When we are reptiles, we often these situations:
-
The website is complex and will encounter many repeated requests.
-
Sometimes the crawler is interrupted unexpectedly, but we don't save the crawling state. If we run again, we need to crawl again.
There are such problems.
So how to solve these repeated crawling problems? You probably think of "caching", that is, you can skip crawling directly after crawling once.
What do you usually do?
For example, I write a logic to save the URL that has been crawled to the file or database. Before each crawl, just check whether it is in the list or database.
Yes, this idea is OK, but have you thought about these problems:
-
Writing to a file or database may be permanent. If I want to control the effective time of the cache, I have to have an expiration time control.
-
What is this cache based on? If only the URL itself is enough? There are also Request Method and Request Headers. If they are different, do you want to use cache?
-
If we have many projects, don't we have a common solution?
It's really some problems. We really need to consider a lot of problems when implementing it.
But don't worry. Today I'll introduce you an artifact that can help us solve the above problems.
introduce
It is requests cache, which is an extension package of requests library. Using it, we can easily cache requests and directly get the corresponding crawling results.
-
GitHub: https://github.com/reclosedev/requests-cache
-
PyPi: https://pypi.org/project/requests-cache/
-
Official documents: https://requests-cache.readthedocs.io/en/stable/index.html
Let's introduce its use.
install
The installation is very simple. You can use pip3 to:
pip3 install requests-cache
After installation, let's understand its basic usage.
Basic Usage
Let's first look at a basic example:
import requests
import time
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time', end - start)
Here we requested a website, yes http://httpbin.org/delay/1 , the website simulates a one second delay, that is, after the request, it will not return the response until one second later.
It has been requested 10 times, so it will take at least 10 seconds to complete the operation.
The operation results are as follows:
Finished 1 requests Finished 2 requests Finished 3 requests Finished 4 requests Finished 5 requests Finished 6 requests Finished 7 requests Finished 8 requests Finished 9 requests Finished 10 requests Cost time 13.17966604232788
As you can see, it took a total of 13 seconds.
What if we use requests cache? What will happen?
Rewrite the code as follows:
import requests_cache
import time
start = time.time()
session = requests_cache.CachedSession('demo_cache')
for i in range(10):
session.get('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time', end - start)
Here we declare a CachedSession. We have replaced the original Session object, but we have requested it 10 times.
The operation results are as follows:
Finished 1 requests Finished 2 requests Finished 3 requests Finished 4 requests Finished 5 requests Finished 6 requests Finished 7 requests Finished 8 requests Finished 9 requests Finished 10 requests Cost time 1.6248838901519775
You can see that the climb is over in more than a second!
What happened?
At this time, we can find that a demo is generated locally_ cache. SQLite database.
After opening it, we can find a responses table with a key value record in it, as shown in the figure:
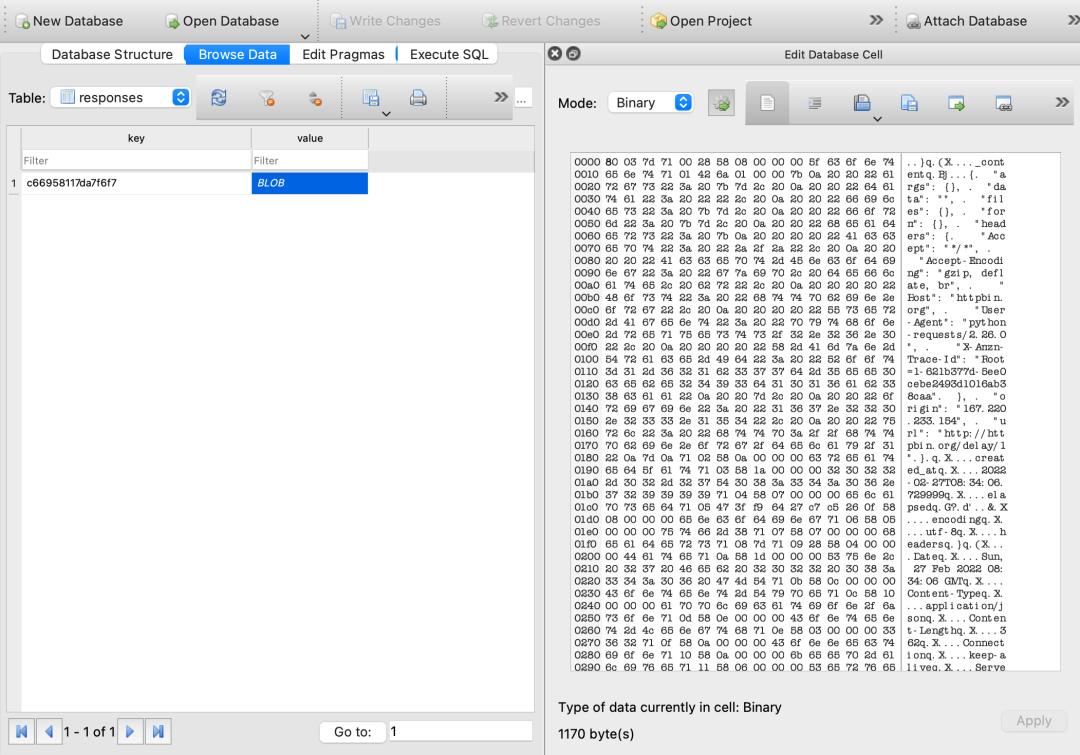
We can see that the key in the key value record is a hash value, and the value is a Blob object. The content in it is the result of the Response.
It can be guessed that a corresponding key will be generated for each request, and then the requests cache stores the corresponding results in the SQLite database. The URL s of subsequent requests are the same as those of the first request. After some calculations, their keys are the same, so the subsequent 2-10 requests will be returned immediately.
Yes, with this mechanism, we can skip many repeated requests and greatly save crawling time.
Patch writing
However, when we were writing just now, we directly replaced the session object of requests. Is there any other way to write it? For example, I don't affect the current code. I just add a few lines of initialization code in front of the code to complete the configuration of requests cache?
Of course, the code is as follows:
import time
import requests
import requests_cache
requests_cache.install_cache('demo_cache')
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time', end - start)
This time, we directly call the install of the requests cache library_ Just use the cache method. The Session of other requests can be used as usual.
Let's run it again:
Finished 1 requests Finished 2 requests Finished 3 requests Finished 4 requests Finished 5 requests Finished 6 requests Finished 7 requests Finished 8 requests Finished 9 requests Finished 10 requests Cost time 0.018644094467163086
This time it's faster than last time. Why? Because all requests hit the Cache this time, the result is returned soon.
Backend configuration
We just learned that requests cache uses SQLite as the cache object by default. Can we change this? For example, what about files or other databases?
Of course.
For example, we can replace the back-end with local files, which can be done as follows:
import time
import requests
import requests_cache
requests_cache.install_cache('demo_cache', backend='filesystem')
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time', end - start)
Here, we add a backend parameter and specify it as file system, so that a demo will be generated locally after running_ The cache folder is used as the cache. If you don't want to use the cache, delete this folder.
Of course, we can also change the location of the cache folder, such as:
requests_cache.install_cache('demo_cache', backend='filesystem', use_temp=True)
Add a "use" here_ With the temp parameter, the cache folder will use the temporary directory of the system instead of creating a cache folder in the code area.
Of course, it can also be like this:
requests_cache.install_cache('demo_cache', backend='filesystem', use_cache_dir=True)
Add a "use" here_ cache_ Dir parameter, the cache folder will use the system's private cache folder instead of creating a cache folder in the code area.
In addition, in addition to the file system, requests cache also supports other back ends, such as Redis, MongoDB, GridFS and even memory, but it also needs the support of corresponding dependent libraries. See the following table for details:
| Backend | Class | Alias | Dependencies |
|---|---|---|---|
| SQLite | SQLiteCache | 'sqlite' | |
| Redis | RedisCache | 'redis' | redis-py |
| MongoDB | MongoCache | 'mongodb' | pymongo |
| GridFS | GridFSCache | 'gridfs' | pymongo |
| DynamoDB | DynamoDbCache | 'dynamodb' | boto3 |
| Filesystem | FileCache | 'filesystem' | |
| Memory | BaseCache | 'memory' |
For example, Redis can be rewritten as follows:
backend = requests_cache.RedisCache(host='localhost', port=6379)
requests_cache.install_cache('demo_cache', backend=backend)
For more detailed configuration, please refer to the official document:
https://requests-cache.readthedocs.io/en/stable/user_guide/backends.html#backends
Filter
Of course, sometimes we also want to specify that some requests are not cached. For example, only POST requests are cached and GET requests are not cached. This can be configured as follows:
import time
import requests
import requests_cache
requests_cache.install_cache('demo_cache2', allowable_methods=['POST'])
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for get', end - start)
start = time.time()
for i in range(10):
session.post('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for post', end - start)
Here we have added a} allowable_methods # specifies a filter. Only POST requests will be cached and GET requests will not.
See the operation results:
Finished 1 requests Finished 2 requests Finished 3 requests Finished 4 requests Finished 5 requests Finished 6 requests Finished 7 requests Finished 8 requests Finished 9 requests Finished 10 requests Cost time for get 12.916549682617188 Finished 1 requests Finished 2 requests Finished 3 requests Finished 4 requests Finished 5 requests Finished 6 requests Finished 7 requests Finished 8 requests Finished 9 requests Finished 10 requests Cost time for post 1.2473630905151367
At this time, you can see that the GET request took more than 12 seconds to end because there was no cache, and the POST ended more than one second because of the cache.
In addition, we can filter the Response Status Code. For example, if only 200 will be cached, it can be written as follows:
import time
import requests
import requests_cache
requests_cache.install_cache('demo_cache2', allowable_codes=(200,))
Of course, we can also match the URL. For example, for which Pattern's URL is cached for how long, you can write this:
urls_expire_after = {'*.site_1.com': 30, 'site_2.com/static': -1}
requests_cache.install_cache(
'demo_cache2', urls_expire_after=urls_expire_after)
In that case, site_ The content of 1.com will be cached for 30 seconds_ The content of 2.com/static will never expire.
Of course, we can also customize the Filter. For details, see: https://requests-cache.readthedocs.io/en/stable/user_guide/filtering.html#custom-cache-filtering.
Cache Headers
In addition to our custom cache, requests cache also supports parsing HTTP Request / Response Headers and caching according to the contents of Headers.
For example, we know that there is a "cache control" Request / Response Header in HTTP, which can specify whether the browser should cache this request. How can requests cache support it?
Examples are as follows:
import time
import requests
import requests_cache
requests_cache.install_cache('demo_cache3')
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/1',
headers={
'Cache-Control': 'no-store'
})
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for get', end - start)
start = time.time()
Here, we add "cache control" to "no store" in Request Headers. In this way, even if we declare the cache, it will not take effect.
Of course, the resolution of Response Headers is also supported. We can start it this way:
requests_cache.install_cache('demo_cache3', cache_control=True)
If we configure this parameter, then {expire_ The configuration of after # will be overwritten and will not take effect.
For more usage, see:
https://requests-cache.readthedocs.io/en/stable/user_guide/headers.html#cache-headers.
summary
Well, so far, some basic and common usages such as basic configuration, expiration time configuration, back-end configuration and filter configuration are introduced here
For more detailed usage, please refer to the official documents:
https://requests-cache.readthedocs.io/en/stable/user_guide.html
I hope it will be helpful to you