Distributed locks are usually implemented in the following ways:
-
database
-
Cache (e.g. Redis)
-
Zookeeper
-
etcd
In actual development, Redis and Zookeeper are mostly used, so this article only talks about these two.
Before discussing this issue, let's take a look at a business scenario:
System A is an e-commerce system. At present, it is deployed on A machine. There is an interface for users to place orders. However, users must check the inventory before placing orders to ensure that the inventory is sufficient.
Because the system has certain concurrency, the inventory of goods will be saved in Redis in advance, and the inventory of Redis will be updated when users place an order.
The system architecture is as follows:
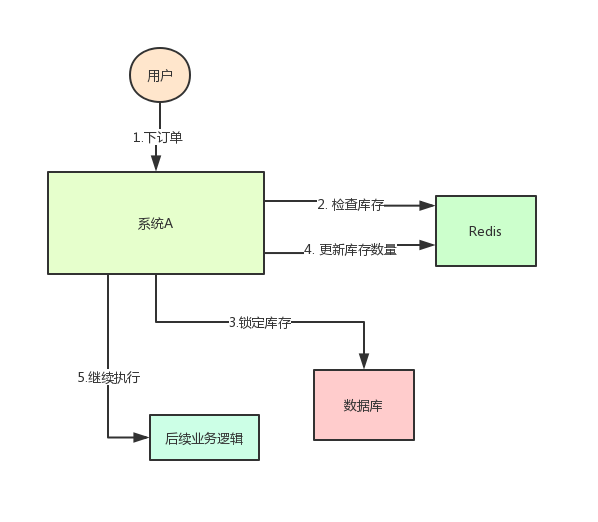
But this will cause a problem: if at a certain time, the inventory of a commodity in redis is 1, then two requests come at the same time. One request is executed to step 3 of the above figure, and the inventory of the database is updated to 0, but step 4 has not been executed yet.
When another request is executed to step 2, if it is found that the inventory is still 1, continue to step 3.
As a result, two goods were sold, but there was only one in stock.
It's obviously wrong! This is a typical inventory oversold problem
At this time, it is easy to think of a solution: Lock steps 2, 3 and 4 with a lock. After they are completed, another thread can come in and execute step 2.
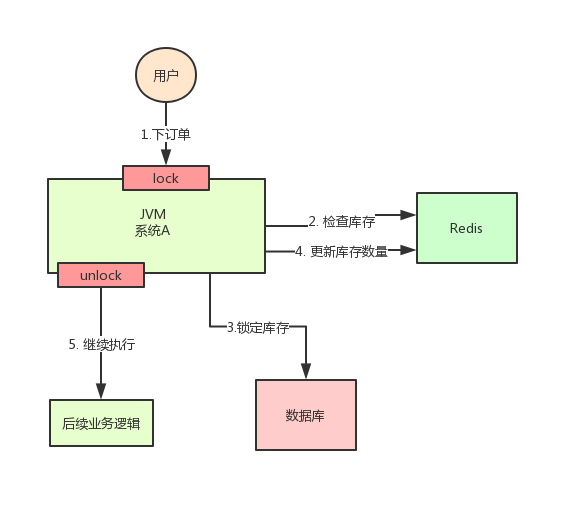
According to the above figure, when executing step 2, use synchronized or ReentrantLock provided by Java to lock, and then release the lock after executing step 4.
In this way, the steps 2, 3 and 4 are "locked", and multiple threads can only be executed serially.
But the good time is not long. The concurrency of the whole system soars, and one machine can't carry it. Now add a machine, as shown in the following figure:
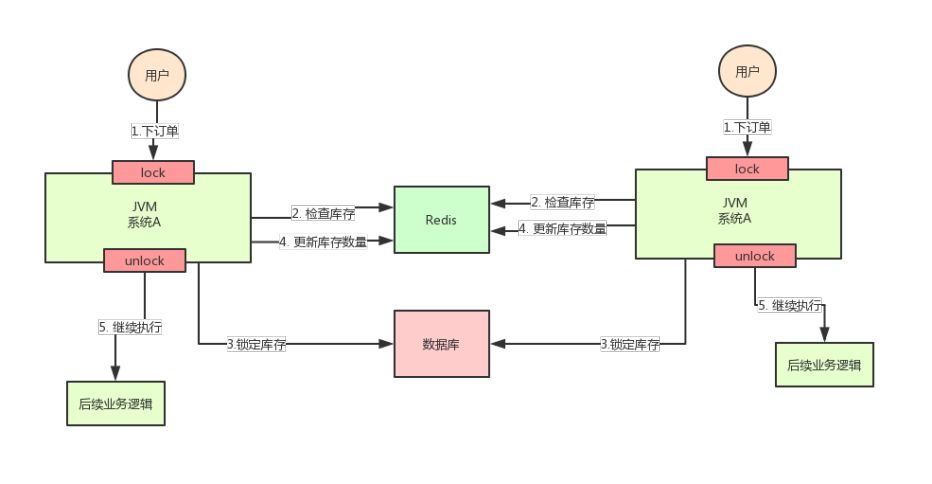
After adding the machine, the system becomes as shown in the figure above, my God!
Assuming that the requests of two users arrive at the same time, but fall on different machines, can the two requests be executed at the same time, or will there be an oversold problem.
Why? Because the two A systems in the above figure run in two different JVMs, the locks they add are only valid for the threads in their own JVMs, but not for the threads of other JVMs.
Therefore, the problem here is that the native locking mechanism provided by Java fails in the scenario of multi machine deployment
This is because the locks of the two machines are not the same lock (the two locks are in different JVM s).
Then, as long as we ensure that the locks added by the two machines are the same lock, won't the problem be solved?
At this point, it's time for distributed locks to make a grand debut. The idea of distributed locks is:
Provide a global and unique "thing" to obtain the lock in the whole system, and then ask this "thing" to get a lock when each system needs to lock, so that different systems can be regarded as the same lock.
As for this "thing", it can be Redis, Zookeeper or database.
The text description is not very intuitive. Let's look at the following figure:
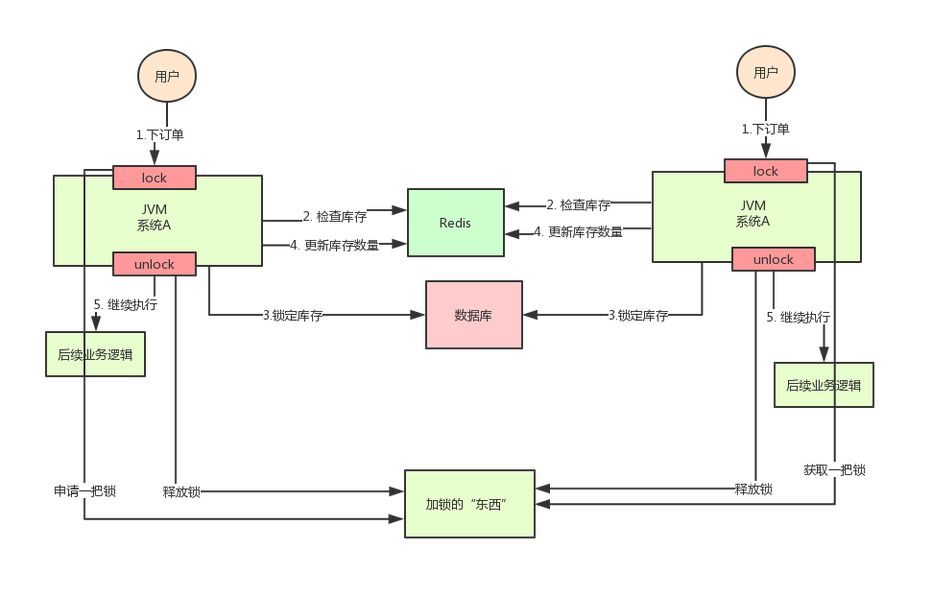
Through the above analysis, we know the inventory oversold scenario. In the case of distributed deployment system, using Java's native locking mechanism can not ensure thread safety, so we need to use the distributed locking scheme.
So, how to implement distributed locks? Keep looking down!
Redis based distributed lock
According to the above analysis, why do we use distributed locks? Let's take a specific look at how to deal with distributed locks when they fall to the ground.
The most common solution is to use Redis as a distributed lock
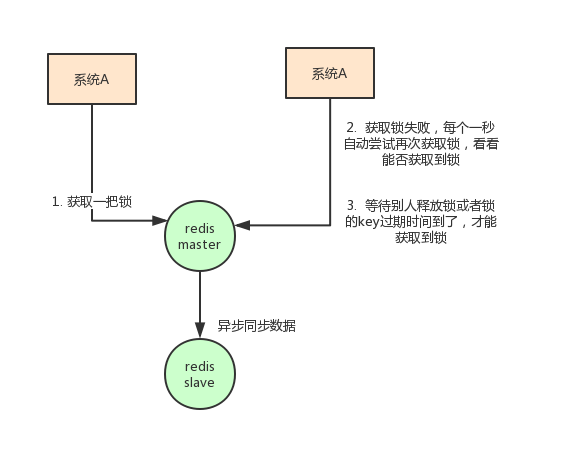
The idea of using redis as a distributed lock is like this: set a value in redis to indicate that the lock is added, and then delete the key when the lock is released.
The specific code is as follows:
//Acquire lock
//NX means that if the key does not exist, it will succeed. If the key exists, it will return false. PX can specify the expiration time
SET anyLock unique_value NX PX 30000
//Release lock: by executing a lua script
//Releasing a lock involves two instructions that are not atomic
//The Lua script support feature of redis is required. The execution of lua script by redis is atomic
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
There are several main points of this approach:
-
Be sure to use the SET key value NX PX milliseconds command
If not, first set the value and then set the expiration time. This is not an atomic operation. It is possible to go down before setting the expiration time, which will cause deadlock (key permanently exists)
-
value should be unique
This is to verify that the value is consistent with the lock before deleting the key when unlocking.
This avoids a situation: suppose a acquires the lock and the expiration time is 30s. At this time, after 35s, the lock has been automatically released. A releases the lock, but B may acquire the lock at this time. A client cannot delete B's lock.
In addition to considering how the client implements distributed locks, we also need to consider the deployment of redis.
redis can be deployed in three ways:
-
standalone mode
-
Master slave + sentinel election mode
-
redis cluster mode
The disadvantage of using redis as a distributed lock is that if the single machine deployment mode is adopted, there will be a single point of problem as long as redis fails. You can't lock it.
The master slave mode is adopted. When locking, only one node is locked. Even if high availability is made through sentinel, if the master node fails and master-slave switching occurs, the problem of lock loss may occur.
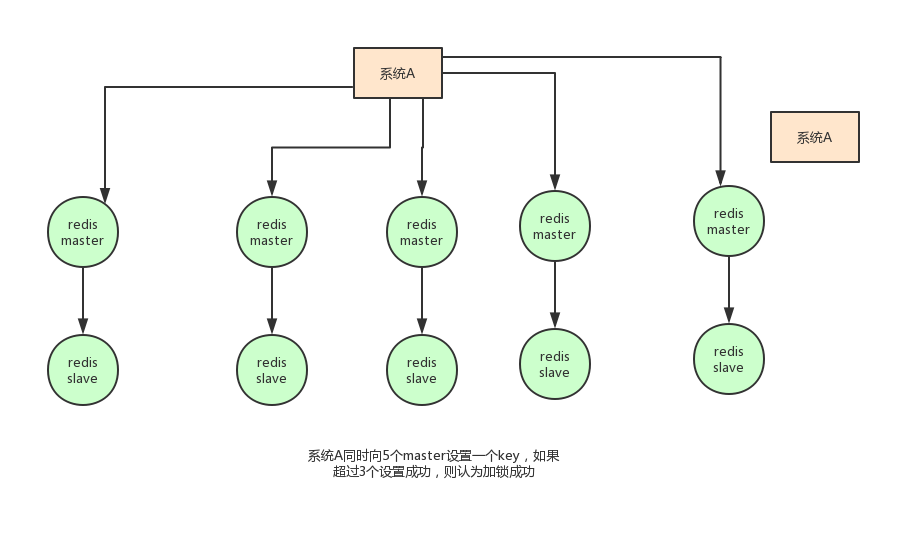
Based on the above considerations, in fact, the author of redis also considered this problem. He proposed a RedLock algorithm. The meaning of this algorithm is roughly as follows:
Assume that the deployment mode of redis is redis cluster. There are five master nodes in total. Obtain a lock through the following steps:
-
Gets the current timestamp in milliseconds
-
Try to create locks on each master node in turn. The expiration time is set to be short, usually tens of milliseconds
-
Try to establish a lock on most nodes. For example, five nodes require three nodes (n / 2 +1)
-
The client calculates the time to establish the lock. If the time to establish the lock is less than the timeout, the establishment is successful
-
If the lock creation fails, delete the lock in turn
-
As long as someone else establishes a distributed lock, you have to constantly poll to try to obtain the lock
However, such an algorithm is still controversial, and there may be many problems, which can not guarantee the correctness of the locking process.
Another way: Redisson
In addition, the Redis distributed lock can be implemented based on redis client's native api, and the open source framework: Redission can also be used
Redisson is an enterprise level open source Redis Client, which also provides distributed lock support. I also highly recommend you to use it. Why?
Recall the above, if you write code to set a value through redis, it is set through the following command.
-
SET anyLock unique_value NX PX 30000
The timeout set here is 30s. If I haven't completed the business logic for more than 30s, the key will expire and other threads may get the lock.
In this way, the first thread has not finished executing the business logic, and the thread safety problem will also occur when the second thread comes in. So we need extra to maintain the expiration time. It's too troublesome~
Let's see how redisson is implemented? First, feel the cool of using reission:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://192.168.31.101:7001")
.addNodeAddress("redis://192.168.31.101:7002")
.addNodeAddress("redis://192.168.31.101:7003")
.addNodeAddress("redis://192.168.31.102:7001")
.addNodeAddress("redis://192.168.31.102:7002")
.addNodeAddress("redis://192.168.31.102:7003");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
lock.unlock();
It's that simple. We only need lock and unlock in its api to complete the distributed lock. He helped us consider many details:
-
redisson executes all instructions through Lua scripts. redis supports the atomic execution of lua scripts
-
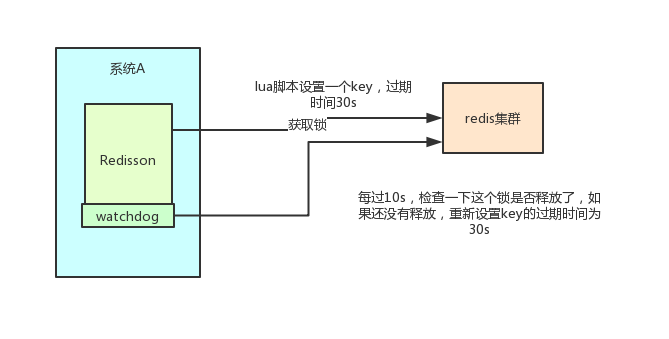
Reisson sets the default expiration time of a key to 30s. What if a client holds a lock for more than 30s?
There is a watchdog concept in reisson, which translates into a watchdog. It will help you set the timeout of the key to 30s every 10 seconds after you obtain the lock
In this way, even if the lock is held all the time, the key will not expire and other threads will get the lock.
-
redisson's "watchdog" logic ensures that no deadlock occurs.
(if the machine goes down, the watchdog will disappear. At this time, the expiration time of the key will not be extended. It will expire automatically after 30s, and other threads can obtain the lock.)
The implementation code is posted here:
//Lock logic
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
if (leaseTime != -1) {
return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
//Call a lua script and set some key s and expiration time
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.addListener(new FutureListener<Long>() {
@Override
public void operationComplete(Future<Long> future) throws Exception {
if (!future.isSuccess()) {
return;
}
Long ttlRemaining = future.getNow();
// lock acquired
if (ttlRemaining == null) {
//Watchdog logic
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
//The watchdog will eventually call here
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
//This task will be delayed by 10s
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//This operation will reset the expiration time of the key to 30s
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
//This method is called recursively to extend the expiration time in an infinite loop
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), new ExpirationEntry(threadId, task)) != null) {
task.cancel();
}
}
In addition, redisson also provides support for redlock algorithm,
Its usage is also very simple:
RedissonClient redisson = Redisson.create(config);
RLock lock1 = redisson.getFairLock("lock1");
RLock lock2 = redisson.getFairLock("lock2");
RLock lock3 = redisson.getFairLock("lock3");
RedissonRedLock multiLock = new RedissonRedLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.unlock();
Summary:
This section analyzes the specific implementation scheme of using Redis as a distributed lock and some of its limitations, and then introduces redison, a Redis client framework. This is also what I recommend you to use. There will be less care details than writing your own code.
Implementation of distributed lock based on zookeeper
In common distributed lock implementation schemes, in addition to redis, zookeeper can also be used to implement distributed locks.
Before introducing the mechanism of zookeeper (replaced by zk below) to realize distributed lock, let's briefly introduce what zk is:
Zookeeper is a centralized service that provides configuration management, distributed collaboration and naming.
zk's model is as follows: zk contains a series of nodes called znode, just like a file system. Each znode represents a directory, and then znode has some features:
-
Ordered node: if a parent node is currently / lock, we can create a child node under this parent node;
Zookeeper provides an optional ordering feature. For example, if we can create child nodes "/ lock/node -" and indicate ordering, zookeeper will automatically add integer sequence numbers according to the current number of child nodes when generating child nodes
In other words, if it is the first child node created, the generated child node is / lock/node-0000000000, the next node is / lock/node-0000000001, and so on.
-
Temporary node: the client can establish a temporary node. After the session ends or the session times out, zookeeper will automatically delete the node.
-
Event monitoring: when reading data, we can set event monitoring for the node at the same time. When the node data or structure changes, zookeeper will notify the client. Currently, zookeeper has the following four events:
-
Node creation
-
Node deletion
-
Node data modification
-
Child node change
-
Based on the characteristics of zk mentioned above, we can easily get the landing scheme of using zk to realize distributed lock:
-
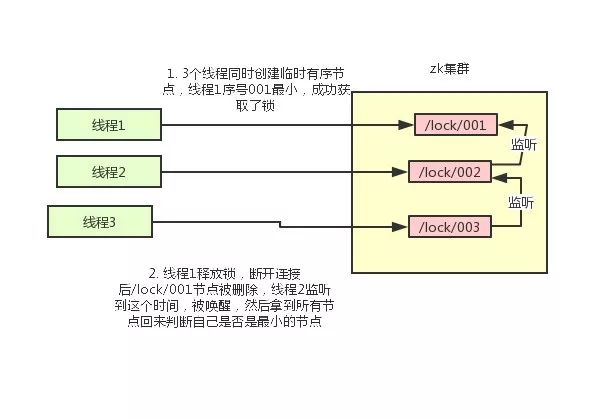
Using zk's temporary nodes and ordered nodes, each thread acquiring a lock is to create a temporary ordered node in zk, such as in the / lock / directory.
-
After the node is created successfully, obtain all temporary nodes in the / lock directory, and then judge whether the node created by the current thread is the node with the lowest sequence number of all nodes
-
If the node created by the current thread is the node with the smallest sequence number of all nodes, it is considered to have succeeded in obtaining the lock.
-
If the node created by the current thread is not the node with the smallest sequence number of all nodes, add an event listener to the previous node of the node sequence number.
For example, if the node sequence number obtained by the current thread is / lock/003, and then the list of all nodes is [/ lock/001,/lock/002,/lock/003], add an event listener to the node / lock/002.
If the lock is released, the node with the next sequence number will be awakened, and then step 3 will be performed again to determine whether its own node sequence number is the smallest.
For example, / lock/001 is released and / lock/002 listens to the time. At this time, the node set is [/ lock/002,/lock/003], then / lock/002 is the minimum sequence number node and obtains the lock.
The whole process is as follows:
The specific implementation idea is like this. As for how to write the code, it is more complex and will not be posted.
Introduction to Curator
Cursor is an open source client of zookeeper, which also provides the implementation of distributed locks.
His usage is also relatively simple:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock"); interProcessMutex.acquire(); interProcessMutex.release();
The core source code of distributed lock is as follows:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try {
if ( revocable.get() != null ) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
//Gets the sorted collection of all current nodes
List<String> children = getSortedChildren();
//Gets the name of the current node
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
//Judge whether the current node is the smallest node
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
//Get lock
haveTheLock = true;
} else {
//If the lock is not obtained, register a listener for the previous node of the current node
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null ){
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}else{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
catch ( Exception e ) {
doDelete = true;
throw e;
} finally{
if ( doDelete ){
deleteOurPath(ourPath);
}
}
return haveTheLock;
}
In fact, the underlying principle of curator implementing distributed locks is similar to that analyzed above. Here we describe its principle in detail with a diagram:
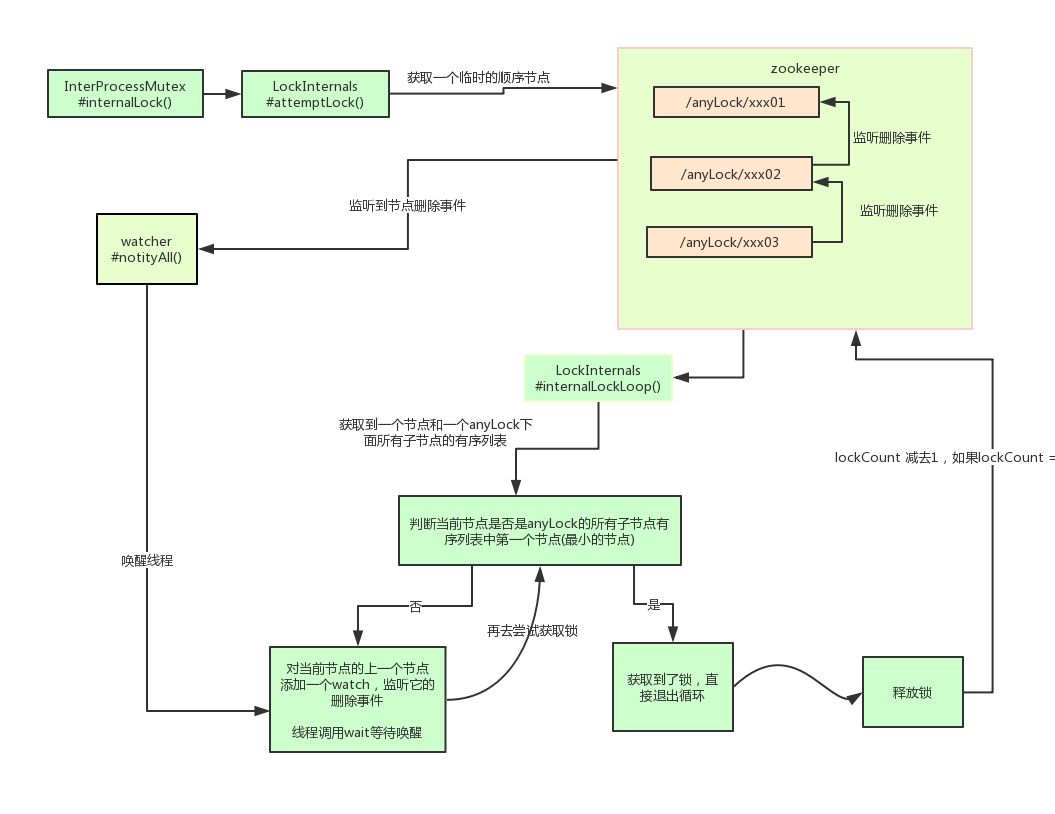
Summary:
This section introduces the scheme of Zookeeperr to realize distributed lock and the basic use of zk's open source client, and briefly introduces its implementation principle.
Comparison of advantages and disadvantages of the two schemes
After learning the two implementation schemes of distributed locks, this section needs to discuss the advantages and disadvantages of redis and zk.
For redis distributed locks, it has the following disadvantages:
-
The way it obtains locks is simple and rough. If it can't obtain locks, it directly and continuously tries to obtain locks, which consumes more performance.
-
On the other hand, the design orientation of redis determines that its data is not highly consistent. In some extreme cases, problems may occur. The lock model is not robust enough
-
Even if the redlock algorithm is used to implement it, in some complex scenarios, it can not be guaranteed that its implementation is 100% free of problems. For the discussion of redlock, see How to do distributed locking
-
redis distributed locks actually need to constantly try to obtain locks, which consumes performance.
But on the other hand, using redis to implement distributed locks is very common in many enterprises, and in most cases, we will not encounter the so-called "extremely complex scenario".
Therefore, using redis as a distributed lock is also a good scheme. The most important thing is that redis has high performance and can support highly concurrent lock acquisition and release operations.
For zk distributed locks:
-
zookeeper's natural design orientation is distributed coordination and strong consistency. The model of lock is robust, easy to use and suitable for distributed lock.
-
If you can't get the lock, you just need to add a listener. You don't have to poll all the time, and the performance consumption is small.
But zk also has its disadvantages: if more clients frequently apply for locking and releasing locks, the pressure on zk cluster will be greater.
Summary:
To sum up, both redis and zookeeper have their advantages and disadvantages. We can use these problems as reference factors when making technology selection.
proposal
Through the previous analysis, two common schemes for implementing distributed locks: redis and zookeeper, each of which has its own merits. How to select the type?
Personally, I prefer zk implemented locks:
Because Redis may have hidden dangers, which may lead to incorrect data. However, how to choose depends on the specific scenario in the company.
If there are zk cluster conditions in the company, zk is preferred. However, if there is only redis cluster in the company, there is no condition to build zk cluster.
It can also be realized by using redis. In addition, the system designer may choose redis when considering that the system already has redis, but does not want to introduce some external dependencies again. This is based on the architecture of the system designer.