into the cache * * @ param key * @ param time (seconds) * @ param values can be multiple values * @ return the number of successes * / public long ssetandtime (string key, long time, object... Values) {try {long count = redistemplate. Opsforset(). Add (key, values); if (time > 0) { expire(key, time); } return count; } catch (Exception e) { e.printStackTrace(); return 0; } } /** * Get the length of the set cache * * @ param key * / public long sgetsetsize (string key) {try {return redistemplate. Opsforset(). Size (key);} catch (Exception e) { e.printStackTrace(); return 0; } } /** * Remove the * * @ param key key with value * @ param values value can be multiple * @ return the number of removed * / public long setremove (string key, object... Values) {try {long count = redistemplate. Opsforset(). Remove (key, values); return count;} catch (Exception e) { e.printStackTrace(); return 0; } } // =============================== List ===================================================================================/ * * get the contents of the list cache * * @ param key * @ param start * @ param end end end 0 to - 1 represent all values * / public list < Object > lget (string key, long start, long end) {try {return redistemplate. Opsforlist(). Range (key, start, end catch (Exception e) { e.printStackTrace(); return null; } } /** * Get the length of the list cache * * @ param key * / public long lgetlistsize (string key) {try {return redistemplate. Opsforlist(). Size (key);} catch (Exception e) { e.printStackTrace(); return 0; } } /** * Get the value in the list through the index * * @ param key key * @ param index index > = 0, 0 header, 1 second element, and so on; When index < 0, - 1, footer, - 2, the penultimate element, and so on * / public object lgetindex (string key, long index) {try {return redistemplate. Opsforlist(). Index (key, index);
Use this tool class to inject @ Autowired directly
Advanced
Learn all the previous contents = = > redis Basics
Advanced operations are behind
8, Redis Conf detailed explanation
We usually start Redis through Redis Conf startup (I started with 6379.conf of the installation service earlier)
Therefore, we must understand Redis Only by configuring conf can Redis be better understood and used
Company
- Case insensitive
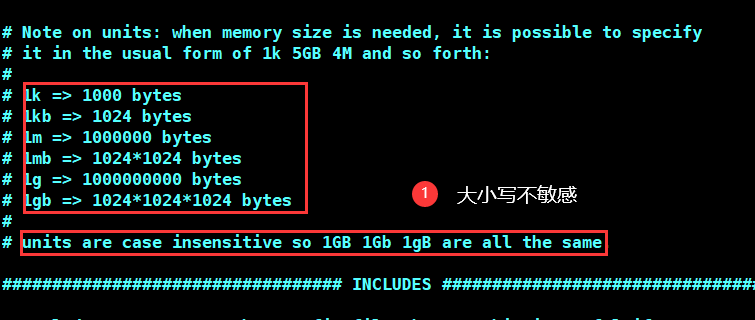
contain
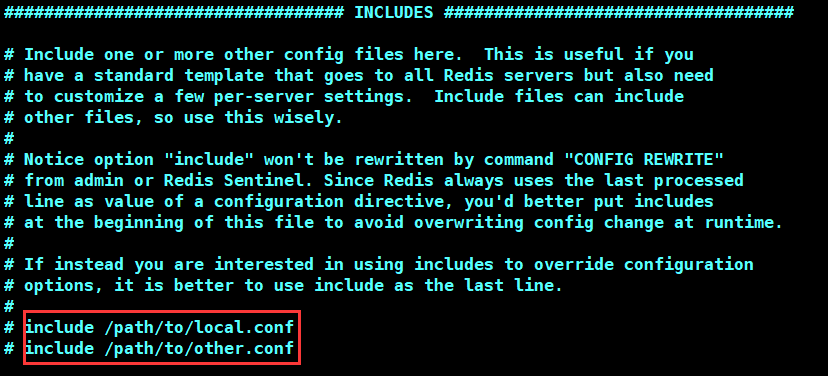
-
Multiple configuration files can be included (that is, these files are imported into the main configuration file Redis.conf)
network
bind 0.0.0.0 # IP(Default 127.0.0.1)protected-mode no # Protected mode (default) yes)port 6379 # Port settings (default 6379)
currency
daemonize yes # Run as a daemon, i.e. in the background (default) no)pidfile /var/run/redis_6379.pid # If the background runs, you must specify one pid file# journal# Specify the server verbosity level.# This can be one of:# debug (A lot of information, Used in the test or development phase)# verbose (Much less useful information, but not as confusing as the debug level)# notice (It is lengthy and you may want to use it in a production environment)# warning (Only very important/Key messages were recorded)loglevel notice # default noticelogfile "" # File location name of the log databases 16 # Number of databases (default 16) always-show-logo yes # Enable logo (yes by default)
snapshot
Persistence: how many operations are performed within a specified time and will be persisted to a file (. rdb,. aof)
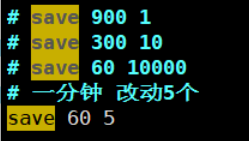
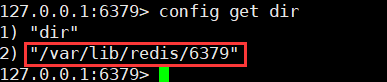
save 900 1 # 900 Seconds (15 minutes), if there is at least 1 Key After modification, we perform the persistence operation save 300 10 # 300 Seconds (5 minutes), if there are at least 10 Key After modification, we perform the persistence operation save 60 10000 # 60 Seconds (1 minute), if there are at least 10000 Key After modification, we perform the persistence operation stop-writes-on-bgsave-error yes # If persistence fails, do you need to continue working (default) yes)rdbcompression yes # Whether to compress rdb File (default) yes),Will consume some CPU resources rdbchecksum yes # preservation rdb Error check and verification when the file is dir ./ # Directory where rdb files are saved
Master slave REPLICATION
SECURITY
requirepass Your password # Set the password (it is annotated by default, and you need to unlock the annotation by yourself)

Of course, it can be configured through the command line (temporary, service restart failure)
Client restrictions
# maxclients 10000 # Limit up to 10000 client access (default comment)
memory management
# maxmemory <bytes> # Maximum memory setting (default comment)# maxmemory-policy noeviction # Processing policy after the memory limit is reached (default) noeviction) # 1,volatile-lru: Only for those with expiration time set key conduct LRU((default) # 2,allkeys-lru : delete lru Algorithmic key # 3,volatile-random: Random deletion is about to expire key # 4,allkeys-random: Random deletion # 5,volatile-ttl : Delete expiring # 6. noeviction: never expires, return error
APPEND ONLY MODE (AOF configuration)
appendonly no # The default is not on aof Yes, used by default rdb Mode persistence appendfilename "appendonly.aof" # Persistent file name# appendfsync always # Each modification will be synchronized to reduce the performance consumption appendfsync everysec # Perform synchronization once per second, and you may lose this 1 second of data# appendfsync no # Out of sync, the operating system synchronizes the data itself, which is the fastest
9, Redis persistence (key)
Redis is an in memory database. The database status is powered off and lost. Therefore, redis provides persistence function (memory data is written to disk)
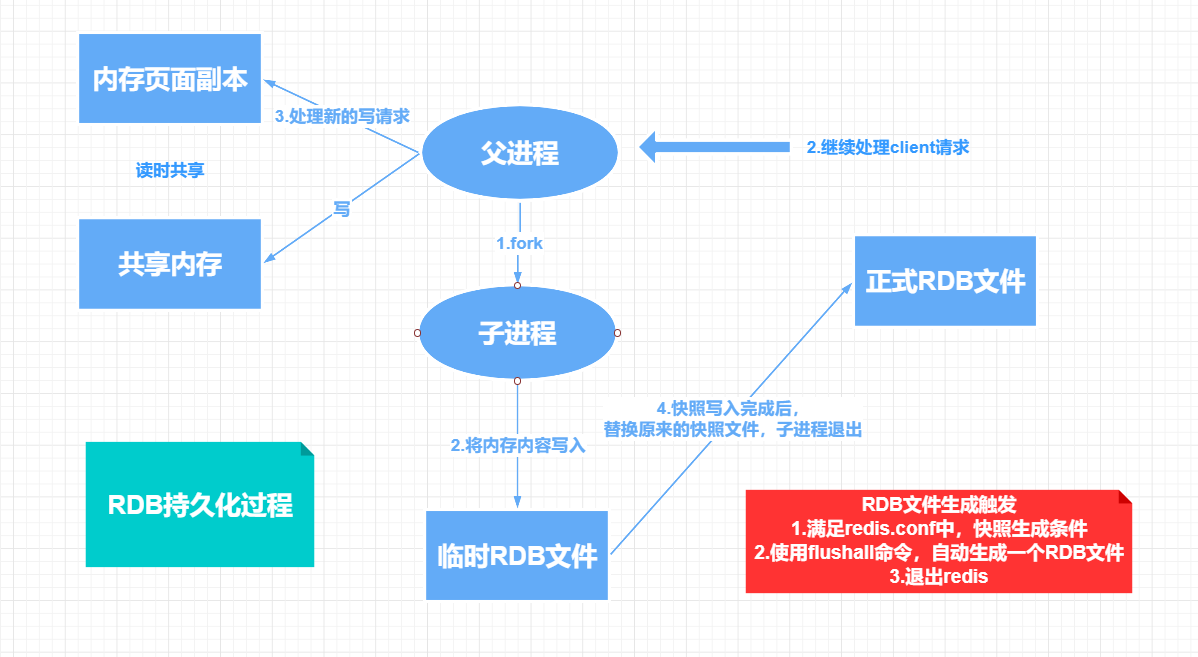
1,RDB(Redis DataBase)
RDB persistence refers to writing the data set snapshot in memory to disk within a specified time interval. The actual operation process is a sub process of fork. First write the data set to a temporary file, and then replace the previous file after successful writing, and store it with binary compression. Save the file format dump rdb
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG gthbbtx4-1642752175457)( https://www.kuangstudy.com/bbs/2020-11-2-Redis%E8%AF%A6%E7%BB%86%E7%AC%94%E8%AE%B0.assets/image -20201117102650803. png)]
Set RDB file saving conditions
Restart service
systemctl restart redis_6379
Result test
1. View the directory where rdb files are stored

2. Delete the existing dump RDB file
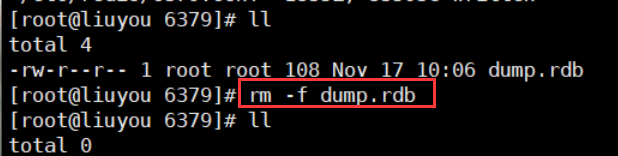
3. Add 5 key s
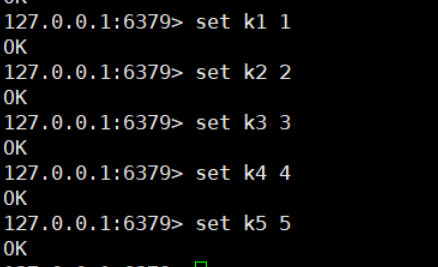

RDB file generation trigger mechanism
1. Meet redis In conf, snapshot save generates conditions
2. Use the flush command to automatically generate an RDB file
3. Exit redis
RDB file recovery
Just put the RDB file into the Redis startup directory, and Redis will load it automatically
Advantages and disadvantages
- advantage:
- Suitable for large-scale data recovery!
- Low requirements for data integrity
- Disadvantages:
- Process operation requiring a certain time interval; If redis goes down unexpectedly, there will be no data for the last modification
- The fork process takes up a certain amount of space
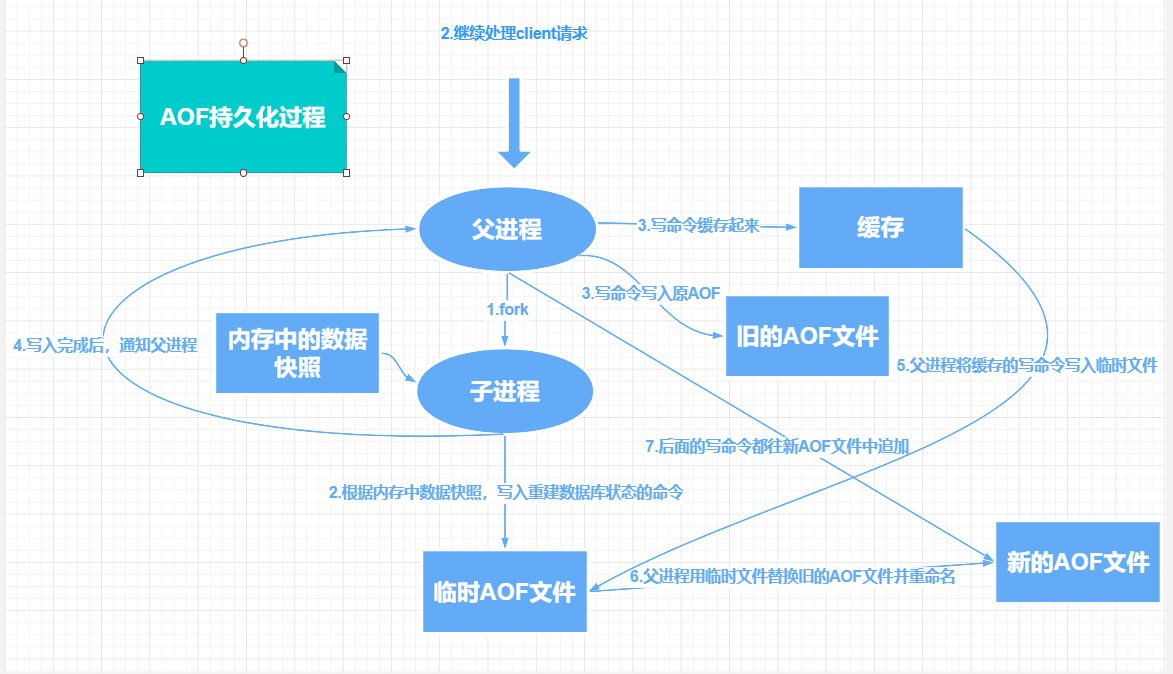
2,AOF(Append Only File)
AOF persistence records every write and delete operation processed by the server in the form of log. The query operation will not be recorded. Only files can be added, and files cannot be overwritten. Record in the form of text. You can open the file to see the detailed operation record.
Save the file format appendonly aof
aof is not enabled by default and needs to be enabled in the configuration file

After restarting redis, append only Automatic generation of AOF files
The client performs some operations
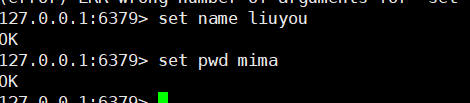
appendonly.aof file content, recorded in log form
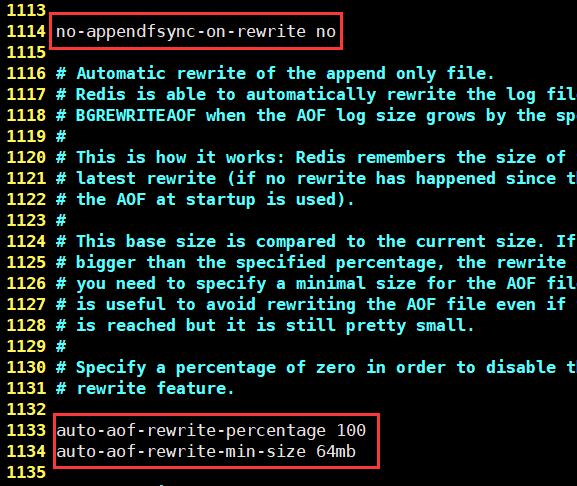
Rewriting regulation
If the aof file is larger than 64mb, we will fork a new process to rewrite our file (clear the previous 64mb)
mismatch repair
If there is an error in the aof file, redis cannot be started. You can use the official redis check aof -- fix aof file to repair it
Advantages and disadvantages
- advantage
- Every modification is synchronized, and the file integrity will be better
- Syncing once per second may cause one second of data loss
- shortcoming
- Compared with data files, aof is much larger than rdb, and the repair speed is slower than rdb
- aof runs slower than rdb (append, frequent IO operations)
extend

10, Redis publish and subscribe
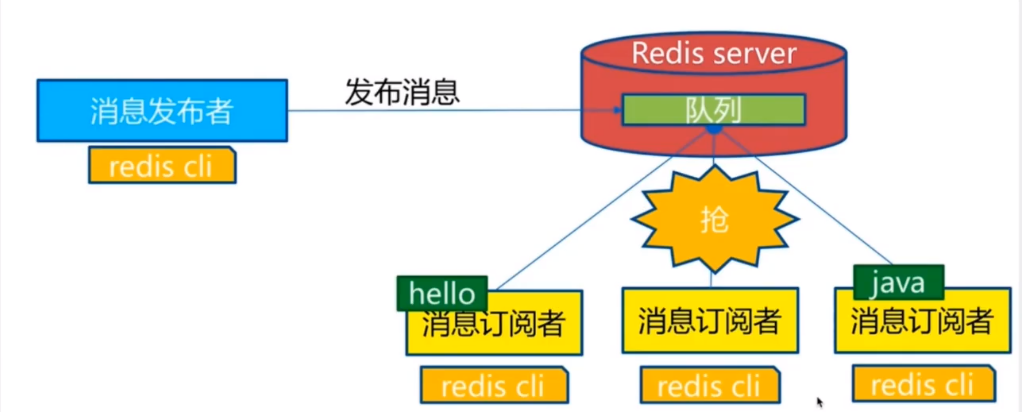
Redis publish / subscribe (pub/sub) is a message communication mode: the sender (pub) sends messages and the subscriber (sub) receives messages. Wechat, microblog, attention system!
Redis client can subscribe to any number of channels
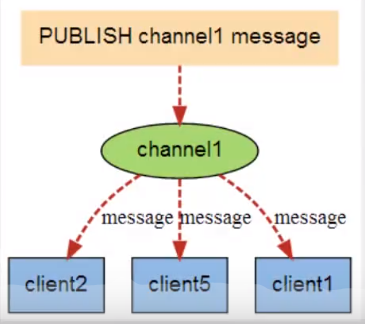
Subscribe / publish message diagram:
The following figure shows the relationship between channel 1 and the three clients subscribing to this channel - client2, client5 and client1:
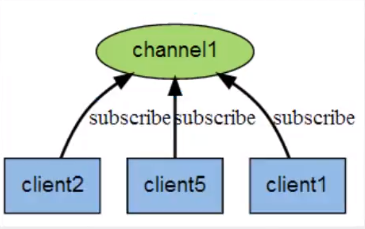
When a new message is sent to channel 1 through the PUBLISH command, the message will be sent to the three clients subscribing to it:
command
These commands are widely used to build instant messaging applications, such as chat room, real-time broadcast, real-time reminder and so on.
| command | describe |
|---|---|
| PSUBSCRIBE pattern [pattern..] | Subscribe to one or more channels that match the given pattern. |
| PUNSUBSCRIBE pattern [pattern..] | Unsubscribe from one or more channels that match the given mode. |
| PUBSUB subcommand [argument[argument]] | View subscription and publishing system status. |
| PUBLISH channel message | Publish messages to specified channels |
| SUBSCRIBE channel [channel..] | Subscribe to a given channel or channels. |
| SUBSCRIBE channel [channel..] | Unsubscribe from one or more channels |
test
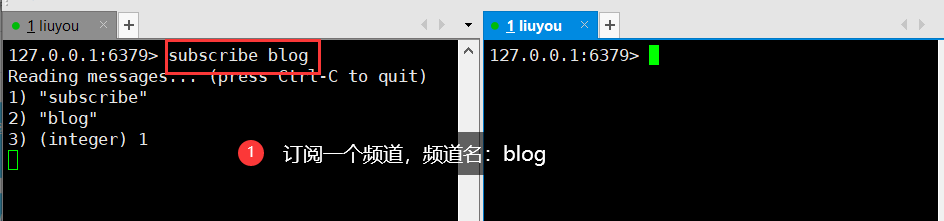
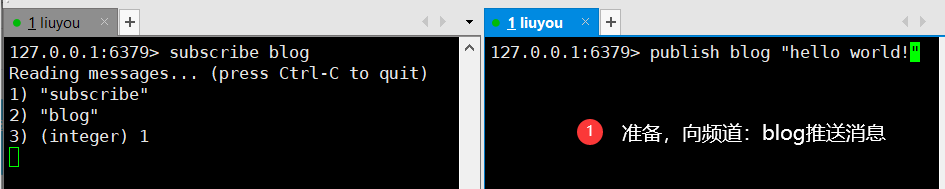
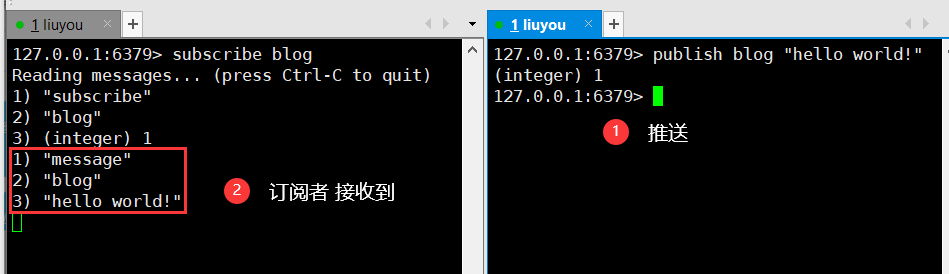
127.0.0.1:6379> subscribe blog # Subscribed Channels Reading messages... (press Ctrl-C to quit) # Waiting for push message 1) "subscribe"2) "blog"3) (integer) 11) "message" # Message 2) "blog" # Message from channel 3) "hello world!" # Message content 127.0.0.1:6379> publish blog "hello world!" # Send message to channel (integer) 1127.0.0.1:6379 >
principle

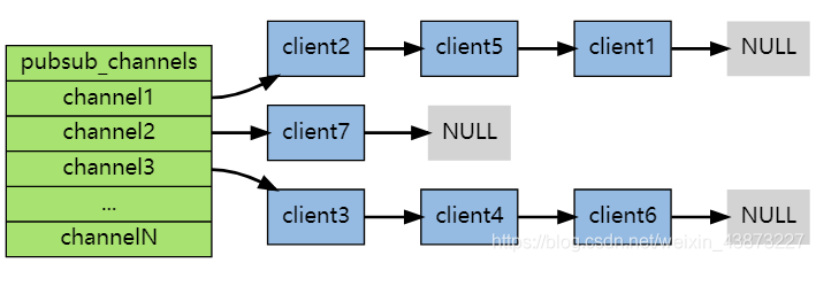
Each Redis server process maintains a Redis. Net that represents the server status H / redisserver structure, PubSub of structure_ The channels attribute is a dictionary, which is used to save the information of subscribed channels. The key of the dictionary is the channel being subscribed, and the value of the dictionary is a linked list, which stores all clients subscribing to this channel.
When a client subscribes, it is linked to the end of the linked list of the corresponding channel. Unsubscribing is to remove the client node from the linked list.
Usage scenario:
- Real time messaging system!
- Live chat! (the channel acts as a chat room and echo the message to everyone)
- You can subscribe and pay attention to the system
In complex situations, use professional message middleware
Disadvantages of subscription
- If a client subscribes to a channel but does not read messages fast enough, the continuous backlog of messages will make the volume of redis output buffer become larger and larger, which may slow down the speed of redis itself or even crash directly.
- This is related to the reliability of data transmission. If the subscriber is disconnected, he will lose all messages published by the publisher during the short term.
11, Master slave replication
concept
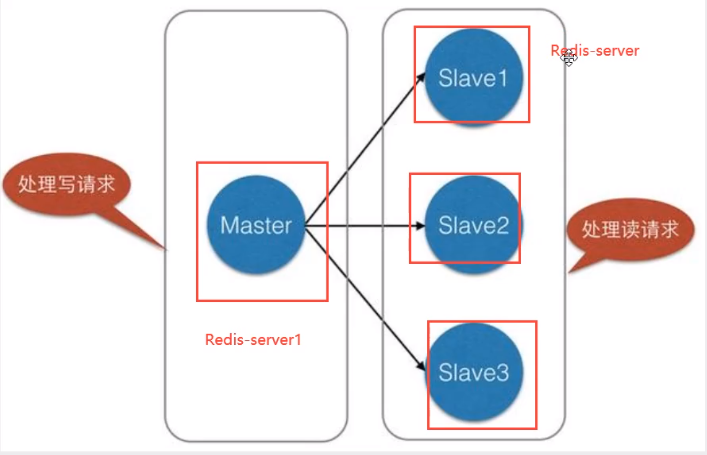
Master slave replication refers to copying data from one Redis server to other Redis servers. The former is called Master/Leader and the latter is called Slave/Follower. Data replication is one-way! It can only be copied from the master node to the slave node (the master node is dominated by writing and the slave node is dominated by reading).
Main functions of master-slave replication
- Data redundancy: master-slave replication realizes the hot backup of data, which is a way of data redundancy other than persistence.
- Fault recovery: when the master node fails, the slave node can temporarily replace the master node to provide services, which is a way of service redundancy
- Load balancing: on the basis of master-slave replication, with read-write separation, the master node performs write operations and the slave node performs read operations to share the load of the server; Especially in the scenario of more reads and less writes, multiple slave nodes share the load to improve the concurrency.
- High availability cornerstone: master-slave replication is also the basis for sentinel and cluster implementation.
Generally speaking, to apply Redis to engineering projects, it is absolutely impossible to use only one Redis (to avoid downtime, one master and two slaves). The reasons are as follows:
- Structurally, a single Redis server will have a single point of failure, and one server needs to handle all request loads, which is under great pressure
- In terms of capacity, the memory capacity of a single Redis server is limited. Even if the memory capacity of a Redis server is 256G, all memory can not be used as Redis storage memory. Generally speaking, the maximum memory used by a single server does not exceed 20G.
As long as it is impossible to use a single machine (with bottlenecks) in the company, you must configure clusters and use master-slave replication
Environment configuration
You only need to configure the slave library, not the master library
To view master-slave replication information:
By default, each Redis server is the master node
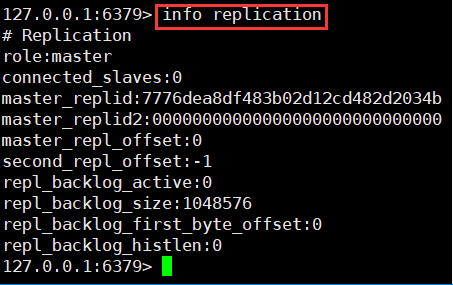
127.0.0.1:6379> info replication# Replicationrole:master # Master node connected_slaves:0 # No master from node_ replid:7776dea8df483b02d12cd482d2034ba55ec7dab0master_ replid2:0000000000000000000000000000000000000000master_ repl_ offset:0second_ repl_ offset:-1repl_ backlog_ active:0repl_ backlog_ size:1048576repl_ backlog_ first_ byte_ offset:0repl_ backlog_ histlen:0
1. Copy the profile Redis Conf to Redis installation directory
2. Copy 3 more files from this file
Host: redis_6379.conf
From: redis_6380.conf,redis_6381.conf
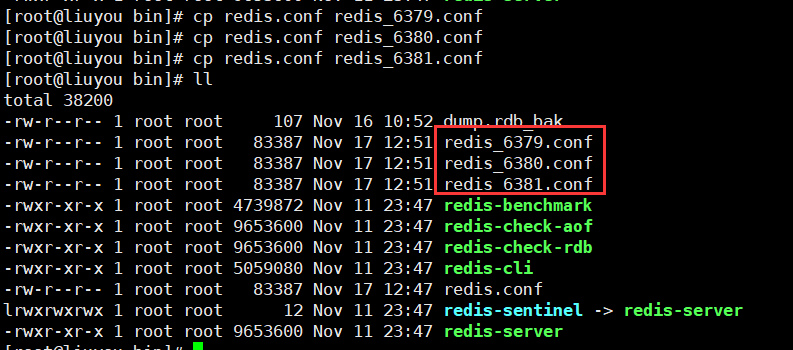
3. Modify master profile
Since the default running pid of the port and background is 6379, it will not be changed


4. Modify slave profile
Next, redis_ Take 6380.conf as an example, redis_6381.conf the same is true
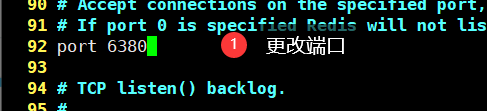

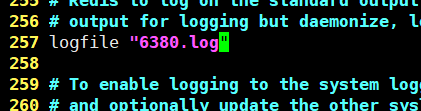
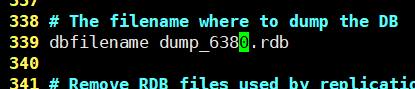
Profile modification information
- Port (92 rows)
- pid process name (244 lines)
- Log file name (line 257)
- rdb file name (339 lines)
5. Start service (single machine multi service)
cd /usr/local/bin # Enter the directory where the configuration file is located[root@liuyou bin]# redis-server redis_6379.conf[root@liuyou bin]# redis-server redis_6380.conf[root@liuyou bin]# redis-server redis_6381.conf[root@liuyou bin]# ps -ef | grep redis # View startup status root 2862 1 0 13:13? 00:00:00 redis-server 0.0.0.0:6379root 2868 1 0 13:13 ? 00:00:00 redis-server 0.0.0.0:6380root 2874 1 0 13:13 ? 00:00:00 redis-server 0.0.0.0:6381root 2880 2393 0 13:13 pts/0 00:00:00 grep --color=auto redis
6. Login client
① Open four windows, the first three for master-slave replication and the last one for testing
② Login (note port)
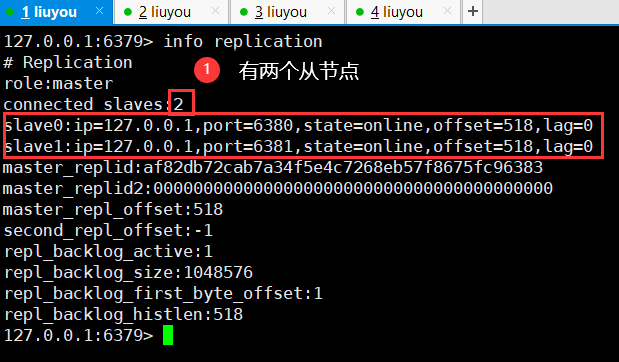
7. One master and two slaves
By default, each Redis server is the master node
Generally, only the slave is configured
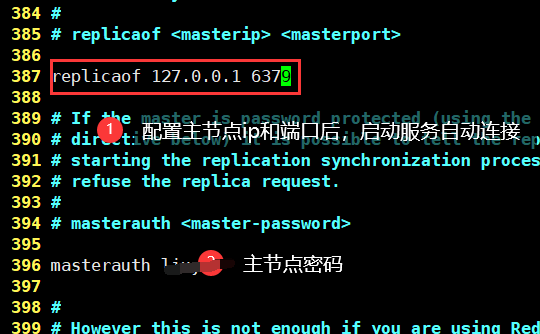
If you have a password, you need to configure it from the configuration file, which will be explained later
Next, take window 3 (port 6381) as an example, and window 2 is the same
Use slaveof to specify the primary node ip and port (temporary configuration)
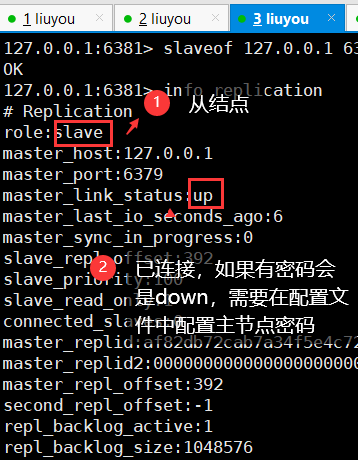
View master node and master-slave replication information
Password configuration (+ permanent configuration)
Restart service after configuration
test
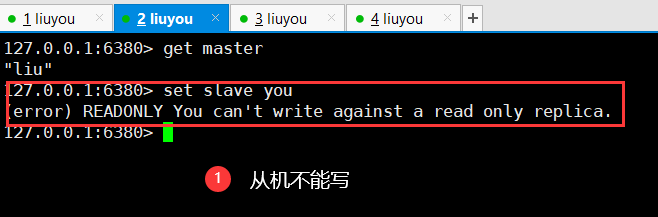
Redis only allows the host to write and the slave to read
Host write
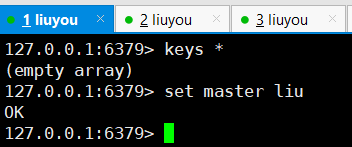
Read from machine
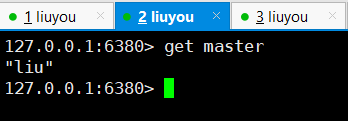
Slave cannot write
When the host is disconnected, the slave is still connected to the host, but there is no write operation. If the slave recovers to normal halfway, the slave can still obtain the content written by the host
If the command line configuration is used, the slave will become the master when it is restarted (the content of the previous host can be obtained only when it becomes the slave)
When the slave is disconnected, the host continues to write new content. As long as the slave is restored, the new content written by the host can be obtained
Replication principle
After Slave is successfully started and connected to the Master, it will send a sync command
After receiving the command, the Master starts the background save process and collects all the received commands for modifying the dataset. After the background process is executed, the Master will transfer the whole data file to Slave and complete a complete synchronization
Full copy: after receiving the database file data, the Slave service saves it and loads it into memory
Incremental replication: the Master continues to transmit all new collection and modification commands to Slave in turn to complete synchronization
However, as long as the Master is reconnected, a full synchronization (full replication) will be performed automatically.
8. Caterpillar configuration (master-slave)
The previous M connects to the next S (you can see an implementation of master-slave replication)
Configuration: change the host of window 3 configured above to window 2
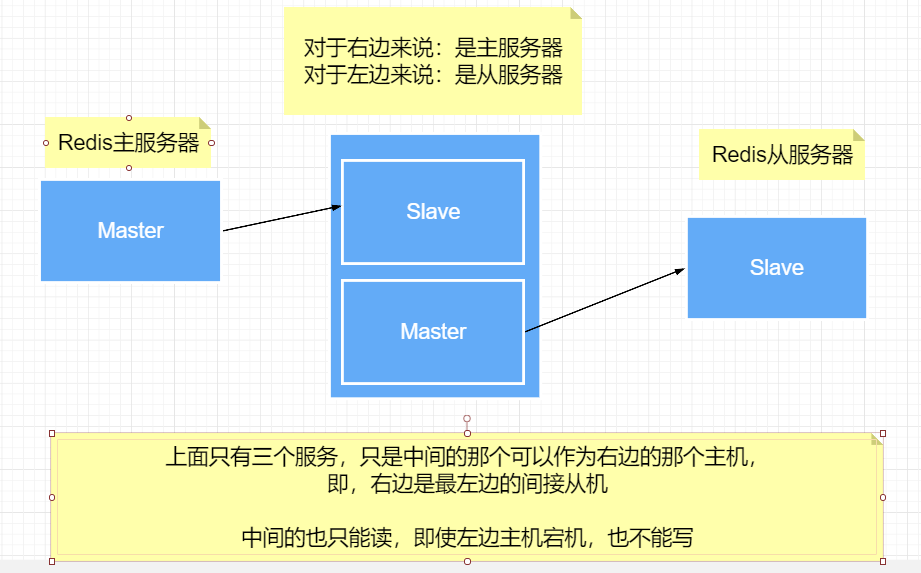
9. Manually configuring hosts for downtime
slaveof no one # If the master is disconnected, the slave can use this command to turn itself into the master and connect other nodes to the node
If the host comes, it is not connected to the slave.
12, Sentinel mode
Automatically elect the Redis master server (if the master server is down)
On redis2 Before 8, the host was manually configured (which will lead to service unavailability for a period of time)
Redis2. After 8, redis provided Sentinel to solve this problem (when the host goes down, a new host will be automatically selected from the host according to the vote)
Sentinel mode is a special mode. Firstly, Redis provides sentinel commands. Sentinel is an independent process and will run independently * *. The principle is that the sentinel monitors multiple running Redis instances by sending commands and waiting for a response from the Redis server**
Single sentinel mode
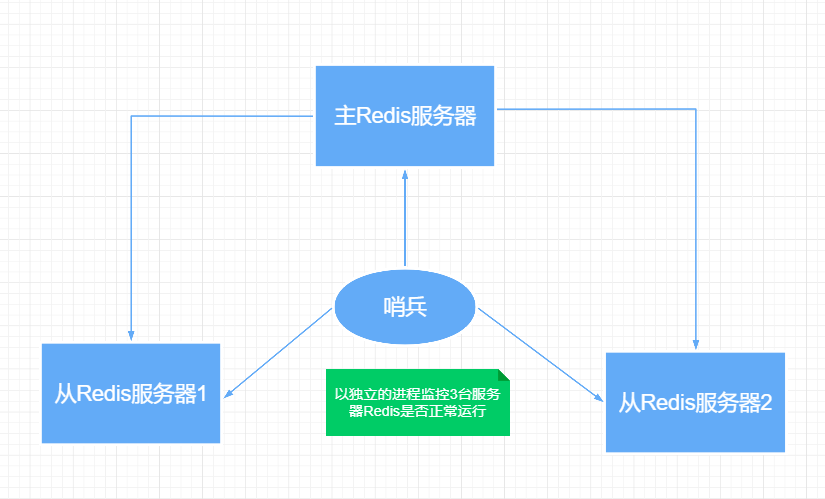
The role of sentinels:
- Send a command to let Redis server return to monitor its running status, including master server and slave server
- When the sentinel detects that the master is down, it will automatically switch the slave to the master, and then notify other slave servers through publish subscribe mode to modify the configuration file and let them switch hosts
Multi sentry mode
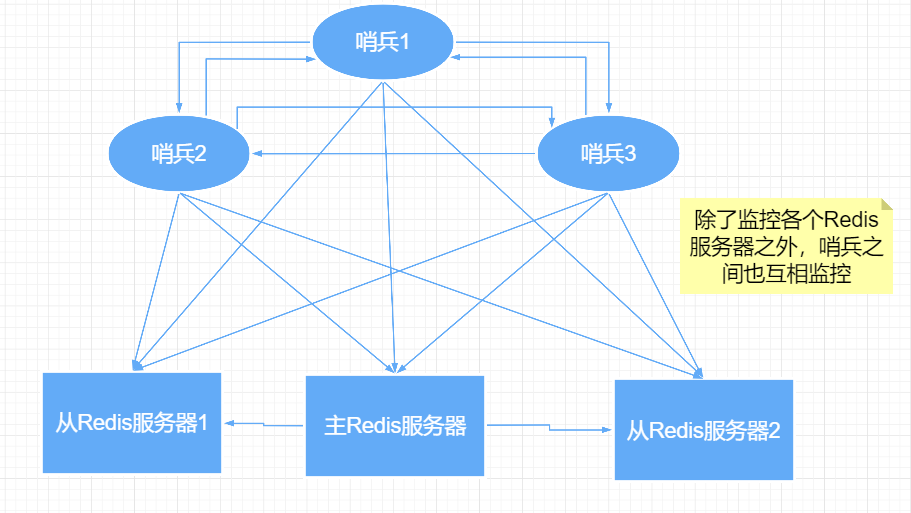
Assuming that the main server is down, sentry 1 detects this result first, and the system will not immediately fail over. Sentry 1 subjectively thinks that the main server is unavailable. This phenomenon is called subjective offline.
When other sentinels also detect that the primary server is unavailable and reaches a certain number, a vote will be held between sentinels. The voting result is initiated by a sentinel for failover failover.
After the switch is successful, each sentinel will switch its monitored from the server to the host through the publish and subscribe mode. This time is called objective offline
Test (one master, two slave, single sentry)
1. Configure sentinel configuration file (file name sentinel.conf)
The file name cannot be written wrong. The following is the file content (of course, this file needs to be created by yourself)
# sentinel monitor Monitored name host port 1 # 1 indicates that the host is down, and the slave votes to elect sentinel monitor myredis 127.0.0.1 6379 1
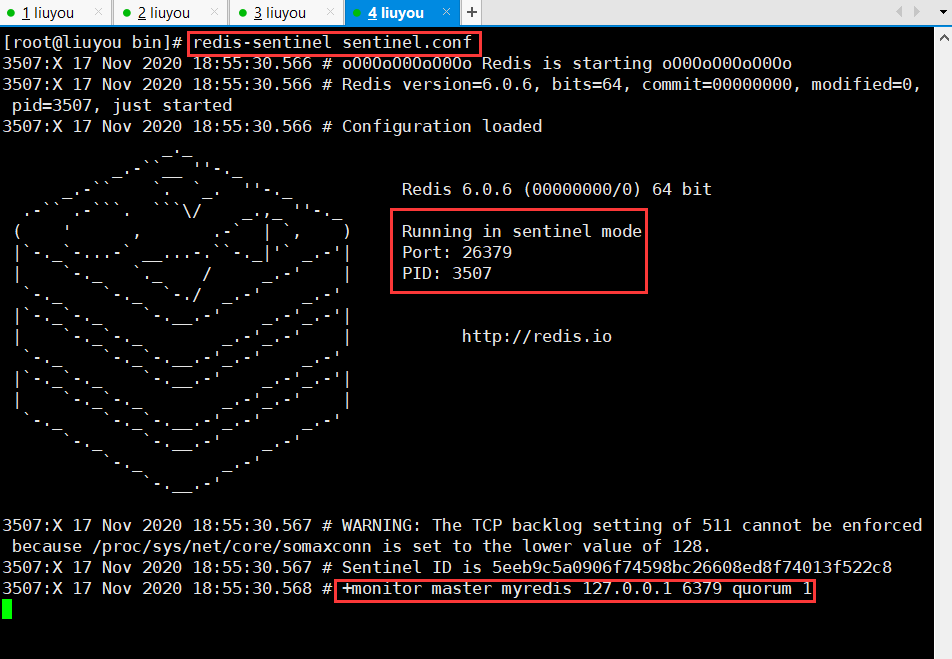
2. Start sentinel mode
If the password is monitored, it needs to be in sentinel Conf configuration file, append
# Sentinel auth pass monitored host name < password > sentinel auth pass myredis < password >
redis-sentinel sentinel.conf
3. Shut down the host and test the election
① Host shutdown
② Sentry details
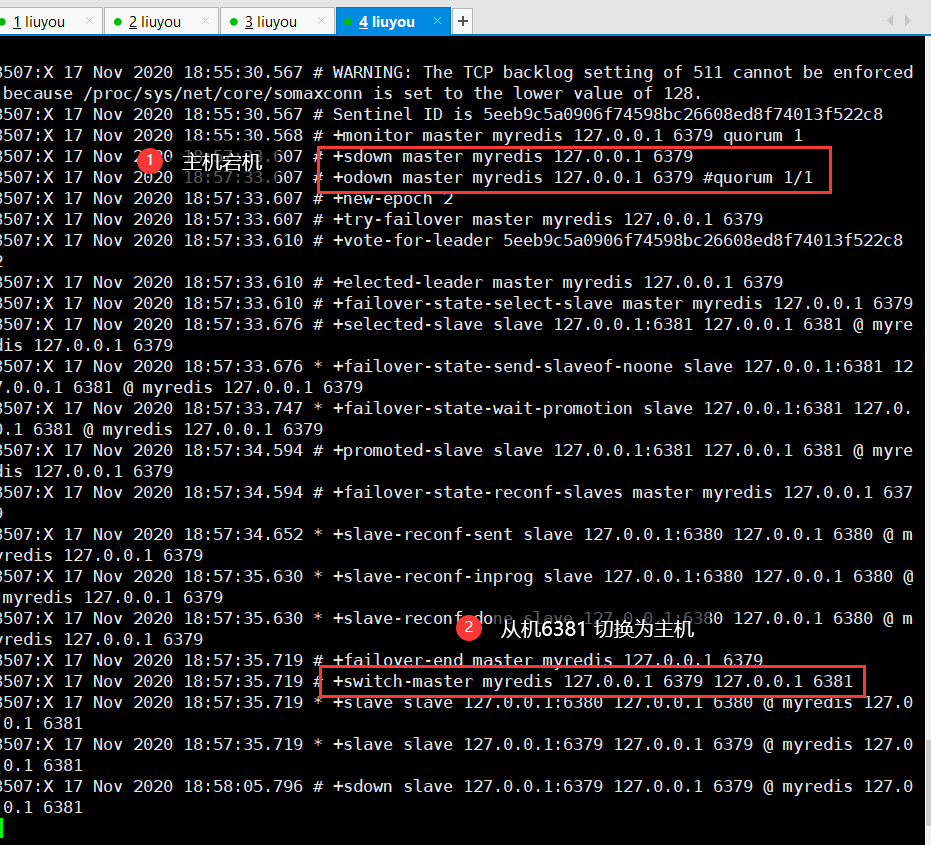
③ Check window 3 (port 6381)
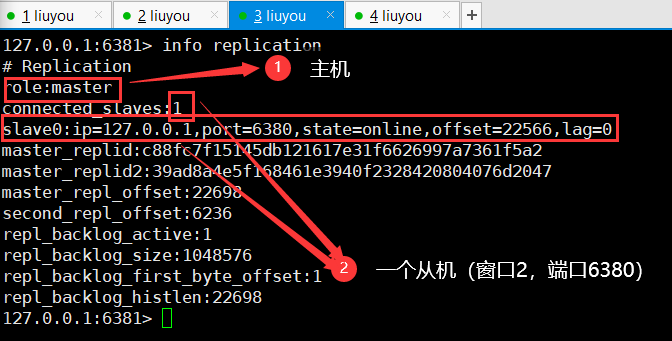
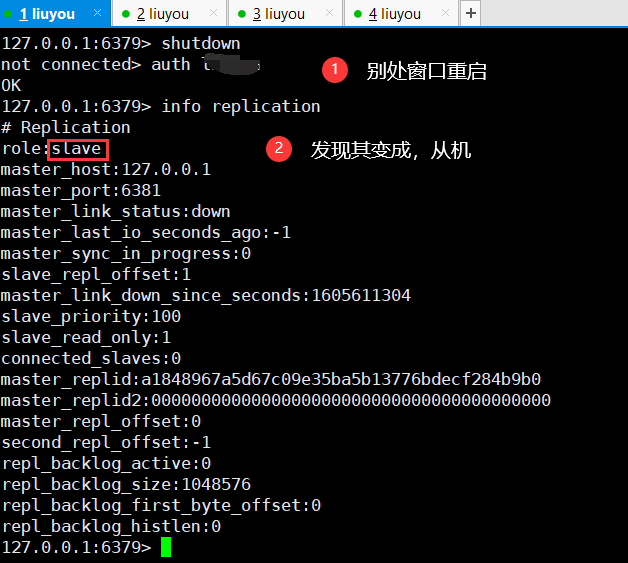
④ Let's Restore window 1 (the previous host) and see what happens
Become a slave
Advantages and disadvantages
- advantage:
- Sentinel cluster is based on master-slave replication mode. It has all the advantages of master-slave configuration
- The master-slave can be switched and the fault can be transferred, so the system availability will be better
- Sentinel mode is the upgrade of master-slave mode. It is more robust from manual to automatic
- shortcoming
- Redis is not easy to expand online. Once the cluster capacity is online, online expansion is very troublesome
- The configuration of sentinel mode is actually very troublesome. There are many choices
Full configuration of sentinel mode
# Example sentinel.conf# sentry sentinel The default port on which the instance runs is 26379 # If there are sentinel clusters, multiple ports need to be configured port 26379 # sentry sentinel Working directory for dir /tmp# sentry sentinel Monitored redis Primary node ip port # master-name The name of a master node that can be named by itself can only be composed of letters A-z,Number 0-9 ,These three characters".-_"form.# quorum When these quorum number sentinel The sentry thought master If the primary node is lost, it is objectively considered that the primary node is lost# sentinel monitor <master-name> <ip> <redis-port> <quorum>sentinel monitor mymaster 127.0.0.1 6379 1# When in Redis Enabled in the instance requirepass foobared Authorization password so that all connections Redis The client of the instance must provide a password# Set up sentry sentinel The password for connecting master and slave. Note that the same authentication password must be set for master and slave# sentinel auth-pass <master-name> <password>sentinel auth-pass mymaster MySUPER--secret-0123passw0rd# Specifies the number of milliseconds after which the master node does not respond to the sentinel sentinel At this time, the sentinel subjectively thinks that the primary node goes offline for 30 seconds by default# sentinel down-after-milliseconds <master-name> <milliseconds>sentinel down-after-milliseconds mymaster 30000# This configuration item specifies what happens when failover How many can there be at most during active / standby switching slave At the same time, for the new master Synchronize,# The smaller the number, the better failover The longer it takes,# But if this number is larger, it means more slave because replication Not available.# You can ensure that there is only one at a time by setting this value to 1 slave Is in a state where the command request cannot be processed.# sentinel parallel-syncs <master-name> <numslaves>sentinel parallel-syncs mymaster 1# Timeout for failover failover-timeout It can be used in the following aspects: #1. Same sentinel For the same master twice failover The interval between.#2. Be a slave From a wrong master There the synchronization data starts to calculate the time. until slave Corrected to correct master When synchronizing data there.#3.When you want to cancel an ongoing failover Time required. #4.When carried failover When, configure all slaves Point to new master Maximum time required. But even after this timeout, slaves Will still be correctly configured to point to master,But you don't parallel-syncs Here comes the configured rule# The default is three minutes# sentinel failover-timeout <master-name> <milliseconds>sentinel failover-timeout mymaster 180000# SCRIPTS EXECUTION#Configure the script to be executed when an event occurs. You can notify the administrator through the script. For example, send an email to notify relevant personnel when the system is not running normally.#There are the following rules for the running results of scripts:#If the script returns 1 after execution, the script will be executed again later. The number of repetitions is currently 10 by default#If the script returns 2 after execution, or a return value higher than 2, the script will not be executed repeatedly.#If the script is terminated due to receiving a system interrupt signal during execution, the behavior is the same as when the return value is 1.#The maximum execution time of a script is 60 s,If this time is exceeded, the script will be SIGKILL The signal is terminated and then re executed.#Notification script:When sentinel When an event with any warning level occurs (for example redis The instance's subjective failure and objective failure, etc.) will call this script,#At this time, the script should be sent by email, SMS And other ways to inform the system administrator about the abnormal operation of the system. When calling the script, two parameters will be passed to the script,#One is the type of event,#One is the description of the event.#If sentinel.conf If the script path is configured in the configuration file, you must ensure that the script exists in the path and is executable. Otherwise sentinel Unable to start normally, successfully.#Notification script# sentinel notification-script <master-name> <script-path> sentinel notification-script mymaster /var/redis/notify.sh# Client reconfiguration master node parameter script# Be a master because failover When a change occurs, this script will be called to notify the relevant client about master Information that the address has changed.# The following parameters will be passed to the script when the script is called:# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port># at present<state>Always“ failover",# <role>Yes“ leader"Or“ observer"One of them. # parameter from-ip, from-port, to-ip, to-port It's used with old ones master And new master(That is, the old slave)Communicable# This script should be generic and can be called multiple times, not targeted.# sentinel client-reconfig-script <master-name> <script-path>sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # Operation and maintenance configuration
13, Cache penetration and avalanche (interview frequency, commonly used at work)
This is just an understanding and does not involve the underlying solution
The use of Redis cache has greatly improved the performance and efficiency of applications, especially in data query. But at the same time, it brings some problems. One of the most crucial problems is the problem of data consistency. Strictly speaking, this problem has no solution. If data consistency is required, caching cannot be used. Other typical problems are cache penetration, cache avalanche and cache breakdown. At present, the industry also has more popular solutions.
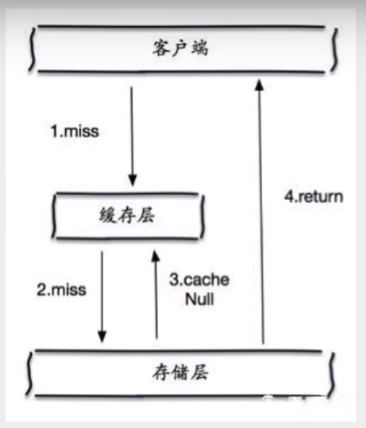
1. Cache penetration (not found)
Cache penetration: the user wants to query a data and finds that there is no in Redis memory database, that is, the cache misses, so he queries the persistence layer database. No, so this query failed. When there are many users, the cache misses (second kill!), So they all request the persistence layer database. This will cause great pressure on the persistence layer database, which is equivalent to cache penetration.
Solution
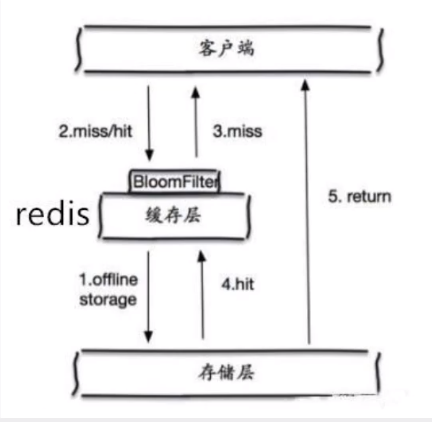
Bloom filter
Bloom filter is a data structure that stores all possible query parameters in the form of Hash. It is verified at the control layer and discarded if it does not meet the requirements, so as to avoid the query pressure of the storage system.
Cache empty objects
When the storage layer fails to hit, even the returned empty object will be cached, and an expiration time will be set. Then accessing the data will be obtained from the cache, protecting the back-end data source
But there are two problems with this method
- If null values can be cached, this means that the cache needs more space to store more keys, because there may be many null keys
- Even if the null value sets the expiration time, there will be inconsistency between the data of the cache layer and the storage layer for a period of time, which will have an impact on the business that needs to maintain consistency
2. Cache Avalanche (centralized failure)
Cache avalanche means that the cache set expires in a certain period of time. Redis is down!
One of the causes:
For example, in the rush purchase at double 11:00, the same batch of commodity information will be put into the cache. Assuming that the cache is set to expire for one hour, the cache of this batch of commodities will expire at 1:00 a.m. The access and query of these commodities fall on the database, which will produce periodic suppression peaks. Therefore, all requests will be to the storage layer, and the call volume of the storage layer will increase sharply, which may lead to the collapse of the storage layer and the downtime of the server.
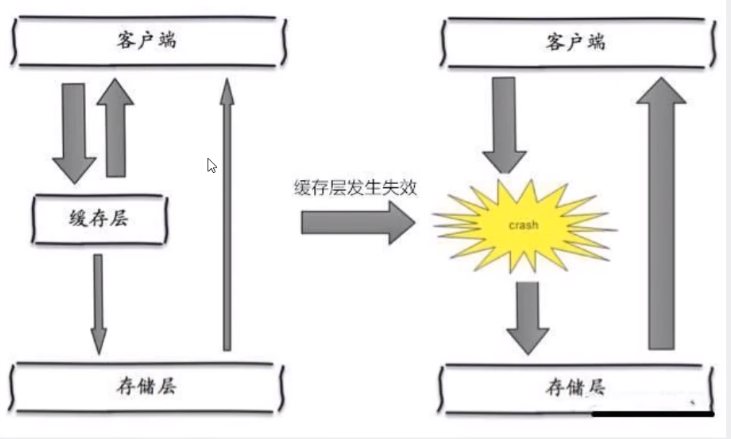
In fact, centralized expiration is not very fatal. The more fatal cache avalanche is the downtime or disconnection of a node of the cache server. Because of the naturally formed cache avalanche, the cache must be created centrally in a certain period of time. At this time, the database can withstand the pressure. It is nothing more than periodic pressure on the database. The downtime of the cache service node will cause unpredictable pressure on the database server, which is likely to crush the database in an instant.
Solution
Redis high availability
The idea is that since Redis may be connected, we should add more Redis so that others can continue to work after hanging up. In fact, it is to build clusters
Current limiting degradation
The idea of this solution is to control the number of threads reading and writing to the database cache by locking or queuing after the cache fails. For example, for a key, only one thread is allowed to query data and write cache, while other threads wait.
Data preheating
The meaning of data heating is that before the formal deployment, we first access the data in advance, so that some data that may be accessed in large quantities will be loaded into the cache. When a large concurrent access is about to occur, manually trigger the loading of different key s in the cache, and set different expiration times to make the time point of cache invalidation as uniform as possible.
3. Cache breakdown (the number of queries is too large, and the cache expires at the moment)
Here we need to pay attention to the difference between cache penetration and cache breakdown. Cache breakdown refers to that a key is very hot and carries large concurrency constantly. Large concurrency accesses one point in a centralized way. When the key fails, the large concurrency will break through the cache and directly request the persistent layer database, which is like cutting a hole in a screen.
When a key expires, a large number of requests are accessed concurrently. This kind of data is generally hot data. Because the cache expires, the database will be accessed at the same time to query the latest data and write back to the cache, which will lead to excessive pressure on the database at the moment.
Solution
Set hotspot data never to expire
From the cache level, the expiration time is not set, so there will be no problems after the hot key expires.
Add mutex
Distributed lock: using a distributed lock ensures that only one thread can query the back-end service for each key at the same time. Other threads do not have the permission to obtain the distributed lock, so they only need to wait. This method shifts the pressure of high concurrency to distributed locks, so the test of distributed locks is great.
Copyright notice: This article is the original article of the blogger and follows CC 4.0 BY-SA Copyright agreement, please attach the original source link and this statement for reprint. KuangStudy is a lifelong companion with learning!
Link to this article: https://www.kuangstudy.com/bbs/1353692191381356545