
Problem throw
Have you used Python's list? It is a data structure that can store any type of data and supports random reading.
If you haven't used it, there's no way.
In essence, this list can use arrays and linked lists as its underlying structure. I don't know what the list in Python takes as its underlying structure.
But redis's list is neither a linked list nor an array as its underlying implementation. The reason is obvious: it's inconvenient to get a two-dimensional array? Flexible? How do you write it? The linked list can be realized. For the general linked list, the list function can be realized by putting void * in the data field. However, the disadvantages of linked list are also obvious, which is easy to cause memory fragmentation.
In this environment, adhering to the guiding ideology of "save as you can", please design a data structure.
Structural design
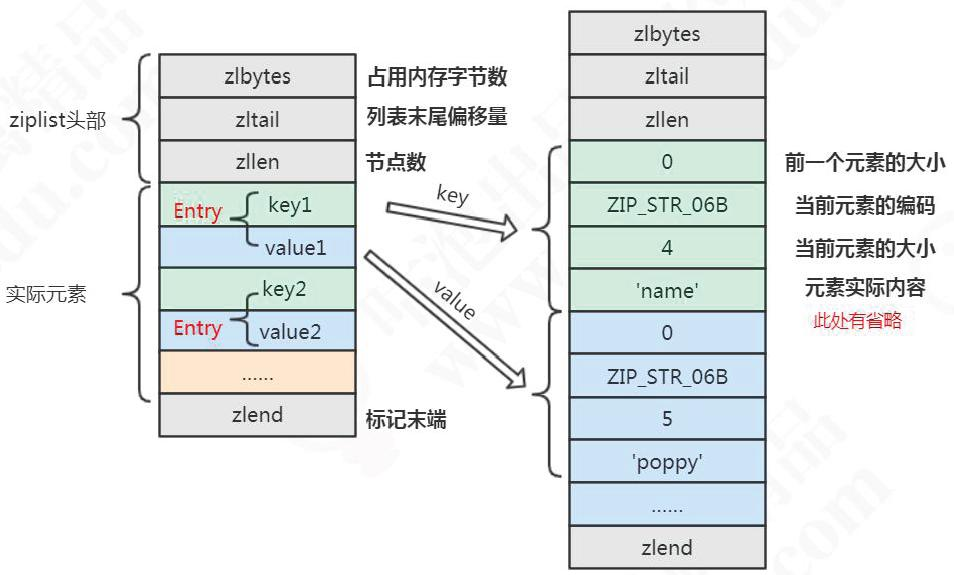
Note that there is no record of "current element size" on the right side of the figure
This figure is very detailed, which saves me from interpreting each field. The whole is very good.
In other words, the notes at the beginning of the document are also very clear. (ziplist.c)
/* The ziplist is a specially encoded dually linked list that is designed * to be very memory efficient. It stores both strings and integer values, * where integers are encoded as actual integers instead of a series of * characters. It allows push and pop operations on either side of the list * in O(1) time. However, because every operation requires a reallocation of * the memory used by the ziplist, the actual complexity is related to the * amount of memory used by the ziplist. * * ---------------------------------------------------------------------------- * * ZIPLIST OVERALL LAYOUT * ====================== * * The general layout of the ziplist is as follows: * * <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend> * * NOTE: all fields are stored in little endian, if not specified otherwise. * * <uint32_t zlbytes> is an unsigned integer to hold the number of bytes that * the ziplist occupies, including the four bytes of the zlbytes field itself. * This value needs to be stored to be able to resize the entire structure * without the need to traverse it first. * * <uint32_t zltail> is the offset to the last entry in the list. This allows * a pop operation on the far side of the list without the need for full * traversal. * * <uint16_t zllen> is the number of entries. When there are more than * 2^16-2 entries, this value is set to 2^16-1 and we need to traverse the * entire list to know how many items it holds. * * <uint8_t zlend> is a special entry representing the end of the ziplist. * Is encoded as a single byte equal to 255. No other normal entry starts * with a byte set to the value of 255. * * ZIPLIST ENTRIES * =============== * * Every entry in the ziplist is prefixed by metadata that contains two pieces * of information. First, the length of the previous entry is stored to be * able to traverse the list from back to front. Second, the entry encoding is * provided. It represents the entry type, integer or string, and in the case * of strings it also represents the length of the string payload. * So a complete entry is stored like this: * * <prevlen> <encoding> <entry-data> * * Sometimes the encoding represents the entry itself, like for small integers * as we'll see later. In such a case the <entry-data> part is missing, and we * could have just: * * <prevlen> <encoding> * * The length of the previous entry, <prevlen>, is encoded in the following way: * If this length is smaller than 254 bytes, it will only consume a single * byte representing the length as an unsinged 8 bit integer. When the length * is greater than or equal to 254, it will consume 5 bytes. The first byte is * set to 254 (FE) to indicate a larger value is following. The remaining 4 * bytes take the length of the previous entry as value. * * So practically an entry is encoded in the following way: * * <prevlen from 0 to 253> <encoding> <entry> * * Or alternatively if the previous entry length is greater than 253 bytes * the following encoding is used: * * 0xFE <4 bytes unsigned little endian prevlen> <encoding> <entry> * * The encoding field of the entry depends on the content of the * entry. When the entry is a string, the first 2 bits of the encoding first * byte will hold the type of encoding used to store the length of the string, * followed by the actual length of the string. When the entry is an integer * the first 2 bits are both set to 1. The following 2 bits are used to specify * what kind of integer will be stored after this header. An overview of the * different types and encodings is as follows. The first byte is always enough * to determine the kind of entry. * * |00pppppp| - 1 byte * String value with length less than or equal to 63 bytes (6 bits). * "pppppp" represents the unsigned 6 bit length. * |01pppppp|qqqqqqqq| - 2 bytes * String value with length less than or equal to 16383 bytes (14 bits). * IMPORTANT: The 14 bit number is stored in big endian. * |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes * String value with length greater than or equal to 16384 bytes. * Only the 4 bytes following the first byte represents the length * up to 2^32-1. The 6 lower bits of the first byte are not used and * are set to zero. * IMPORTANT: The 32 bit number is stored in big endian. * |11000000| - 3 bytes * Integer encoded as int16_t (2 bytes). * |11010000| - 5 bytes * Integer encoded as int32_t (4 bytes). * |11100000| - 9 bytes * Integer encoded as int64_t (8 bytes). * |11110000| - 4 bytes * Integer encoded as 24 bit signed (3 bytes). * |11111110| - 2 bytes * Integer encoded as 8 bit signed (1 byte). * |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer. * Unsigned integer from 0 to 12. The encoded value is actually from * 1 to 13 because 0000 and 1111 can not be used, so 1 should be * subtracted from the encoded 4 bit value to obtain the right value. * |11111111| - End of ziplist special entry. * * Like for the ziplist header, all the integers are represented in little * endian byte order, even when this code is compiled in big endian systems. * * EXAMPLES OF ACTUAL ZIPLISTS * =========================== * * The following is a ziplist containing the two elements representing * the strings "2" and "5". It is composed of 15 bytes, that we visually * split into sections: * * [0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff] * | | | | | | * zlbytes zltail entries "2" "5" end * * The first 4 bytes represent the number 15, that is the number of bytes * the whole ziplist is composed of. The second 4 bytes are the offset * at which the last ziplist entry is found, that is 12, in fact the * last entry, that is "5", is at offset 12 inside the ziplist. * The next 16 bit integer represents the number of elements inside the * ziplist, its value is 2 since there are just two elements inside. * Finally "00 f3" is the first entry representing the number 2. It is * composed of the previous entry length, which is zero because this is * our first entry, and the byte F3 which corresponds to the encoding * |1111xxxx| with xxxx between 0001 and 1101. We need to remove the "F" * higher order bits 1111, and subtract 1 from the "3", so the entry value * is "2". The next entry has a prevlen of 02, since the first entry is * composed of exactly two bytes. The entry itself, F6, is encoded exactly * like the first entry, and 6-1 = 5, so the value of the entry is 5. * Finally the special entry FF signals the end of the ziplist. * * Adding another element to the above string with the value "Hello World" * allows us to show how the ziplist encodes small strings. We'll just show * the hex dump of the entry itself. Imagine the bytes as following the * entry that stores "5" in the ziplist above: * * [02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64] * * The first byte, 02, is the length of the previous entry. The next * byte represents the encoding in the pattern |00pppppp| that means * that the entry is a string of length <pppppp>, so 0B means that * an 11 bytes string follows. From the third byte (48) to the last (64) * there are just the ASCII characters for "Hello World". * * ---------------------------------------------------------------------------- * * Copyright (c) 2009-2012, Pieter Noordhuis <pcnoordhuis at gmail dot com> * Copyright (c) 2009-2017, Salvatore Sanfilippo <antirez at gmail dot com> * All rights reserved. */
Are you finished? The next step is the basic operation stage. For any data structure, the basic operation is nothing but addition, deletion, query and modification.
Actual node
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
basic operation
I think this picture needs to be laid out again:
Note that there is no record of "current element size" on the right side of the figure
increase
This function is actually inserted:
Seriously, my scalp is a little numb. Then let's use the old routine and take it apart step by step.
/* Insert item at "p". */
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipStoreEntryEncoding will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
/* Store offset because a realloc may change the address of zl. */
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
How many steps are there to insert data into the linked list?
1. Offset
2. Put it in
3. Stitching
What's special about this "list"? In particular, it is relatively compact, and there are actually two data types, either integer or string. So what are its steps?
1. Data recoding
2. Parse data and allocate space
3. Access data
Recoding
What is recoding? When inserting an element, do you need to make statistics on the data such as the size of the previous element, its own size and the current element code, and then insert them together. That's it.
There are no more than three insertion positions, head, middle and tail.
Header: the size of the previous element is 0 because there is no previous element.
Medium: the "size of the previous element" recorded by the element after the position to be inserted. Of course, the size itself becomes the "size of the previous element" in the eyes of the latter element.
Tail: then add up the three fields.
I won't read how to re encode it. This article is already very long.
Parse data
The next step is to parse the data.
First, try to parse the data into integers. If it can be parsed, it will be encoded and stored according to the integer type of the compressed list; If the parsing fails, it is encoded and stored according to the byte array type of the compressed list.
After parsing, the value is stored in value and the encoding format is stored in encoding. If the parsing is successful, the number of bytes occupied by the integer is also calculated. The variable reqlen stores the space required for the current element, and then accumulates the space of the other two fields, which is the space required for this node.
Reallocate space
Look at this posture, why, there is still no place to plug it?
Let's see.
The allocated space here is not simply allocated as much as the newly inserted data. If you don't read the English above carefully, well, you can choose to go back and read the composition of that node carefully. Especially that:
/* * The length of the previous entry, <prevlen>, is encoded in the following way: * If this length is smaller than 254 bytes, it will only consume a single * byte representing the length as an unsinged 8 bit integer. When the length * is greater than or equal to 254, it will consume 5 bytes. The first byte is * set to 254 (FE) to indicate a larger value is following. The remaining 4 * bytes take the length of the previous entry as value. */
So this previous is an uncertain factor. It is possible that people were originally arranged in 1-1 arrangement, and one inserted in the middle became arranged in 1-1-5 arrangement; It is also possible that people are arranged in 1-5 and 5-1. In short, they are uncertain.
Therefore, after inserting a data at the location of entryX, the previous of entryX+1 may not change, may increase or decrease four, and no one is sure. I'm not sure. I have to measure it. So just test it, that's all.
Access data
How to access data? Since this is really not a linked list, it is a list.
So, according to the array. yes.
It's troublesome. In fact, it's not troublesome. Have you seen it give you a chance to insert in the middle in redis? Not to mention head insertion, have you seen it give you a chance to head insertion?
An aside: when big data is inserted, the array is not necessarily input to the linked list. In the tail insertion, the advantage of array is far beyond the linked list (of course, only limited to tail insertion). I did this series of experiments in my blog two months ago.
Delete is not written. The reverse operation of addition has not been written since the beginning of the series. However, deleting here will inevitably copy a large amount of data (if you don't delete, just make a deletion flag? This will save time, but it will cause memory fragmentation. However, you can design a function to adjust the memory regularly. For example, compact after reusing one-third of the blocks? Compact when the memory is not enough? That's what STL does).
There's nothing to talk about. The application scenario of this data structure is generally to retrieve keys. Here is a value. The difference is that this value is a string.
Therefore, in addition to the original forward and backward traversal, it also provides range query, which is not difficult.