
Source code analysis jdk1 HashMap under 7
We all know that the bottom layer of hashmap version 1.7 is composed of array and linked list. Today, let's analyze the source code ourselves~
It's a little long. I don't talk much nonsense. I'll start the analysis directly~
Attribute declaration
//Initialization capacity static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 //Maximum capacity static final int MAXIMUM_CAPACITY = 1 << 30; //Default load factor static final float DEFAULT_LOAD_FACTOR = 0.75f; int threshold; Copy code
Construction method
//Customize the initialization capacity and loading factor, and judge whether the two values are legal // The default initial capacity - MUST be a power of two. Capacity must be to the power of 2 public HashMap(int initialCapacity, float loadFactor) //Customize the initialization capacity and use the default load factor public HashMap(int initialCapacity) //Use default initialization capacity and default load factor public HashMap() Copy code
//In the final analysis, the constructor is called
public HashMap(int initialCapacity, float loadFactor) {
//Judge whether the initialization capacity is legal
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//When the initialization capacity is greater than or equal to the maximum capacity, it is directly assigned as the maximum capacity
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//Determine whether the loading factor is the sum method
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//Assign a value to the load factor
this.loadFactor = loadFactor;
//Leave a question here? What the hell is this? Why assign it.
threshold = initialCapacity;
init(); //This method in hashMap is empty and not implemented. It can only be implemented in LinkedList, so it is not studied here
}
Copy codeput method
public V put(K key, V value) {
//If the current table array is empty, initialize the size. Here we can know why the initialization capacity should be assigned to threshold in the construction method. According to my understanding, it actually has the effect of lazy initialization, that is, it initializes the size of the array when you put the first value
if (table == EMPTY_TABLE) {
inflateTable(threshold); // Skip to 1
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
Copy code- inflateTable(threshold)
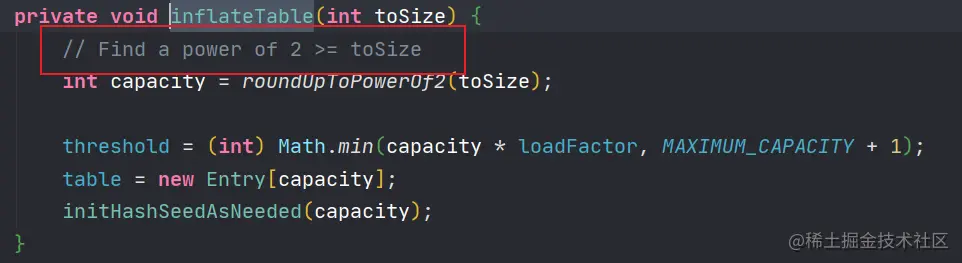
private void inflateTable(int toSize) {
// Find a power of 2 > = toSize according to the notes, you can find a power greater than or equal to toSize
// For example, when toSize=5, the capacity will be equal to 8
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
Copy codeLet's continue to explore
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
// Come in and see, we can find that these are two nested ternary expressions
// There is another function we don't know. Let's continue to study it
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
Copy codeLet's move on
// This function looks very concise, all bit operations, so what is it doing?
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
Copy codeLet's take an example to verify what it is?
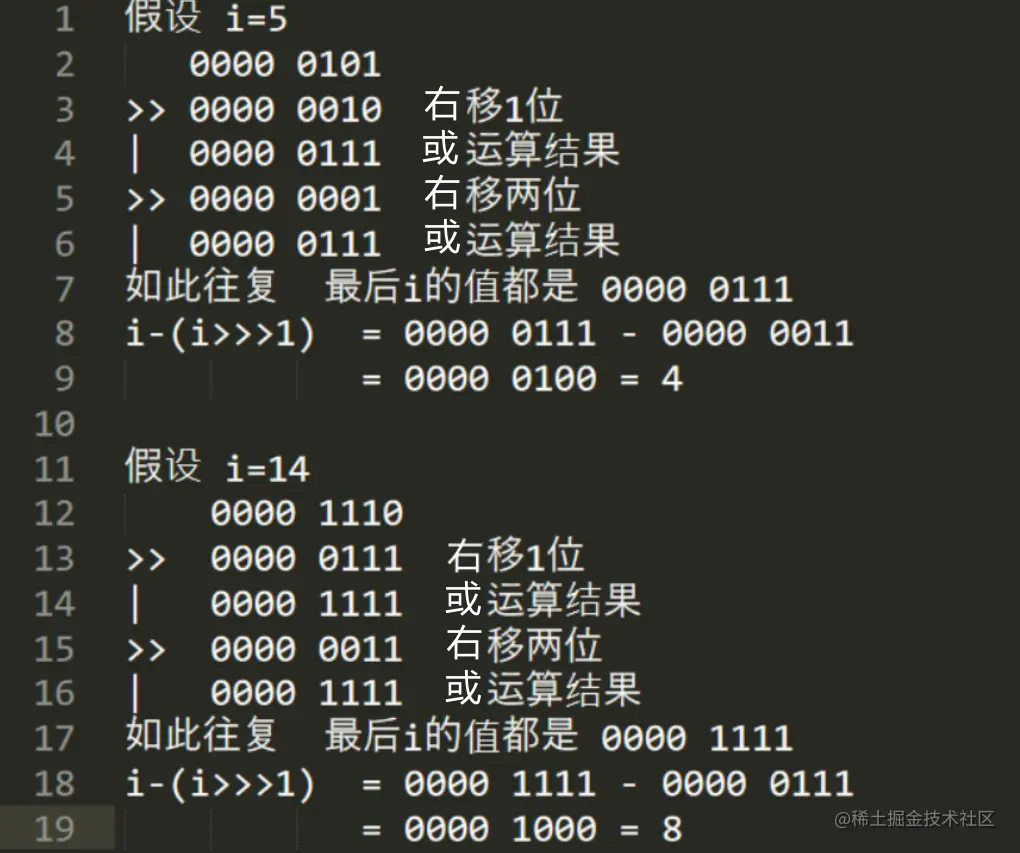
i wonder if you have found a rule. Does the final returned result have anything to do with the i we passed in?
Just called the roundUpToPowerOf2 function of highestOneBit. The official comment has told us to find a power greater than or equal to toSize
Then let's go back to the function of highestOneBit. If you pass in 5, it returns 4, and if you pass in 14, it returns 8. With the above interpolation, it should not be difficult to find that the function is just opposite to the purpose of roundUpToPowerOf2. highestOneBit is to find the number less than or equal to the power of 2 of i, that is, 5 - > 4, 15 - > 8.
So our question is, why do we have to move to the right five times? And the number of shifts to the right is different? Let's explore together~
The first shift to the right was 1 bit, the second shift to the right was 2 bits, the third shift to the right was 4 bits, and the fifth shift to the right was 16 bits, a total of 31 bits.
i wonder if you think the answer is approaching step by step. Our int type occupies 4 bytes in memory, a total of 32 bits. Suppose i is very large and takes up 32 bits, and then we move an integer word to the right by 31 bits. Can't this effect set all the last 31 bits to 1? Next, the following operation will subtract the number after its unsigned right shift from the number obtained, and the result is 0010 ····· (28 zeros are omitted here). Compared with the original number 1xxx ····· (28 x are omitted here, x represents 0 or 1), isn't it that the power of 2 less than or equal to i is found? Isn't it wonderful~
Well, now we're going to go back up step by step, because we're going from the function to the bottom, and now we're going to go back up~
//At this point, we return to here. highestOneBit is passed in 5 and returns 4
//Then the function is passed in 5 and returns 8
//It's obviously the opposite, so how does it happen?
/**
Assuming that number is now equal to 5, it eventually goes back to calling this integer highestOneBit((number - 1) << 1),
Below we all use bit operations to represent 0000 0101 - 0000 0001 = 0000 0100 < < 1 = 0000 1000 = 8
At this time, call the highestOneBit function and pass in 8. Isn't the number to the power of 2 less than or equal to 8 8?
At this time, isn't the number obtained by rounduptopoweroff2 function the power of 2 greater than or equal to 5?
**/
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
Copy codeAt this time, we can only sigh that the foreigners who realized these functions had already used the bit operation wonderfully at that time!!!
Continue to return up
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
//It is marked here and needs to be studied. Since it has nothing to do with the later, it will not be discussed first (this value is related to capacity expansion, which will be discussed at the end)
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//At this point, we can see that it opens up an array with the size of capacity for table.
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
Copy codeWell, after wandering back and forth for so long, we're going to return to the put function again
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
//When the key is null, call the following method to add null value
//Here you can click in when you review, because it is very simple and easy to understand. It saves time and is not alone
//The same as the following cycle
return putForNullKey(value);
//Skip to explanation 1 below
int hash = hash(key);
int i = indexFor(hash, table.length);
//Skip to explanation 2 below
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//When the calculated position of the put key is null at this time, it will be executed here and jump to explanation 3
modCount++;
addEntry(hash, key, value, i);
return null;
}
Copy code int hash = hash(key); //Calculate the hash value of the key
int i = indexFor(hash, table.length);
//Let's talk about the storage rules of each key in hashmap. We know that 1.7 it is implemented with linked list + array. Then we put in a pair of k-v each time
//How is it stored? These two lines are to calculate the specific position of the key in the array. It uses the hash value of the key to model the length of the array,
//The final calculation is the index stored in the array. The source code of indexFor is below
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1); //Why subtract 1, because the subscript of the array starts from 0
}
because hash()The function involves the knowledge of hash seed, so I won't explain it here (because I don't understand it yet,--!).
Copy code //The cycle here is actually easy to understand. We can see it by looking at the figure below
//When the key put in already exists, the original value will be replaced and the old value will be returned
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this); //There is no implementation here. It is implemented in LinkedHashMap, involving LRU cache structure
return oldValue;
}
}
Copy codeIt should be noted that the key put in each time is placed at the head of the linked list, that is, it will be pushed down
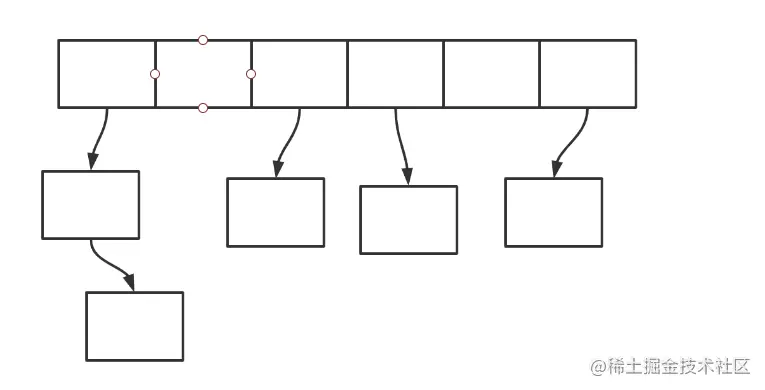
Don't BB, show me the code, let's write a demo to test it
public class HashMapTest {
public static void main(String[] args) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
System.out.println(hashMap.put(1, 10));
System.out.println(hashMap.put(1, 20));
}
}
Copy codeRun output: the result is obvious. When the value is put in for the first time, the hashmap is still empty. After putting in 1-10, the returned oldval is null
The second put 1-20 will overwrite the original 10, and then return oldval to 10. At this time, get(1) will be equal to 20.

// Hash is the hash value, and bucketIndex is the subscript of the key calculated above
void addEntry(int hash, K key, V value, int bucketIndex) {
// Here is the expansion of hashmap, which will be described separately below
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//Call this function if capacity expansion is not required
createEntry(hash, key, value, bucketIndex);
}
//This function simply adds the key
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++; //Mark the number of stored key Vals in the table array to determine whether capacity expansion is required
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
Copy codeThe above basically finished the liver. Now let's explore the problem of a wave of volume expansion
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
Copy codeWell, the threshold attribute value appears again. We know that the function of size is to represent the number of all k-v key value pairs in our hashmap. At this time, if the threshold is exceeded and there is already a value in the subscript of the current location to be stored (both conditions are indispensable), the capacity will be expanded.
// How to calculate the value of threshold? We can see this formula
// capacity * loadFactor initialization capacity * load factor
// The default capacity and load factor are taken as examples,
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int MAXIMUM_CAPACITY = 1 << 30;
// It can be calculated that capacity * LoadFactor = 16 * 0.75 = 12
// Take a small value and assign it to threshold. The maximum capacity is very large, so threshold = 12 by default
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
Copy codeThat is, when the element in the hash table is greater than or equal to 12, we want to put in a key value pair. Through the above explanation, we know the process of putting in the value. First, we need to calculate the hash value through hash(key), and then model the length of the array. In this way, we can calculate the subscript index. Suppose table [index]= Null, capacity expansion will occur; otherwise, capacity expansion will not occur.
(size >= threshold) && (null != table[bucketIndex]) //These two conditions are indispensable Copy code
Here's the code test:
Test1
public class HashMapTest {
public static void main(String[] args) throws Exception {
HashMap<String, String> map = new HashMap<>();
//We put in 15 k-v with a loop
for (int i = 1; i <= 15; i++){
map.put("test"+i,"test");
}
//Next, take the value in the reflection operation to verify
//No reflection. You can go to OB for an article I posted a long time ago
Class<? extends HashMap> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
Field size = mapType.getDeclaredField("size");
size.setAccessible(true);
System.out.println("size : " + size.get(map));
Field threshold = mapType.getDeclaredField("threshold");
threshold.setAccessible(true);
System.out.println("threshold : " + threshold.get(map));
Field loadFactor = mapType.getDeclaredField("loadFactor");
loadFactor.setAccessible(true);
System.out.println("loadFactor : " + loadFactor.get(map));
}
}
Copy codeGuess what the result will be? Don't worry about looking down, understand the code, and then write your guess in your heart or on paper
I guess capacity=16, size=15, threshold=12, loadFactor=0.75
Let's look at the results:
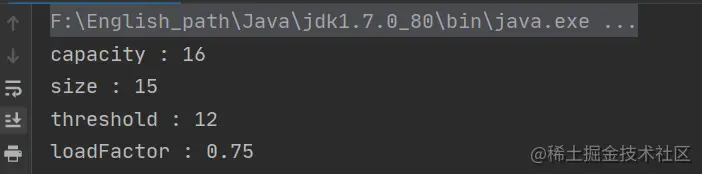
Are you right? In fact, the results are easy to understand. They are all default values, because the conditions for capacity expansion are not met at this time
Repeat the following expansion conditions again: size > = threshold & & table [index]= null
Next we test:
Test2
//To save space, I'll just post code different from the above
//I still put in 15 k-v this time. The only difference from the last test is the k-v put in
for (int i = 1; i <= 15; i++){
map.put(i+"",i*10+"");
}
Copy codeLet's guess the output?
The result is the same as above? capacity=16, size=15, threshold=12, loadFactor=0.75
The output result must be different from the above. The test is meaningful, otherwise it will be meaningless.
Running the output, we can find:
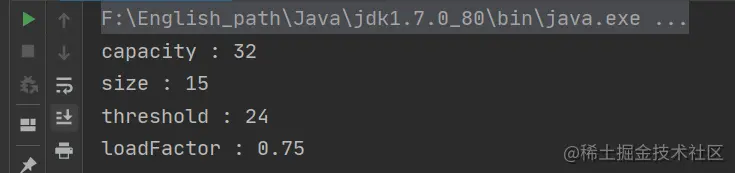
Good guy, Tuan Mie! It's different from what we expected. What's going on?
Let's go back and analyze the conditions for capacity expansion= null
Because it is obviously expanded, it shows that the above two conditions are met.
So now our problem comes? What is the difference between Test1 and Test2?
We can see that 15 values are also put in, and 15 > 12 obviously meet the first condition. Then why does Test1 not meet the second condition, and then Test2 meet it? Let me draw a picture to answer these doubts~
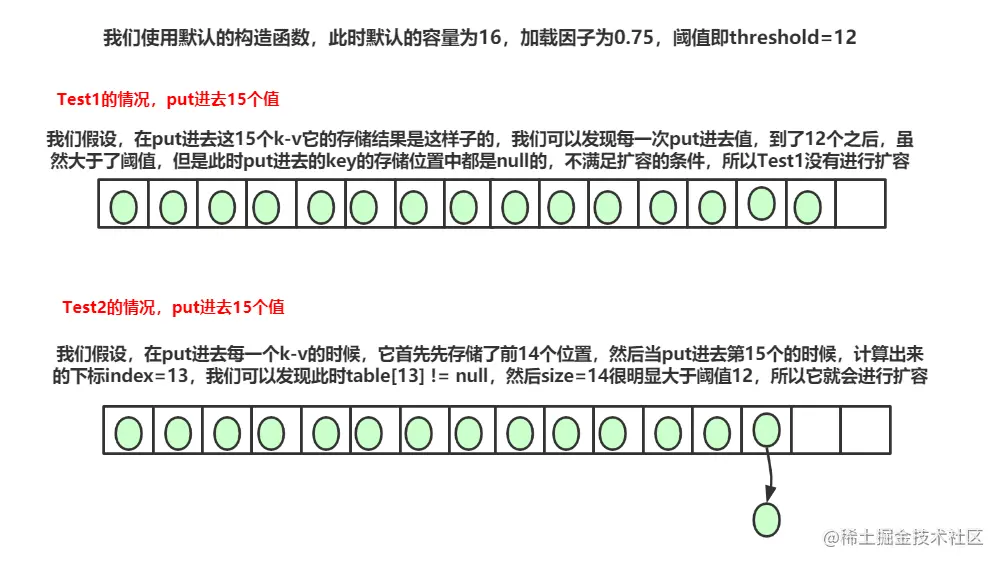
Introduce a noun, hash collision, what is hash collision called? As in Test2, when the 15th key Val is put in and the subscript value is calculated through hash, the same subscript is calculated from two different hash values, which is called hash collision.
Summary: the default capacity is 16, the loading factor is 0.75, and the threshold is 12.
Then, how many values can the hash table store before capacity expansion? You can save up to 11 + 15 + 1 = 27. How do you calculate it?
In extreme cases, in the first position, 11 K-V can be put in. At this time, it is less than the threshold 12, and there will be no capacity expansion. Then, in the remaining 15 positions, put in k-v. at this time, the size is greater than the threshold, but there is no hash collision, and there will be no capacity expansion. Then put in another K-V, and there will be hash collision, so there will be capacity expansion, That's why we have 11 + 15 + 1.
Now that we know the circumstances under which capacity expansion occurs, let's take a look at the expansion method:
//Call the resize function
//Pass in twice the oldtable length
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
void resize(int newCapacity) {
Entry[] oldTable = table;
//If the capacity of the old array is equal to the maximum capacity of 1 < < 30, directly set the threshold to the same size and then return.
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//Create a new array. The length of the array is twice the original. The parameters passed in above
Entry[] newTable = new Entry[newCapacity];
//Call the transfer function initHashSeedAsNeeded function to initialize the hash seed value, HashSeed
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
//Calculate the new threshold
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
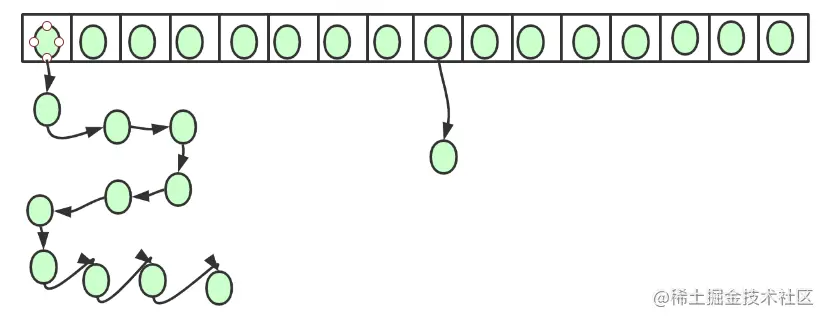
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { //Corresponding to 1 in the figure
while(null != e) {
Entry<K,V> next = e.next; //Corresponds to 2 in the figure
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //Corresponding to 3 in the figure
newTable[i] = e; //Corresponding 4
e = next; //Corresponding 5
}
}
}
Copy codeThe circle without background color represents null. Add it for drawing effect
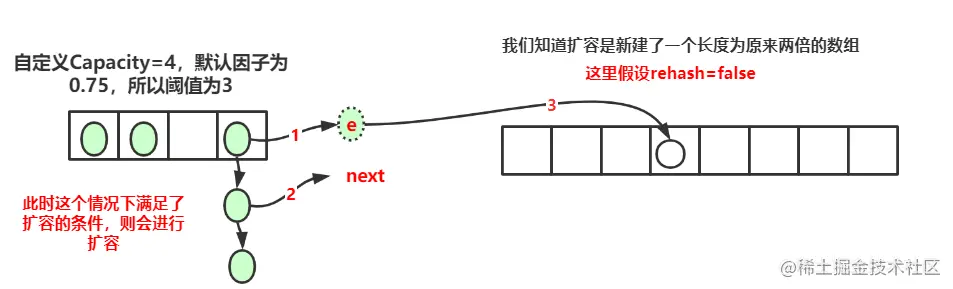
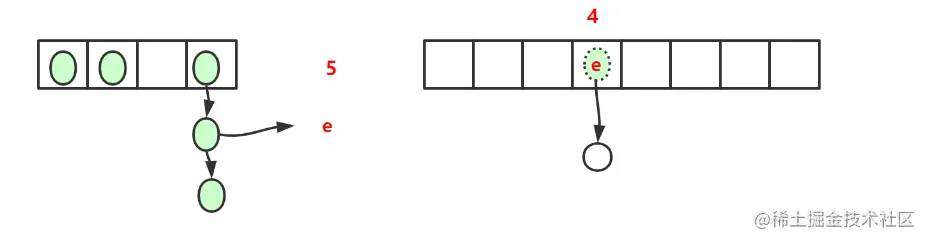
Because I don't know how to draw a dynamic diagram, I use two static diagrams to describe the dynamic process, how to go back and forth, and finally become the appearance of
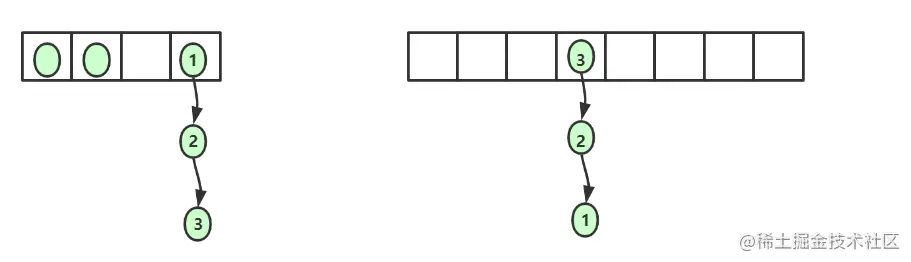
We can find that the linked list is reversed after capacity expansion.
Another thing to note is, is each k-v placed in the new array or the original subscript? If it's the same, doesn't it have the meaning of capacity expansion, so the subscript will be different. This line of code is to calculate the new subscript
int i = indexFor(e.hash, newCapacity); //Let's assume that the original hash value is 17, 17% 4 = = 1, 17% 8 = = 1. At this time, the calculated subscripts are all 1 //Assuming that the hash value is 21, 21% 4 = 1, 21% 8 = 5 = 1 + 4, it can be found that the subscripts are different //Because the original capacity * 2 is used for each capacity expansion, it is not difficult to find that the key is placed in the position of the new array, either unchanged, or the original subscript + the original capacity Copy code
At this point, the whole process of put method has been finished.
get method
First, we see the source code of the get method
public V get(Object key) {
// When key is null
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
Copy codeWhen key is null
As we know, HashMap supports null key. So first, when the key is null, call another method getForNullKey
private V getForNullKey() {
// Null if map is null
if (size == 0) {
return null;
}
// Traversal to find value with null key
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
// null if not found
return null;
}
Copy codeWhen the key is not null
Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); Copy code
The two lines of code are actually easy to understand. Find the entry of the corresponding key and return.
Let's look at the getEntry method again
final Entry<K,V> getEntry(Object key) {
// Null if map is null
if (size == 0) {
return null;
}
// In fact, the following methods and steps have been analyzed in the put method, and I forgot to turn forward
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
// null if not found
return null;
}
Copy codeSo far, the whole process of put and get has been finished. We can see that the most important method is the put method, and the get method is actually very simple.
But HashMap is more than that, because in jdk1 In version 8, it will reference the red black tree, so jdk1 Version 8 of HashMap is composed of linked list + array + red black tree. Next, I will analyze the source code, study thoroughly, and then continue to work out.
It's also difficult to see the source code, but the harvest of persistence is far beyond your expectation. Because the content of the article is completely from their own step-by-step source code analysis, if there are errors, please correct them~