Redis is a high-performance key value in memory database. Redis is completely open source and free, and complies with the BSD protocol
1. Architecture
- KV database of single process and single thread model
- It is completely based on memory and provides data persistence function
- The data structure is simple and the operation is simple
- Using multiplex I/O multiplexing model
- There are five network IO models
Blocking IO, non blocking IO, IO multiplexing model, signal driven IO, asynchronous IO model
2. Features
-
Data persistence is supported. The data in memory can be saved on disk and automatically loaded again for use when restarting.
-
It supports not only key value data operations (strings), but also the storage of list, set, zset, hash and other data structures.
-
Support the master-slave backup of data, and adopt the master-slave backup mode.
-
The new version of 3.x also supports the distributed deployment mode, which truly realizes the distributed storage and response of data blocks.
-
Extremely high performance – Redis reads 110000 times / s and writes 80000 times / s.
-
All operations are atomic
-
Rich practical features, such as subscription publish mode, producer consumer mode, key expiration and other common and easy-to-use modes.
-
Three operation modes
- Stand alone deployment
- Main standby deployment
- Distributed deployment
3. Application scenarios
Objective: accelerate client access speed or other function points to accelerate efficiency
- Cache some static data
- Cache some infrequently changing data
- Cache some time-consuming computing data
- Cache some precomputed data
- Act as a middleware for decoupling between system modules or subsystems
- Front end acceleration of spring boot integrated ecarts word cloud project
When the word cloud list is displayed on the web, it will change from the database query operation to the first query from the database, and then check the redis operation to experience the improvement of speed
- Front end acceleration of large public opinion hot spot mining projects
When hotspot mining is displayed on the web side, it will always change from database query operation to the first query from database, and then check redis operation to experience the improvement of speed
- redis middleware storage and system decoupling application of advanced crawler
redis is used as the third-party storage of the collected task object collection of the crawler, eliminating the need to recover the collected task object collection from the database.
redis is used to decouple the interaction between the master and slave nodes in the distributed collector, and direct communication is no longer required
4. Specific use
reference resources: https://www.jianshu.com/p/40dbc78711c8
- To cache hot data, you can set the expiration time and then update the cache
- For the application of time limited business, you can use the expire command to set the lifetime of a key, and redis will delete it after the time. This feature can be used in business scenarios such as limited time preferential activity information and mobile phone verification code
- Because the incrby command can achieve atomic increment, redis can be applied to highly concurrent second kill activities and the generation of distributed serial numbers. The specific services are also reflected in, for example, limiting the number of short messages sent by a mobile phone number, limiting the number of requests per minute for an interface, limiting the number of calls per day for an interface, and so on
- For the ranking problem, the query speed of relational databases is generally slow in ranking, so you can sort hot data with the SortedSet of redis
- Distributed lock
- Delayed Operation
- Paging, fuzzy search
- Storage of likes, friends and other relationships
5. Specific operation and use
In windows:
- Open service
- cmd enter the corresponding directory and redis-server.exe --maxheap 268435456
- Start through the configuration file: modify the value of the maxheap parameter in redis.windows.conf to 26843545. After CMD enters the corresponding directory, redis-server.exe redis.windows.conf
- Client connection server
- Run redis-cli.exe,set k1 v1, add kv data, keys * view all v,get k1 view v1
- You can specify a custom ip and port. cmd enters the directory, redis-cli.exe -h 127.0.0.1 -p 6379
In linux:
- Open it directly through the browser or wget
- Unzip it into a source package, which can only be used after compilation
tar -xzvf redis-2.8.24.tar.gz cd redis-2.8.24 make Source code compilation cd src Enter the home directory of the compiled executable file ./redis-server Start with default parameters redis-server ,perhaps./redis-server ../redis.conf //Start redis server according to the specified parameter file. The configuration of the parameter file is the same as the conf file of windows
- Client connection server
cd src ./redis-cli perhaps ./redis-cli -h 127.0.0.1 -p 6379
6 common commands
6.1 setting password
In redis.conf, modify the requirepass parameter, followed by the password, and restart to take effect. Enter:. / redis cli - a XXXX, enter. / redis cli first, and then verify auth xxxx
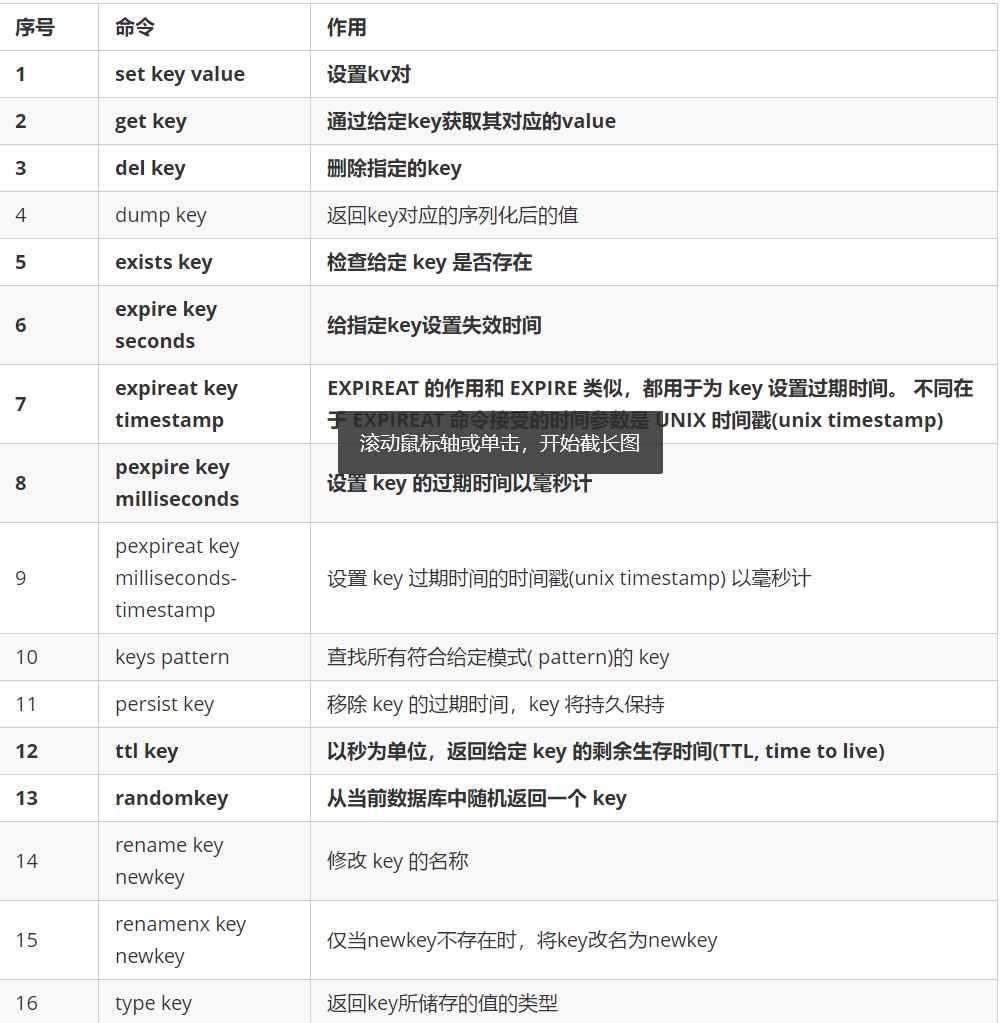
6.2 common commands
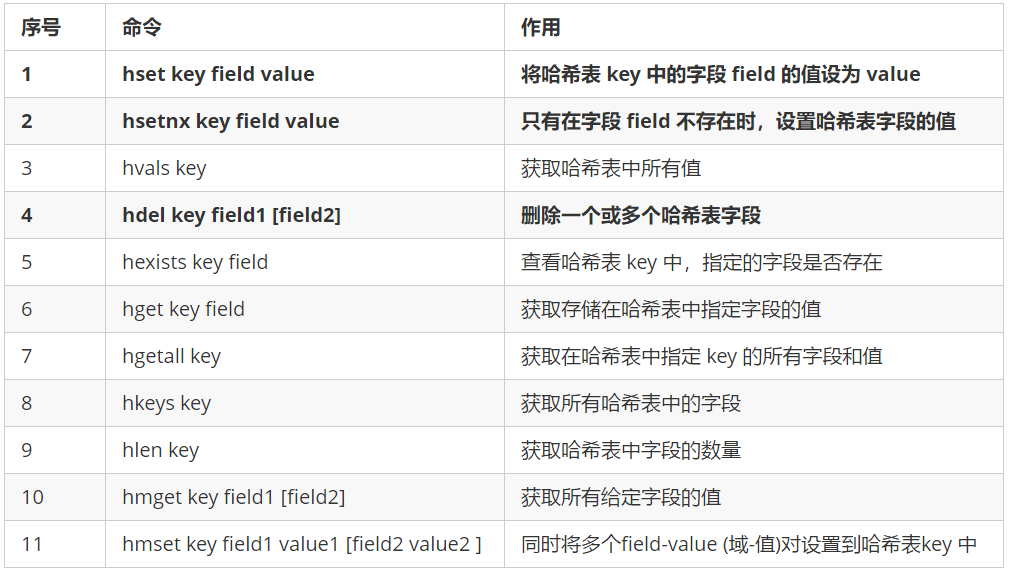
6.3 common commands for hash structure operation
Similar to the map structure in java, a name field is set for the map object, which is internally composed of a series of kv pairs.
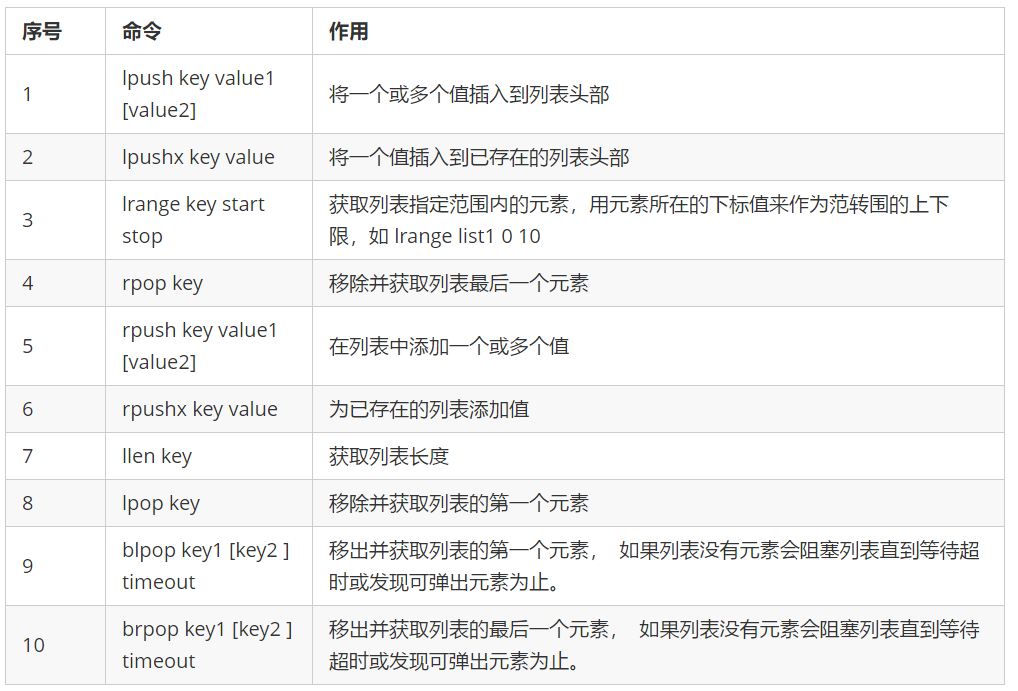
6.4 common commands for list structure operation
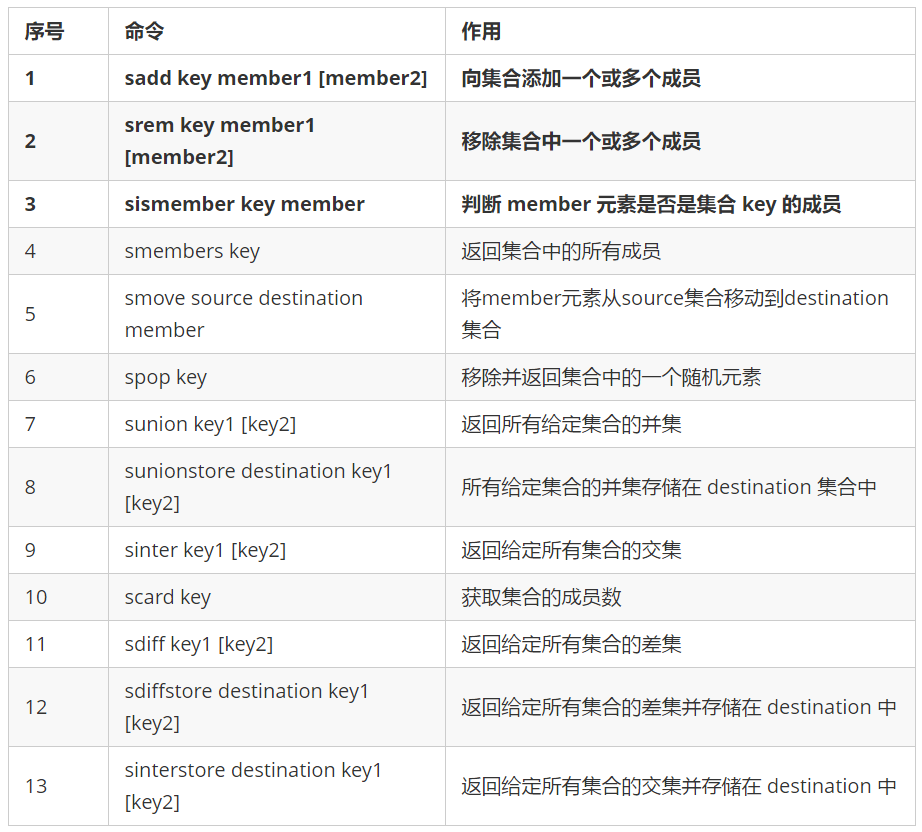
6.5 common commands for Set structure operation
- Similar to the HashSet in JavaSe, the Set structure in Redis mainly stores unordered sets of String type.
- The collection is implemented through hash table, so the time complexity of adding, deleting and searching is O(1).
- Collection members are unique and non duplicate data structures.
6.6 redis connection server operation

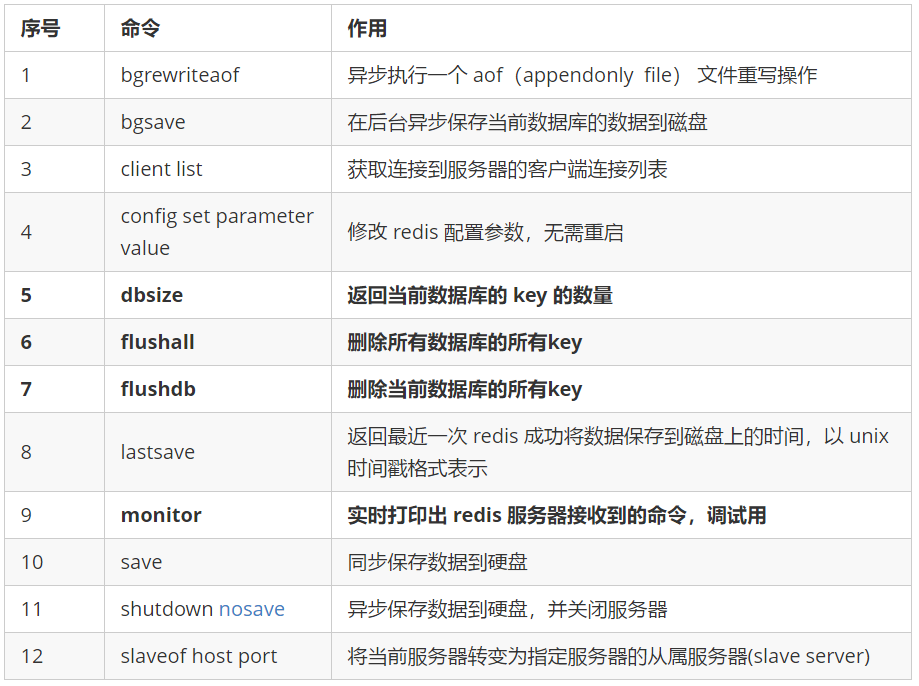
6.7 redis server operation
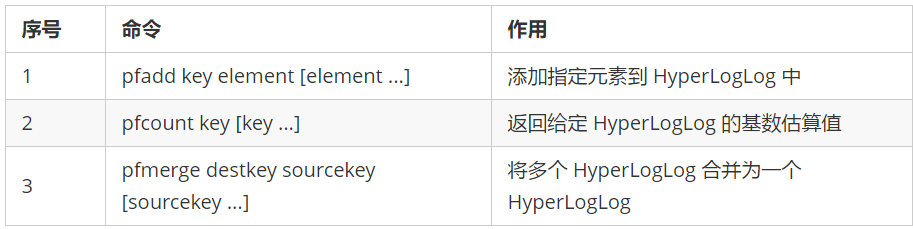
6.8 cardinality statistical structure hyperlog (cardinality is de duplication)
- HyperLogLog structure is used for cardinality statistics. The corresponding algorithm is HyperLogLog algorithm, which is an algorithm for probability cardinality calculation.
- This structure can be used in scenarios where absolute accuracy is not required, such as within the range of 1% standard error.
- Its remarkable advantage is that when the number or volume of input elements is very, very large, the space required to calculate the cardinality is always fixed and very small.
- Each hyperlog key only needs 12 KB of memory to calculate the cardinality of nearly 2 ^ 64 different elements. Its storage space does not grow linearly.
- Only the cardinality is calculated and the data itself is not stored, so the element itself cannot be returned
7 Java operation redis
7.1. Introducing dependencies
- The third-party library for java operation redis is jedis
<project
xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tl.job002</groupId>
<artifactId>RedisTest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!-- First, configure the server location of the warehouse,Alibaba cloud is preferred. You can also configure the image mode. The effect is the same -->
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.2</version>
</dependency>
</dependencies>
<build>
<finalName>RedisTest</finalName>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
7.2. Test whether the redis server starts normally
import redis.clients.jedis.Jedis;
public class RedisUtil {
public static void main(String[] args) {
// Connect to the local Redis service
Jedis jedis = new Jedis("localhost", 6379);
// Check whether the service is running
System.out.println("The service is running: " + jedis.ping());
}
}
7.3 testing adding kv pairs to redis and querying
import redis.clients.jedis.Jedis;
public class RedisUtil {
public static void main(String[] args) {
// Connect to the local Redis service
Jedis jedis = new Jedis("localhost", 6379);
jedis.set("jedis_k1", "jedis_v1");
System.out.println("jedis_k1=:"+ jedis.get("jedis_k1"));
}
}
7.4. Query results from redis client black window
Enter get jedis_k1 will return jedis_v1 description works
redis operation tool
import redis.clients.jedis.Jedis;
public class RedisUtil {
private Jedis jedis;
public Jedis getJedis() {
return jedis;
}
public void setJedis(Jedis jedis) {
this.jedis = jedis;
}
public RedisUtil(String host, int port, String password) {
jedis = new Jedis(host, port);
jedis.auth(password);
}
public void set(String key, String value) {
jedis.set(key, value);
}
public String getString(String key) {
return jedis.get(key);
}
public void close() {
this.jedis.close();
}
public static void main(String[] args) {
// Connect to the local Redis service
RedisUtil redisUtil = new RedisUtil("localhost", 6379, "tianliangedu");
redisUtil.set("jedis_k1", "jedis_v1");
System.out.println("jedis_k1=:" + redisUtil.getString("jedis_k1"));
}
}