Regular parsing (re module)
Single character:
- ...: All characters except newlines
- []: [aoe] [a-w] matches any character in the set
- \ d: Number [0-9]
- \ D: Non-digital
- \ w: Numbers, letters, underscores, Chinese
- \ W: Nonw
- \ s: All blank character packages, including spaces, tabs, page breaks, and so on. It is equivalent to [f n r t v].
-
\ S: Non-blank
Quantitative Modification: - * Any number of times >= 0
- + At least once >= 1
- ?: Is it possible to do it 0 or 1 times?
- {m}: Kuding m times hello{3,}
- {m,}: at least m times
-
{m,n}: m-n times
Borders: - $: End with _____________.
-
^ Start with ______________
Grouping: - (ab)
Greedy mode:.*
Non-greedy (inert) model: *?
Usage method
re.I: Ignore case and case
re.M: Multi-line matching
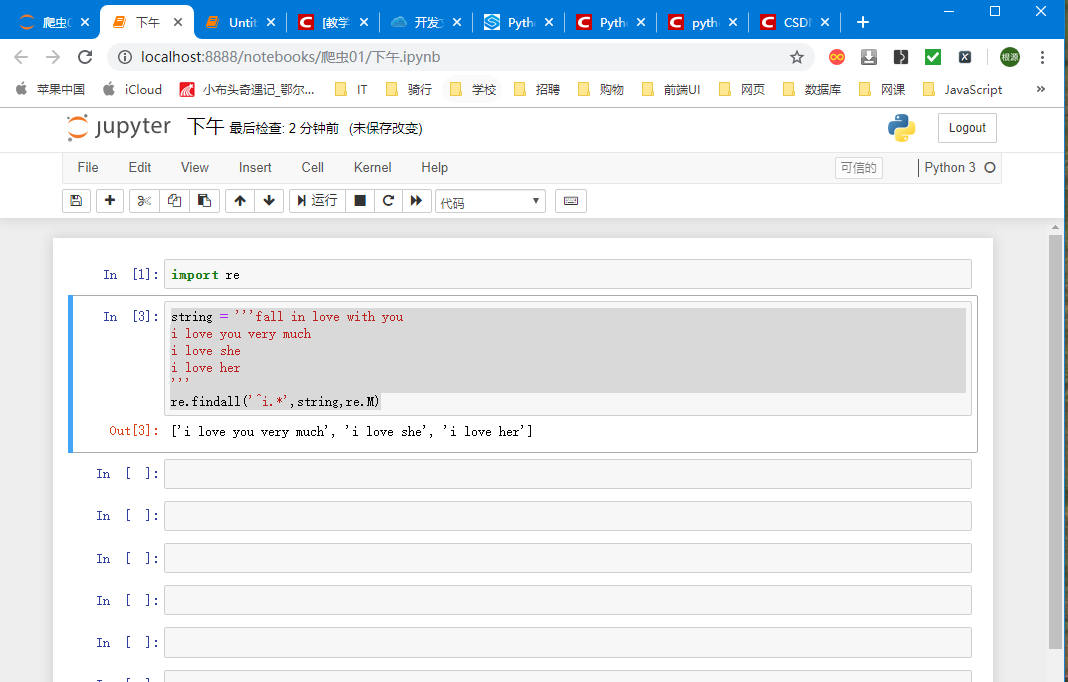
string = '''fall in love with you i love you very much i love she i love her ''' re.findall('^i.*',string,re.M)
re.S: One-line matching
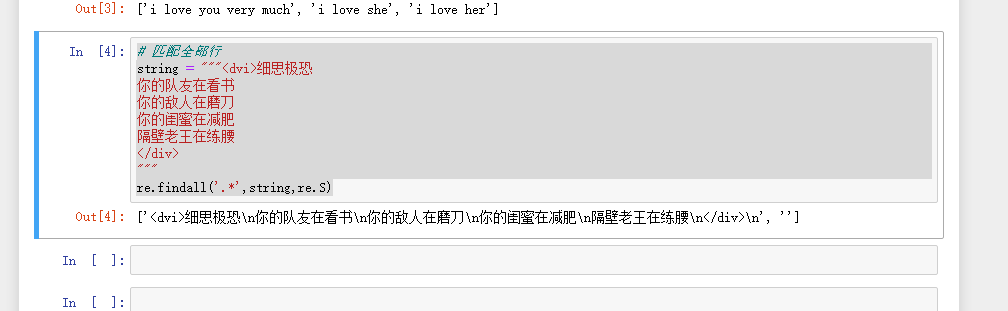
# Match all rows
String = ""< DVI > Reflect on Terror
Your teammates are reading books
Your enemies are sharpening their knives
Your girlfriend is losing weight
Next door Lao Wang is practicing waist
</div>
"""
re.findall('.*',string,re.S)
re.sub (regular expression, replacement content, string)
Example
Click the picture of Encyclopedia of Gongshi
import requests import re import urllib import os url = 'https://www.qiushibaike.com/pic/page/%d/?s=5216960' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' } # Create a folder for storing pictures if not os.path.exists('./qiutu'): os.mkdir('./qiutu') start_page = int(input('enter a start pageNum:')) end_page = int(input('enter a end pageNum:')) for page in range(start_page,end_page+1): new_url = format(url%page) page_text = requests.get(url=new_url,headers=headers).text img_url_list = re.findall('<div class="thumb">.*?<img src="(.*?)" alt=.*?</div>',page_text,re.S) for img_url in img_url_list: img_url = "https:"+img_url imgName = img_url.split('/')[-1] imgPath = 'qiutu/'+imgName urllib.request.urlretrieve(url=img_url,filename=imgPath) print(imgPath,'Download success!') print("over!")
bs4 analysis
Download bs4 and lxml
pip install bs4 pip install lxml
Analytical Principle
- Load the source code to be parsed into the bs object
- Calling related methods or attributes in bs object to locate related labels in source code
- Getting text or attribute values between tags that will be located
Basic use
Use process:
- Guide: from BS4 import Beautiful Soup
- Usage: html can be converted into BeautifulSoup objects, and the specified node content can be found by attributes or attributes.
(1) Transform local files:
- Sop = BeautifulSoup (open ('local file'),'lxml')
(2) Transforming network files;
- Sop = BeautifulSoup ('string type or byte type','lxml')
(3) Print soup object to display content in html file
Basic method calls:
(1) Search by label name
- Sop. a can only find the first label that meets the requirements
(2) Getting attributes
- Sop.a.attrs retrieves all attributes and attribute values of a and returns a dictionary
- soup.a.attrs ['href'] Gets href attributes
- Sop.a ['href'] can also be abbreviated as this form.
(3) Access to content
- soup.a.string
- soup.a.text
- soup.a.get_text()
[Note] If the tag still has a tag, string returns None and the other two returns text.
(4) find: Find the first tag that meets the requirements
- soup.find('a') finds the first one that meets the requirements
- soup.find('a',title="xxx")
- soup.find('a',alt="xx")
- soup.find('a',class="xx")
- soup.find('a',id="xxxx")
(5) find_all: Find all tags that meet the requirements
- soup.find_all('a')
- soup.find_all(['a','b']) finds all a and B Tags
- soup.find_all('a', limit=2) limits the first two
(6) Specified content selected by selector
select:soup.select('#feng')
- Common selectors: label selector (a), class selector (.), id selector (#), hierarchical selector
Example
Download Romance Novels of the Three Kingdoms from Ancient Poetry and Literature Website Website
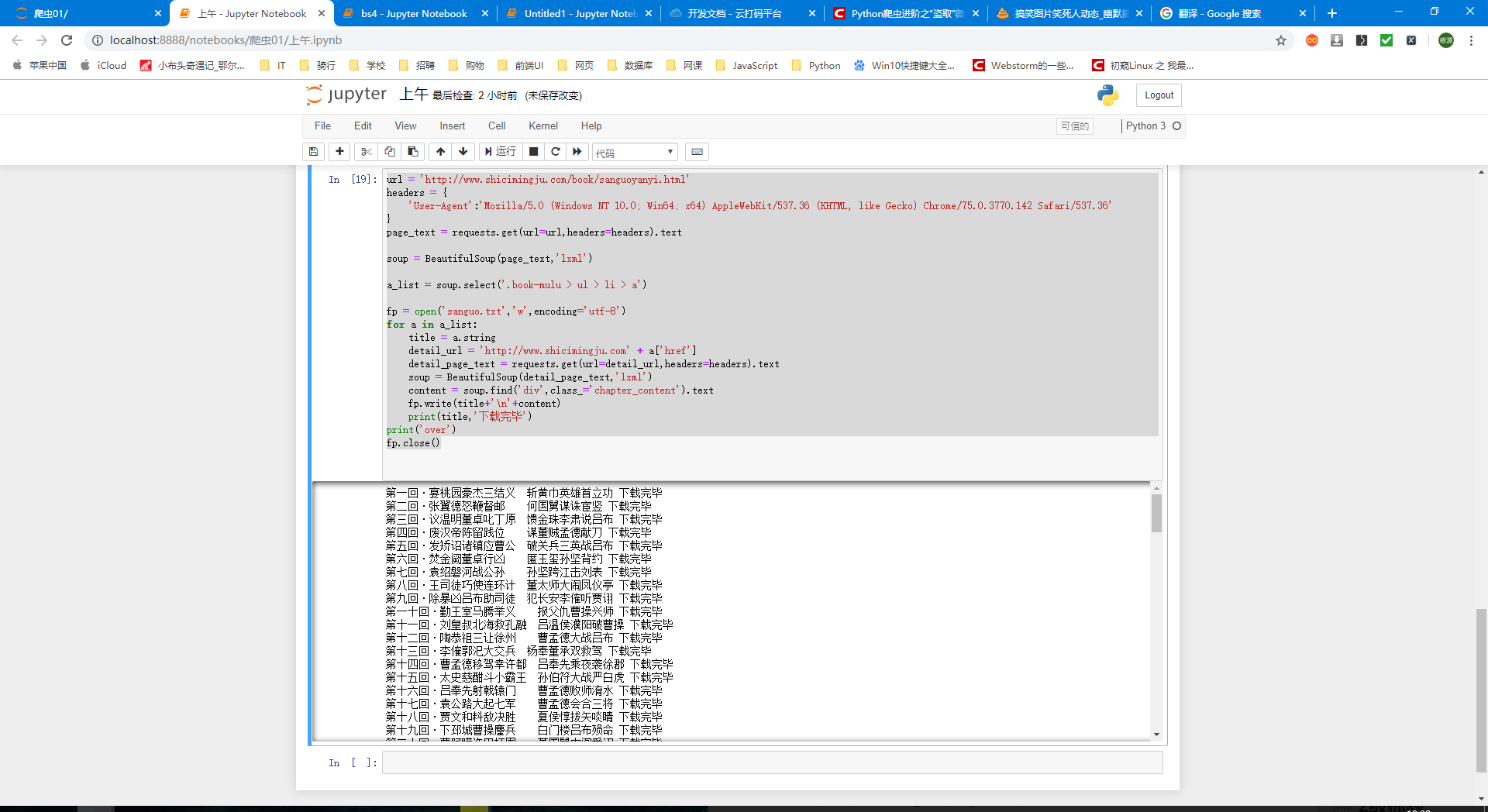
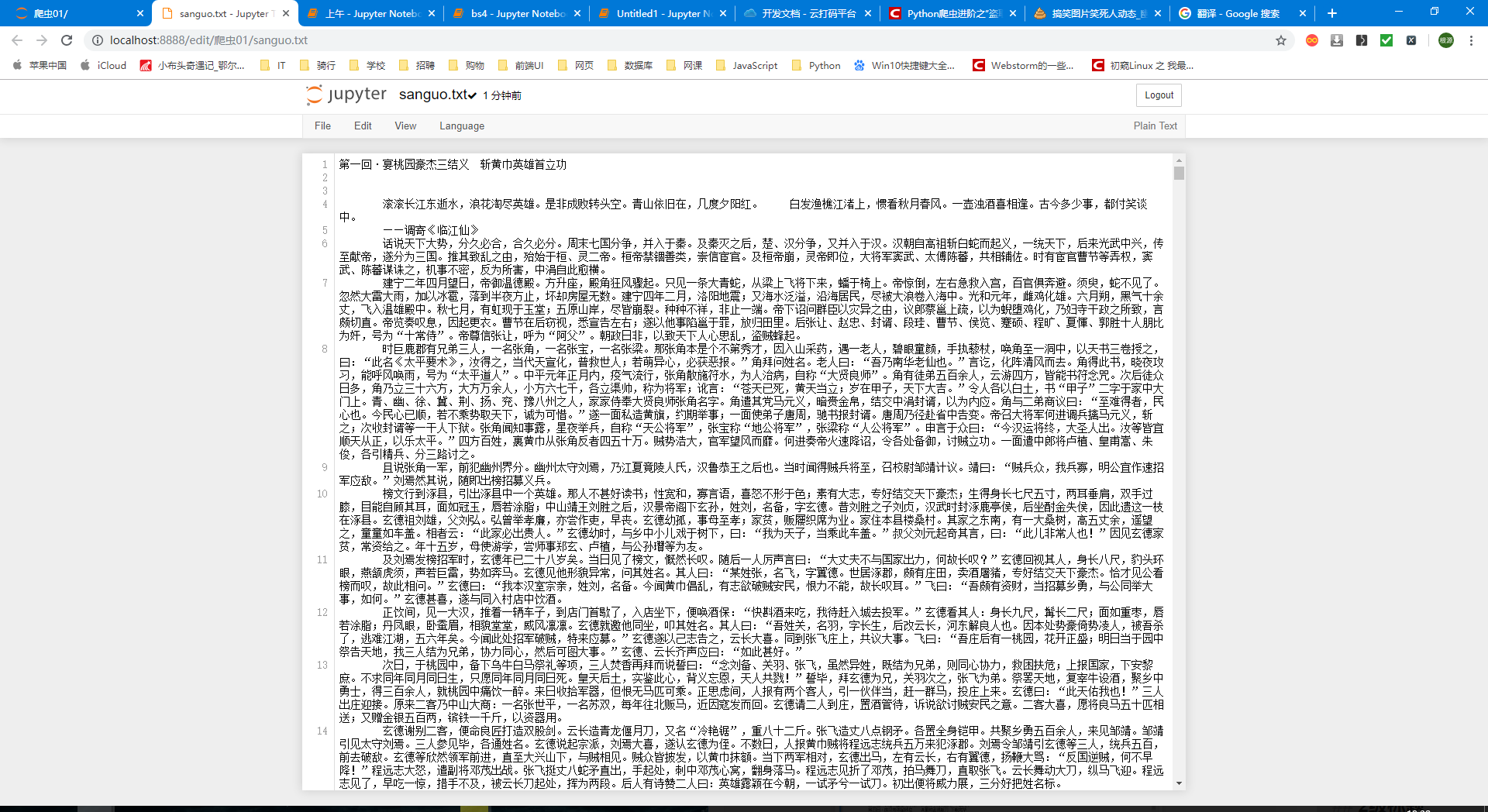
import requests from bs4 import BeautifulSoup url = 'http://www.shicimingju.com/book/sanguoyanyi.html' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' } page_text = requests.get(url=url,headers=headers).text soup = BeautifulSoup(page_text,'lxml') a_list = soup.select('.book-mulu > ul > li > a') fp = open('sanguo.txt','w',encoding='utf-8') for a in a_list: title = a.string detail_url = 'http://www.shicimingju.com' + a['href'] detail_page_text = requests.get(url=detail_url,headers=headers).text soup = BeautifulSoup(detail_page_text,'lxml') content = soup.find('div',class_='chapter_content').text fp.write(title+'\n'+content) print(title,'Download finished') print('over') fp.close()