1, Why use distributed locks
When developing applications, if we need multi-threaded synchronous access to a shared variable, we can use the Java multi-threaded processing we learned, and it can run perfectly without bugs!
However, this is a stand-alone application, that is, all requests will be allocated to the JVM of the current server, and then mapped to the threads of the operating system for processing! The shared variable is just a memory space inside the JVM!
Later, business development requires clustering. An application needs to be deployed to several machines and then load balanced, as shown in the figure below:
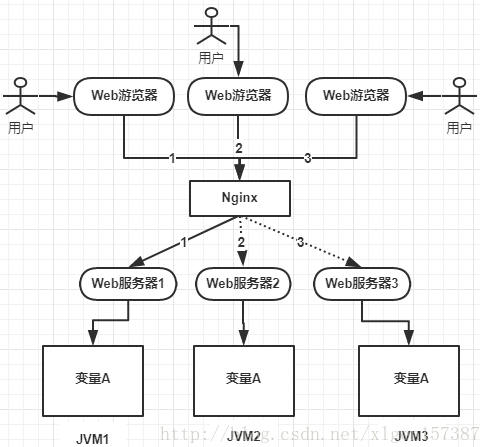
As can be seen from the above figure, variable A exists in the memory of JVM1, JVM2 and JVM3. If no control is added, variable A will allocate A piece of memory in the JVM at the same time. The three requests will operate on this variable at the same time. Obviously, the result is wrong! Even if it is not sent at the same time, the three requests operate the data of three different JVM memory regions respectively. There is no sharing and visibility between variables A, and the processing result is wrong!
If this scenario does exist in our business, we need a way to solve this problem!
In order to ensure that a method or attribute can only be executed by the same thread at the same time in the case of high concurrency, in the case of stand-alone deployment of traditional single application, Java concurrency processing related APIs (such as ReentrantLock or Synchronized) can be used for mutual exclusion control. In the stand-alone environment, Java provides many APIs related to concurrent processing. However, with the needs of business development, after the system deployed by the original single machine has been evolved into a distributed cluster system, the concurrency control lock strategy under the original single machine deployment will become invalid because the distributed system is multi-threaded, multi process and distributed on different machines. The simple Java API can not provide the ability of distributed lock. In order to solve this problem, a cross JVM mutual exclusion mechanism is needed to control the access to shared resources, which is the problem to be solved by distributed locking!
2, What are the conditions for distributed locks
Before analyzing the three implementation methods of distributed lock, first understand what conditions distributed lock should have: 1,In the distributed system environment, a method can only be executed by one thread of one machine at the same time; 2,High availability acquisition lock and release lock; 3,High performance acquisition lock and release lock; 4,Reentrant feature; 5,Have lock failure mechanism to prevent deadlock; 6,It has the non blocking lock feature, that is, if the lock is not obtained, it will directly return the failure of obtaining the lock.
3, Three implementation methods of distributed lock
At present, almost many large websites and applications are deployed distributed, and the problem of data Consistency in distributed scenarios has always been an important topic. The distributed CAP theory tells us that "no distributed system can meet Consistency, Availability and Partition tolerance at the same time, but only two at most." Therefore, many systems have to choose between these three at the beginning of design. In most scenarios in the Internet field, strong Consistency needs to be sacrificed in exchange for high Availability of the system. The system often only needs to ensure "final Consistency", as long as the final time is within the range acceptable to users.
In many scenarios, in order to ensure the final consistency of data, we need a lot of technical solutions to support, such as distributed transactions, distributed locks, etc. Sometimes, we need to ensure that a method can only be executed by the same thread at the same time.
Realize distributed lock based on database; Cache based( Redis Etc.) realize distributed locking; be based on Zookeeper Realize distributed lock;
**
1. Exclusive lock based on Database
**
Table structure
CREATE TABLE `method_lock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Primary key', `method_name` varchar(64) NOT NULL COMMENT 'Locked method name', `state` tinyint NOT NULL COMMENT '1:Not allocated; 2: Assigned', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `version` int NOT NULL COMMENT 'Version number', `PRIMARY KEY (`id`), UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='Methods in locking'
Get lock information first
select id, method_name, state,version from method_lock where state=1 and method_name='methodName';
Possession lock
update t_resoure set state=2, version=2, update_time=now() where method_name='methodName' and state=1 and version=2;
If no update affects a row of data, it indicates that the resource has been occupied by others.
Disadvantages:
1,This lock strongly depends on the availability of the database. The database is a single point. Once the database hangs, the business system will be unavailable. 2,This lock has no expiration time. Once the unlocking operation fails, the lock record will always be in the database, and other threads can no longer obtain the lock. 3,This lock can only be non blocking because of the lack of data insert Operation. Once the insertion fails, an error will be reported directly. Threads that do not obtain locks do not enter the queue. To obtain locks again, you need to trigger the obtain locks operation again. 4,The lock is non reentrant, and the same thread cannot obtain the lock again before releasing the lock. Because the data already exists in the data.
Solution:
1,Is the database a single point? Two databases, two-way synchronization before data. Once hung up, quickly switch to the standby database. 2,No expiration time? Just do a scheduled task and clean up the timeout data in the database at regular intervals. 3,Non blocking? Make one while Cycle until insert Success returns success. 4,Non reentrant? Add a field in the database table to record the host information and thread information of the machine currently obtaining the lock, The next time you acquire a lock, query the database first. If the host information and thread information of the current machine can be found in the database, Just assign the lock to him.
2. redis based implementation
Command for obtaining lock:
SET resource_name my_random_value NX PX 30000
Scheme:
Pring date redis version: 1.6.2
Scenario: when using setIfAbsent(key,value), you want to set an expiration time for the key, and you need to use the return value of setIfAbsent to specify the subsequent process, so you use the following code:
try{
lock = redisTemplate.opsForValue().setIfAbsent(lockKey, LOCK);
logger.info("cancelCouponCode Lock acquired:"+lock);
if (lock) {
// TODO
redisTemplate.expire(lockKey,1, TimeUnit.MINUTES); //The expiration time was set successfully
return res;
}else {
logger.info("cancelCouponCode The lock is not obtained and the task is not executed!");
}
}finally{
if(lock){
redisTemplate.delete(lockKey);
logger.info("cancelCouponCode When the task is over, release the lock!");
}else{
logger.info("cancelCouponCode No lock was acquired, no need to release the lock!");
}
}
There is a problem with this Code: when setIfAbsent succeeds, disconnect and set the expiration time as stringredistemplate expire(key,timeout); It cannot be executed. At this time, a large number of data without expiration time will exist in the database. One idea is to add transaction management. The modified code is as follows:
stringRedisTemplate.setEnableTransactionSupport(true);
stringRedisTemplate.multi();
boolean store = stringRedisTemplate.opsForValue().setIfAbsent(key,value);
if(store){
stringRedisTemplate.expire(key,timeout);
}
stringRedisTemplate.exec();
if(store){
// todo something...
}
This ensures the consistency of the whole process. This is OK, but the fact is always unsatisfactory, because I found the following contents in the document:
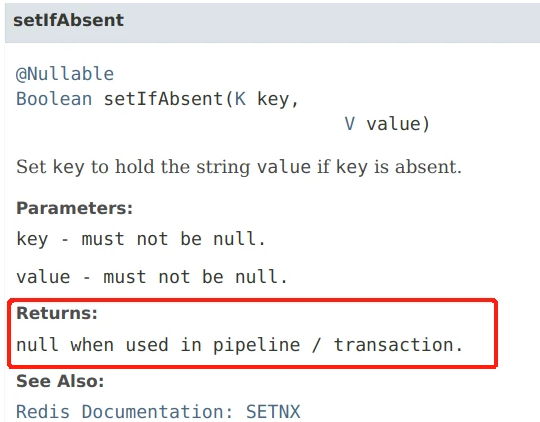
After adding transaction management, the return value of setIfAbsent turns out to be null, so there is no need to judge whether to add the expiration time later according to the return value.
solve:
stringRedisTemplate.setEnableTransactionSupport(true);
stringRedisTemplate.multi();
String result = stringRedisTemplate.opsForValue().get(key);
if(StringUtils.isNotBlank(result)){
return false;
}
// The lock expires in 1 hour
stringRedisTemplate.opsForValue().set(key, value,timeout);
stringRedisTemplate.exec();
// todo something...
In fact, there is a problem with the code above. When concurrency occurs, string result = stringredistemplate opsForValue(). get(key); Here, multiple threads will get empty keys at the same time and write dirty data at the same time.
Final solution:
Method 1 Use stringredistemplate exec(); The return value of determines whether setIfAbsent is successful
stringRedisTemplate.setEnableTransactionSupport(true);
stringRedisTemplate.multi();
stringRedisTemplate.opsForValue().setIfAbsent(lockKey,JSON.toJSONString(event));
stringRedisTemplate.expire(lockKey,Constants.REDIS_KEY_EXPIRE_SECOND_1_HOUR, TimeUnit.SECONDS);
// Here, the result will return the result of each operation in the transaction. If the setIfAbsent operation fails, the result[0] will be false.
List result = stringRedisTemplate.exec();
if(true == result[0]){
// todo something...
}
Method 2 Upgrade redis version to above 2.1, and then use
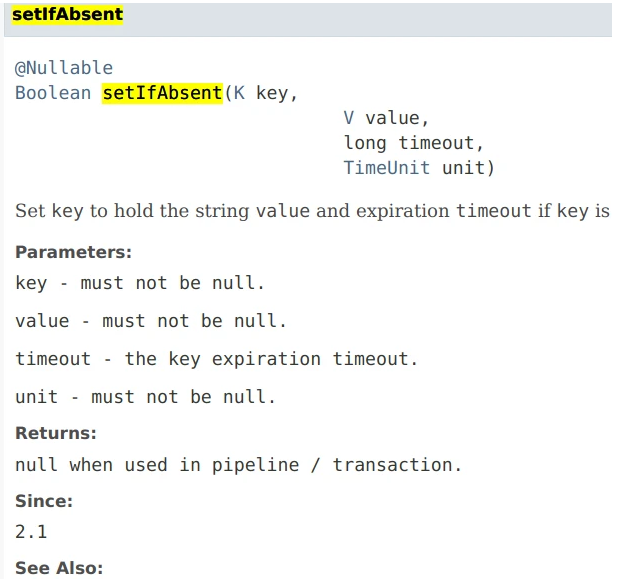
Set the expiration time directly in setIfAbsent
update :
When java uses redis transactions, it cannot directly use multi() and exec() in Api. In this way, the stringRedisTemplate used twice by multi() and exec() is not a connect, which will lead to deadlock. The correct method is as follows:
private Boolean setLock(RecordEventModel event) {
String lockKey = event.getModel() + ":" + event.getAction() + ":" + event.getId() + ":" + event.getMessage_id();
log.info("lockKey : {}" , lockKey);
// Processing with sessionCallBack
SessionCallback<Boolean> sessionCallback = new SessionCallback<Boolean>() {
List<Object> exec = null;
@Override
@SuppressWarnings("unchecked")
public Boolean execute(RedisOperations operations) throws DataAccessException {
operations.multi();
stringRedisTemplate.opsForValue().setIfAbsent(lockKey,JSON.toJSONString(event));
stringRedisTemplate.expire(lockKey,Constants.REDIS_KEY_EXPIRE_SECOND_1_HOUR, TimeUnit.SECONDS);
exec = operations.exec();
if(exec.size() > 0) {
return (Boolean) exec.get(0);
}
return false;
}
};
return stringRedisTemplate.execute(sessionCallback);
}
Disadvantages:
In this scenario (master-slave structure), there is obvious competition:
client A from master Get lock,
stay master Synchronize locks to slave Before, master It's down.
slave Node promoted to master Node,
client B The same resource was obtained by the client A Another lock that has been acquired. Safety failure!
3. Implementation based on zookeeper
Let's review the concept of Zookeeper node:
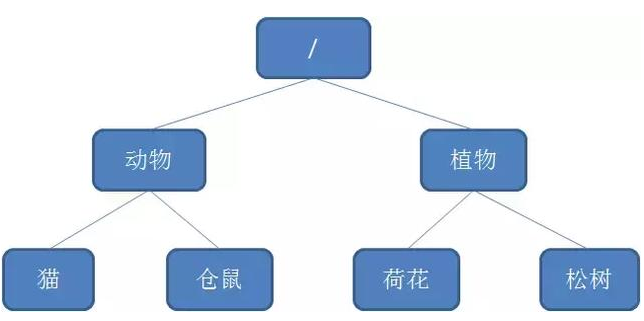
The data storage structure of Zookeeper is like a tree, which is composed of nodes called Znode.
There are four types of Znode:
1. PERSISTENT node
The default node type. After the client that created the node disconnects from zookeeper, the node still exists.
2. PERSISTENT_SEQUENTIAL node
The so-called sequential node means that when creating a node, Zookeeper numbers the node name according to the creation time sequence:
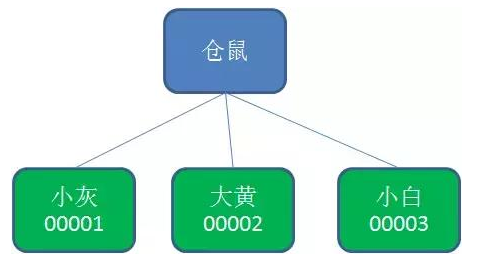
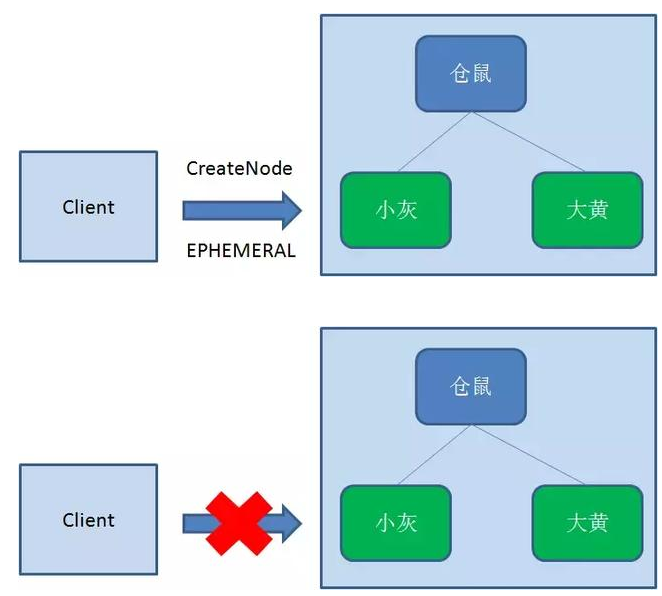
3. Temporary node (EPHEMERAL)
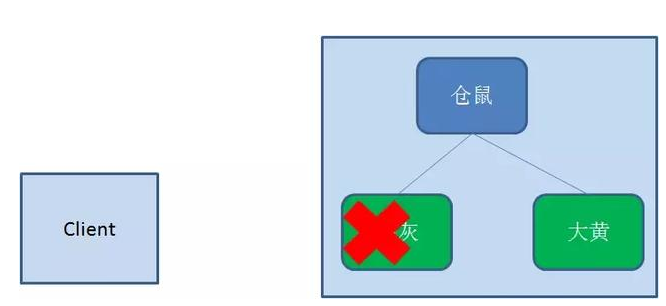
In contrast to persistent nodes, temporary nodes are deleted when the client creating the node disconnects from zookeeper:
4. Temporary sequential node (EPHEMERAL_SEQUENTIAL)
As the name suggests, temporary sequential node combines the characteristics of temporary node and sequential node: when creating a node, zookeeper numbers the name of the node according to the time sequence of creation; When the client that created the node disconnects from zookeeper, the temporary node is deleted.
Principle of Zookeeper distributed lock
Zookeeper distributed lock just applies temporary sequential nodes. How to achieve it? Let's look at the detailed steps:
Acquire lock
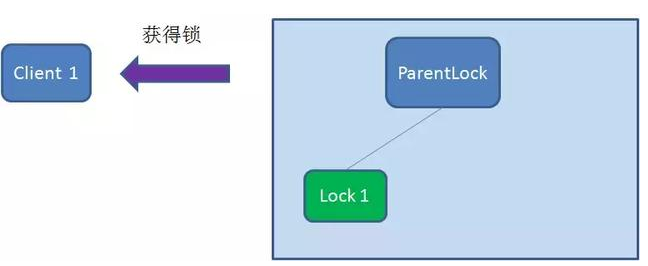
First, create a persistent node ParentLock in Zookeeper. When the first client wants to obtain a lock, it needs to create a temporary sequence node Lock1 under the ParentLock node.
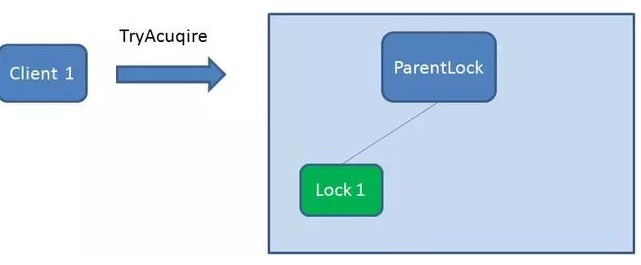
After that, Client1 finds all temporary order nodes under ParentLock and sorts them to determine whether the node Lock1 created by itself is the one with the highest order. If it is the first node, the lock is successfully obtained.
At this time, if another client Client2 comes to obtain the lock, create a temporary sequence node Lock2 in the ParentLock download.
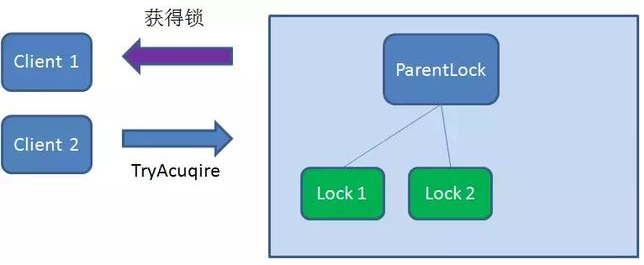
Client2 finds and sorts all temporary order nodes under ParentLock, and judges whether the node Lock2 created by itself is the one in the top order. It is found that node Lock2 is not the smallest.
Therefore, Client2 registers a Watcher with the node Lock1 whose ranking is only higher than it to monitor whether the Lock1 node exists. This means that Client2 failed to grab the lock and entered the waiting state.
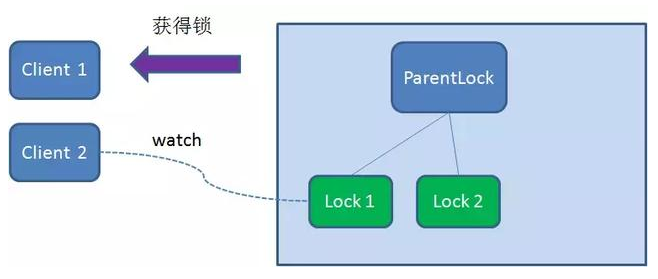
At this time, if another client Client3 comes to obtain the lock, create a temporary sequence node Lock3 in the ParentLock download.
Client3 finds and sorts all temporary order nodes under ParentLock, and judges whether the node Lock3 created by itself is the one in the top order. As a result, it is also found that node Lock3 is not the smallest.
Therefore, Client3 registers a Watcher with the node Lock2 that is only ahead of it to listen for the existence of the Lock2 node. This means that Client3 also failed to grab the lock and entered the waiting state.
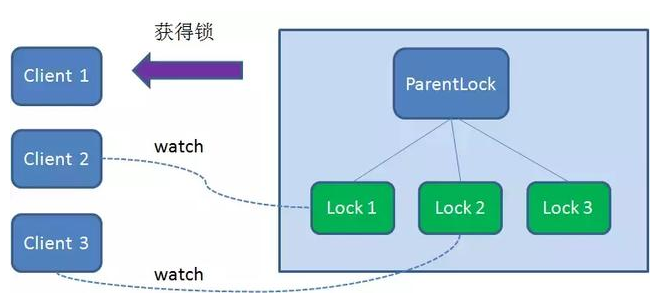
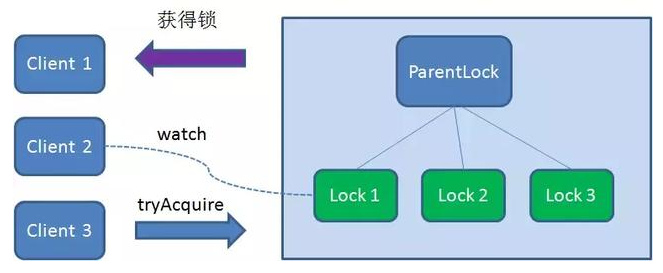
In this way, Client1 gets the lock, Client2 listens to Lock1, and Client3 listens to Lock2. This just forms a waiting queue, much like the one that ReentrantLock in Java relies on
Release lock
There are two situations to release the lock:
1. When the task is completed, the client displays release
When the task is completed, Client1 will display the instruction calling to delete node Lock1.
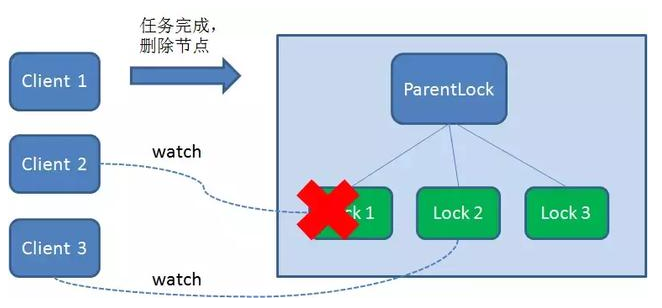
2. The client crashes during task execution
If Duang crashes during the execution of the task, Client1 that has obtained the lock will disconnect the link with the Zookeeper server. Depending on the characteristics of the temporary node, the associated node Lock1 is automatically deleted.
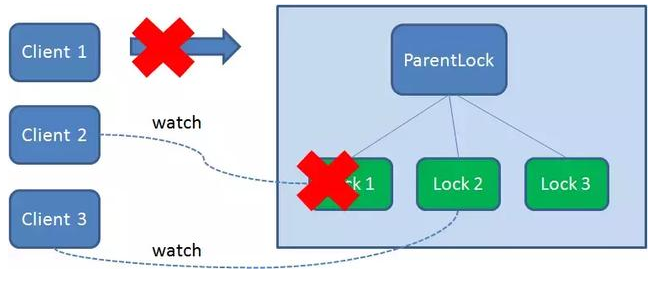
Because Client2 has been monitoring the existence status of Lock1, when the Lock1 node is deleted, Client2 will immediately receive a notification. At this time, Client2 will query all nodes under ParentLock again to confirm whether the created node Lock2 is the smallest node at present. If it is the smallest, Client2 naturally obtains the lock.
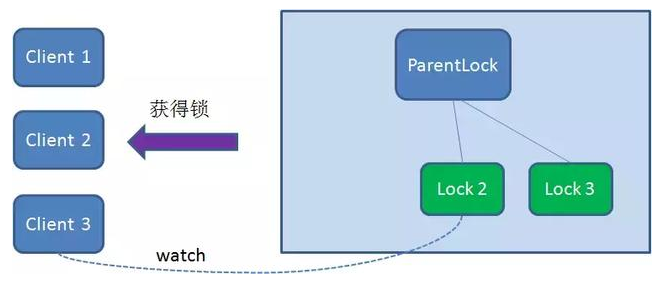
Similarly, if Client2 deletes node Lock2 because the task is completed or the node crashes, Client3 will be notified.
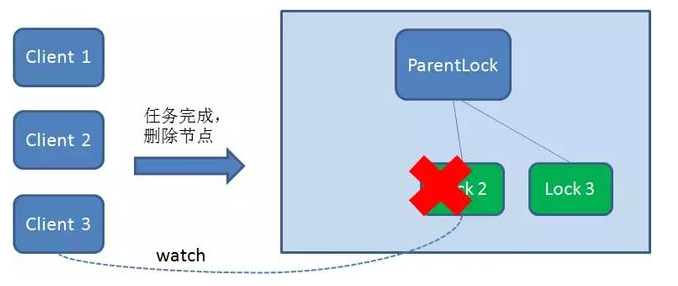
Finally, Client3 successfully got the lock.
Scheme:
You can directly use the zookeeper third-party library cursor client, which encapsulates a reentrant lock service.
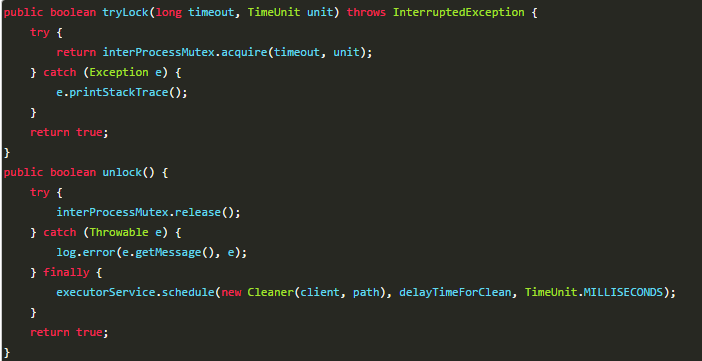
InterProcessMutex provided by cursor is the implementation of distributed lock. The acquire method is used to obtain the lock from the user, and the release method is used to release the lock.
Disadvantages:
The performance may not be as high as the cache service. Because every time in the process of creating and releasing locks, instantaneous nodes must be dynamically created and destroyed to realize the lock function. ZK Nodes can be created and deleted only through Leader Server to execute, and then the data is not the same as all Follower On the machine.
be careful: Actually, use Zookeeper It may also cause concurrency problems, but it is not common. Considering this situation, due to network jitter, the client can ZK Clustered session The connection is broken, then zk Thought the client hung up, The temporary node will be deleted, and other clients can obtain the distributed lock. Concurrency problems may arise. This problem is not common because zk There is a retry mechanism, once zk The cluster cannot detect the heartbeat of the client, Will try again, Curator The client supports multiple retry strategies. The temporary node will not be deleted until it fails after multiple retries. (Therefore, it is also important to choose an appropriate retry strategy. We should find a balance between lock granularity and concurrency.)
4. Summary
Advantages and disadvantages of Zookeeper and Redis distributed locks:
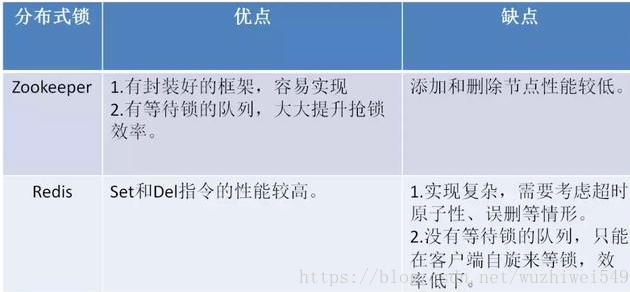
Comparison of three schemes
None of the above methods can be perfect. Just like CAP, it cannot meet the requirements of complexity, reliability and performance at the same time. Therefore, it is the king to choose the most suitable one according to different application scenarios.
From the perspective of implementation complexity (from low to high)
Zookeeper > = cache > Database
From a performance perspective (high to low)
Cache > zookeeper > = database
From the perspective of reliability (from high to low)
Zookeeper > cache > Database