1, Knowledge needed
xpath syntax, data type conversion, basic crawler.
xpath is suitable for data cleaning when the web page data is html, so as to achieve the purpose of extracting data. I recommend a particularly easy-to-use plug-in, xpath helper. If you need me, you can chat with me in private. I will update the installation tutorial and operation in the future.
Data type conversion: focus on the data taken from the web page is in string format. Data < class' STR '> cannot be extracted directly through xpath syntax, so you need to convert the data type STR > > xpath object. In this way, we convert the format through a third-party library. The uppercase html method in the etree class in the html module returns the html object that can extract data through xpath syntax.
2, Third party Library Download and introduction
Third party Library Download: enter PIP install lxml - I in cmd https://pypi.tuna.tsinghua.edu.cn/simple
Function: convert the string type data obtained by the crawler into extractable html type data.
3, Crawling idea
Data capturing process 1 packet capturing, sending request 2 data cleaning 3 data saving Destination url:https://movie.douban.com/top250 . If you don't know the basic process of crawler, I suggest you look at my first article to get familiar with it Reptile combat https://blog.csdn.net/qq_54857095/article/details/122268948?spm=1001.2014.3001.5501
IV. page analysis
This is the interface we opened

We can see 25 movies on a page. Right click to check and find that the data is very regular, which is just in line with the taste of our crawler engineers.

Then click
Then click the mouse and the text you want to extract will be loaded into the
The above page (according to the example of Shawshank Redemption), and then extract the target text according to the xpath syntax. (we are encouraged to write xapth syntax by ourselves. Of course, we can also copy and paste xath directly, but the extraction may not be accurate.)
The simple method is shown in the figure above. Directly copy xpath. Then we used our magic plug-in. No more nonsense, just look at the picture.
Left: xpath syntax. Right: corresponding content. In this way, our xpath syntax is constructed. But we need to get 25 items of data on this page. In xpath syntax, * represents all data under such nodes. From this, we can know that each li node contains a movie data.
Then we modify the xpath syntax to operate
After modification, 25 items of data will be obtained. Follow the same method to get, movie links, and ratings.
5, Code implementation
"""extract html Format data installation module lxml
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
Task: Pass lxml To extract Douban movie data
1 Movie name
2 score
3 link
4.brief introduction
use:
"""
from lxml import etree
import requests
import json
"""
Data capture process
1 Capturing packets, sending requests
2 Data cleaning
3 Data saving
https://movie.douban.com/top250
"""
# 1. Capture packets and send requests
# Confirm url
url="https://movie.douban.com/top250"
# Build user agent
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36"
}
# Send request and get response
response=requests.get(url=url,headers=headers)
print(response.encoding)
res_data=response.content.decode()
# The key point is that the data taken from the web page is in string format. Data < class' STR '> cannot be extracted directly through xpath syntax
# You need to convert the data type STR > > XPath object
# print(res_data)
# The uppercase html method in the etree class in the html module returns the html object that can extract data through xpath syntax
html=etree.HTML(res_data)
print(html)
# Now you can extract data through xpath syntax
# Extract through the xpath method of html object. xpath will not automatically generate its own handwriting syntax. Similarly, it is also in the form of string
# Extract the returned object (variable) list type file through xpath syntax, save judgment if variable = = []: no data
# 1 movie name data
title=html.xpath('//div[@class="hd"]/a/span[1]/text()')
# print(title)
# 2 scoring data
score=html.xpath('//div[@class="bd"]/div[@class="star"]/span[2]/text()')
# print(score)
# 3 link
link=html.xpath('//div[@class="info"]/div[@class="hd"]/a/@href')
# tips when observing the extracted data and finding that there are only two nodes, you can confirm the number of nodes
# //div[@class="info"]/div[1]/a/@href
# print(link)
# 4. Introduction
# breif=html.xpath('//div[@class="bd"]/p[2]/span/text()')
# print(link)
with open("Watercress.json","w",encoding="utf-8")as file1:
for node in zip(title,score,link):
item={}
item["title"]=node[0]
item["score"]=node[1]
item["link"]=node[2]
# item["breif"]=node[3]
print(item)
str_data=json.dumps(item,ensure_ascii=False,indent=2)
file1.write(str_data+",\n")
# Douban page turning (the first ten pages) data extraction, saving as json format data screenshot and sending it to me
#
#
#
# Ask questions and copy the source code
#/html/body/app-wos/div/div/main/div/div[2]/app-input-route/app-base-summary-component/div/div[2]/app-records-list/app-record[1]/div[2]/div[1]/app-summary-title/h3/a/@href
#/html/body/app-wos/div/div/main/div/div[2]/app-input-route/app-base-summary-component/div/div[2]/app-records-list/app-record[2]/div[2]/div[1]/app-summary-title/h3/a/@href
#/html/body/app-wos/div/div/main/div/div[2]/app-input-route/app-base-summary-component/div/div[2]/app-records-list/app-record[5]/div[2]/div[1]/app-summary-title/h3/a/@href
This is my code and implementation process. The final effect is as follows.
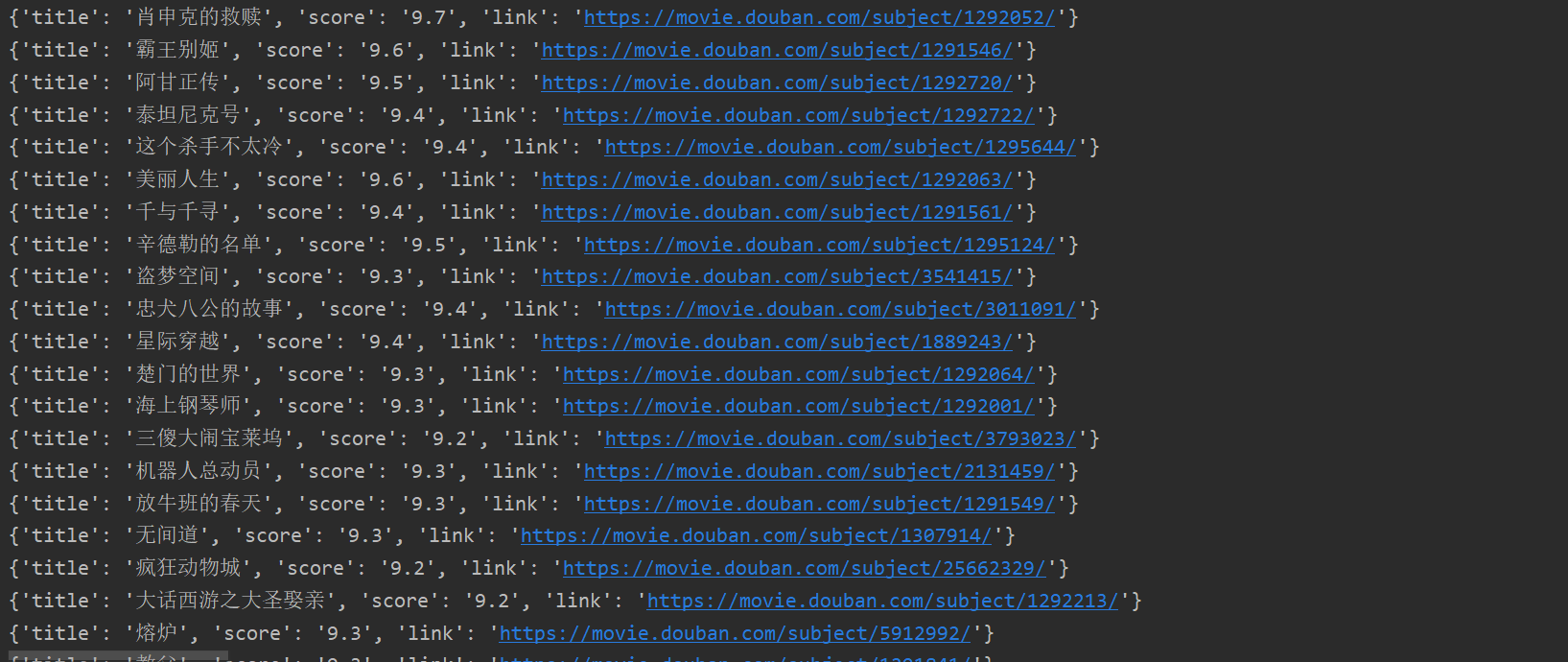
It also includes a file (write file operation. If you won't, you can send me a private letter.) The effect is as follows.

V. small tips
There is a beautification operation when writing a file. Writing this code when writing a file can achieve beautification
with open("Watercress.json","w",encoding="utf-8")as file1:
for node in zip(title,score,link):
item={}
item["title"]=node[0]
item["score"]=node[1]
item["link"]=node[2]
# item["breif"]=node[3]
print(item)
str_data=json.dumps(item,ensure_ascii=False,indent=2)
file1.write(str_data+",\n")
The zip function can handle the traversal of multiple iteratable objects.
6, Finally
Thank you for seeing here. I hope what I have written will help you. Explosive liver hopes to get the support and encouragement of friends.