
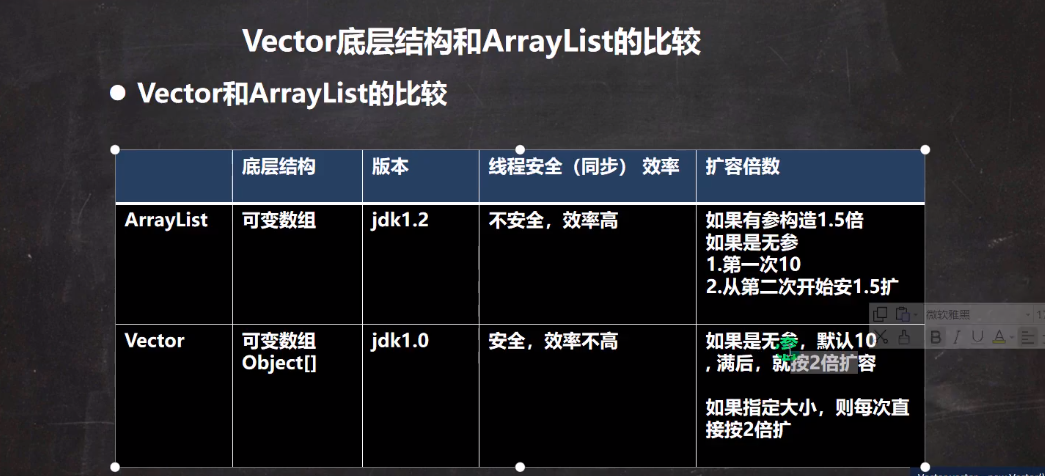
- ArrayList considerations:
-
null values can be added, and multiple data can be added. There are arrays at the bottom to realize data storage.
-
ArrayList is basically the same as Vector. Processing ArrayList is thread unsafe (high execution efficiency). In case of multithreading, ArrayList is not recommended
Source code analysis:
ArrayList
1. ArrayList maintains an array elementData of Object type.
transient Object[] elementData. Transient means transient. When modifying an attribute, it means it will not be serialized
2. When the ArrayList object was originally created, if the parameterless constructor was used, the initial elementData capacity is 0
, if it is added for the first time, the capacity expansion elementData is 10. If it needs to be expanded again, the capacity expansion elementData is 1.5 times.
3. If the constructor with the specified size is used directly, the initial elementData capacity is the specified size. If it needs to be expanded again, the direct expansion capacity is 1.5 times of elementData.
Vector
1. The bottom layer of vector is also an object array, protected Object[] elementData;
2. Vector is thread synchronous, that is, thread safe. The operation method of vector class is synchronized
3. When thread synchronization safety is required, consider using Vector
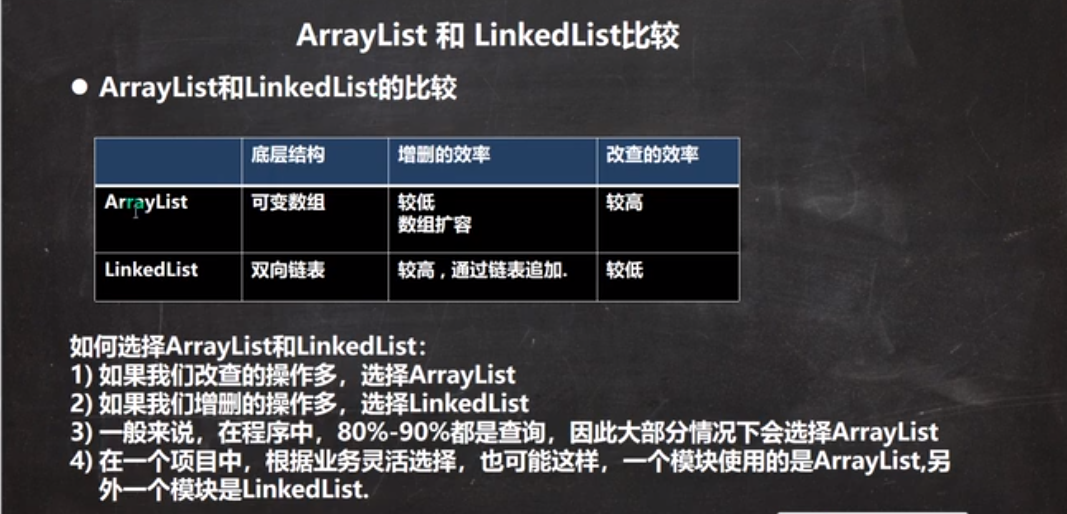
LinkedList
1. The bottom layer realizes two-way linked list + two end pair of columns
2. You can add any element (the element can be repeated), including null
3. Thread is unsafe and synchronization is not realized

public class LinkList_ {
public static void main(String[] args) {
Node tom = new Node("tom");
Node cat = new Node("cat");
Node mouse = new Node("mouse");
//Connect three nodes
// tom->cat->mouse
tom.next = cat;
cat.next = mouse;
//mouse->cat->tom
mouse.pre = cat;
cat.pre = tom;
Node first = tom; //Let the first reference point to Tom to form a header node
Node last = mouse; //Let the last reference point to mouse to form a tail node
while (first != null){
System.out.println(first.item);
first = first.next;
}
System.out.println("============");
while (last != null){
System.out.println(last.item);
last = last.pre;
}
System.out.println("============");
//Add a node and a kitty between cat and mouse
Node kity = new Node("kity");
kity.next = mouse;
kity.pre = cat;
cat.next = kity;
mouse.pre = kity;
first = tom;
while (first != null){
System.out.println(first.item);
first = first.next;
}
}
}
class Node {
public Object item; //Real stored data
public Node next; //Last node
public Node pre; //Previous node
public Node(Object item) {
this.item = item;
}
@Override
public String toString() {
return "Node name=" + item;
}
}
LinkedList add source code debug:
linkedList.add(1);
add Underlying call linkLast.
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
Set:
Set interface adopts the following methods:
- Like the List interface, the Set interface is also a sub interface of the Collection. Therefore, the common methods are the same as the Collection interface.
Set interface traversal mode - You can use iterators.
- Enhanced for
- Cannot be retrieved by index
HashSet
- The bottom layer of HashSet is actually HashMap.
public HashSet() {
map = new HashMap<>();
}
- Null can be stored, and only one null can be stored
- HashSet does not guarantee that the elements are in order, that is, it does not guarantee that the data stored in the elements is consistent with the extraction order
- The same element cannot be stored
Source code analysis
Let's analyze a set of codes first:
public class HashSet01 {
public static void main(String[] args) {
Set hashSet = new HashSet<>();
hashSet.add("lucy");
hashSet.add(new Dog_("tom"));
hashSet.add(new Dog_("dog"));
System.out.println(hashSet);
System.out.println("*-*-*-*-*-**-");
hashSet.add("test");
hashSet.add("test");
System.out.println(hashSet);
}
}
class Dog_ {
private String name;
public Dog_(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog_{" +
"name='" + name + '\'' +
'}';
}
}
The running result of the above code:
Conclusion:
HashSet underlying mechanism principle (the underlying layer is composed of HashMap = = "array + linked list + red black tree)
- When adding an element, the hash value is obtained first and will be converted into an index value.
- Find the storage data table table (array) and see whether the index position has stored the element value to be added at present.
- If not, add it directly.
- If yes, call equals for comparison. If it is the same, discard the addition. If it is different, add it to the end.
- In JDK8, if the number of elements in a linked list reaches treeify_ Threshold (the default value is 8), and the table size > = min_ TREEIFY_ Capability (64 by default), the linked list will be trealized (red black tree)
Debug
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
1,Initialize a HashSet
public HashSet() {
map = new HashMap<>();
}
2,implement add method
public boolean add(E e) {
// E = = > for the currently added element, present = = > private static final object present = new object();
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
Continue calculation hash value
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Core method
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//transient Node<K,V>[] table;
//If the initialization table is empty, you will enter this if and call the resize() method to initialize the array size
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//Calculate whether an element exists at a certain position of the array according to the hash value. If it does not exist, directly create a node
tab[i] = newNode(hash, key, value, null);
else {
//If it does not comply with the above, enter else and calculate the array subscript position through the hash value,
Node<K,V> e; K k;
//If it is the same object or the content is the same, enter if and you cannot add it
//p represents the head node of each linked list
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//Judge whether it is a node of red black tree
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//If the index position corresponding to table already exists in the form of a linked list
//(1) , which are different from each element of the linked list, are added to the end of the linked list. After adding elements to the linked list, judge immediately whether the linked list has reached eight nodes. When it has reached eight nodes, call treeifyBin() method to convert the current linked list into a red black tree A judgment should also be made when turning into a red black tree, that is, tab = = null | (n = tab. Length) < min_ TREEIFY_ Capability (64)) array size. Only when the size of the array is satisfied can it be trealized. Otherwise, the capacity of the array will be expanded.
// (2) . in the process of comparing with each element of the linked list in turn, if it is the same, it will break directly without adding.
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//Judge each time to see if it exceeds the actual array size
if (++size > threshold)
resize();
//Empty method for subclass implementation
afterNodeInsertion(evict);
//Return null, that is, the addition is successful
return null;
}
Method of calculating array size
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold; //The initial value of threshold is defined as 0
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0)
newCap = oldThr;
else {
//It will enter here during initialization
// static final int DEFAULT_ INITIAL_ CAPACITY = 1 << 4; Therefore, the initialization size is 16
//The default loading factor is 0.75, so the actual initialization size is 16 * 0.75 = 12
//static final float DEFAULT_LOAD_FACTOR = 0.75f;
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Code verification conclusion:
- The bottom layer of HashSet is HashMap. When it is added for the first time, the table array is expanded to 16, and the threshold is 16 * the loading factor is 0.75 = 12.
- If the table array reaches the critical value of 12, it will be expanded to 16 * 2 = 32. At this time, the new critical value is 24, and so on
- In Java 8, if the number of elements in a linked list reaches TREEIFY_THRESHOLD = 8, and the size of table > = min_ TREEIFY_ Capability (64 by default) will be trealized, otherwise the array capacity expansion mechanism will still be adopted.
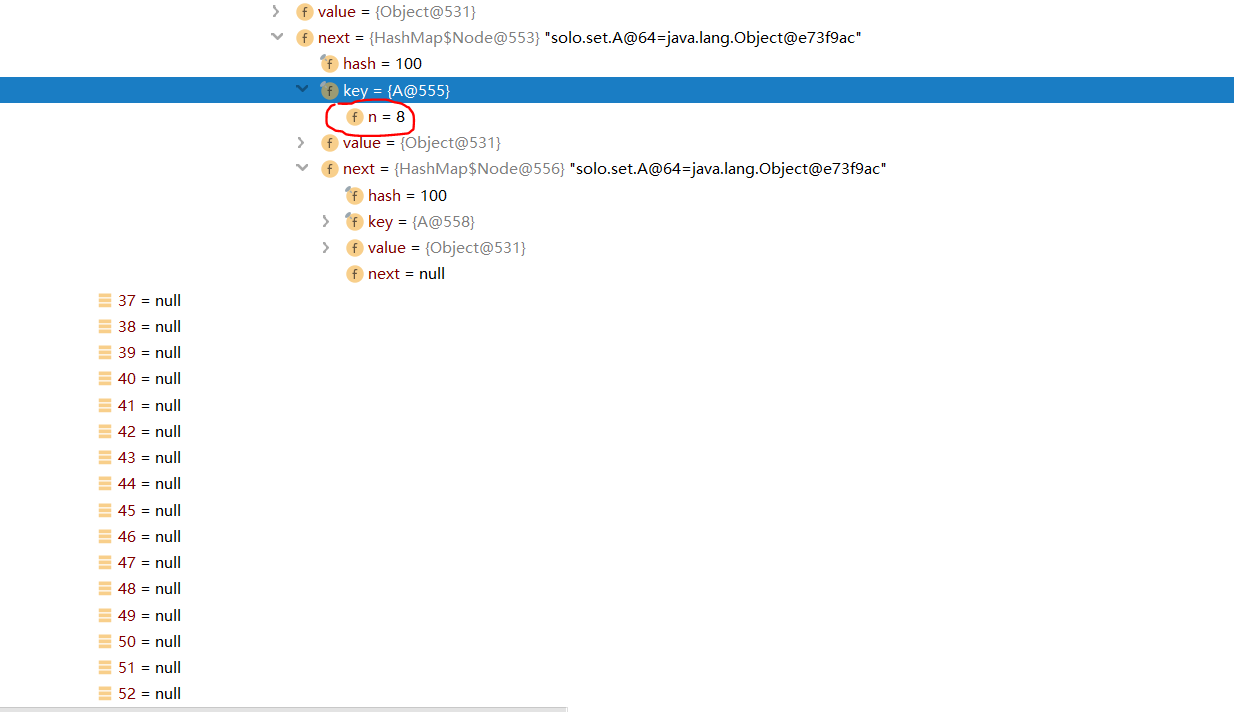
HashSet hashSet = new HashSet<>();
for (int i = 0; i < 100; i++) {
hashSet.add(i);
}


HashSet hashSet = new HashSet<>();
for (int i = 0; i < 12; i++) {
hashSet.add(new A(i));
}
class A{
private int n;
public A(int n) {
this.n = n;
}
//Rewrite the hashcode method to ensure that each object of new has the same hashcode value, that is, the subscript falls in the same position, which is convenient for testing.
@Override
public int hashCode() {
return 100;
}
}
You can see that when the number of elements exceeds 12, the array is expanded. Verified 1,2
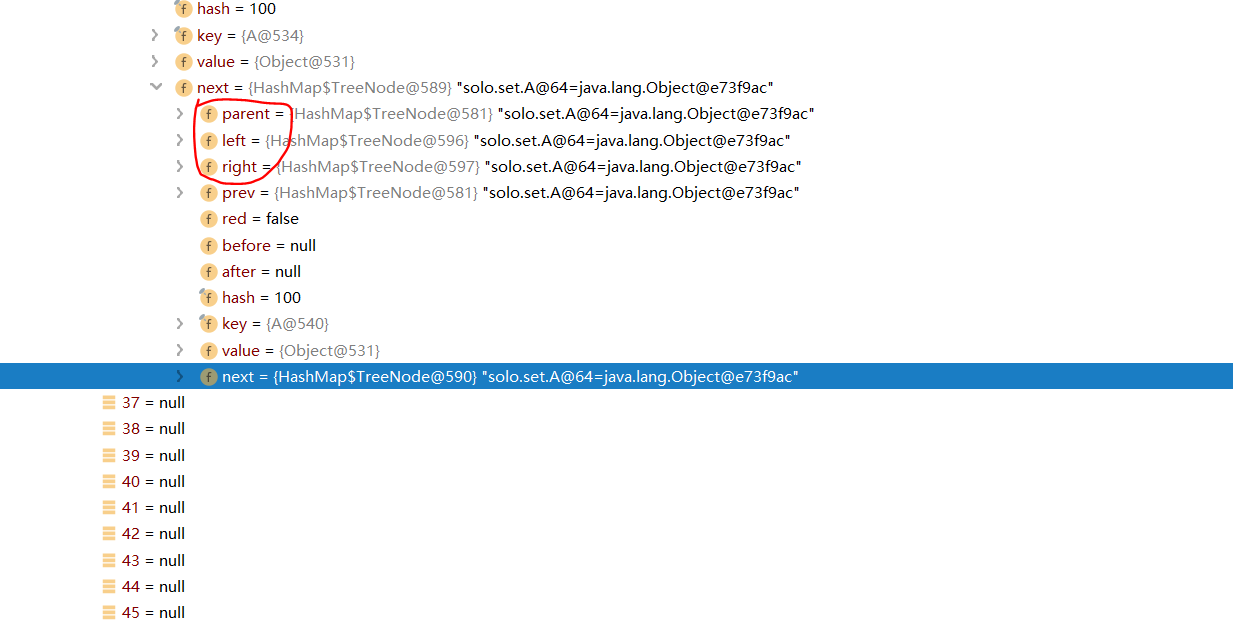
It can be seen that when the length of the array reaches 64, the capacity is expanded first, and then if you continue to add elements, the data structure of the node will become a tree structure. Verify the conclusion 3
LinkedHashSet:
- LinkedHashSet is a subclass of HashSet.
- The bottom layer of LinkedHashSet is a LinkedHashMap, and the bottom layer maintains an array + two-way linked list.
- LinkedHashSet determines the storage location of elements according to the hashCode value of elements, and uses the linked list to maintain the order of elements, which makes the elements appear to be saved in insertion order.
- LinkedHashSet does not allow adding duplicate elements.
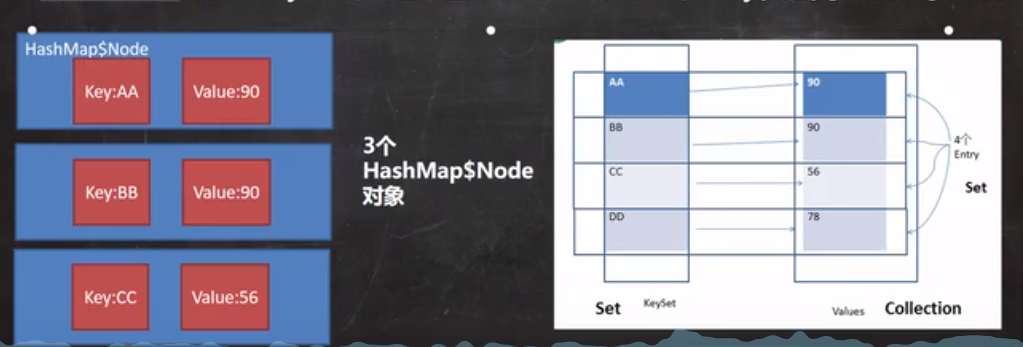
HashMap
- The format of data stored in the Map is key value. A pair of key values are placed in a HashMap$Node. Because the Node implements the Entry interface, it can also be said that a pair of k-v is an Entry. The important method getKey () is provided in Entry; getValue();
- In order to facilitate traversal, an entryset set is also created. The data type stored in the set is entry, that is, transient set < map Entry<K,V>> entrySet. In fact, only the reference address of k-v is stored in the entry.
- The type defined in the entrySet is map Entry < K, V >, but the HashMap$Node is actually stored because the static class node < K, V > implements map Entry<K,V>
jdk7.0 hashmap bottom layer implementation [array + linked list], jdk8 0 bottom layer implementation [array + linked list + red black tree]
Capacity expansion mechanism: (consistent with HashSet)
- The underlying layer of HashMap maintains the array table of Node type, which is null by default
- When creating an object, initialize the load factor to 0.75
- When adding key val, the index in the table is obtained through the hash value of the key Then judge whether there are elements in the index. If there are no elements, add them directly. If there is an element in the index, continue to judge whether the key of the element is equal to the key to be added. If it is equal, directly replace val; If it is not equal, you need to judge whether it is a tree structure or a linked list structure and deal with it accordingly. If it is found that the capacity is insufficient when adding, it needs to be expanded.
- For the first addition, you need to expand the capacity. The capacity of the table is 16 and the threshold is 12
- If you want to expand the capacity later, you need to double the capacity of the table, and the critical value is twice the original, that is, 24, and so on
- In Java 8, if the number of elements of a linked list exceeds tree threshold (8 by default), and the size of the table > = min tree capability (64 by default), it will be trealized (red black tree)
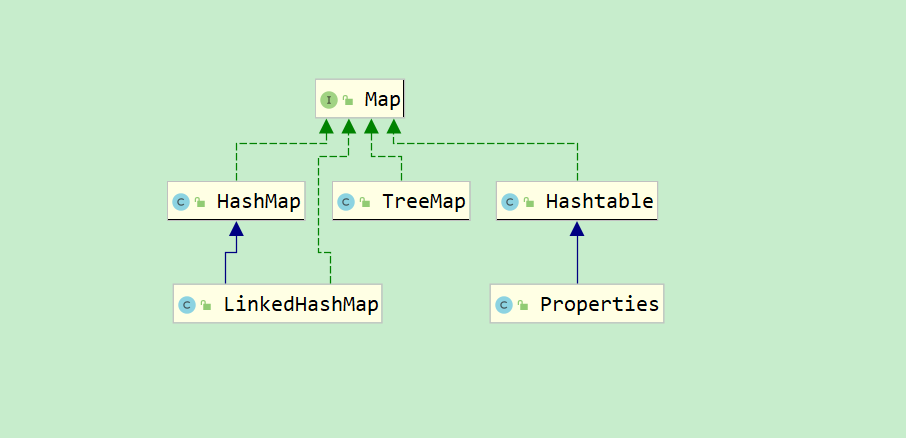
HashTable
- The storage elements are key value pairs, i.e. k-v
- The key and value of hashtable cannot be null
- Hashtable is thread safe, while HashMap is not
- The underlying array structure HashTable$Entry [], initialization Size 11, loading factor 0.75, critical value 8
HashTable capacity expansion mechanism:
int newCapacity = (oldCapacity << 1) + 1;

Properties
- The Properties class inherits from the Hashtable class and implements the Map interface. It also uses K-V key value pairs to save data.
- The usage features are similar to Hashtable.
- Also available from xxx.properties In the Properties file, load the data into the Properties class object, and read and modify it.

TreeSet
- It can be used to sort stored elements. The incoming elements or objects need to implement the Comparator interface, otherwise ClassCastException will be reported.
- Source code analysis TreeSet the bottom layer is TreeMap. The put method follows the put method of TreeMap.
TreeSet class
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
TreeMap:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
TreeMap
Same as TreeSet.