4.3 data definition
4.3. 1 Definition and deletion of mode
What is a database schema? Database schema is a logical grouping object. Database schema is a collection of database objects, which contains various tables, views, stored procedures, indexes, etc. Imagine a schema as a container for objects. Database schema can be used as a namespace to prevent object name conflicts from different schemas. Patterns help determine who can access database objects and simplify security management
==The schema to be deleted cannot contain any objects. If the schema contains objects, the drop statement fails
4.3. 2 definition, deletion and modification of basic table
Create a table named Users with the user name VuserName and password vPassword fields
create table users( vUsername varchar(18) not null, vPassword varchar(20) not null )
Create a student table. Specify the student number as the main keyword to realize the specified constraints
create table student( Sno char(10) primary key, Sname char(20) not null, Ssex char(2) )
Create SC table with SQL statement
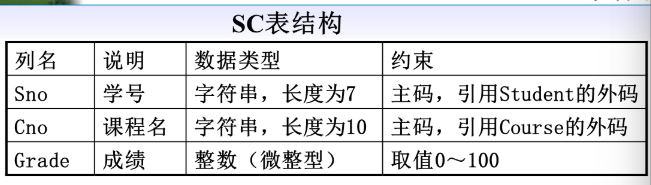
create table SC( Sno char(7), Cno char(10), Grade tinyint, check (grade>=0 and grade<=100), primary key(sno,cno), primary key(sno)references student(sno), primary key(cno)references course(cno) )
Data query
Retrieve the first three rows of data from the Student table
select top 3 * from student select top 3 * from student
Query the information of students whose age is not 19-21
select sno,sname,ssex,sage from student where sage not between 19 and 21
Query the information of teachers who are professors or associate professors
select * from teacher where trop in('professor','associate professor')
Query the Student information with only four characters on the @ left of the email address in the Student table. The results show three columns: name, department and email address
select sname,sdept,email from student where sname like '____@%'
Retrieve SPT in master database_ Data row with empty low field in values table
select * from spt_values where low is null
Displays all rows of the Course table, arranged in descending order by Course name
select * from course group by cname desc
All rows in the Course table are displayed, arranged in descending order according to the Course name, and then arranged in ascending order according to the Course number when the learning score is the same
select * from course group by cname desc,cno asc
==Count(*) returns the number of records in the table. The count (column_name) function returns the number of values of the specified column (null is not counted)
Classify the course table according to compulsory and elective courses, and count the number of courses in each category
select xklb category,count(cname)
The studnet table is grouped by major and gender to display the number of students of each major and gender. The results are displayed in descending order of the number of students
select smajor,ssex,count from student group by smajor,ssex order by count(sno) desc
For the teacher table, the professional title and the corresponding number of people are displayed. It is required that only the statistical number of people is greater than or equal to 5
==The having phrase is used to filter groups. The difference between where and having is that where filters the original data before grouping. Having is the filtering of aggregated (grouped) data
SELECT TROPT,COUNT(TROPT) FROM teacher group by tropt having count(tropt)>=5
4.4. 3 multi table connection query
Multi table join query actually queries data through the correlation of common columns between various tables. It is the most important feature of relational database. Connection query can be divided into three categories: inner connection, outer connection and cross connection
- Inner join: it is the most typical and commonly used join query. It matches according to the common columns in the table. Only the data that meets the matching conditions can be queried. In general, internal join queries are used when there is a primary foreign key relationship between two tables
- The '=' comparison operator is usually used to judge whether the two columns of data are equal. The association between tables is carried out by using the INNER JOIN keyword.
- The left outer connection contains all rows of coordinates. If there is no match in the left table and the right table, the part of the corresponding row and the right table in the result is empty (NULL)
- Full external connection:
The process of performing a connection operation
- First, take the first tuple in Table 1, scan table 2 from the beginning, and pay attention to finding tuples that meet the connection conditions
- When Hu is found, the first tuple in Table 1 is spliced with the tuple to form a tuple in the result table
- After all the queries in Table 2 are completed, the second tuple in Table 1 is retrieved. Then scan from the beginning
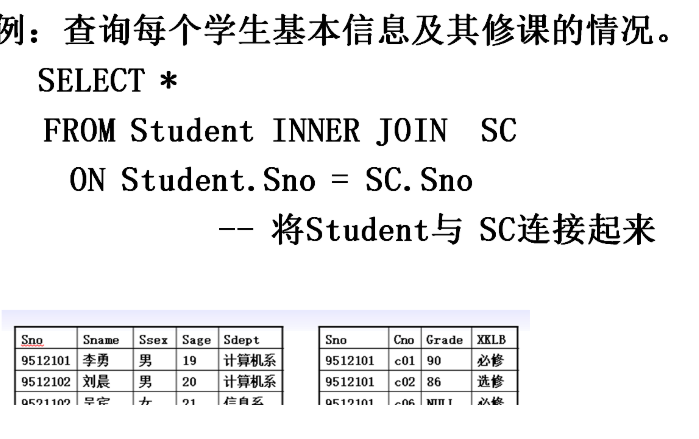
select * from student inner join sc on sc.sno=student.sno select * from student,sc where student.sno=sc.sno
The join results of the two tables contain all the columns of the two tables. The Sno column is repeated twice, which is unnecessary. Therefore, when you write a query statement again, you should remove these duplicate columns = = write the required column name directly in the select clause, not *)
Query the shock situation of students in the information department, and ask to list the students' names, course numbers and grades
select sname,cno,grade from student join sc on student.sno=sc.sno where sdept ='Information system'
  **Query the course status of students, including students who have taken courses and students who have not taken courses** ```sql select student.sno,sname,cno,grade from student left outer join sc on student.sno=sc.sno
select student.sno,sname,cno,grade from sc right outer join student on student.sno=sc.sno
Connect the student table and the sc table to the outside left, that is, the student's information will be displayed regardless of whether the student elects a course or not
select student.sno,student.sname,sc.sno,sc.grade from student left outer join sc on student.sno=sc.sno
4.4. 4 nested query
- Subquery with in: the subquery result introduced through in is a list containing zero or more values. After the subquery returns results, the external query will use these results
- Use ANY,ALLL OR SOME
- Exists: note that the subquery introduced by exists is slightly different from other subqueries in the following aspects. The exists keyword is not preceded by a column name, constant, or other expression. The selection list of subqueries introduced by EXIST is usually composed of asterisks
Query the information of students with an examination score of 48 in a subject
select * from student where sno=(select sno from sc where grade=48)
The above is not allowed
Query the student information of elective courses in the SC table
select * from student where sno in(select distinct sno from sc)
In the classroom table, retrieve the information of male teachers older than any female teacher
select * from teacher where tsex='male' and tage>all(select tage from teacher where tsex='female')
Query the basic information of students who have taken B004 course
select * from student where exists (select * from sc where sno=student.sno and cno='B004')
Query the basic information of all students studying in the same major as the kingdom
select sno,sname,smajor, from student s1 where exists (select * from student s2 where s1.smajor=s2.smajor and s2.sname='kingdom')
Inquire about students studying in the same department as Liu Chen
select sno,sname,sdept from student where sdept=(select sdept from student where sname='Liu Chen') and sname!='Liu Chen'
Query the student number and name of students with scores greater than 90
select sno,sname from student where sno in(select sno from sc where grade >90)
select student.sno,sname from student,sc where student.sno=sc.sno and grade>90
Query the student number and name of the students who have taken the database foundation
Implement with sub query
select sno,sname from student where sno in (select sno from sc where cno in( select cno from course where cname='Database foundation' ))
Join query with multiple tables
select student.sno,sname from student,sc,course where student.sno=sc.sno and sc.cno=course.cno and cname='Database foundation'
Query the number of courses and average score of students taking database and application courses
select sno,count(*) avg(grade) from sc,course where sc.cno=course.cno and cname='Database and Application' group by sno
select sno,count(*),avg(grade) from sc where sno in (select sno from sc,course where sc.cno=c.cno and cname='Database application') group by sno
Query the student number and grade of students who have taken the 'c02' course and whose grade is higher than the average score of this course
select sno,grade from sc where cno='c02' and grade>(select avg(grade) from sc where cno = 'c02')
Query the name and age of students younger than a student in the Department of Information Science in other departments
select sname,sage from student where sage<any(select sage from student where sdept='is') and sdept<>'is'
select sname,sgae from student where sage<(select max(sage) from student where sdept='is') and sdept<>'is'
Concept of unrelated subquery: when performing set based test or comparison test with subquery, the subquery is executed first, and then the outer query is executed based on the results of the subquery. The sub query is executed only once, and the query conditions of the sub query do not depend on the outer query. Such subqueries are called irrelevant subqueries or nested subqueries
Query the names of all students who have taken c01 course
Using nested queries
select sname from student where exists (select * from sc where sno=student.sno and cno='c01')
Note: the processing process is from outside to inside. The results of the inner layer are determined by the value of the outer layer, and the execution times of the inner layer are determined by the number of results of the outer layer
Note: since the subquery of exists can only return town or false values, it is meaningless to give the column name here. Therefore, in the subquery with exists, the target list expression is usually used*
Query the names of all students who have taken c01 course
select sname from student,sc where student.sno=sc.sno and cno='c01'
select sname from student where sno in( select sno from sc where cno='c01' )
Query the name and Department of students who do not take c01 course
select sname,sdept from student where sno not in (select sno from sc where cno='c01')
Concept of related sub query: sub query with EXISTS is often called related sub query because it involves association with outer table data. The query criteria of the sub query depend on the parent query

4.4. 5 set query
The query results of select statements are a collection of tuples, so the query results of multiple select statements can be merged, The three operations including Union, intersect and excpet can be performed on the premise that the select statement must have the same quantity and be compatible with the same type. Note that the union operation has two uses: Union and UNION ALL. The former removes the duplicate tuple. The latter does not
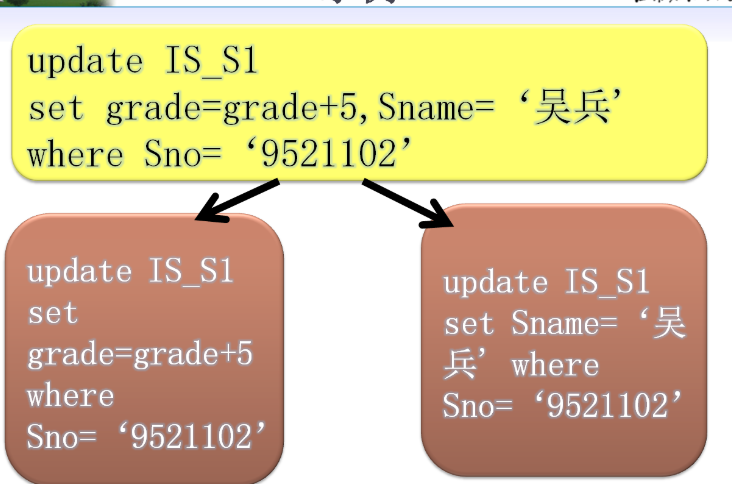
4.5 data update
4.6 view
Is a table exported from one or more basic tables. The structure and data of the view are the results of the query on the data table.
Only the definition of the view is stored, and the corresponding data is not stored
When the data in the base table changes, the data queried from the view also changes
- It provides a certain degree of logical independence
- Improved data security
- Enables users to view the same data from multiple perspectives
- Simplify data query statements
4.6. 1 define view
create view <>[] as Subquery statement
Subqueries usually do not contain an order by clause. When defining a view, either specify all view columns or omit all without writing. If omitted, the column name of the view is the same as the subquery column name.
Create view
You need to explicitly specify all the column names that make up the view
- A target column is a computed function or a list expression and no alias is specified
- When connecting multiple tables, the fields with the same name are selected as the view fields
- You need to choose a new and more appropriate column name for a column in the view
Define a single source table view
create view is_student as select sno,sname,sage from student where sdept='is'
Define multi-source table views
This means that there can be more than one original table defining the sub query of the view. Such a view is generally only used for query and not for modifying data. You can also modify only for a single table.
Establish a view of students in the information department who have taken the course 'c01', including student number, name and grades
create view v_is_s1 as select student.sno,sname,grade from student,sc where student.sno=sc.sno and sdept='is' and cno='c01'
Establish a view of student number, name and score of students with more than 90 scores who have taken c01 course in the information department
create view v_is_s2 as select sno,snmae,grade from v_is_s1 where grade>=90
Because the data in the view is not actually stored, you can set some derived attribute columns as needed when defining the view, and save the calculated values in these derived attribute columns
create view bt_S(sno,sname,sbirth) as select sno,sname,2021-sage from student
A view with grouping statistics means that the sub query of the view contains a group by clause. Such a view can only be used for queries. Cannot be used to modify data
create view s_g(sno,average) as select sno,avg(grade) from sc group by sno

Modify the previously defined view S_G (Sno, average grade) to make it count the average score of each student and the total number of courses
alter view s_g(sno,avggrade,count_cno) as select sno,avg(grade),count(*) from sc group by sno
Delete view
drop view is_student
If the deleted view is used as the data source of other views, the exported view will not be used in. Similarly, if the base table that defines the view is deleted, the view will not be available.
View Resolution

Modifying data in a view
- If the update statement affects the data of multiple tables, it cannot be modified
- If the value of a column is calculated or obtained by an aggregate function, the value of the column cannot be modified
4.7 index
In relational database, index is a separate and physical storage structure for sorting the values of one or more columns in the database. It is the collection of one or several column values in a table and the corresponding data pointing to the physical marks of these values in the table. It also has a logical pointer list
The function of index is equivalent to the catalogue of books, which can quickly find the required content with more pages in the catalogue
General principles for indexing:
- If an attribute or attribute group often appears in query criteria, consider indexing the attribute or attribute group
- If an attribute is often used as the basis column for grouping, consider indexing the attribute
- If an attribute and attribute group often appear in the connection condition of a connection operation, consider indexing the attribute or attribute group
4.7. 1 Classification of index
- Clustered index: records are arranged in the order specified by the index key, so that records with the same index key value are physically clustered together. Only one clustered index can be built for a table
- The clustered index is equivalent to using the Pinyin search of the dictionary, because the stored records of the clustered index are physically continuous, that is, after Pinyin a, it must be the same as b
- Nonclustered index: it does not affect the actual storage order of records in a table. A table can establish multiple nonclustered indexes
- A nonclustered index is equivalent to using the radicals of a dictionary to search. A nonclustered index is logically continuous, but the physical storage is not continuous
Classification of indexes
- Unique index: the index value of each row is unique (if a unique constraint is created, the system will automatically create a unique index)
- Primary key index: when creating a table, the specified primary key column will automatically create a primary key index, which has unique characteristics and is a specific type of unique index