Next, I will introduce how to crawl and save the top 250 web page data of Douban step by step.
First, we need the foundation of python: defining variables, lists, dictionaries, tuples, if statements, while statements, etc.
Then use to understand the basic framework (principle) of the crawler: the crawler is to imitate the browser to access the web pages in the network, crawl the web pages into the computer memory and analyze them, and finally store the data we want. Under this condition, we need to give the reptile (soul) logic, which requires us to compare the individual and population of the crawling object, so as to find the law. In other words, if we want the crawler to move, we must first understand the web page by ourselves. (it will be easier to learn html in advance)
Then, we will use python's powerful third-party libraries. In this example, I use these libraries:
import urllib.request,urllib.error import re from bs4 import BeautifulSoup import xlwt
I won't say much about its corresponding usage.
For the whole framework, it is undoubtedly the operation of the function. Set the doll in the main function:
#-*- codeing = utf-8 -*-
def main():
print('''
1.Web crawling function
2.Analytic data function
3.Save data function
'''
)
if __name__ == __mian__:
main()I'll put the main function here first and look at it finally
def main():
baseurl="https://movie.douban.com/top250?start="
savepath="Douban film Top250.xls"
datalist=getData(baseurl)
saveData(datalist,savepath)1. First, we have to climb the web page
def askURL(url):
head={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
}
request=urllib.request.Request(url,headers=head)
html = ""
try:
response=urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return htmlThis is roughly the process of the browser asking for web pages from other people's servers. The first is the request header. Generally, for websites that do not need to log in, just put our Google 'user agent' in it. If it is a website that needs to log in, it almost needs a full set. The rest is left to urllib. Since the state of the object service is unknown, we need to understand the state in our crawling process, that is, error capture. We give reptiles so much work that we can't go on strike because a task can't be completed. Try a try. Here is urlib using urlib Error to identify the network error. Finally, assign the obtained web page to html and you can leave.
2. Analyze web pages while crawling
def getData(baseurl):
datalist=[]
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url) #Save the obtained web page source code
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
#print(item)
data=[]
item = str(item) #Convert to string
link =re.findall(findlink,item)[0]
data.append(link)
imgSrc =re.findall(findImgSrc,item)[0]
data.append(imgSrc)
datalist.append(data)
title=re.findall(findTitle,item)
data.append(title)
return datalistWe can't just crawl a url. We need to design a crawl route for the crawler according to the characteristics of my web page. We have to parse a page for each page. According to the observation, there are 25 movies on each page, a total of 250 movies, and a total of 10 pages are required. The last few numbers in the url are just related to the serial number of the first movie on each page. Just use the for loop to traverse it. askurl is called once at each side of the loop, And use "beautiful soup" "To analyze it, we must first screen out the relevant web page source code and analyze it. It is found that there is' div 'in front of each film. Then leave all div and its sub pages as item. Continue to extract the data of the left things by using the rules formulated in advance with regular expression to extract the data we want. The following is the regular expression placed in the global variable :
findlink = re.compile(r'<a href="(.*?)">',re.S)#Include the newline character in the string findTitle =re.compile(r'<span class="title">(.*)</span>') findImgSrc =re.compile(r'<img.*src="(.*?)"',re.S)
3. Save data
def saveData(datalist,savepath):
book =xlwt.Workbook(encoding="utf-8")
sheet = book.add_sheet('Watercress Top250')
col=("Movie details link","picture","title")
for i in range(0,3):
sheet.write(0,i,col[i])
for i in range(0,250):
print("The first%d strip"%(i+1))
data=datalist[i]
for j in range(0,3):
sheet.write(i+1,j,data[j])
book.save('student.xls')Here, the data is saved in excel. After all, there are only 250 rows. If there are tens of thousands of rows, the database must be used. The effect of saving is as follows:
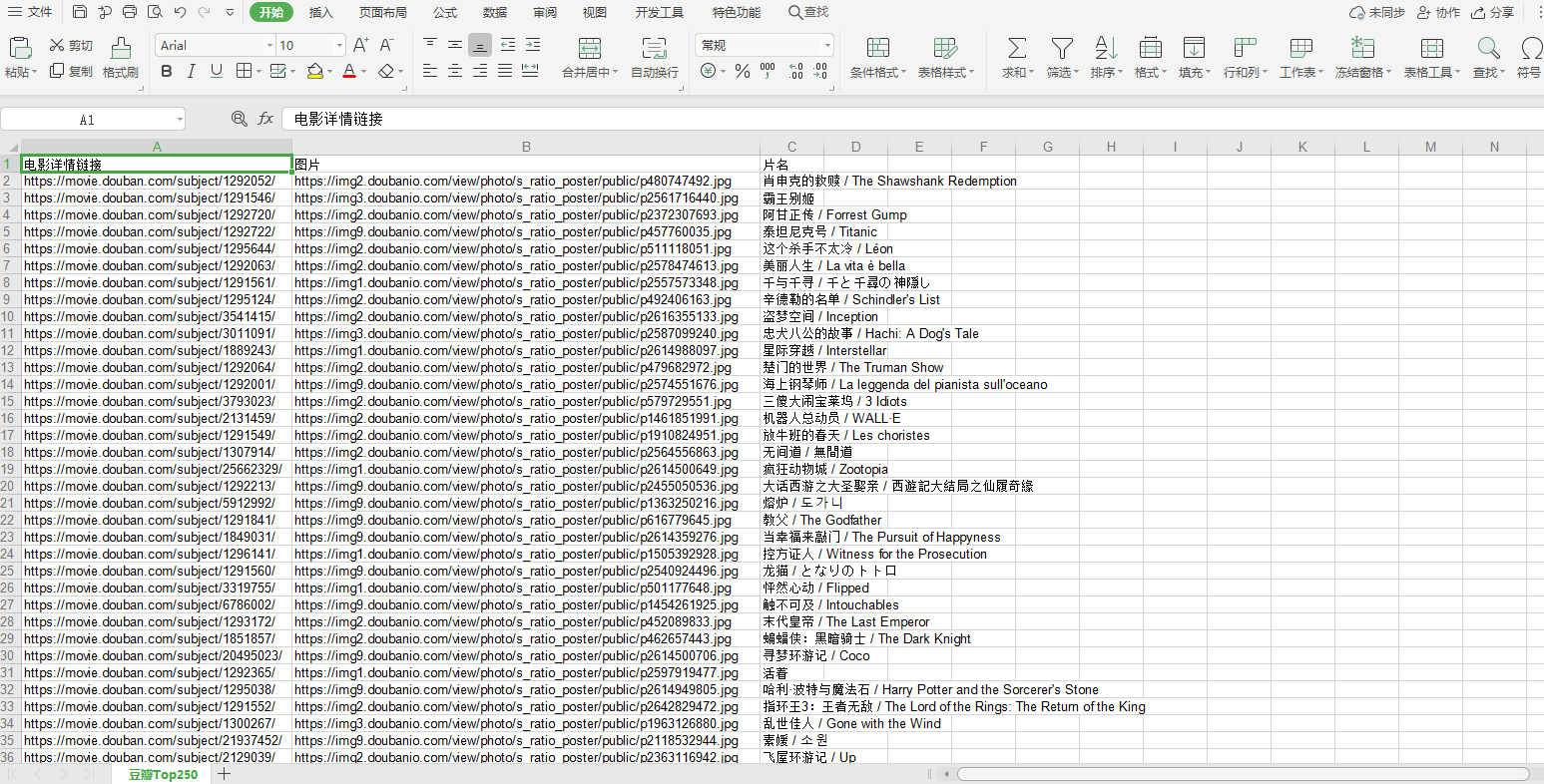
Next, I will visualize the data and listen to the next chapter for how to decompose.
This paper only combs the ideas, and the specific academic problems are not widespread. Please understand.