Three Scheduling Strategies
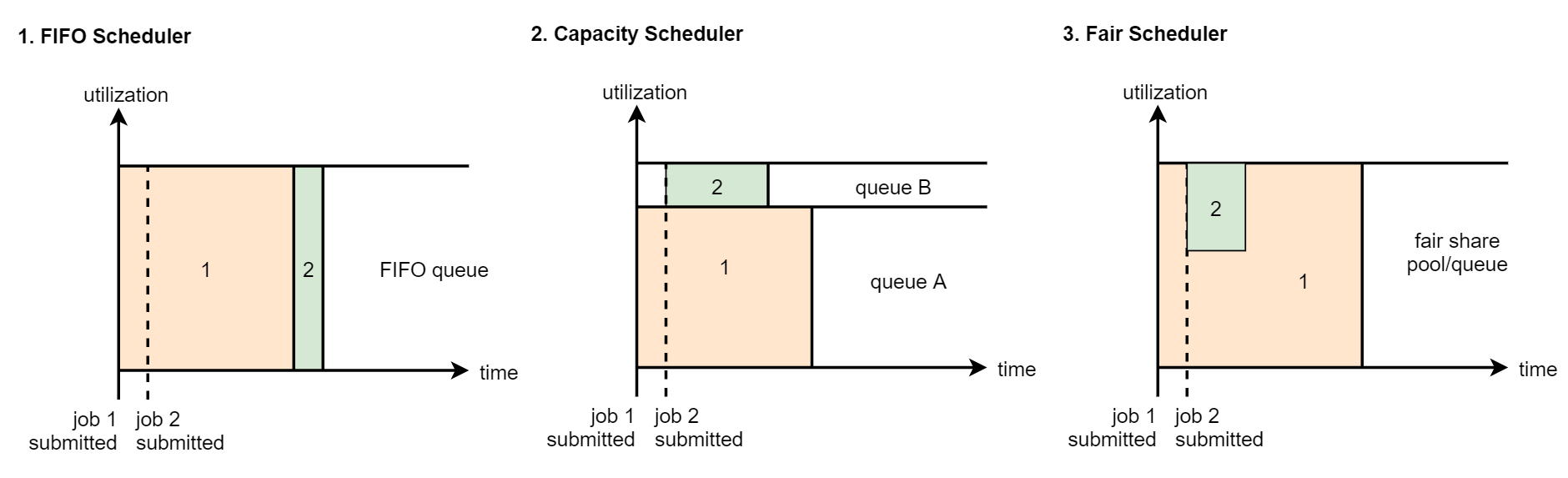
FIFO Scheduler, Capacity Scheduler and Fair Scheduler policies are listed from left to right. These three policies are introduced below
FIFO Scheduler: first in, first out scheduling strategy
Tasks are carried out in turn. Resources can only be released after the execution of previous tasks. This is unreasonable sometimes, because some tasks have high priority. We hope that tasks can be executed immediately after they are submitted. This cannot be achieved.
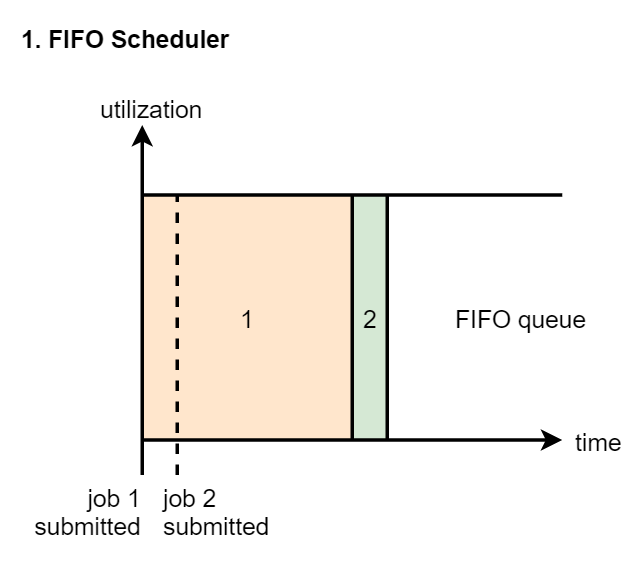
Capacity Scheduler is a multi queue version of FIFO scheduler. We first divide the whole resource in the cluster into multiple parts. We can artificially define usage scenarios for these resources. For example, queue A in the figure runs ordinary tasks and queue B runs tasks with higher priority. The resources of the two queues are opposite to each other.
[note] the queue is still in accordance with the first in first out rule
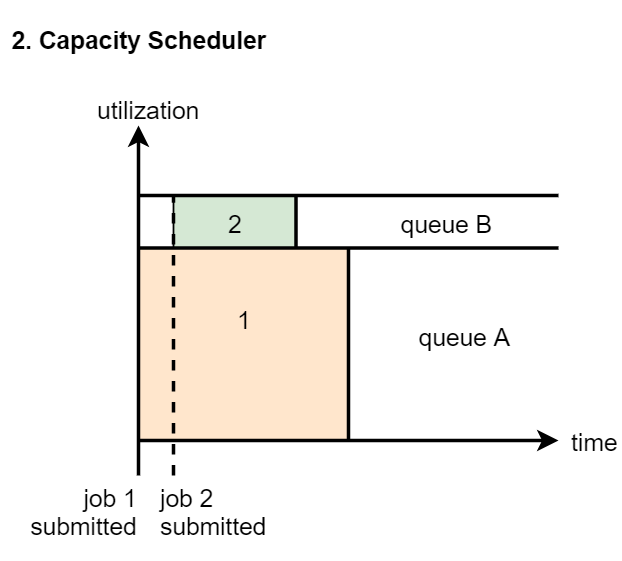
FairScheduler: multi queue, multi-user shared resources. Each queue can be configured with certain resources. The tasks in each queue share all the resources in the queue. There is no need to queue for resources. Suppose we submit a task 1 to a queue. At first, task 1 will occupy the resources of the whole queue, but when you submit task 2, task 1 will release some of its resources for task 2
In practice, we usually use the CapacityScheduler. Starting from Hadoop 2, CapacityScheduler is the default scheduler in the cluster
Configuration and use of YARN multi resource queue
Requirements: it is hoped to add two queues, one is online queue (running real-time tasks) and the other is offline queue (running offline tasks)
Then submit a MapReduce task to the offline queue.
First step
Modify the capacity scheduler in the etc/hadoop directory of the cluster XML configuration file. Modify and add the following parameters. For existing parameters, modify the value in value. For parameters that do not exist, add them directly. The default here needs to be reserved. Add online and offline. The resource ratio of these three queues is 7:1:2. The specific ratio needs to be determined according to the actual business needs. Depending on the types of tasks you have, the resource ratio in the corresponding queue should be increased.
[root@bigdata01 hadoop]# vi capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,online,offline</value>
<description>Queue list,Multiple queues are separated by commas</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>default Queue 70%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.capacity</name>
<value>10</value>
<description>online Queue 10%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.capacity</name>
<value>20</value>
<description>offline Queue 20%</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>70</value>
<description>Default The maximum number of resources available to the queue.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.online.maximum-capacity</name>
<value>10</value>
<description>online The maximum number of resources available to the queue.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.offline.maximum-capacity</name>
<value>20</value>
<description>offline The maximum number of resources available to the queue.</description>
</property>
Synchronous cluster node
[root@bigdata01 hadoop]# scp -rq capacity-scheduler.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/ [root@bigdata01 hadoop]# scp -rq capacity-scheduler.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
Restart cluster
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh [root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Step 2
Add a line of code to the job
//Parse the parameters passed after - D in the command line and add them to conf String[] remainingArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
implement
[root@bigdata01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.bigdata.mr.WordCountJobQueue -Dmapreduce.job.queuename=offline /test/hello.txt /outqueue
Resource queue configuration Java code
/**
* Specify queue name
*
* Created by xuwei
*/
public class WordCountJobQueue {
/**
* Map stage
*/
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* You need to implement the map function
* This map function can receive < K1, V1 > and generate < K2, V2 >
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//Output the value of k1,v1
//k1 represents the beginning offset of each row of data, and v1 represents the content of each row
//Cut each row of data and cut out the words
String[] words = v1.toString().split(" ");
//Iterative cut word data
for (String word : words) {
//Encapsulate the iterated words in the form of < K2, V2 >
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//Write out < K2, V2 >
context.write(k2,v2);
}
}
}
/**
* Reduce stage
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* For < K2, {V2...} > The data is accumulated and summed, and finally the data is converted into K3 and v3
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
//Create a sum variable to save the sum of v2s
long sum = 0L;
//Accumulate and sum the data in v2s
for(LongWritable v2: v2s){
//Output the value of k2,v2
sum += v2.get();
}
//Assembly k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//Value of output k3,v3
// Write the results out
context.write(k3,v3);
}
}
/**
* Assembly Job=Map+Reduce
*/
public static void main(String[] args) {
try{
//Specify the configuration parameters required by the Job
Configuration conf = new Configuration();
//Parse the parameters passed after - D in the command line and add them to conf
String[] remainingArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//Create a Job
Job job = Job.getInstance(conf);
//Note that this line must be set, otherwise the WordCountJob class cannot be found when executing in the cluster
job.setJarByClass(WordCountJobQueue.class);
//Specify the input path (either a file or a directory)
FileInputFormat.setInputPaths(job,new Path(remainingArgs[0]));
//Specify the output path (only one directory that does not exist can be specified)
FileOutputFormat.setOutputPath(job,new Path(remainingArgs[1]));
//Specifies the code associated with the map
job.setMapperClass(MyMapper.class);
//Specifies the type of k2
job.setMapOutputKeyClass(Text.class);
//Specifies the type of v2
job.setMapOutputValueClass(LongWritable.class);
//Specify the code related to reduce
job.setReducerClass(MyReducer.class);
//Specifies the type of k3
job.setOutputKeyClass(Text.class);
//Specifies the type of v3
job.setOutputValueClass(LongWritable.class);
//Submit job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
}
}
reference
https://www.imooc.com/wiki/BigData: Muke.com big data Development Engineer System Course