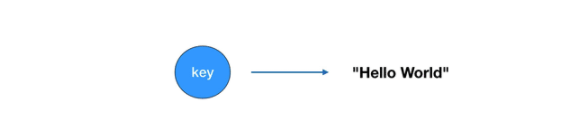
As a data structure storage system in memory, Redis can be used as database, cache and message middleware. Its value supports many types of data structures. The basic data structures include: strings, hashes, lists, sets and sorted sets. These five data structures are often used in our work and often asked during the interview. Therefore, mastering the use and application scenarios of these five basic data structures is the most basic and important part of Redis knowledge.
1. strings
1.1 type introduction
String is the simplest storage type of Redis. Its stored values can be strings, integers or floating-point numbers. Operations are performed on the whole string or part of the string; Performs an increment or decrement operation on an integer or floating-point number.
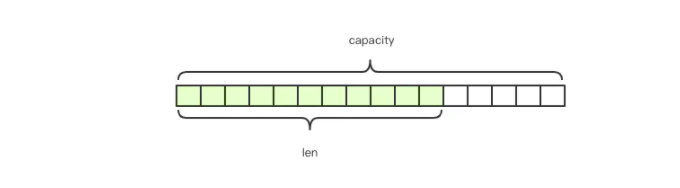
Redis string is a sequence composed of bytes, which is somewhat similar to ArrayList in java. It uses pre allocation of redundant space to reduce frequent memory allocation. As shown in the figure, the internal space capacity actually allocated for the current string is generally higher than the actual string length len. When the string length is less than 1M, the expansion is to double the existing space. If it exceeds 1M, only 1M more space will be expanded at a time. Note that the maximum length of the string is 512M.
1.2 application scenarios
String type is widely used in work. It is mainly used to cache data and improve query performance. For example, store login user information, store commodity information in e-commerce, and make counters (want to know when to block an IP address (access more than several times)), etc.
Operation instruction
set key value: Add a String Type data get key: Get one String Type data mset key1 value1 key2 value2: Add multiple String Type data mget key1 key2: Get multiple String Type data incr key: Self increasing(+1) incrby key step: By step( step)Self increasing decr key: Self subtraction(-1) decrby key step: By step( step)Diminishing
Practical operation
# Insert string >set username zhangsan "OK" # Get string >get username "zhangsan" # Insert multiple strings >mset age 18 address bj "OK" # Get multiple strings >mget username age 1) "zhangsan" 2) "18" # Self increasing >incr num "1" >incr num "2" # Self subtraction >decr num "1" # Specified step size increment >incrby num 2 "3" >incrby num 2 "5" # Specify step size self subtraction >decrby num 3 "2" # delete >del num "1"
2. hashes
2.1 type introduction
Hash is equivalent to HashMap in Java, with an unordered dictionary inside. The implementation principle is consistent with HashMap. A hash table has multiple nodes, and each node saves a key value pair.
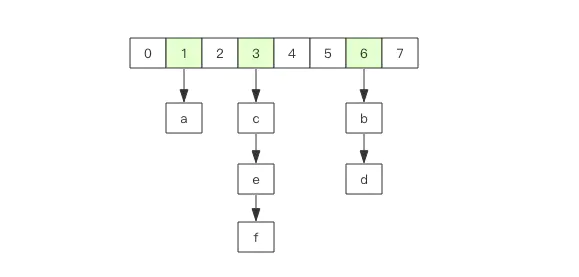
Different from the HashMap in Java, the rehash method is different, because when the HashMap in Java has a large dictionary, rehash is a time-consuming operation and needs to rehash all at once. In order to achieve high performance and can not block the service, Redis adopts a progressive rehash strategy.
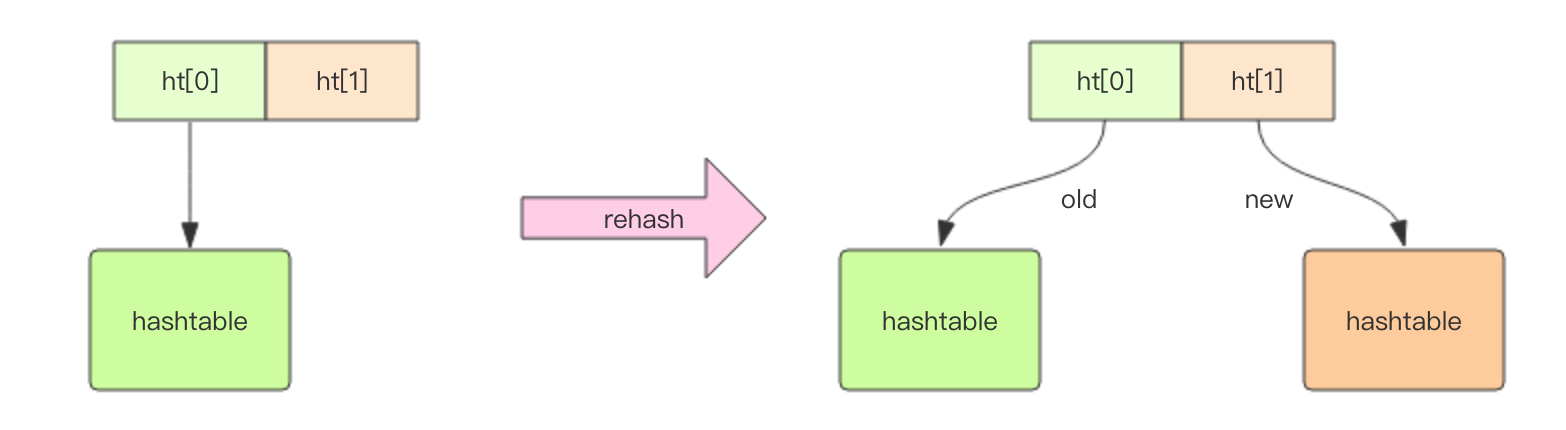
Progressive rehash will retain the old and new hash structures while rehash. When querying, it will query the two hash structures at the same time, and then gradually migrate the contents of the old hash to the new hash structure in subsequent scheduled tasks and hash operation instructions. When the migration is completed, it will be replaced by the new hash structure.
When the hash removes the last element, the data structure is automatically deleted and the memory is reclaimed.
2.2 application scenarios
Hash can also be the same as object storage, such as storing user information. Unlike string, string can be saved only after the object is serialized (such as json serialization). Hash can store each field of user object separately, so as to save the time of serialization and deserialization. As follows:
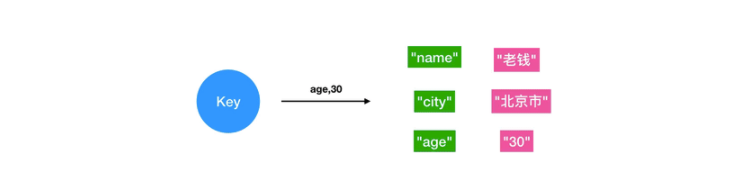
In addition, it can also save the user's purchase records, such as key for user id, field for commodity id and value for commodity quantity. It can also be used to store shopping cart data, such as key for user id, field for commodity id, value for purchase quantity, etc.
Operation instruction
# set a property hset keyname field1 value1 field2 value2 # Get a property value hget keyname field # Get all attribute values hgetall keyname # Delete an attribute hdel keyname field # Get the number of attributes hlen keyname # Increase an attribute by step (the attribute must be numeric) hincrby keyname field step
Practical operation
# Insert hash data >hset userInfo username zhangsan age 18 address bj "3" # Get hash single field data >hget userInfo username "zhangsan" >hget userInfo age "18" # Get hash multiple field data >hmget userInfo username age 1) "zhangsan" 2) "18" # Get all field data of hash >hgetall userInfo 1) "username" 2) "zhangsan" 3) "age" 4) "18" 5) "address" 6) "bj" # Gets the number of field s in the hash >hlen userInfo "3" # A field of self incrementing hash >hincrby userInfo age 2 "20" >hincrby userInfo age 2 "22" # Delete a field of hash >hdel userInfo age "1" # Delete all hash data >del userInfo "1"
3. lists
3.1 type introduction
lists in Redis is equivalent to LinkedList in Java. Its implementation principle is a two-way linked list (its bottom layer is a fast list), which supports reverse search and traversal, making it easier to operate. Insert and delete operations are very fast, with a time complexity of O(1), but index positioning is very slow, with a time complexity of O(n).
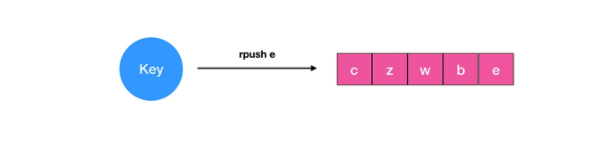
delete
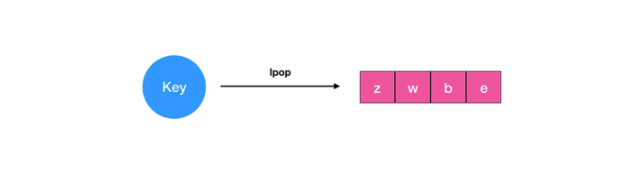
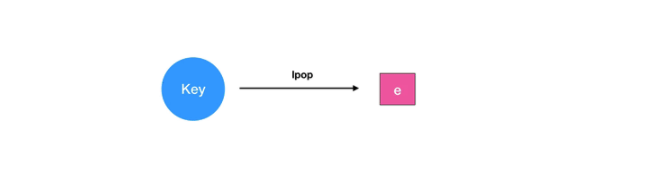
3.2 application scenarios
There are many application scenarios for lists, which can be used to easily realize the best-selling list; work queue can be realized (use the push operation of lists to store the task in lists, and then the working thread can take out the task for execution with pop operation); the latest list, such as the latest comments, can be realized.
Operation instruction
# Left entry lpush key value1 value2 value3... # Left out lpop key # Right entry rpush key value1 value2 value3... # Right out rpop key # start and end read from left to right are subscripts lrange key start end
Practical operation
# Insert from the left side of the list >lpush student zhangsan lisi wangwu "3" # Insert from the right of the list >rpush student tianqi "4" # Pop up one from the left of the list >lpop liangshan "wangwu" # Pop up one from the right side of the list >rpop liangshan "tianqi" # Get the data of list subscripts 0 ~ 1 (closed left and closed right) >lrange liangshan 0 1 1) "lisi" 2) "zhangsan"
Note: blpop blocking version gets
Why block the version of pop is mainly to avoid polling. For a simple example, if we use list to implement a work queue, the thread executing the task can call the blocked version of pop to obtain the task, so as to avoid polling to check whether there is a task. When the task comes, the worker thread can return immediately or avoid the delay caused by polling .
4. sets
4.1 type introduction
The collection is similar to the HashSet in Java. The internal implementation is a HashMap whose value is always null. In fact, it can quickly eliminate the duplication by calculating the hash, which is why set can judge whether a member is in the collection.
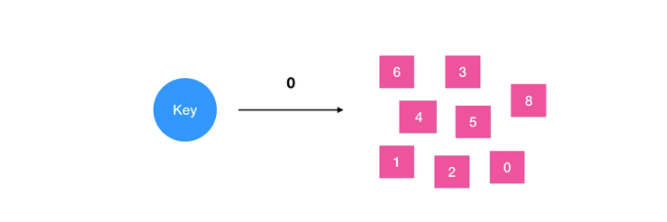
4.2 application scenarios
The sets type of redis is constructed using a hash table, so the complexity is O(1). It supports addition, deletion, modification and query within a set, and supports multiple sets
The intersection, union and difference set operations of the union. These set operations can be used to solve the problems between many data sets in the process of program development, such as calculating the independent ip of the website, user labels in user portraits, common friends and other functions
Operation instruction
# Add content sadd key value1 value2 # Query all values in key smembers key # Remove a value from the key srem key value # Randomly remove a value spop key # Returns the union of two set s sunion key1 key2 # Returns the part where key1 kicks out the intersection (difference set) sdiff key1 key2 # In contrast to sifer, it returns the intersection sinter key1 key2
Practical operation
# Insert multiple pieces of data and remove duplicates >sadd nums 1 2 3 "3" # Insert multiple pieces of data and remove duplicates >sadd nums 1 2 3 "0" # Get all data >smembers nums 1) "1" 2) "2" 3) "3" # Delete a piece of data. The returned 1 indicates that a piece of data has been deleted >srem nums 2 "1" # A piece of data pops up. The returned 1 indicates that the pop-up data value is 1 >spop nums "1" # Insert multiple pieces of data and remove duplicates >sadd nums1 1 2 3 "3" >sadd nums2 2 3 4 "3" # intersection >sinter nums1 nums2 1) "2" 2) "3" # Difference set >sdiff nums1 nums2 1) "1" # Union >sunion nums1 nums2 1) "1" 2) "2" 3) "3" 4) "4"
5. sorted sets
5.1 type introduction
Sorted sets is a combination of Redis similar to SortedSet and HashMap. On the one hand, it is a set to ensure the uniqueness of the internal value. On the other hand, it can give each value a score to represent the sorting weight of the value. HashMap and skip list are used internally to ensure the storage and order of data. HashMap stores the mapping from member to score, while the skip table stores all members. The sorting is based on the score stored in HashMap. Using the structure of skip table can obtain relatively high search efficiency and simple implementation. After the last value in sorted sets is removed, the data structure is automatically deleted and the memory is recycled.
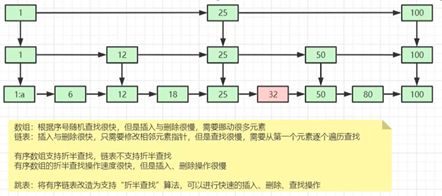
5.1.1 jump list
The internal sorting function of sorted sets is realized through the "jump list" data structure. Its structure is very special and complex. Because zset supports random insertion and deletion, it is not easy to use arrays. Let's first look at an ordinary linked list structure.
We need to sort the linked list according to the score value. This means that when a new element needs to be inserted, it should be located at the insertion point at a specific position, so as to continue to ensure that the linked list is orderly. Usually, we will find the insertion point through binary search, but the object of binary search must be an array. Only the array can support fast location, and the linked list can't do it. What should we do?
Think of a start-up company. At the beginning, there were only a few people. All team members were equal and were co founders. With the growth of the company, the number of people gradually increases, and the cost of team communication increases. At this time, the team leader system will be introduced to divide the team. Each team will have a team leader. Meetings are conducted in teams, and multiple team leaders will have their own meeting arrangements. With the further expansion of the company's scale, it is necessary to add another level - Department. Each department will select a representative from the group leader list as the minister. Ministers will also have their own arrangements for high-level meetings.
The jump list is similar to this hierarchy. All the elements in the lowest layer will be connected. Then select a representative every few elements, and then string these representatives with another level of pointer. Then select secondary representatives from these representatives and string them together. Finally, a pyramid structure is formed.
Think about the location of your hometown in the world map: Asia - > China - > Anhui Province - > Bengbu City - > Guzhen County - > Liuji town - > XXX village - > XXXX, which is a similar structure.

The reason why the "jump list" is "jump" is that the internal elements may "have multiple roles". For example, the element in the middle of the above figure is at L0, L1 and L2 levels at the same time, so it can quickly "jump" between different levels.
When locating the insertion point, first locate it at the top level, then dive to the next level, dive all the way to the bottom level, find a suitable position and insert new elements. You may ask, how can the newly inserted element have the opportunity to "hold several positions"?
The jump list adopts a random strategy to determine which layer new elements can be added to.
First of all, L0 layer must be 100%, L1 layer has only 50%, L2 layer has only 25%, L3 layer has only 12.5%, and it is random to the top layer L31 layer. Most elements can't pass through several layers, and only a few elements can go deep into the top layer. The more elements in the list, the deeper the level, and the greater the probability of entering the top level.
5.2 application scenarios
It is mainly used in the scenario of queues sorted according to a certain weight, such as game score ranking, priority setting task list, student transcript, etc.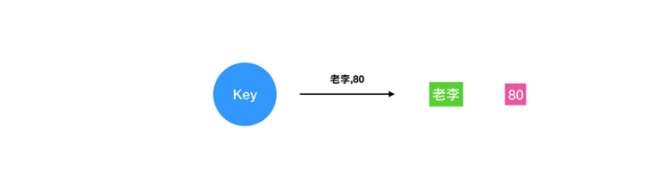
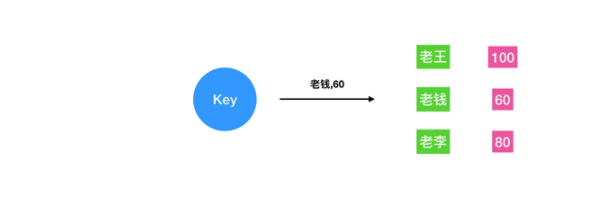
Operation instruction
# Add element zadd key score value [score value...] # Get the values of the collection and arrange them from small to large according to the score. The smallest is the top zrange key start end # Returns all members in the ordered set key whose score value is between min and max (including those equal to min or max). The ordered set members are arranged in the order of increasing score value (from small to large), and the smallest is the top zrangeByScore key score_min score_max # delete zrem key value # How many elements are there in the collection that gets the key zcard key # How many elements are there in the statistical score from small to large (closed interval) zcount key score_min score_max # Get the location of value (sort from small to large, and the smallest is 0) zrank key value # Get the position of value (from large to small, and the largest is 0) zrevrank key value
Practical operation
# Insert multiple pieces of data and scores and de duplicate and sort >zadd rank 66 zhangsan 88 lisi 77 wangwu 99 zhaoliu "4" # Insert multiple pieces of data and scores and de duplicate and sort >zadd rank 66 zhangsan 88 lisi 77 wangwu 99 zhaoliu "0" # Get the data of subscripts 0 ~ 3 (closed left and closed right) >zrange rank 0 3 1) "zhangsan" 2) "wangwu" 3) "lisi" 4) "zhaoliu" # Obtain data with scores between 77 and 99 (closed left and closed right) >zrangeByScore rank 77 99 1) "wangwu" 2) "lisi" 3) "zhaoliu" # Delete a piece of data >zrem rank zhaoliu "1" # Number of query elements >zcard rank "3" # Statistics of data with scores between 77 and 88 (closed left and closed right) >zcount rank 77 88 "2" # Gets the subscript of the specified element >zrank rank zhangsan "0" # Gets the subscript of the specified element and reverses it >zrevrank rank zhangsan "2"
6. Supplement
The following pictures are sponsored by my good brother Lao Wang, a highly skilled full stack expert.