catalogue
Comparison between embstr and raw
Differences between sds and c language strings:
Implementation principle of zskiplist
redis data storage
redis is an in memory database. The data is stored in the global object redisServer. redis supports multiple db. Each db is a hash table. The key is the sds type, the value is the redisObject type, and the k-v data is stored in the hash table of the corresponding db.
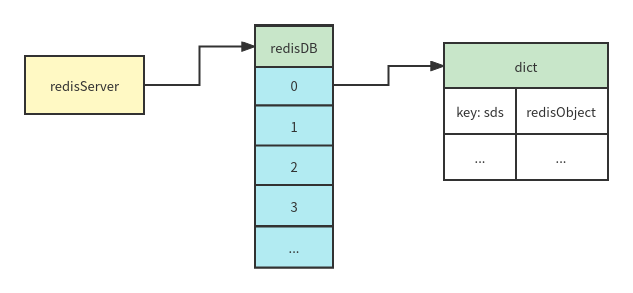
redisDB structure definition
//redisDB structure definition
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;Data structure and coding
redis uses the redisObject structure to save different data types (the structure is as follows). There are five data types: string, list, set, zset and hash. Each data type can use different encoding methods.
//object type
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
//Object encoding method
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
//redisObject structure definition
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;string
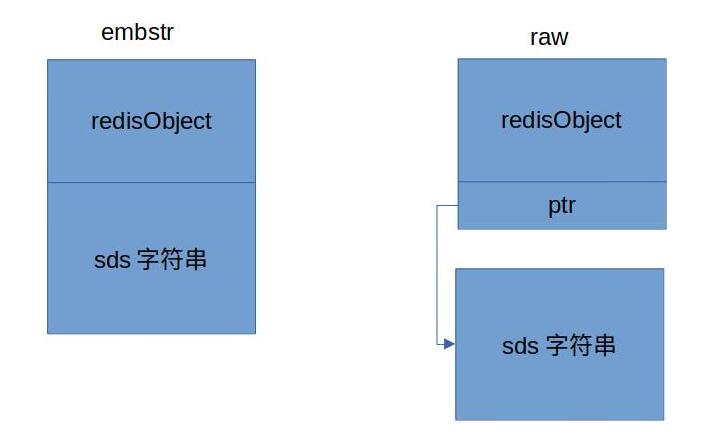
The implementation of string type is in t_ string. In the C file, there are three encoding methods for string types according to different values: int, embstr and raw. The pseudo code is as follows:
if len(str) <= 20 and is_numeric(str):
return to_number(str)
else if len(str) <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT: # 44
return Embstr(str)
else:
return Raw(str)embstr
Embstr is a compact encoding format. When the string length is less than 44, it will be encoded as embstr. Embstr format will use a continuous piece of memory to save types and data. This structure is more compact and saves pointer space.
Comparison between embstr and raw
sds
The c language string ends with '\ 0', which cannot meet the needs of redis in terms of function and performance, so redis encapsulates the saved string of sds (Simple Dynamic String). sds structure is as follows:
//sds structure definition
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
//type definition
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
#define SDS_TYPE_5_LEN(f) ((f)>>SDS_TYPE_BITS)Unlike the old version, the new redis uses sdshdr type structures with different lengths, which can save more space for short characters. sds type selection code is as follows:
//Use the appropriate data type according to the character length
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5)
return SDS_TYPE_5;
if (string_size < 1<<8)
return SDS_TYPE_8;
if (string_size < 1<<16)
return SDS_TYPE_16;
#if (LONG_MAX == LLONG_MAX)
if (string_size < 1ll<<32)
return SDS_TYPE_32;
return SDS_TYPE_64;
#else
return SDS_TYPE_32;
#endif
}Differences between sds and c language strings: 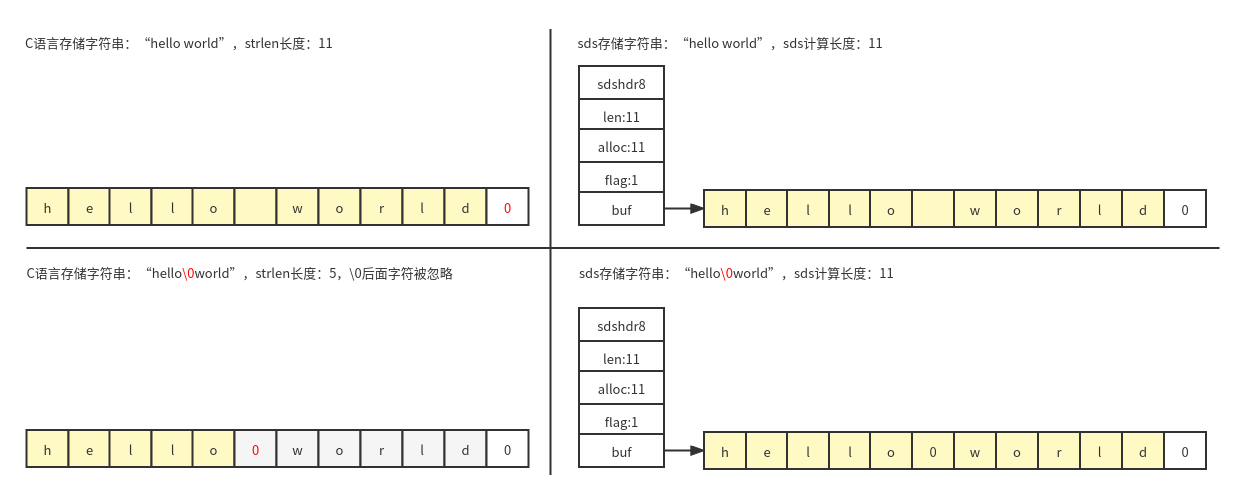
list
redis uses the quicklist structure to replace the original double linked list. quicklist uses double linked list and compressed list internally. This has the advantage of higher memory utilization and reduced memory fragmentation. The structure is as follows:
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmakrs are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
//quickList structure definition
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
//quickList node definition
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;quicklist structure diagram:
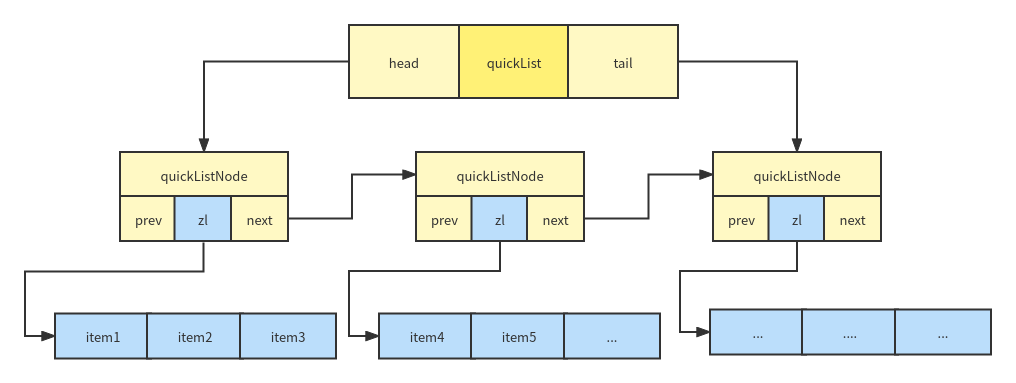
set
The bottom layer of the set type is implemented by hash, and the value is null. The others are the same as hash.
zset
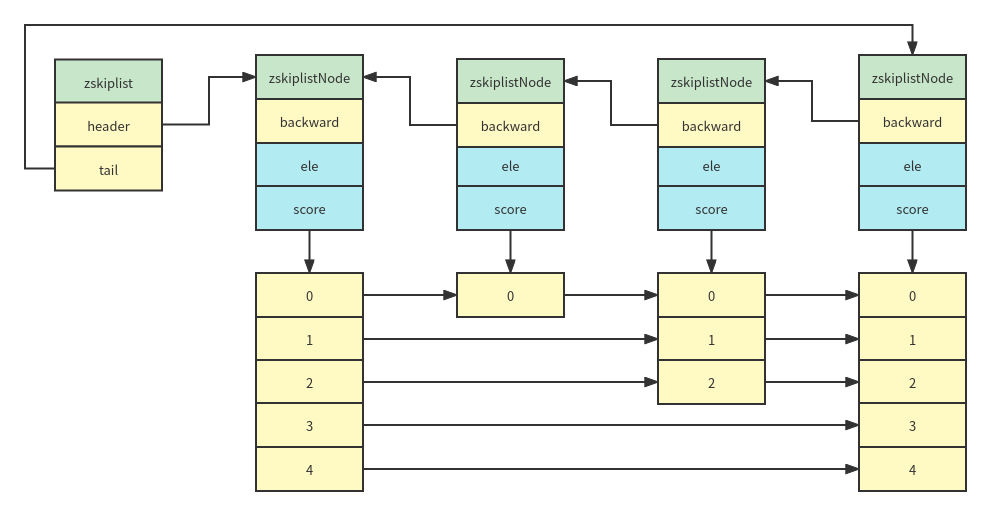
redis uses ziplost and zskipplist structures to save zset types. When there are few elements, it uses ziplost to save space. You can use the parameter zset Max ziplost entries to adjust (128 by default). The zskiplist structure is as follows:
//Jump table node
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
//Jump table structure definition
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
//zset structure definition, use dict to locate elements and jump tables for range query
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;Implementation principle of zskiplist
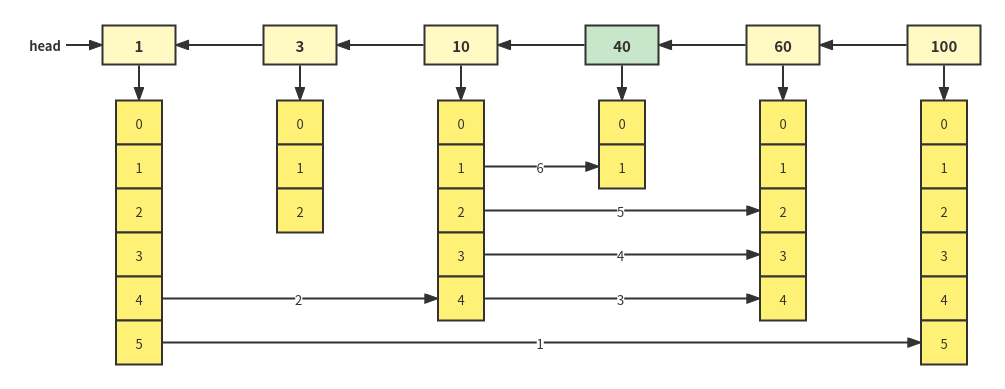
Jump table is a typical space for time data structure. In order to solve the problem that single linked table can only find linearly, multi-layer data index is added. The structure is shown in the figure below:
skiplist query process
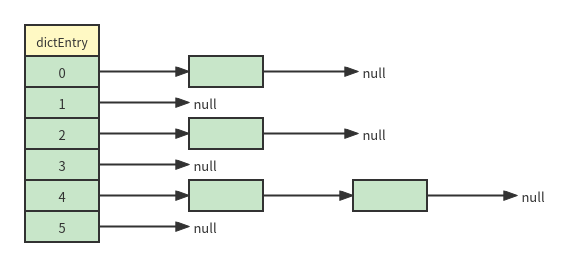
hash
The bottom layer of hash is realized by hash table, and the chain structure is used to solve the hash conflict problem, which is similar to the hashmap structure before Java 8. The structure is as follows:
//hash node definition
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
//Hash type, which defines some hash operation functions
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
int (*expandAllowed)(size_t moreMem, double usedRatio);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
//hash structure definition
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
//dict structure definition
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
} dict;hash structure
redis does not use the tree structure like java8 HashMap to solve the problem of query degradation caused by too many conflicts. Personally, I think it may be due to memory use. Using a tree structure is bound to increase the pointer. If a red black tree is used, an additional color marker bit is required. When there are many key s, the cost is also very considerable.
summary
In the past, I always thought that redis is actually a big HashMap. After reading the redis source code, I found that this idea is a little too superficial. Redis uses a lot of data structures and the use of memory is the ultimate.
Finally: due to the limited personal ability, there are inevitably mistakes in the article. You are welcome to point out.