Research on consistent HASH algorithm
Contributor: underground Stalker
1. Introduction
When studying the CRUSH algorithm of distributed storage Ceph, I saw the article introduce that it is a special consistency HASH algorithm, so I began to study the consistency HASH algorithm, make early preparation, and found that the concept is indeed close, so I first studied the implementation idea of consistency HASH algorithm.
2. Background and advantages of consistent HASH
In distributed systems, HASH algorithm is often used for data distribution to make massive data evenly distributed on different cache servers. The purpose is to evenly distribute the data to all nodes and share the pressure, especially in the cache system. A typical design is as follows:
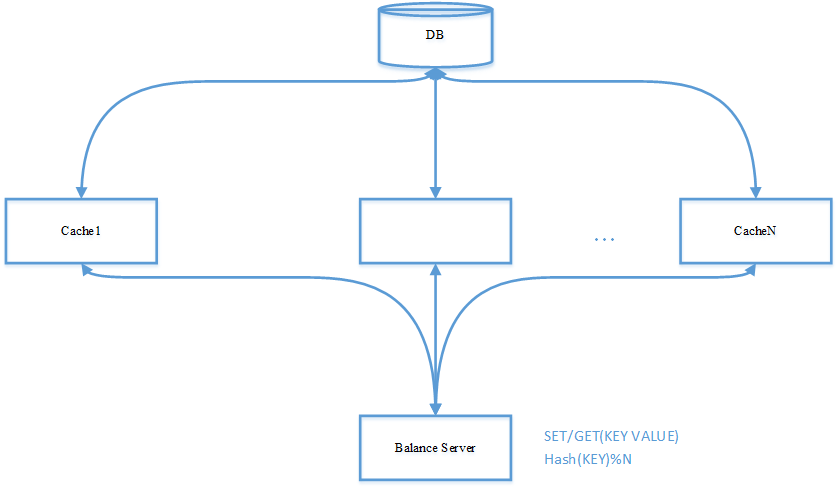
2.1 scenario description
In order to improve the system performance and solve the bottleneck of database access performance, n cache servers are set, and each cache server is responsible for 1/N data of the database. When accessing data, the application calculates the hash value according to the keywords in the data structure, locates the cache node where the data is located according to the hash value, and then accesses the data.
2.2 simplest model
The simplest way is to use the hash(key) mode N method to calculate the server location where the file falls. In the Find Cache Server step, you need to add a touch operation. The existing problems are:
Add machines to the cluster, and the calculation formula becomes hash(key) / (N + newAddedCount)
When the cluster exits the machine, the calculation formula becomes hash(key) / (N - removedCount)
As the denominator of the calculation formula changes, the calculation results will change when calculating the server location where the data is located. There will be a large number of KEY calculation results that cannot be hit, cache failure, and then direct access to the database. The pressure on the database will increase sharply and the access delay of the system will also increase. We need to find a way. When we expand the cluster or remove the failed machines from the cluster, only a small amount of data access fails. We can quickly rebuild the cache on the normal machines or new machines, so as to ensure the stability and reliability of the system.
2.2.1 Hash algorithm
The Hash(KEY) in the figure above represents the hash algorithm, which is generally called the hash algorithm. It is responsible for transforming the input of any length into the input of fixed length through the hash algorithm. It is equivalent to a mapping transformation, which compresses the message of any length into the message summary of a fixed length. Convert a data set from one space to another. Modular operation is the simplest hash algorithm. It's also the easiest to understand.
Add hash: add the input elements one by one to form the final result. The following algorithm takes string input as an example to illustrate how to calculate a hash value according to the string.
/**
* Addition hash
*
* @param key
* character string
* @param prime
* A prime number
* @return hash result
*/
public static int additiveHash(String key, int prime) {
int hash, i;
for (hash = key.length(), i = 0; i < key.length(); i++)
hash += key.charAt(i);
return (hash % prime);
}
This sample code is provided by JAVA to write.
Bit operation Hash; This type of Hash function fully mixes input elements by using various bit operations (commonly shift and XOR)
/**
* Rotate hash
*
* @param key
* Input string
* @param prime
* Prime number
* @return hash value
*/
public static int rotatingHash(String key, int prime) {
int hash, i;
for (hash = key.length(), i = 0; i < key.length(); ++i)
hash = (hash << 4) ^ (hash >> 28) ^ key.charAt(i);
return (hash % prime);
}
Multiplication Hash; This type of Hash function takes advantage of the irrelevance of multiplication
static int bernstein(String key)
{
int hash = 0;
int i;
for (i=0; i<key.length(); ++i)
{
hash = 33*hash + key.charAt(i);
}
return hash;
}
Division hash; Similar to multiplication hash, it is less used.
Mixed Hash; Hybrid Hash algorithm makes use of the above methods. Various common Hash algorithms, such as MD5 and Tiger, belong to this scope.
String MD5(byte[] source)
{
String s = null;
char hexDigits[] = { // A character used to convert a byte into a hexadecimal representation
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};
try {
java.security.MessageDigest md = java.security.MessageDigest.getInstance("MD5");
md.update(source);
byte tmp[] = md.digest(); //The calculation result of MD5 is a 128 bit long integer,
// Expressed in bytes, it is 16 bytes
char str[] = new char[16 * 2]; //If each byte is represented in hexadecimal, two characters are used,
// So it needs 32 characters to be expressed in hexadecimal
int k = 0; //Represents the corresponding character position in the conversion result
for (int i = 0; i < 16; i++) { //Starting from the first byte, every byte of MD5
// Conversion to hexadecimal characters
byte byte0 = tmp[i]; //Take the i th byte
str[k++] = hexDigits[byte0 >>> 4 & 0xf]; //Take the digital conversion of the upper 4 bits in the byte,
// >>>For logical right shift, shift the sign bits to the right together
str[k++] = hexDigits[byte0 & 0xf]; //Take the digital conversion of the lower 4 bits in the byte
}
s = new String(str); // The converted result is converted to a string
} catch (Exception e) {
e.printStackTrace();
}
return s;
}
}
Look up table Hash; Through a series of Hash algorithm sets as Hash function groups, a function is randomly taken out from the group for calculation.
Ring HASH. Consistency is the basis of HASH.
- Find the hash value and assign it to the circle of 0 ~ 2 ^ 32. In fact, hash the machine number to this ring.
- Use the same method to calculate the hash value of the stored data key and map it to the same circle
- Then, start searching clockwise from the data mapping to the location, and save the data to the first server found. If 2 ^ 32 still cannot find the server, it will be saved to the first server.
For the introduction of Hash algorithm, refer to the known documents: https://zhuanlan.zhihu.com/p/168772645
2.2.2 HASH collision
HASH collision refers to different keys, and the corresponding HASH value is the same after calculation. In this case, there are many different storage forms to deal with.
2.2.2.1 hash table based on zipper method
The HASH table based on zipper method organizes the data in the form of bucket. After HASH calculation, the collision data is placed in a bucket. Once the number of buckets changes, the location of the data will shake violently.
When implementing the algorithm, the Bucket can be understood as an array space with a pointer. A series of colliding data can be linked through the pointer.
When compared with the cache server cluster, each bucket is a cache server. Put the data set with the same Hash value on a cache server.
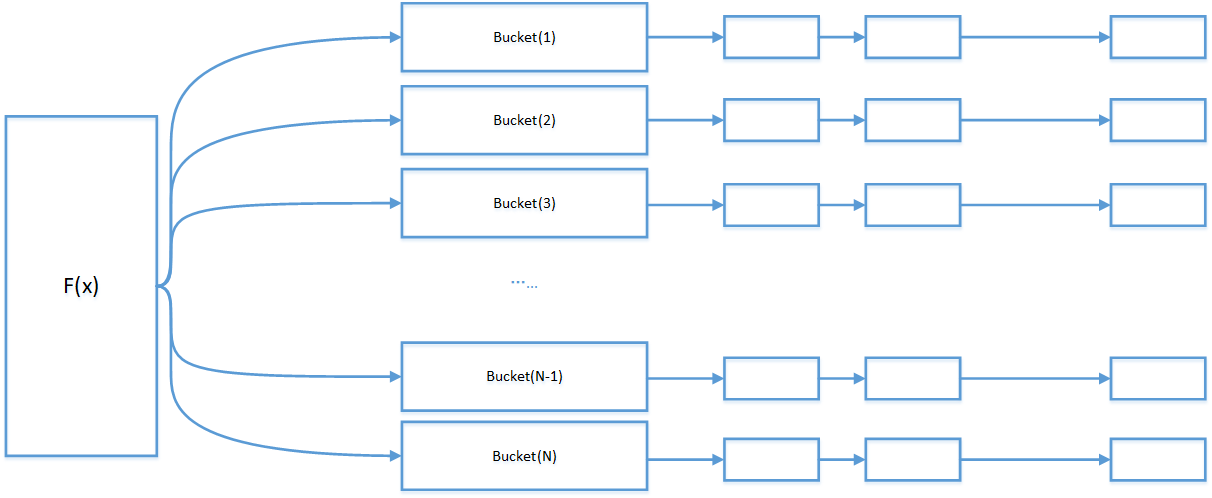
2.2.2.2 hash table based on linear detection method
The implementation idea of hash table based on linear detection method is to directly check the next position of hash table when collision occurs. Find an available location to save the data. In this case, the space of hash table is larger than the number of keys. When a collision occurs, the next position of the hash table is detected directly (the index is added by one). Such linear detection may produce three situations:
- Hit, the position has been occupied, the key is the same as the searched key, and the corresponding VALUE can be overwritten;
- Missed, the position has not been occupied, and the key is empty;
- Continue to search. The key at this position is different from the searched key. Continue to check the next until the key is found or an empty element is encountered.
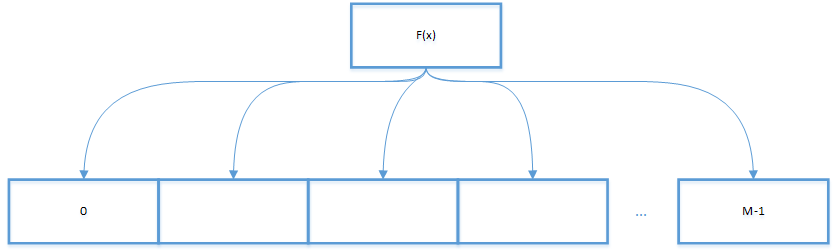
2.3 consistency HASH model
In order to avoid the severe jitter of data location when adding and deleting cache nodes in the traditional HASH method, professionals put forward clear requirements and form a paper, and the consistency HASH is generated.
Consistency HASH paper
2.3.1 basic design idea of consistency HASH
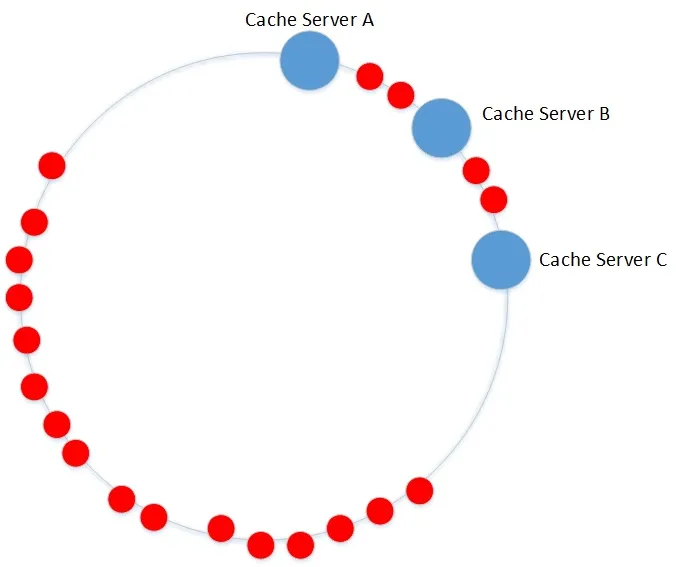
The consistent hash constructs a hash ring, maps the server nodes to the ring, and maps obj to the ring. Place them in the same space (0 ~ 2 ^ 32-1). For each object, clockwise find the first device node > = hash (obj), which is the target system to store. If it is not found, clockwise return to the first server.
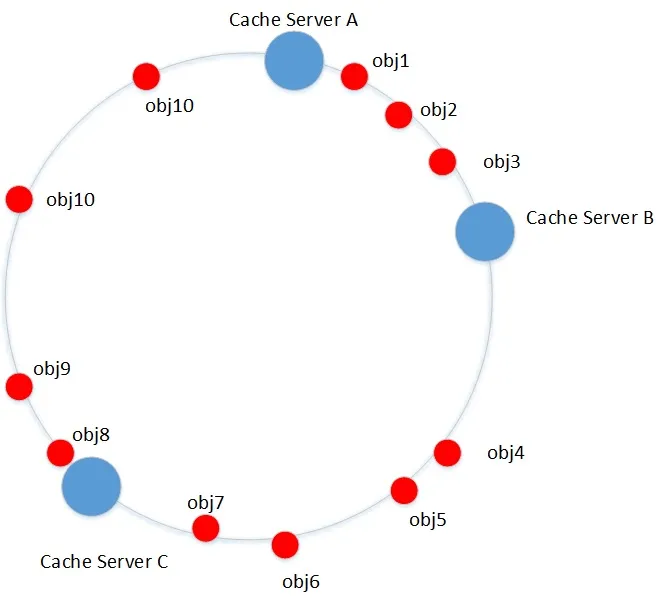
In the example above,
obj1 ~ 3 belong to Cache Server B;
obj4 ~ 7 belong to Cache Server C;
obj8~10 belongs to Cache Server A
It is the result of analysis according to the above rules.
However, there is A problem that the data distribution is uneven. As can be seen in the figure below, A large amount of data will be on server A, but there is only A small amount of data on server B and C. The data distribution is obviously unbalanced.
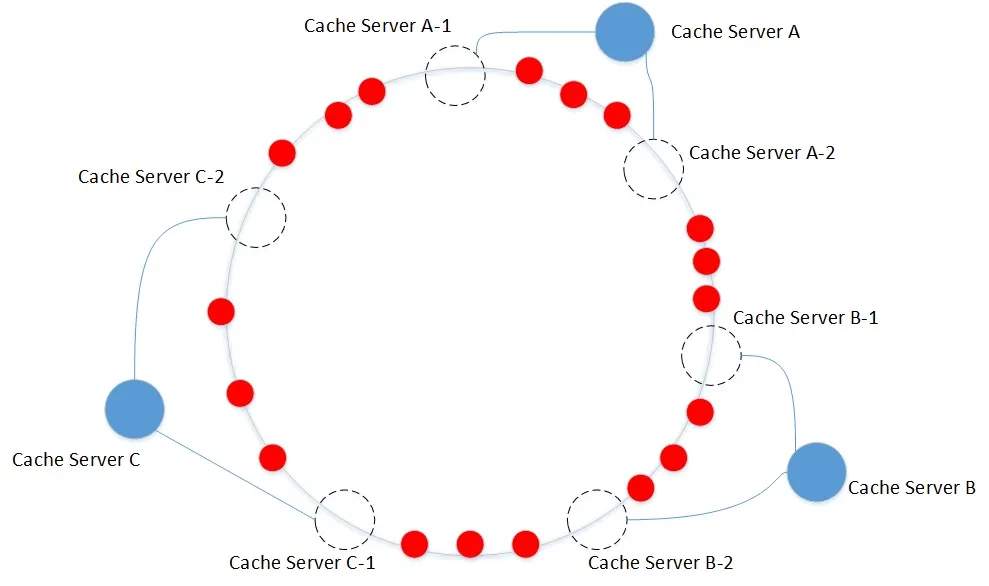
In order to solve the problem of data imbalance, virtual nodes are introduced into consistency HASH, objects are evenly mapped to virtual nodes, and then virtual nodes are mapped to physical nodes.
By setting a large number of virtual nodes, the data is evenly distributed to the virtual nodes, and finally the effect of evenly distributed to the physical nodes is achieved.
Here, the consistency hash meets our expectations:
1. Balance: the results after hash ing can be evenly distributed. For example, in storage, the data can be evenly distributed to all nodes, and there will be no situation that the amount of data in individual nodes is very small and individual nodes are very large;
2. Monotonicity: when adding or removing a node, it is either mapped to the original location or to a new node;
2.3.2 data distribution balance test
In order to test the characteristics of consistency hash algorithm and the influence of virtual nodes on data distribution balance, I implemented a consistency hash algorithm in C + + for statistical experiments.
The actual physical equipment node is 5 and the data volume is 10000. The corresponding IP address is (the IP address was hidden for security reasons in the original public network URL test):
xxx.xx.x.31 xxx.xx.x.32 xxx.xx.x.33 xxx.xx.x.34 xxx.xx.x.35
- Under the same data and the same physical node, test the distribution of data under different number of virtual nodes:
Test sample: 10000 URL records are used as object names and as input to hash functions
Hash function used: default std::hash() in c++11
The number of virtual nodes parameter in the data refers to the number of virtual nodes corresponding to each physical node.
1 Virtual node (one physical device corresponds to one virtual node) xxx.xx.x.31:80 764 xxx.xx.x.32:80 2395 xxx.xx.x.33:80 1478 xxx.xx.x.34:80 786 xxx.xx.x.35:80 4577 10 Node (one physical device corresponds to 10 virtual nodes) xxx.xx.x.31:80 1139 xxx.xx.x.32:80 4862 xxx.xx.x.33:80 1484 xxx.xx.x.34:80 1243 xxx.xx.x.35:80 1272 100 Node (one physical device corresponds to 100 virtual nodes) xxx.xx.x.31:80 2646 xxx.xx.x.32:80 2576 xxx.xx.x.33:80 1260 xxx.xx.x.34:80 705 xxx.xx.x.35:80 2813 512 Virtual node (one physical device corresponds to 512 virtual nodes) xxx.xx.x.31:80 2015 xxx.xx.x.32:80 2038 xxx.xx.x.33:80 1948 xxx.xx.x.34:80 2128 xxx.xx.x.35:80 1871 1024 Virtual node (one physical device corresponds to 1024 virtual nodes) xxx.xx.x.31:80 2165 xxx.xx.x.32:80 1389 xxx.xx.x.33:80 2045 xxx.xx.x.34:80 2123 xxx.xx.x.35:80 2278 2048 Node (one physical device corresponds to 2048 virtual nodes) xxx.xx.x.31:80 1976 xxx.xx.x.32:80 1939 xxx.xx.x.33:80 1892 xxx.xx.x.34:80 2164 xxx.xx.x.35:80 2029 4096 Node (4096 virtual nodes corresponding to a physical device) xxx.xx.x.31:80 1972 xxx.xx.x.32:80 2139 xxx.xx.x.33:80 2095 xxx.xx.x.34:80 1879 xxx.xx.x.35:80 1915
It can be seen from the data that with more and more corresponding virtual nodes, the distribution of data becomes more and more balanced. However, when a certain number of virtual nodes reach the bottleneck, it is impossible to achieve absolute balance after all.
2.3.3 implementation of consistent hash algorithm
//A hash ring with virtual nodes is constructed. For each real physical node, several virtual nodes are configured and sorted
for (RNode node : rnodes)
{
for (int i = 1; i <= virtual_node_count; i++)
{
VNode vnode;
vnode.ip_port = node.ip_port + "#" + to_string(i);
vnode.id = myhash(vnode.ip_port); //Mapping of virtual nodes on hash rings
circle.push_back(vnode);
node.virtual_nodes.push_back(vnode);
}
}
sort(circle.begin(), circle.end(), cmpVNode);
//Calculate which virtual node each URL falls on
VNode getLocation(string url, vector<VNode>& vnodes)
{
VNode tmp;
tmp.id = myhash(url.c_str());
vector<VNode>::iterator iter = std::lower_bound(vnodes.begin(), vnodes.end(), tmp, cmpVNode);
if (iter == vnodes.end())
{
return vnodes[0];
}else
{
return *iter;
}
}
//Find the corresponding physical node according to the virtual node
string real_node = getRealNodeInfo(vnode);
3. Further study of crushmap
The purpose of studying consistency HASH is to better understand the principle of distributed storage in Ceph.
CRUSHMAP algorithm. Here is a brief description of how objects in Ceph are mapped to a hard disk of a specific device.
In Ceph, each object belongs to a pg. I understand these PG as virtual nodes in the consistent hash in order to make the object distribution more uniform.
How does pg map to OSD. In the above, this mapping relationship is relatively simple, that is, many to one. In ceph, it is more complex, because the mapping relationship depends on the topology of the cluster, and each object has multiple copies. You need to specify a mapping algorithm to calculate the primary OSD and copy OSD of pg.
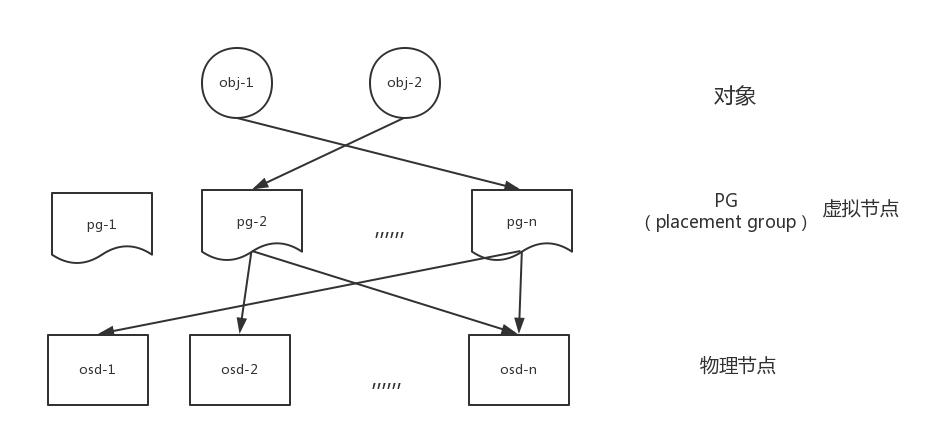
I will explain the mapping relationship between obj and pg and how to map between pg and osd in my blog in the future.
4 appendix
Consistency hash algorithm is widely used in distributed storage, cache system and nginx load balancing. Understanding consistency hash algorithm is very helpful to understand the implementation mechanism in distributed system. The following is a more in-depth article on consistency hash, which can be studied.
Use of consistent HASH in nginx
Consistency HASH in database sub table
Ceph data distribution: CRUSH algorithm and consistency Hash - shanno
Amazon Dynamo system
jump Consistent hash: zero memory consumption, uniform, fast, concise, consistent hash algorithm from Google