This article is shared from Huawei cloud community< How to update data in Clickhouse >, author: bully.
As an OLAP database, Clickhouse has very limited support for transactions. Clickhouse provides a station operation (through the ALTER TABLE statement) to UPDATE and DELETE data, but it is a "heavier" operation. Unlike UPDATE and DELETE in standard SQL syntax, it is asynchronous. It is useful for infrequent UPDATE or deletion of batch data. Please refer to https://altinity.com/blog/2018/10/16/updates-in-clickhouse . In addition to the music operation, Clickhouse can also UPDATE and DELETE data through CollapsingMergeTree, VersionedCollapsingMergeTree and replaceingmergetree combined with specific business data structures. These three methods all INSERT the latest data through the INSERT statement. The new data will "offset" or "replace" the old data, but "offset" or "replace" Both occur in the data file background Merge, that is, before Merge, new data and old data will exist at the same time. Therefore, we need to do some processing during query to avoid querying old data. Clickhouse official documents provide guidance on using CollapsingMergeTree and VersionedCollapsingMergeTree, https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/collapsingmergetree/ . Compared with CollapsingMergeTree and VersionedCollapsingMergeTree, it is more convenient to UPDATE and DELETE data with replaceingmergetree. Here we focus on how to UPDATE and DELETE data with replaceingmergetree.
We assume a scenario that requires frequent data updates, such as the statistics of users' power consumption in a city. We know that users' power consumption may change every minute, so frequent data updates will be involved. First, create a table to record the electricity consumption of all users in a city.
CREATE TABLE IF NOT EXISTS default.PowerConsumption_local ON CLUSTER default_cluster
(
User_ID UInt64 COMMENT 'user ID',
Record_Time DateTime DEFAULT toDateTime(0) COMMENT 'Power recording time',
District_Code UInt8 COMMENT 'User's administrative region code',
Address String COMMENT 'User address',
Power UInt64 COMMENT 'Electricity consumption',
Deleted BOOLEAN DEFAULT 0 COMMENT 'Is the data deleted'
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/default.PowerConsumption_local/{shard}', '{replica}', Record_Time)
ORDER BY (User_ID, Address)
PARTITION BY District_Code;
CREATE TABLE default.PowerConsumption ON CLUSTER default_cluster AS default.PowerConsumption_local
ENGINE = Distributed(default_cluster, default, PowerConsumption_local, rand());PowerConsumption_local is the local table and powerconsumption is the corresponding distributed table. Where PowerConsumption_local uses the replicated replacing mergetree table engine. The third parameter is' record '_ Time 'indicates multiple pieces of data with the same primary key, and only record will be retained_ Time is the biggest one. We use the feature of replaceingmergetree to update and delete data. Therefore, when selecting a primary key, we need to ensure that the primary key is unique. Here, we choose (User_ID, Address) as the primary key, because the user ID plus the user's address can determine the only meter, and the second same meter will not appear. Therefore, for multiple data of a meter, only the latest one of the power recording time will be retained.
Then we insert 10 pieces of data into the table:
INSERT INTO default.PowerConsumption VALUES (0, '2021-10-30 12:00:00', 3, 'Yanta', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (1, '2021-10-30 12:10:00', 2, 'Beilin', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (2, '2021-10-30 12:15:00', 1, 'Weiyang', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (3, '2021-10-30 12:18:00', 1, 'Gaoxin', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (4, '2021-10-30 12:23:00', 2, 'Qujiang', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (5, '2021-10-30 12:43:00', 3, 'Baqiao', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (6, '2021-10-30 12:45:00', 1, 'Lianhu', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (7, '2021-10-30 12:46:00', 3, 'Changan', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (8, '2021-10-30 12:55:00', 1, 'Qianhan', rand64() % 1000 + 1, 0); INSERT INTO default.PowerConsumption VALUES (9, '2021-10-30 12:57:00', 4, 'Fengdong', rand64() % 1000 + 1, 0);
The data in the table is shown in the figure:
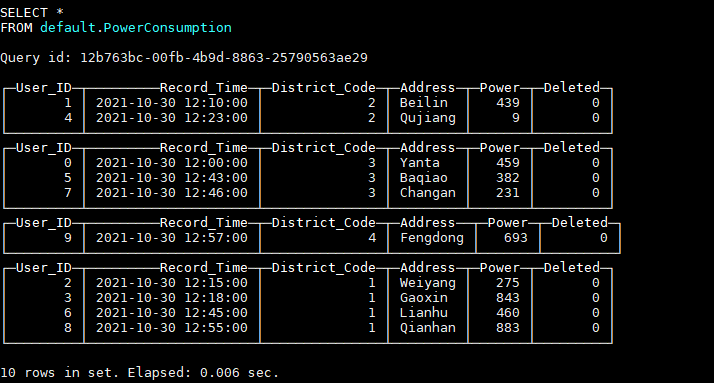
If we want to update all user data with administrative region code 1, we insert the latest data:
INSERT INTO default.PowerConsumption VALUES (2, now(), 1, 'Weiyang', rand64() % 100 + 1, 0); INSERT INTO default.PowerConsumption VALUES (3, now(), 1, 'Gaoxin', rand64() % 100 + 1, 0); INSERT INTO default.PowerConsumption VALUES (6, now(), 1, 'Lianhu', rand64() % 100 + 1, 0); INSERT INTO default.PowerConsumption VALUES (8, now(), 1, 'Qianhan', rand64() % 100 + 1, 0);
After inserting the latest data, the data in the table is as shown in the figure:
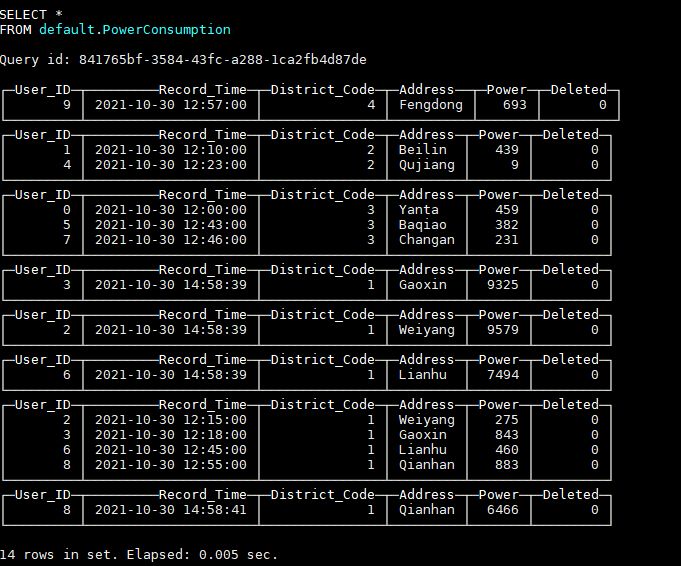
It can be seen that the newly inserted data and the old data exist in the table at the same time. Because the background data file has not been merged and "replacement" has not occurred, some processing needs to be done to the query statement to filter out the old data. The function argMax(a, b) can take the value of a according to the maximum value of B. therefore, only the latest data can be obtained through the following query statement:
SELECT
User_ID,
max(Record_Time) AS R_Time,
District_Code,
Address,
argMax(Power, Record_Time) AS Power,
argMax(Deleted, Record_Time) AS Deleted
FROM default.PowerConsumption
GROUP BY
User_ID,
Address,
District_Code
HAVING Deleted = 0;The query results are as follows:
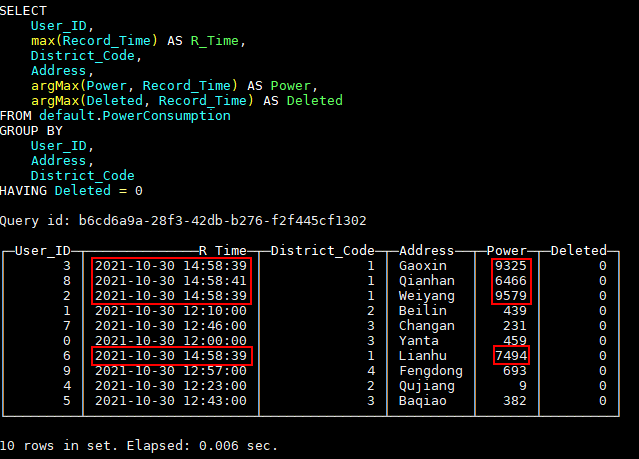
To facilitate our query, we can create a view here:
CREATE VIEW PowerConsumption_view ON CLUSTER default_cluster AS
SELECT
User_ID,
max(Record_Time) AS R_Time,
District_Code,
Address,
argMax(Power, Record_Time) AS Power,
argMax(Deleted, Record_Time) AS Deleted
FROM default.PowerConsumption
GROUP BY
User_ID,
Address,
District_Code
HAVING Deleted = 0;Through this view, you can query the latest data:
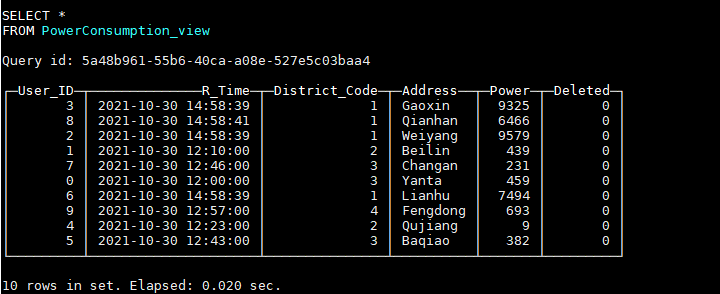
If we need to delete the data with user ID 0 now, we need to insert a user ID_ Data with ID field 0 and Deleted field 1:
INSERT INTO default.PowerConsumption VALUES (0, now(), 3, 'Yanta', null, 1);
Query view, find user_ The data with ID 0 cannot be queried:
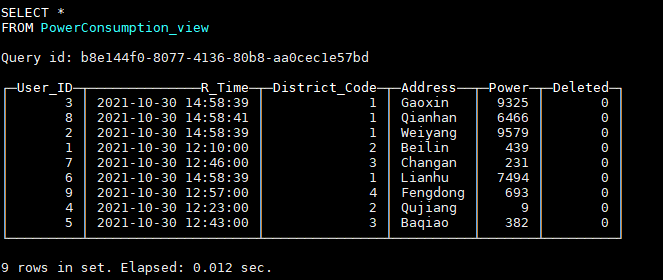
Through the above methods, we can update and delete Clickhouse data, just like using OLTP database, but we should be clear that in fact, the real deletion of old data occurs when the data file Merge. Only after Merge, the old data will be deleted in the real physical sense.
Click focus to learn about Huawei cloud's new technologies for the first time~