Summary
This is a series of pytorch notes that follow station b. There are a lot of classified articles about renet model image recognition on the internet, but the image part is usually just a link to it. Or read a well-known article and prepared the dataset from scratch.
One dataset preparation
The dataset consists of 102 categories of flowers from the United Kingdom. Each category consists of 40-258 pictures
Visual Geometry Group - University of Oxford

It is the 1, 4, 5 parts of the red circle. 1. More than 8,000 picture packages.

4,5 can be downloaded with wget and copied to the project folder
imagelabels.mat
There are 8189 columns in total, and the numbers in each column represent the category number.
setid.mat
-trnid field:There are a total of 1020 columns, and every 10 columns are a picture of a class of flowers. The numbers in each column represent the picture number. -valid field:There are a total of 1020 columns, and every 10 columns are a picture of a class of flowers. The numbers in each column represent the picture number. -tstid field:There are 6149 columns in total, and the number of columns for each type of flower is variable. The numbers in each column represent the picture number.
import scipy.io # For loading mat files
import numpy as np
import os
from PIL import Image
import shutil
labels = scipy.io.loadmat('./data/flower_data/imagelabels.mat')
labels = np.array(labels['labels'][0]) - 1
print("labels:", labels)
######## flower dataset: train test valid data id Identification ########
setid = scipy.io.loadmat('./data/flower_data/setid.mat')
validation = np.array(setid['valid'][0]) - 1
np.random.shuffle(validation)
train = np.array(setid['trnid'][0]) - 1
np.random.shuffle(train)
test = np.array(setid['tstid'][0]) - 1
np.random.shuffle(test)
######## flower data path Data Save Path ########
flower_dir = list()
######## flower data dirs Generate absolute paths and names to hold data ########
for img in os.listdir("/Users/benmu/Downloads/jpg"):
######## flower data ########
flower_dir.append(os.path.join("/Users/benmu/Downloads/jpg", img))
######## flower data dirs sort Absolute path and name sorting of data from smallest to largest ########
flower_dir.sort()
# print(flower_dir)
des_folder_train = "/Users/benmu/PycharmProjects/pythonProject128/data/flower_data/train"
for tid in train:
######## open image and get label ########
img = Image.open(flower_dir[tid])
# print(flower_dir[tid])
img = img.resize((256, 256), Image.ANTIALIAS)
lable = labels[tid]+1
# print(lable)
path = flower_dir[tid]
print("path:", path)
base_path = os.path.basename(path)
print("base_path:", base_path)
classes = str(lable)
class_path = os.path.join(des_folder_train, classes)
# Judgement Result
if not os.path.exists(class_path):
os.makedirs(class_path)
print("class_path:", class_path)
despath = os.path.join(class_path, base_path)
print("despath:", despath)
img.save(despath)
des_folder_validation = "/Users/benmu/PycharmProjects/pythonProject128/data/flower_data/validation"
for tid in validation:
######## open image and get label ########
img = Image.open(flower_dir[tid])
# print(flower_dir[tid])
img = img.resize((256, 256), Image.ANTIALIAS)
lable = labels[tid]+1
# print(lable)
path = flower_dir[tid]
print("path:", path)
base_path = os.path.basename(path)
print("base_path:", base_path)
classes = str(lable)
class_path = os.path.join(des_folder_validation, classes)
# Judgement Result
if not os.path.exists(class_path):
os.makedirs(class_path)
print("class_path:", class_path)
despath = os.path.join(class_path, base_path)
print("despath:", despath)
img.save(despath)
des_folder_test = "/Users/benmu/PycharmProjects/pythonProject128/data/flower_data/test"
for tid in test:
######## open image and get label ########
img = Image.open(flower_dir[tid])
# print(flower_dir[tid])
img = img.resize((256, 256), Image.ANTIALIAS)
lable = labels[tid]+1
# print(lable)
path = flower_dir[tid]
print("path:", path)
base_path = os.path.basename(path)
print("base_path:", base_path)
classes = str(lable)
class_path = os.path.join(des_folder_test, classes)
# Judgement Result
if not os.path.exists(class_path):
os.makedirs(class_path)
print("class_path:", class_path)
despath = os.path.join(class_path, base_path)
print("despath:", despath)
img.save(despath)
Classification Number Effect:

Here the image is uniformly sized 256x256. Common models require this or 224x224 size. You can also process the following image enhancement sections without adjusting them.
Train, validation are 1020, test 6149 can adjust itself, I just changed test to train.
Data Enhancement:

The framework is already implemented and does not need to be handled by opencv alone.
data_dir = './data/flower_data/'
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'
# Perform data enhancement operations
data_transforms = {
'train': transforms.Compose([
transforms.RandomRotation(45), # Random rotation, -45 to 45 degrees
transforms.CenterCrop(224), # Cut from center to 224
transforms.RandomHorizontalFlip(p=0.5), # Probability with p random horizontal inversion
transforms.RandomVerticalFlip(p=0.5), # Flip vertical
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1), ##Brightness, Contrast, Saturation, Hue
transforms.RandomGrayscale(p=0.025), # 0.025% chance of becoming grayscale
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), # Mean, Variance
]),
'valid': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
Image addition refers to rotation, cropping, and finally normalization on the training set. valid does not require rotation.
batch_size = 8
# Include: path, enhancement
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in
['train', 'valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}
class_names = image_datasets['train'].classes
print(image_datasets)Print image_ The datasets contain information:
{'train': Dataset ImageFolder
Number of datapoints: 6149
Root location: ./data/flower_data/train
StandardTransform
Transform: Compose(
RandomRotation(degrees=[-45.0, 45.0], interpolation=nearest, expand=False, fill=0)
CenterCrop(size=(224, 224))
RandomHorizontalFlip(p=0.5)
RandomVerticalFlip(p=0.5)
ColorJitter(brightness=[0.8, 1.2], contrast=[0.9, 1.1], saturation=[0.9, 1.1], hue=[-0.1, 0.1])
RandomGrayscale(p=0.025)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
), 'valid': Dataset ImageFolder
Number of datapoints: 1020
Root location: ./data/flower_data/valid
StandardTransform
Transform: Compose(
Resize(size=256, interpolation=bilinear, max_size=None, antialias=None)
CenterCrop(size=(224, 224))
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)}The actual name of the label cat_to_name.json

Show data
Note that tensor's data needs to be converted to numpy The format of the
def im_convert(tensor):
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
##Because tensor is c*h*w, we need to turn it into h*w*c
image = image.transpose(1, 2, 0)
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))
##clip function, which changes numbers less than 0 to 0 and numbers greater than 1 to 1
image = image.clip(0, 1)
return image
fig=plt.figure(figsize=(20, 12))
columns = 4
rows = 2
dataiter = iter(dataloaders['valid'])
inputs, classes = dataiter.next()
for idx in range (columns*rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))])
plt.imshow(im_convert(inputs[idx]))
plt.show()

2. Load the model provided in models
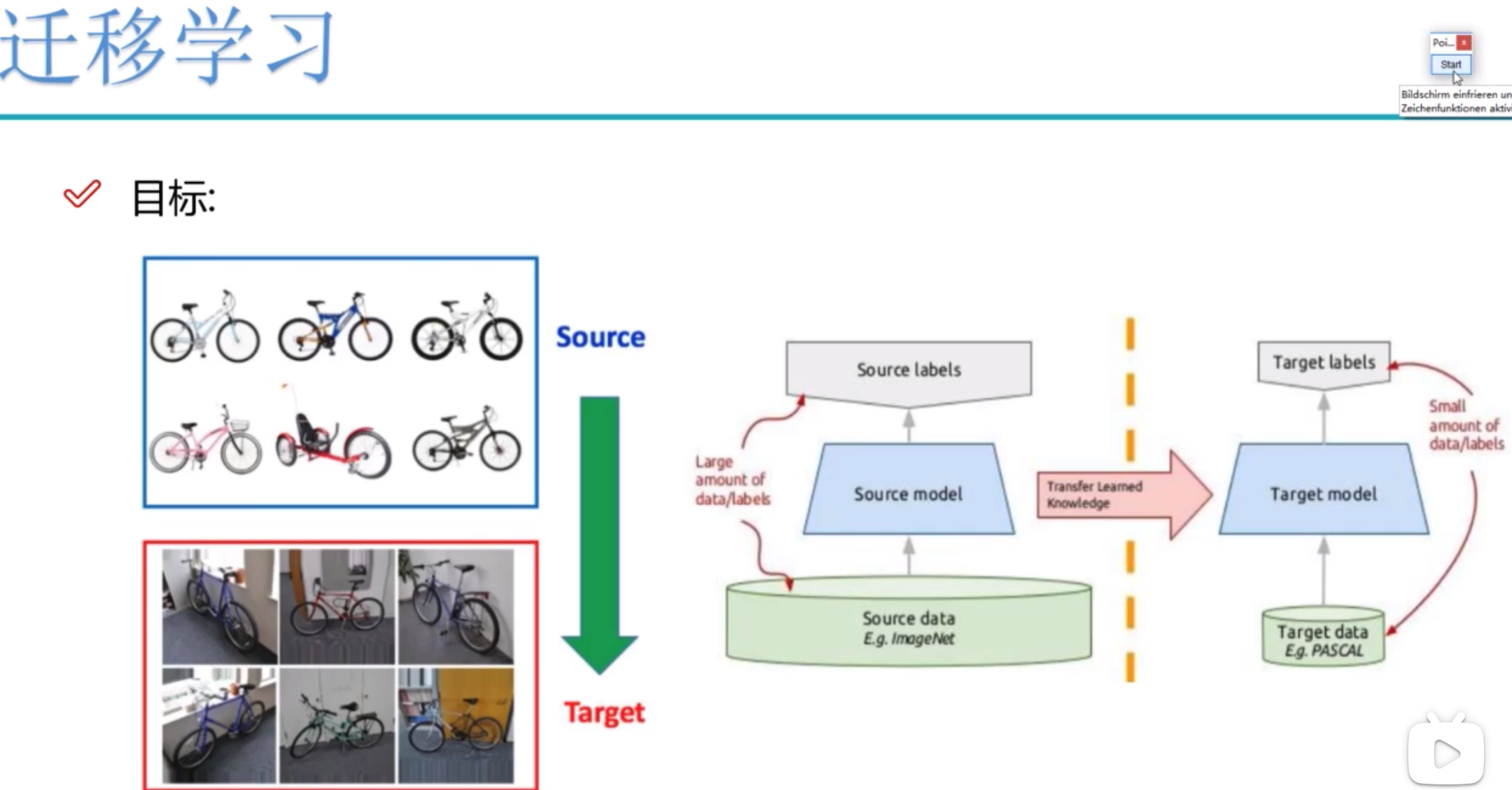 The purpose of migration learning is to use the weights and bias parameters of existing models as our initialization parameters. Try to approximate your model as much as possible.
The purpose of migration learning is to use the weights and bias parameters of existing models as our initialization parameters. Try to approximate your model as much as possible.
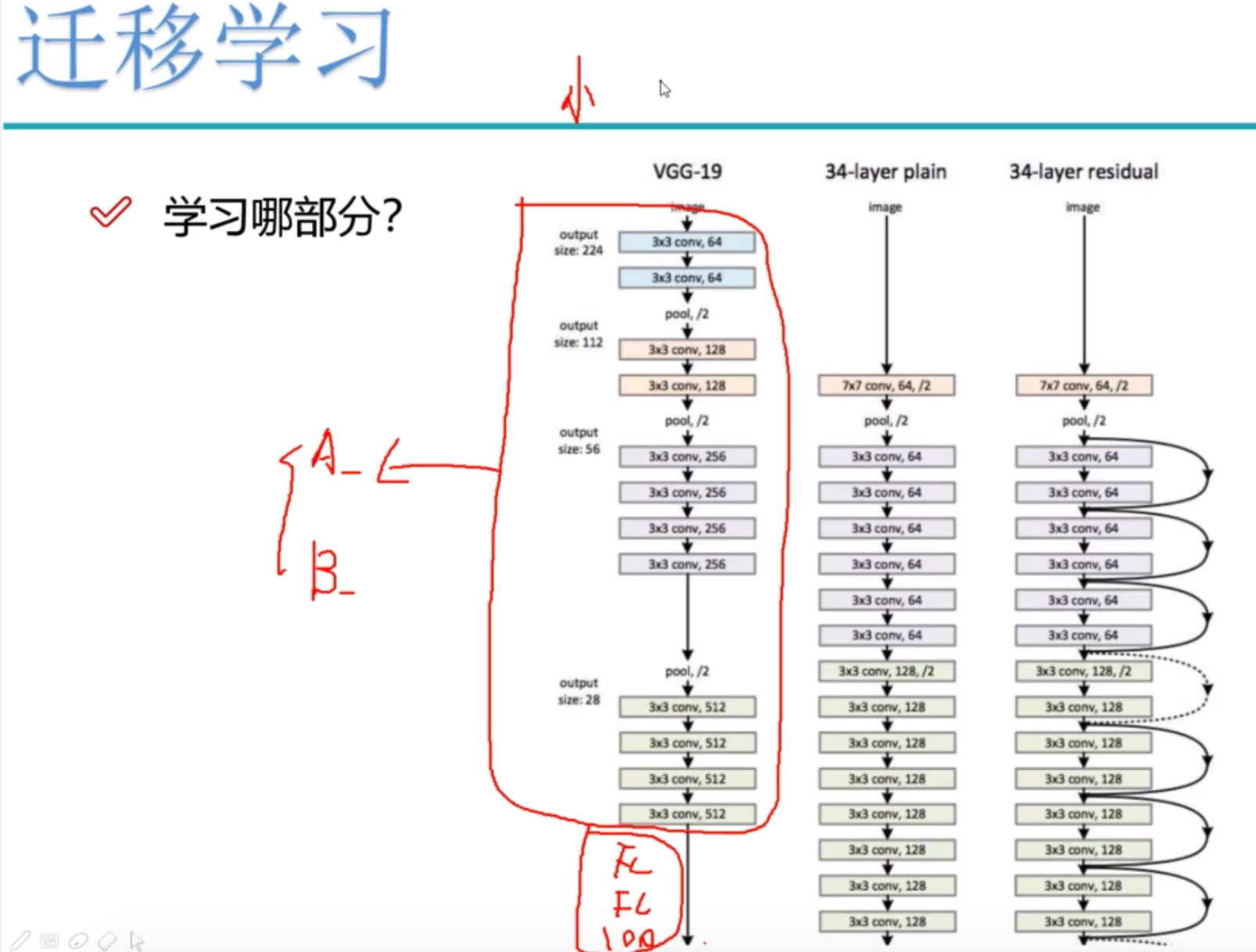
What to learn? There are usually two strategies: A then trains, B freezes the model layer and only changes the full connection layer.
2.1 Whether to train with GPU
# Whether to train with GPU
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
2.2 Use trained renet
model_ft = models.resnet152()
Because my mac has no cuda, no GPU, and 224x224x3 pictures are entered, the model: resnet152 is not estimated to work. (
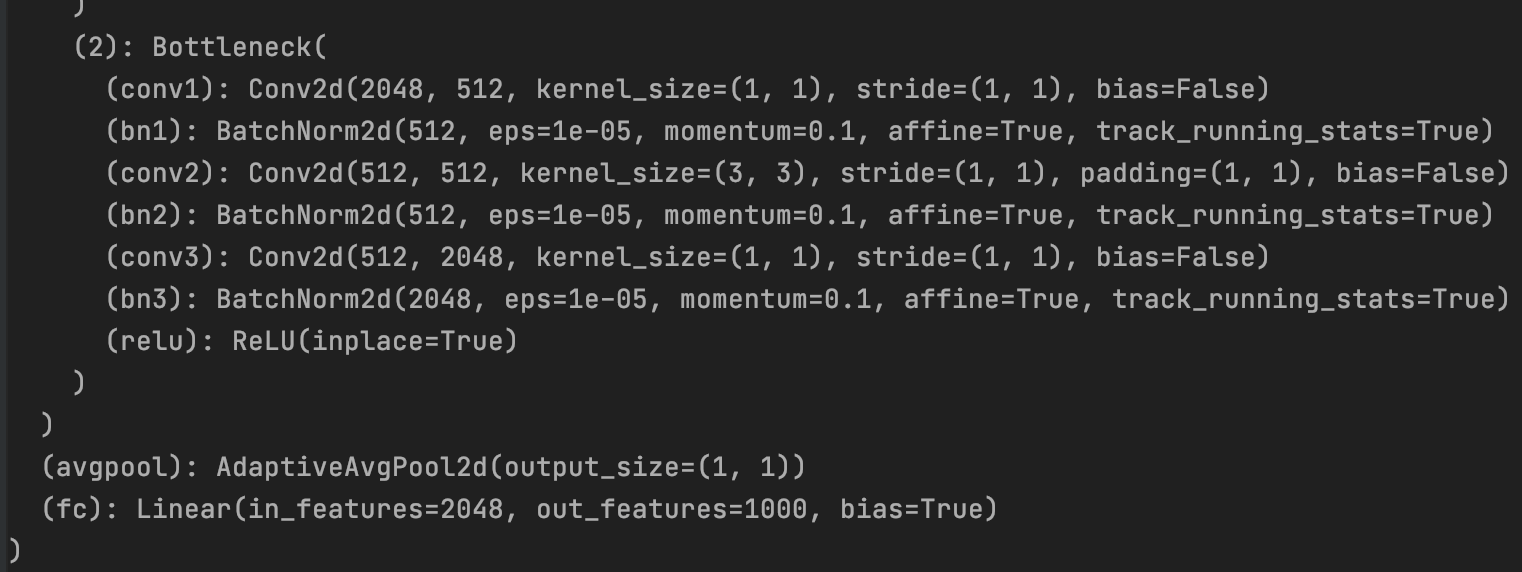
Full Connection Layer out_feature=1000, to modify to its own output 102
2.3 Example of pytorch website, defining image classification model
Here's just a list of resnet. vgg, other not pasted
model_name = 'resnet' # More options ['resnet','alexnet','vgg','squeezenet','densenet','inception']
# Do you want to use trained characteristics?
feature_extract = True
def set_parameter_requires_grad(model, feature_extracting): # Use resnet's trained weight parameters, no more training
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# Choose the appropriate model and the initialization methods differ slightly from model to model.
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet152
"""
model_ft = models.resnet50(pretrained=use_pretrained) # Download resnet model locally
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102), # Full Connection Layer Output Changed to Our Image Category 102
nn.LogSoftmax(dim=1)) # Do one more log operation on the result of softmax
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg16(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)
input_size = 224
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
2.4 Set which layers need training
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True)
#GPU computing
model_ft = model_ft.to(device)
# Model Save
filename='checkpoint.pth'
# Whether to train all layers
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
Output parameters:
Params to learn:
fc.0.weight
fc.0.bias
Print the model, and you can see that the output of the last full connection layer has been changed to 102
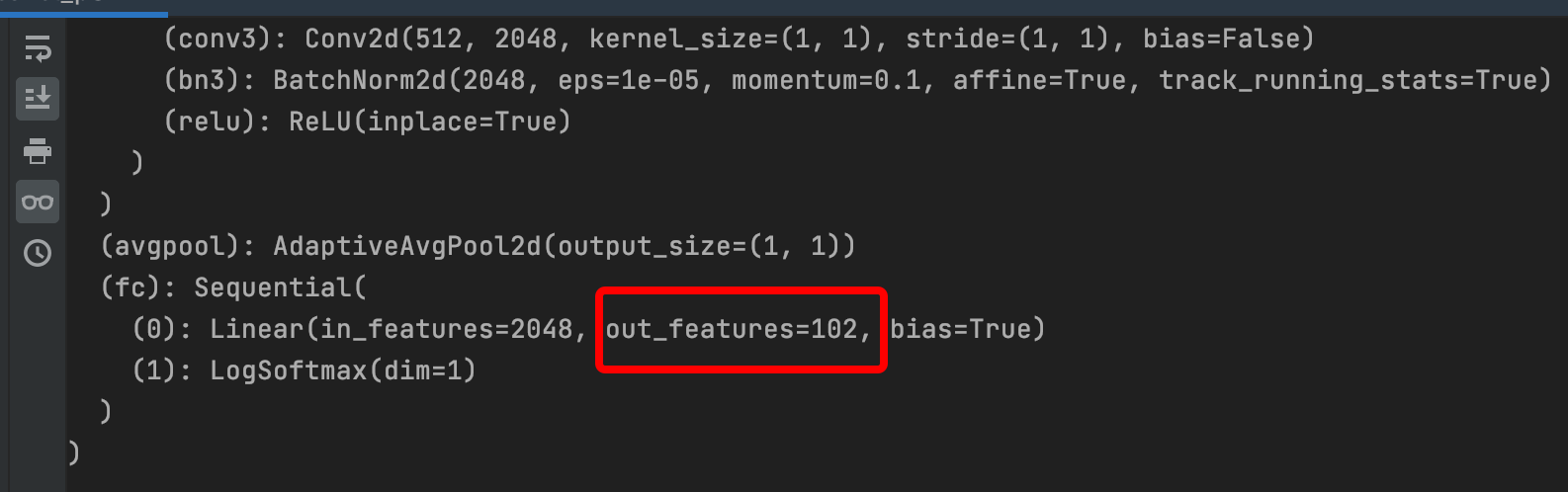
Note: models.resnet152(pretrained=use_pretrained) #Download the resnet model locally
This more than 200M may be slower, take a look at the local path:. cache/torch/hub/checkpoints
2.5 Optimizer Settings
# Optimizer Settings optimizer_ft = optim.Adam(params_to_update, lr=1e-2) scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#Optim. Lr_ Schduler learning rate adjustment strategy, learning rate decays to 1/10 of original every 7 epoch s #The last layer already has LogSoftmax(), so it cannot be nn.CrossEntropyLoss() is calculated, nn.CrossEntropyLoss() is equivalent to logSoftmax () and nn.NLLLoss() Integration criterion = nn.NLLLoss()
Here the teacher explains why the loss function should not use cross-entropy instead of NLLLoss.
2.6 Training Modules
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename): #Is_ Is inception using another network
since = time.time()
best_acc = 0
"""
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
model.class_to_idx = checkpoint['mapping']
"""
model.to(device)
val_acc_history = []
train_acc_history = []
train_losses = []
valid_losses = []
LRs = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Training and Validation
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # train
else:
model.eval() # Verification
running_loss = 0.0
running_corrects = 0
# Get all the data
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# Zero
optimizer.zero_grad()
# Calculate and update gradients only during training
with torch.set_grad_enabled(phase == 'train'):
if is_inception and phase == 'train':
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:#resnet does this
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# Update weights during training
if phase == 'train':
loss.backward()
optimizer.step()
# Calculate loss
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
time_elapsed = time.time() - since
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# Get the best model of the time
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
state = {
'state_dict': model.state_dict(),
'best_acc': best_acc,
'optimizer' : optimizer.state_dict(),
}
torch.save(state, filename)
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
scheduler.step(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRs.append(optimizer.param_groups[0]['lr'])
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# Use the best time after training as the final result of the model
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs
Start training:
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=20, is_inception=(model_name=="inception"))
Then my poor computer started humming. Only once in 19 minutes. At least 20 times, the teacher suggested 50 times. This level of data will be useless without a computer with a GPU that is essentially a low-profile computer. (
Epoch 0/19
----------
Time elapsed 16m 29s
train Loss: 9.5165 Acc: 0.3410
Time elapsed 18m 49s
valid Loss: 10.0126 Acc: 0.5216
Optimizer learning rate : 0.0010000
Find an individual windows book tomorrow and try it again.
Reference resources:
Based on tensorflow_ Flower Classification Process of Flower 102 Adjusted by Slm Model-Knowing