1. Background
Recently, a third-party interface has been accessed, which limits the frequency of interface calls (single user Id, 30 operations / min). However, the interface does not prompt that the frequency limit is exceeded, indicating that the interface call is successful, but the actual business is not running, and the requests exceeding the frequency limit are directly implicitly ignored.
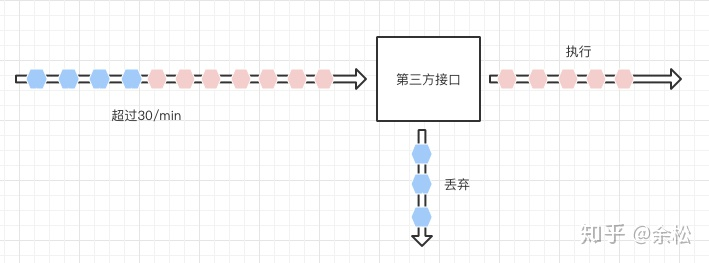
Therefore, it is necessary to detect the request frequency on the caller's side in order to throw exceptions or delay the sending of requests that exceed the frequency limit.
2. Flow shaping scheme
Because of the working experience of communication companies, this demand is easily associated with traffic shaping.
Traffic Shaping is a measure to actively adjust the traffic output rate. Simply, on a network node, the input stream that does not meet the requirements (the rate is too high) is transformed or filtered into the output stream that meets the rules (meeting the rate requirements) through certain rules.
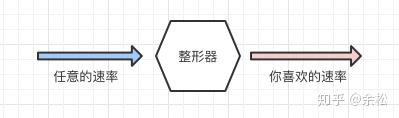
There are two main algorithms for traffic shaping, leaky bucket algorithm and token pass algorithm.
2.1 leaky bucket algorithm
Leaky bucket algorithm is relatively simple. It mainly forcibly controls the rate of output stream and smoothes the burst traffic on the network. As shown below:
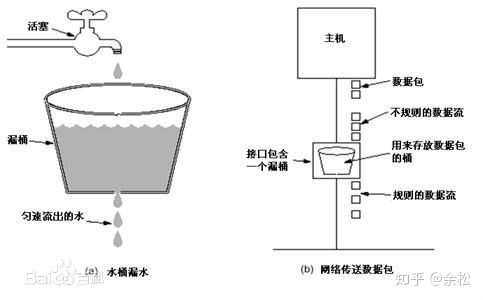
Set the volume of a large bucket (the number of messages), and then control the rate of message output flow. You can think of it as a thread pool with a fixed number of threads. This scheme is also easy to implement. For example, in our scenario, the stupidest way is to add a Redis based distributed lock to each UserId (the TTL of the lock is 60s/30=2s) and send it only after getting the lock.
You don't have to go deep into this scheme. In fact, I don't have it either, because it has a particularly obvious disadvantage: the burst performance is very poor. The service provider only limits the rate to 30 times / min and does not limit 29 requests to be sent in 1 second. If we have 29 requests to be sent (without violating the rules), this scheme takes 58 seconds to complete.
- Simple implementation
- Poor burst performance
2.2 token bucket algorithm
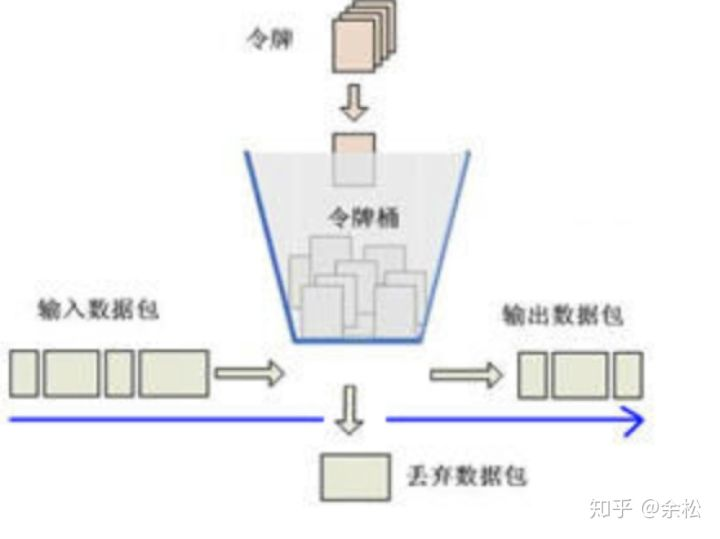
In order to solve the problem of poor burst performance of leaky bucket algorithm in this scenario, we have an improved method - token bucket algorithm. Its idea is that an automated task continuously generates tokens at a fixed frequency, tries to put them into a bucket with a fixed volume, and discards the excess tokens when the volume exceeds the fixed volume. The thread executing the operation attempts to obtain the token from the bucket. When it gets the token, it will execute. If it cannot get it, it will report an error or block. This idea is very similar to the semaphore in Java (it can be ignored if you are not familiar with it). At first glance, the plan seems to meet the demand.
2.3 improved token bucket algorithm based on Redis
It is feasible to implement strictly according to the token bucket algorithm.
The specific method is to use an atomic number (a key in redis) as the token bucket, and set the value to 30 (the maximum sending amount per minute) every other minute. For the thread that needs to send, perform atomic operation on this key minus 1. If the value obtained is greater than 0, it means it can be sent.
This implementation scheme is a little troublesome because it is necessary to maintain a scheduled task to fill the bucket regularly. Therefore, we refer to the Redis Getting Started Guide for an optimized implementation. The pseudo code is as follows (which is also the easiest implementation to find in Baidu):

In short, TTL (Redis Key timeout) is used to replace the scheduled task, which is an implementation of adjusting measures to local conditions in Redis.
A problem is found after the test. The implementation can only ensure the effectiveness of natural time (0s-59s of a certain minute). For scenes spanning minutes, it may lead to excessive traffic. For example, 20 messages were sent in 58 seconds in one minute and 20 messages were sent in 5 seconds in the next minute. Although there is no departure rule, 40 messages were sent in just 10 seconds. As shown below:

- Guaranteed burst performance
- The rate across time (in this case: minutes) cannot be controlled
In the case of an instance machine, you can directly use Guava's RateLimit class to implement it. reference resources
2.4 compromise solution
There are some compromise solutions, such as reducing the maximum number of transmissions per minute to half of the original, in this case to 15 times / min. This can solve the rate surge caused by the cross minute situation. However, it will our normal burst rate and average rate will be half of the maximum, which is unacceptable.
3. The final plan and record each time
It seems that the students in "not only the world's top 500" are not proficient in learning, and the solutions they master are not enough to solve this problem. We had to find another way.
3.1 queue
In order to avoid the problem of cross time interval traffic surge in 2.3, classmate he in the group proposed to use the redis list type to store the time of the last 30 requests. When a new request comes in, compare its time with the 0th time in the queue. If the time difference between the two is greater than 1 minute, it indicates that the request in the last minute is less than 1 minute, meets the rate requirements, executes the service, presses the new time into the queue, and presses out the 0-th time. Otherwise, the change request will be abandoned.
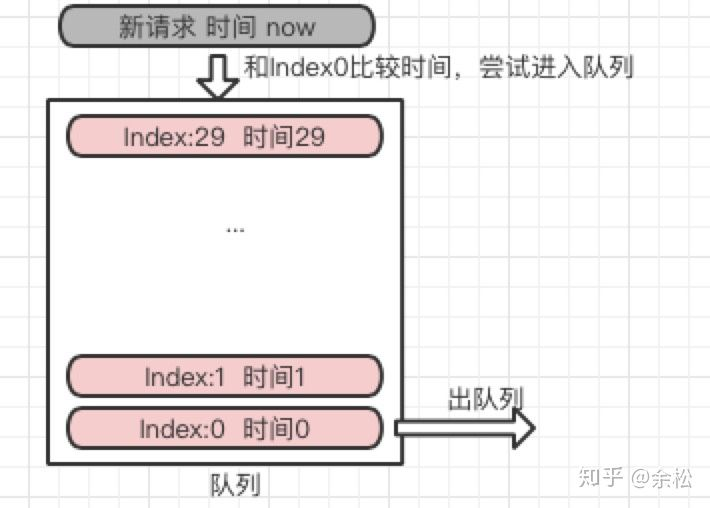
The pseudo code is as follows:

It is logically feasible, but according to experience, the operation of multithreading on the queue must involve things, such as comparing the new request time with the 0th time of the queue and putting it into the queue. It is a very typical CAS operation. For various reasons, the redis service packaged by the basic service group of our factory does not support things (don't ask me why). In addition, the maintenance of the queue is particularly troublesome. The reason why this pseudo code implementation wants to maintain the fixed volume of the queue (press out at the 0th time every time) is to worry about the expansion of the queue.
Another problem is that the rules are not constant at one level. For example, the third-party service adds machines to support the rate of 60 times / min, but the size of the queue is fixed at 30. In addition, multiple rules require multiple queues with different volumes. If you don't delete the original key, these two problems can be solved, but you're worried about the expansion of the queue. You can't have both.
- However, it can realize the rate control of any interval dimension
- CAS requires things to control operations, and multiple thread queuing operations reduce performance (the key is that things are not allowed in our factory)
- In order to prevent the infinite expansion of the queue, the fixed queue volume is complex
- The queue with fixed volume cannot change the rules dynamically
- Multiple rules require multiple queues of fixed volume, which wastes redis memory
3.2 abandon queue
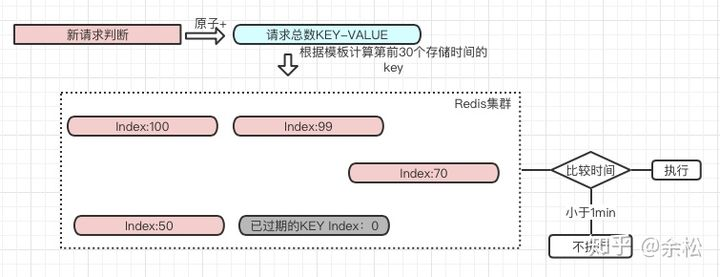
Think carefully about why we use queues. Its biggest advantage is to save the relevant keys in order for easy search. However, this feature is not unique to containers. If I generate Redis keys according to the template fixed rules, we can easily find them even if they are not placed in a container. for instance:
In this example, we replace the KEY in the template with UserId and INDEX with the subscript in the original queue. I just need to add another KEY "atom +" to record the current user's access times. Benefits:
- The original operation on the queue is transformed into an atomic operation on a KEY, and the performance is improved
- The keys of storage time are distributed on different machines in Redis cluster, and multi-threaded operation improves performance
- Most importantly, TTL can be set for each KEY. Mom doesn't have to worry about me running out of Redis memory anymore
- Set the timeout time to be large enough to save enough data before it expires, and you can realize dynamic rule change
- Multiple rules can use the same data without storing redundant data
Attach a simple Java implementation:
/**
* Created by yusong on 2018/9/4.
* Rate control service implementation
* Note: in most cases, the frequency limit rule will be passed. When designing the code, you can judge whether the frequency limit rule is passed in advance,
* To reduce the overhead of frequency rule judgment, refer to the check method of this implementation for details.
*/
@Service
public class RateLimitServiceImpl implements RateLimitService {
private static final Logger logger = LoggerFactory.getLogger(RateLimitServiceImpl.class);
//Record the total number of requests of the current day Redis Key template
private static final String DAY_COUNT_CACHE_KEY_TEMPLATE = "sunlands:rate:limit:count:KEY:DATE";
//Calculator timeout 2 days
private static final int DAY_COUNT_TTL = 3600 * 24 * 2;
//Record the time of each visit Redis Key template
private static final String REQ_TIME_CACHE_KEY_TEMPLATE = "sunlands:rate:limit:time:KEY:DATE:INDEX";
//Recording time timeout unit: s (this expiration time should be greater than the maximum frequency rule period)
private static final int DAY_TIME_TTL = 3600;
/**
* Frequency rules can be set according to the actual situation, or multiple rules can be set
*/
//The time interval unit of frequency rule limit is ms (less than DAY_TIME_TTL* 1000)
private static final long MIN_RATE_LIMIT_PERIOD = 60 * 1000;
//Frequency rule limit
private static final int MIN_MAX_REQ_TIMES = 30;
//Jedis service after simple packaging
@Autowired
private RedisService redisService;
/**
* adding record
* @param key The dimension Key eg of frequency control. For the IP line, the frequency limit key is IP address, for the user frequency limit key is UserId, and for the interface, it can be the interface name
* @return Pass frequency limit
*/
@Override
public boolean addRecord(String key) {
Date now = new Date();
String totalKey = getTotalKey(key, now);
//0. Initialize the counter if necessary and set the timeout
redisService.setnx(totalKey, 0, DAY_COUNT_TTL);
//1. How many requests is this
long index = redisService.incre(totalKey, 1);
//2. Store the current request time
String timeKey = getTimeKey(key, now, index);
long timeMs = now.getTime();
redisService.put(timeKey, timeMs, DAY_TIME_TTL);
//3. Check whether the frequency limit is exceeded
boolean res = check(key, timeMs, index, MIN_RATE_LIMIT_PERIOD, MIN_MAX_REQ_TIMES);
logger.info("addRecord|Frequency limit result|key:{}|res:{}",key,res);
return res;
}
/**
* Check whether the frequency limit is exceeded
* Note: because of the generality of this method, the period and times parameters are added,
* In order to apply changes to the frequency rules or how small the frequency limit rules are
*
* @param key Dimension Key of frequency control
* @param reqTime The time of this request, in milliseconds
* @param reqIndex Count ID of this request
* @param period Unit time of rate control rule, unit: ms
* @param maxTimes Maximum number of requests per unit time of rate control rule
* @return Is it restricted by frequency rules
*/
private boolean check(String key, long reqTime, long reqIndex, long period, int maxTimes) {
//0. Calculate the frequency identification for comparison
long compareIndex = reqIndex - maxTimes;
if (0 >= compareIndex) {
//Today's request hasn't reached the maximum number, pass
return Boolean.TRUE;
}
//1. Obtain the request time of the comparison request
String compareCacheKey = getTimeKey(key, new Date(reqTime), compareIndex);
if (!redisService.exist(compareCacheKey)) {
//The Key recording time has expired. Since the expiration time is greater than period, there is no need to compare the time
return Boolean.TRUE;
}
long compareTime = redisService.getNumber(compareCacheKey);
long timeDifference = reqTime - compareTime;
if (timeDifference >= period) {
//The number of requests per unit time is less than the rule limit, passed
return Boolean.TRUE;
} else {
logger.warn("check|Failure to pass frequency rule limit|key:{}|timeDifference:{}|period:{}", key, timeDifference, period);
return Boolean.FALSE;
}
}
/**
* Calculate the cache key that counts the total number of requests
*/
private String getTotalKey(String key, Date date) {
DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
String dateStr = dateFormat.format(date);
String cacheKey = DAY_COUNT_CACHE_KEY_TEMPLATE.replace("KEY", key).replace("DATE", dateStr);
return cacheKey;
}
/**
* Cache key to calculate the statistical request time
*/
private String getTimeKey(String key, Date date, long index) {
DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
String dateStr = dateFormat.format(date);
String cacheKey = REQ_TIME_CACHE_KEY_TEMPLATE.replace("KEY", key).replace("DATE", dateStr).replace("INDEX", String.valueOf(index));
return cacheKey;
}
}
Note: the above implementation will also include the rejected requests in the total rate calculation to meet our business needs. If you need not to calculate rejected requests, you need to make a slight modification to the code.