Article catalog
Research background (some nonsense)
Web crawler (also known as web spider, web robot, more often called web chaser in FOAF community) is a program or script that automatically grabs World Wide Web information according to certain rules.
Generally speaking, if you need information on the Internet, such as commodity prices, pictures and video resources, but you don't want or can't open the web page collection one by one, then you write a program to let the program collect information on the Internet according to the rules you specify. This is crawler, baidu we know, Google and other search engines are actually a huge crawler.
Are reptiles legal?
Generally speaking, as long as it does not affect the normal operation of other people's websites, and it is not for commercial purposes, people generally only seal their IP and account numbers, so as not to pose legal risks.
Background of the article: (this article is only for learning and communication)
Crawl an English article and analyze it. This paper selects Jane Eyre's novels, including word frequency analysis and word length statistics. With Chinese word cloud.
Tip: the following is the main content of this article. The following cases can be used for reference
1, Related principles
Web crawler is a program that automatically extracts web pages Search Engines Downloading web pages from the world wide web is an important part of search engines. The traditional crawler obtains the URL on the initial web page from the URL of one or several initial web pages. In the process of grabbing the web page, it continuously extracts new URLs from the current page and puts them into the queue until certain stop conditions of the system are met. The workflow of focus crawler is complex and needs to be based on certain requirements Web page analysis algorithm Filter the links irrelevant to the topic, keep the useful links and put them into the URL queue waiting to be fetched. Then, it will select the next web page URL from the queue according to a certain search strategy, and repeat the above process until a certain condition of the system is reached. In addition, all web pages captured by crawlers will be stored by the system, analyzed, filtered and indexed for future query and retrieval; For focused crawlers, the analysis results obtained in this process may also give feedback and guidance to the future grasping process.
Compared with the general web crawler, the focus crawler also needs to solve three main problems:
(1) Description or definition of capture target;
(2) Analysis and filtering of web pages or data;
(3) Right URL of search strategy .
The environment used in the article:
python 3.9 + bs4 + jieba + matplotlib + wordcloud + PIL + numpy + urllib
You also need some front-end knowledge to parse html text.
See below for the specific principle.
2, Design idea


Find target - crawl - save - Analyze
2, Implementation process
1. Analysis page
1. Reptile target
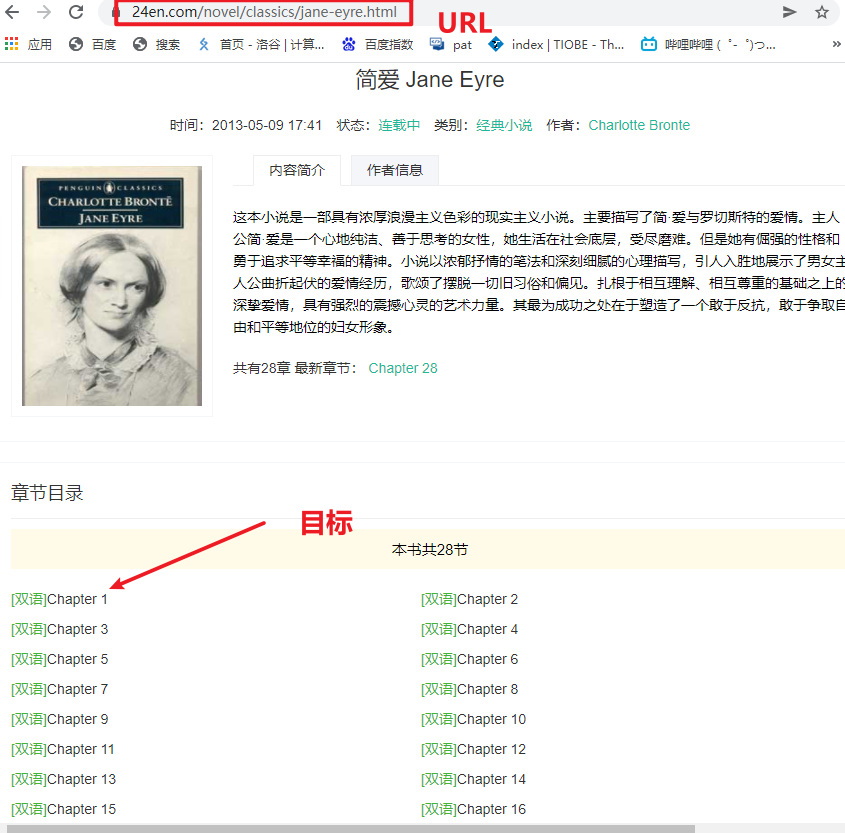
2. Page analysis
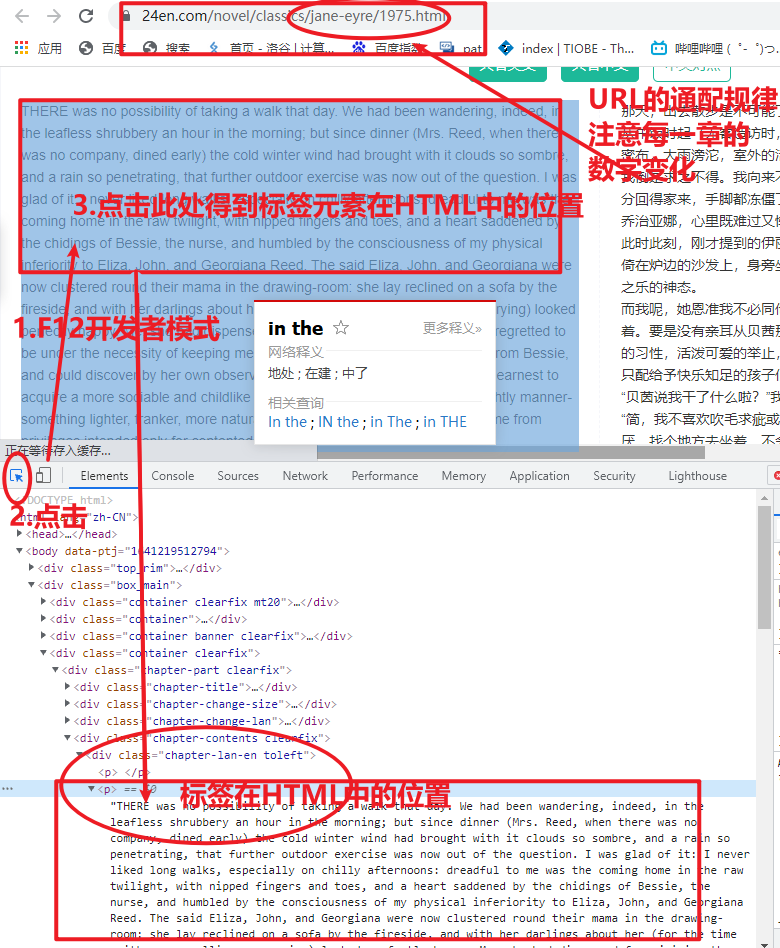
3. Chapter URL
Chapter I:

Chapter II:

Chapter III:
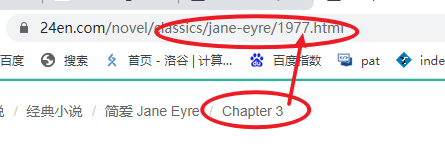
Law:
The URL of Chapter i is: https://www.24en.com/novel/classics/jane-ey re/ {{1975+i-1}} .html
Thus, the url of chapter 28 is:
1975+28-1 = 2002
https://www.24en.com/novel/classics/jane-eyre/2002.html
https :// www.24en.com/novel/classics/jane-eyre/1977.html verification:

2. Introduction module
from bs4 import BeautifulSoup # Web page parsing import urllib.request, urllib.error # Specify URL import jieba # participle from matplotlib import pyplot as plt # Visualization of drawing data from wordcloud import WordCloud # Word cloud from PIL import Image # Image processing import numpy as np # Matrix operation import xlwt # EXCEL processing
3. Obtain data
Use the library function, splice the url, visit the website circularly, parse the crawled html, and save it circularly to the txt document.
See the comments in the source code for details.
4. Analyze data
See the comments in the source code for details.
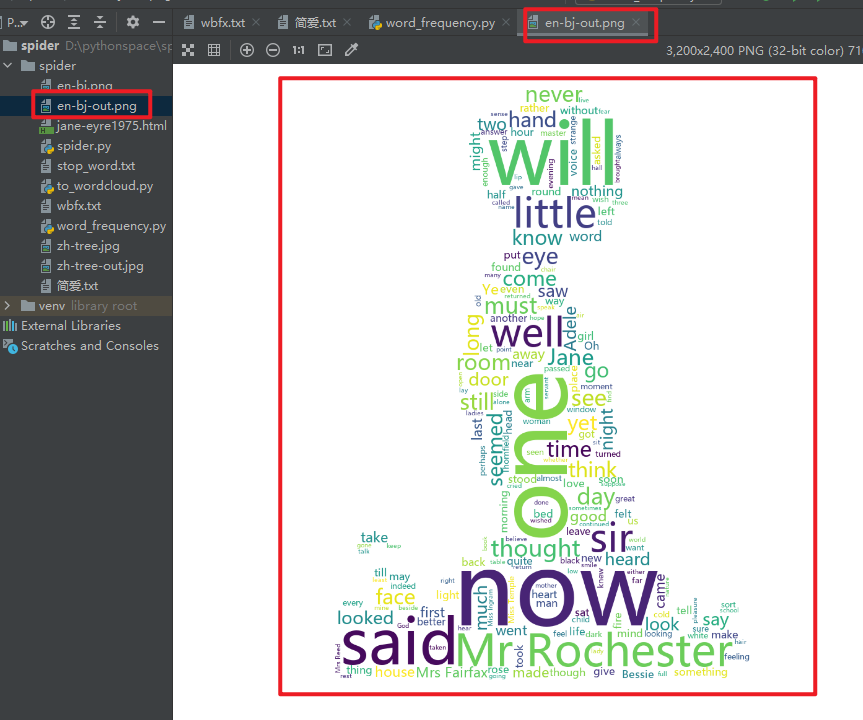
5. CI Yun
See the comments in the source code for details.
3, Result display
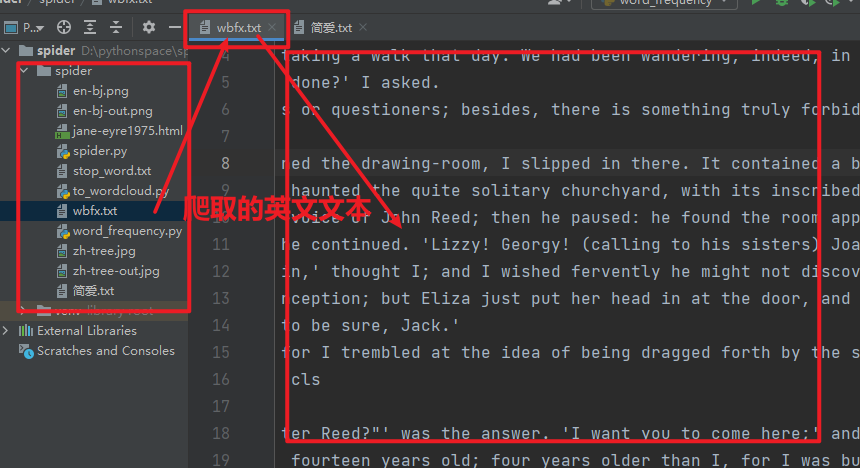
1. English text
2. Chinese text
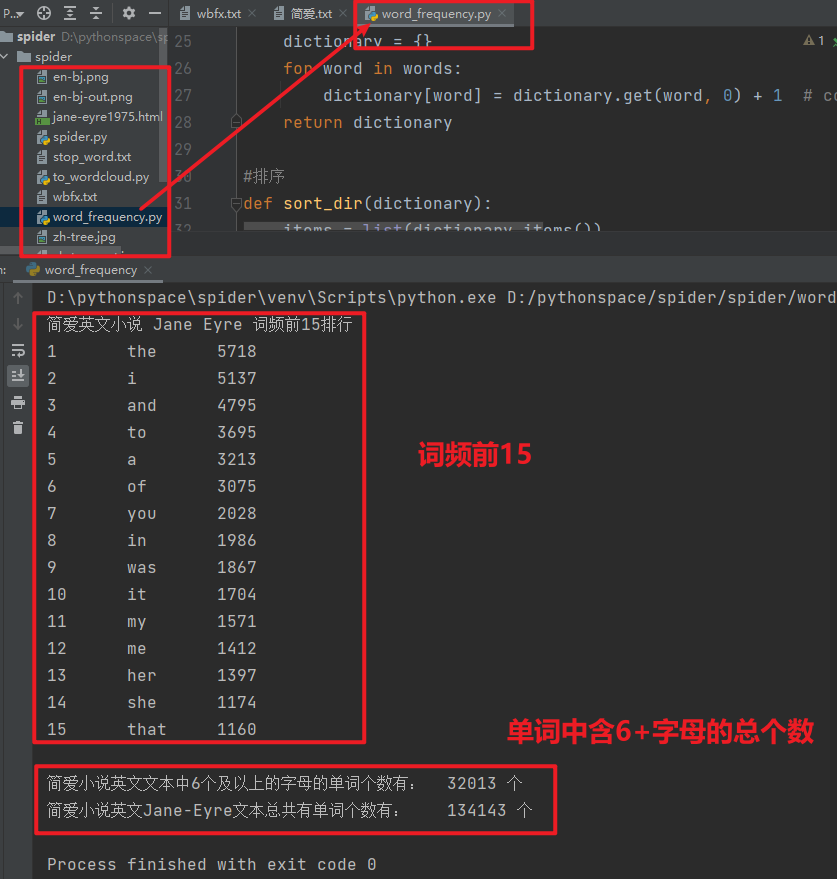
3. Analysis of word frequency and letter number
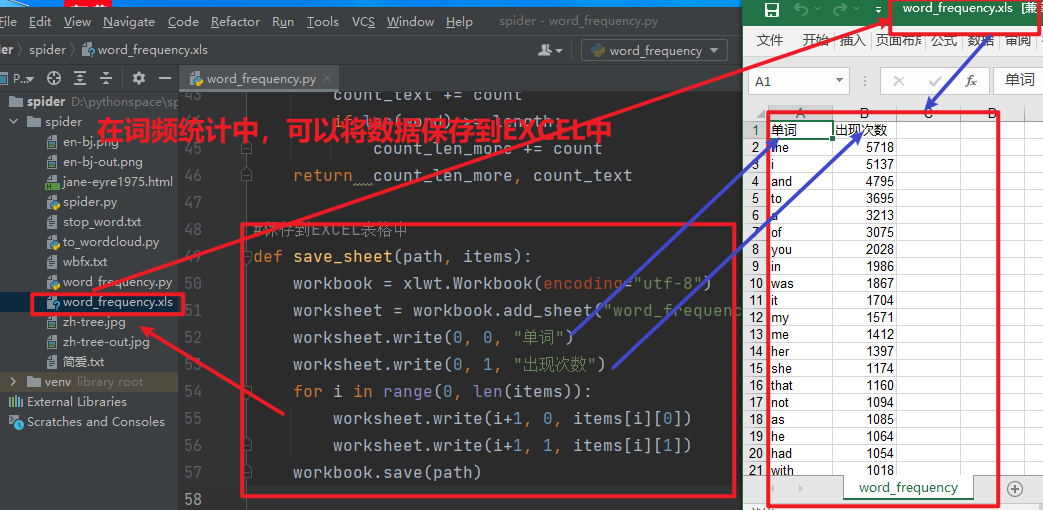
4. Word cloud
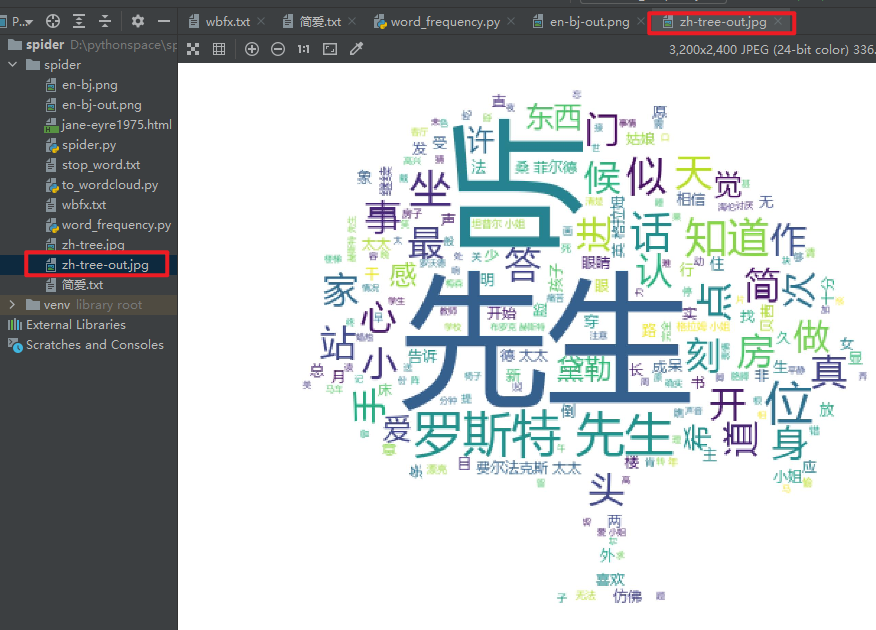
IV. feelings and project structure
The functions in the project are fully implemented and encapsulated, such as the function of outputting the number of words with letters (you can count the length of words that are not a specific number):
#Get the number of words with length and more letters
def get_count_len(items, length: int):
count_len_more = 0
count_text = 0 # Number of words in this list
for word, count in items:
count_text += count
if len(word) >= length:
count_len_more += count
return count_len_more, count_textProject structure:
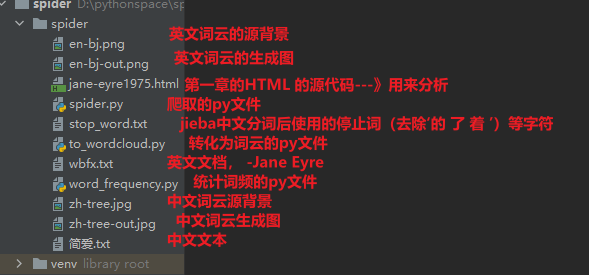
The codes to note are:
1.# lambda x:x[0] sorts tuples (key s) in the list by sort, x:x[1] represents dictionary values (values) to sort, and reverse=true indicates descending
def sort_dir(dictionary):
items = list(dictionary.items())
items.sort(key=lambda x: x[1],
reverse=True)
return items2.# counts.get (word,0)+ 1 refers to the value returned when there is word. The default value is 0 and + 1 can accumulate times; If there is no word, 0 is returned.
def make_dictionary(text_en):
words = text_en.split()
dictionary = {}
for word in words:
dictionary[word] = dictionary.get(word, 0) + 1
return dictionary5, Source code
1 # -*- coding = utf-8 -*- 2 # @Time : 2022/1/3 11:35 3 # @Author : butupi 4 # @File : spider.py 5 # @Software : PyCharm 6 7 from bs4 import BeautifulSoup # Web page parsing 8 import urllib.request, urllib.error # appoint URL 9 10 11 def main(): 12 # Crawling url_base part 13 baseurl = "https://www.24en.com/novel/classics/jane-eyre/" #1975-2002 14 # Crawl save 15 getData(baseurl) 16 17 18 # Crawl web pages 19 def getData(baseurl): 20 #Jane Eyre has 28 chapters 21 for i in range(0, 28): 22 #complete URL,url The starting number is 1975, the beginning of each chapter url All add 1 on this basis 23 url = baseurl + str(1975+i)+".html" # Page feed reading 24 #Visit web page 25 html = askURL(url) # Save the obtained source code 26 # Parse save 27 soup = BeautifulSoup(html, "html.parser") 28 with open("wbfx.txt", "a+", encoding="utf-8") as f: 29 f.writelines("\n Chapter"+str(i+1)+" \n") 30 for item in soup.find_all("div", class_="chapter-lan-en toleft"): # Find a string that meets the requirements 31 for p in item.p.children: 32 f.writelines(p.string.replace(u'\xa0', '')) 33 with open("Jane Eyre.txt", "a+", encoding="utf-8") as f: 34 f.writelines("\n Number" + str(i+1) + "chapter \n") 35 for item in soup.find_all("div", class_="chapter-lan-zh toright"): # Find a string that meets the requirements 36 for p in item.p.children: 37 f.writelines(p.string.replace(u'\xa0', '')) 38 39 40 # Crawl assignment URL document info 41 def askURL(url): 42 #packing request Request header 43 head = { 44 "User-Agent": "Mozilla / 5.0 AppleWebKit " #... 45 } 46 request = urllib.request.Request(url, headers=head) 47 #Save crawled pages 48 html = "" 49 try: 50 response = urllib.request.urlopen(request) 51 html = response.read().decode("utf-8") 52 #print(html) 53 #exception handling 54 except urllib.error.URLError as e: 55 if hasattr(e, "code"): 56 print(e.code) 57 if hasattr(e, "reason"): 58 print(e.reason) 59 return html 60 61 62 if __name__ == "__main__": 63 main() 64 print("Crawling completed")
1 # -*- coding = UTF-8 -*- 2 # @Time : 2022/01/03 13:39 3 # @Author : butupi 4 # @File : to_wordcloud.py 5 # @Software : PyCharm 6 7 import jieba # participle 8 from matplotlib import pyplot as plt # Visualization of drawing data 9 from wordcloud import WordCloud # Word cloud 10 from PIL import Image # Image processing 11 import numpy as np # Matrix operation 12 13 14 #--------------------------------- 15 #Get Chinese and English articles 16 def get_text(path_en, path_zh): 17 text_en = "" 18 text_zh = "" 19 with open(path_en, "r", encoding="utf-8") as f: 20 for line in f.readlines(): 21 text_en += line.rstrip("\n") 22 # print(text_en) 23 with open(path_zh, "r", encoding="utf-8") as f: 24 for line in f.readlines(): 25 text_zh += line.rstrip("\n") 26 return text_en, text_zh 27 28 #--------------------------------- 29 30 #jieba participle 31 def cut_text(text): 32 cut = jieba.cut(text) 33 cut_words = ' '.join(cut) 34 # print(type(cut_words)) 35 # print(len(cut_words)) 36 return cut_words 37 38 #--------------------------------- 39 #Get a list of stop words 40 def get_stop_words(filepath): 41 stop_words = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] 42 return stop_words 43 44 #Remove stop words 45 def move_stop_words(text, path): 46 stop_words = get_stop_words(path) 47 out_str = '' 48 for word in text: 49 if word not in stop_words: 50 if word != '\t' and '\n': 51 out_str += word 52 return out_str 53 #----------------------------------- 54 55 #Generate word cloud 56 def get_word_cloud(source_path, dest_path, out_str): 57 #Get background picture 58 img = Image.open(source_path) 59 #Convert pictures to arrays 60 img_array = np.array(img) 61 #Word cloud attribute 62 wc = WordCloud( 63 background_color='white', 64 mask=img_array, 65 font_path="msyh.ttc" # font 66 ).generate_from_text(out_str) 67 68 #Draw picture 69 fig = plt.figure(1) 70 plt.imshow(wc) # Display as word cloud 71 plt.axis('off') # Do not display coordinates 72 #plt.show() # Displays the generated word cloud picture 73 #Export to file 74 plt.savefig(dest_path, dpi=500) 75 76 #------------------------------- 77 def main(): 78 #get_text 79 text_en, text_zh = get_text("wbfx.txt", "Jane Eyre.txt") 80 81 #jieba 82 cut_words = cut_text(text_zh) 83 84 #move_stop_words 85 out_str = move_stop_words(cut_words, 'stop_word.txt') 86 87 #wordcloud 88 get_word_cloud('zh-tree.jpg', 'zh-tree-out.jpg', out_str) 89 get_word_cloud('en-bj.png', 'en-bj-out.png', text_en) 90 91 92 #--------------------------------- 93 if __name__ == '__main__': 94 main()
1 # -*- coding = utf-8 -*- 2 # @Time : 2022/01/03 20:45 3 # @Author : butupi 4 # @File : word_frequency.py 5 # @Software : PyCharm 6 7 import xlwt # EXCEL handle 8 9 #Get English articles(Replace special characters) 10 def get_text(path_en): 11 text_en = "" 12 with open(path_en, "r", encoding="utf-8") as f: 13 for line in f.readlines(): 14 text_en += line.rstrip("\n") 15 #a lowercase letter 16 text_en = text_en.lower() 17 #Replace special characters 18 for ch in '!"#$&()*+,-./:;<=>?@[\\]^_{|}·~\'''': 19 text_en = text_en.replace(ch, " ") 20 return text_en 21 22 23 #Process text into dictionary 24 def make_dictionary(text_en): 25 words = text_en.split() 26 dictionary = {} 27 for word in words: 28 dictionary[word] = dictionary.get(word, 0) + 1 # counts.get (word,0)+ 1 Means yes word The default value is 0,+1 Be able to accumulate times; No, word Returns 0 when. 29 return dictionary 30 31 #sort 32 def sort_dir(dictionary): 33 items = list(dictionary.items()) 34 items.sort(key=lambda x: x[1], 35 reverse=True) # lambda x:x[0]For tuples in the list( key)to sort Sort, x:x[1]Represents the value of the dictionary( values)to sort Sort, reverse=true Indicates descending order 36 return items 37 38 #obtain length Number of words with letters or more 39 def get_count_len(items, length: int): 40 count_len_more = 0 41 count_text = 0 # Number of words in this list 42 for word, count in items: 43 count_text += count 44 if len(word) >= length: 45 count_len_more += count 46 return count_len_more, count_text 47 48 #Save to EXCEL In the table 49 def save_sheet(path, items): 50 workbook = xlwt.Workbook(encoding="utf-8") 51 worksheet = workbook.add_sheet("word_frequency") 52 worksheet.write(0, 0, "word") 53 worksheet.write(0, 1, "Number of occurrences") 54 for i in range(0, len(items)): 55 worksheet.write(i+1, 0, items[i][0]) 56 worksheet.write(i+1, 1, items[i][1]) 57 workbook.save(path) 58 59 #Count word and word frequency 60 def main(): 61 text_en = get_text("wbfx.txt") 62 63 #The word frequency of the processed text is counted and stored in the dictionary 64 dictionary = make_dictionary(text_en) 65 66 #Arrange the dictionaries in descending order to get a list with elements of( k-v)tuple(Words, frequency) 67 items = sort_dir(dictionary) 68 69 #The statistical results are saved as a list type, sorted by word frequency from high to low, and the first 15 bits are output 70 print("Jane Eyre's English novels Jane Eyre Top 15 word frequency rankings") 71 for i in range(15): 72 word, count = items[i] 73 print("{0}\t\t{1:<8}{2:>5}".format(i+1, word, count)) 74 75 #Save to Excel In the table 76 save_sheet("word_frequency.xls", items) 77 78 #6 Number of words with letter length and above 79 length_word = 6 80 count_six_more, count_text = get_count_len(items, length_word) 81 #print(word, count) # Words with 6 letters + and their frequency 82 print() 83 print("In the English text of Jane Eyre's Novels"+str(length_word)+"The number of words with letters or more is:\t"+str(count_six_more)+" individual") 84 print("Jane Eyre's Novels Jane-Eyre The total number of words in the text is:\t"+str(count_text)+" individual") 85 86 87 if __name__ == '__main__': 88 main()