Introduction: Although visitor mode is not as well known as single case mode in design mode, it is also one of the few design modes that everyone can name. However, due to the complexity of visitor mode, people rarely use it in application systems. After the exploration of this paper, we will have a new understanding and find its more flexible and extensive use.

Author Hang Heng
Source: Ali technical official account
Although visitor mode is not as well known as singleton mode in design mode, it is also one of the few design modes that everyone can name (the other may be "observer mode" and "factory mode"). However, due to the complexity of visitor mode, people rarely use it in application systems. After the exploration of this paper, we will have a new understanding and find its more flexible and extensive use.
Different from the articles that generally introduce design patterns, this paper will not stick to the rigid code template, but directly start from the practice of open source projects and application systems, compare other similar design patterns, and finally explain its essence in the programming paradigm.
A visitor pattern in calculate
Open source class libraries often use visitor style APIs to shield internal complexity. Learning from these APIs can give us an intuitive feeling first.
Calculate is a database basic class library written in Java language, which is used by many well-known open source projects such as Hive and Spark. The SQL parsing module provides the API of visitor mode. We can use its API to quickly obtain the information we need in SQL. Take obtaining all functions used in SQL as an example:
import org.apache.calcite.sql.SqlCall;
import org.apache.calcite.sql.SqlFunction;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.parser.SqlParseException;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.sql.util.SqlBasicVisitor;
import java.util.ArrayList;
import java.util.List;
public class CalciteTest {
public static void main(String[] args) throws SqlParseException {
String sql = "select concat('test-', upper(name)) from test limit 3";
SqlParser parser = SqlParser.create(sql);
SqlNode stmt = parser.parseStmt();
FunctionExtractor functionExtractor = new FunctionExtractor();
stmt.accept(functionExtractor);
// [CONCAT, UPPER]
System.out.println(functionExtractor.getFunctions());
}
private static class FunctionExtractor extends SqlBasicVisitor< Void> {
private final List< String> functions = new ArrayList<>();
@Override
public Void visit(SqlCall call) {
if (call.getOperator() instanceof SqlFunction) {
functions.add(call.getOperator().getName());
}
return super.visit(call);
}
public List< String> getFunctions() {
return functions;
}
}
}In the code, FunctionExtractor is a subclass of SqlBasicVisitor, and its visit(SqlCall) method is rewritten to obtain the name of the function and collect it in functions.
In addition to visit(SqlCall), you can also realize more complex analysis through visit(SqlLiteral) (constant), visit(SqlIdentifier) (table name / column name), etc.
Some people wonder why SqlParser does not directly provide methods such as getFunctions to directly obtain all functions in SQL? In the above example, getFunctions may be more convenient, but as a very complex structure, SQL getFunctions is not flexible enough for more complex analysis scenarios, and its performance is worse. If necessary, you can simply implement a function extractor as described above to meet the requirements.
Second, implement visitor mode
We try to implement a simplified version of SqlVisitor.
First define a simplified SQL structure.
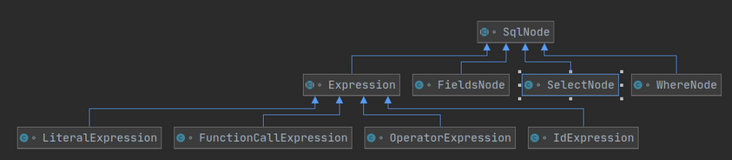
Select upper (name) from test where age > 20; Disassemble to the upper level of this structure, as shown in the figure:
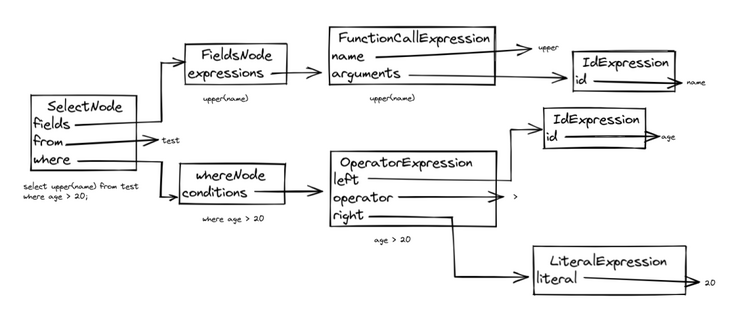
We directly construct the above structure in Java code:
SqlNode sql = new SelectNode(
new FieldsNode(Arrays.asList(
new FunctionCallExpression("upper", Arrays.asList(
new IdExpression("name")
))
)),
Arrays.asList("test"),
new WhereNode(Arrays.asList(new OperatorExpression(
new IdExpression("age"),
">",
new LiteralExpression("20")
)))
);This class has the same method, accept:
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}Here, it will be distributed to different visit methods of SqlVisitor through polymorphism:
abstract class SqlVisitor< R> {
abstract R visit(SelectNode selectNode);
abstract R visit(FieldsNode fieldsNode);
abstract R visit(WhereNode whereNode);
abstract R visit(IdExpression idExpression);
abstract R visit(FunctionCallExpression functionCallExpression);
abstract R visit(OperatorExpression operatorExpression);
abstract R visit(LiteralExpression literalExpression);
}Classes related to SQL structure are as follows:
abstract class SqlNode {
// Method used to receive visitors
public abstract < R> R accept(SqlVisitor< R> sqlVisitor);
}
class SelectNode extends SqlNode {
private final FieldsNode fields;
private final List< String> from;
private final WhereNode where;
SelectNode(FieldsNode fields, List< String> from, WhereNode where) {
this.fields = fields;
this.from = from;
this.where = where;
}
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}
//... get method omitted
}
class FieldsNode extends SqlNode {
private final List< Expression> fields;
FieldsNode(List<Expression> fields) {
this.fields = fields;
}
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}
}
class WhereNode extends SqlNode {
private final List< Expression> conditions;
WhereNode(List< Expression> conditions) {
this.conditions = conditions;
}
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}
}
abstract class Expression extends SqlNode {
}
class IdExpression extends Expression {
private final String id;
protected IdExpression(String id) {
this.id = id;
}
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}
}
class FunctionCallExpression extends Expression {
private final String name;
private final List< Expression> arguments;
FunctionCallExpression(String name, List< Expression> arguments) {
this.name = name;
this.arguments = arguments;
}
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}
}
class LiteralExpression extends Expression {
private final String literal;
LiteralExpression(String literal) {
this.literal = literal;
}
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}
}
class OperatorExpression extends Expression {
private final Expression left;
private final String operator;
private final Expression right;
OperatorExpression(Expression left, String operator, Expression right) {
this.left = left;
this.operator = operator;
this.right = right;
}
@Override
public < R> R accept(SqlVisitor< R> sqlVisitor) {
return sqlVisitor.visit(this);
}
}Some readers may notice that the code of the accept method of each class is the same, so why not write it directly in the parent SqlNode? If you try, you will find that it cannot pass the compilation at all, because our SqlVisitor does not provide visit(SqlNode) at all. Even if visit(SqlNode) is added and the compilation is passed, the running result of the program does not meet the expectation, because at this time, all visit calls will point to visit(SqlNode), and other overloaded methods will be in vain.
The reason for this phenomenon is that different visit methods only have different parameters, which is called "overload", while Java's "overload" is also called "compile time polymorphism". It only determines which method to call according to the type of this in visit(this) at compile time, and its type at compile time is SqlNode, although it may be different subclasses at run time.
Therefore, we may often hear that it is easier to write visitor patterns in dynamic language, especially the functional programming language that supports pattern matching (which is well supported in Java 18). Later, we will go back and re implement the contents of the next section with pattern matching to see if it is much simpler.
Next, as before, we use SqlVisitor to try to parse all function calls in SQL.
First implement a SqlVisitor, which calls accept according to the structure of the current node. Finally, assemble the results and add the function name to the collection when encountering FunctionCallExpression:
class FunctionExtractor extends SqlVisitor< List< String>> {
@Override
List< String> visit(SelectNode selectNode) {
List<String> res = new ArrayList<>();
res.addAll(selectNode.getFields().accept(this));
res.addAll(selectNode.getWhere().accept(this));
return res;
}
@Override
List< String> visit(FieldsNode fieldsNode) {
List< String> res = new ArrayList<>();
for (Expression field : fieldsNode.getFields()) {
res.addAll(field.accept(this));
}
return res;
}
@Override
List< String> visit(WhereNode whereNode) {
List< String> res = new ArrayList<>();
for (Expression condition : whereNode.getConditions()) {
res.addAll(condition.accept(this));
}
return res;
}
@Override
List< String> visit(IdExpression idExpression) {
return Collections.emptyList();
}
@Override
List< String> visit(FunctionCallExpression functionCallExpression) {
// Get function name
List< String> res = new ArrayList<>();
res.add(functionCallExpression.getName());
for (Expression argument : functionCallExpression.getArguments()) {
res.addAll(argument.accept(this));
}
return res;
}
@Override
List< String> visit(OperatorExpression operatorExpression) {
List< String> res = new ArrayList<>();
res.addAll(operatorExpression.getLeft().accept(this));
res.addAll(operatorExpression.getRight().accept(this));
return res;
}
@Override
List< String> visit(LiteralExpression literalExpression) {
return Collections.emptyList();
}
}The code in main is as follows:
public static void main(String[] args) {
// sql definition
SqlNode sql = new SelectNode( //select
// concat("test-", upper(name))
new FieldsNode(Arrays.asList(
new FunctionCallExpression("concat", Arrays.asList(
new LiteralExpression("test-"),
new FunctionCallExpression(
"upper",
Arrays.asList(new IdExpression("name"))
)
))
)),
// from test
Arrays.asList("test"),
// where age > 20
new WhereNode(Arrays.asList(new OperatorExpression(
new IdExpression("age"),
">",
new LiteralExpression("20")
)))
);
// Using FunctionExtractor
FunctionExtractor functionExtractor = new FunctionExtractor();
List< String> functions = sql.accept(functionExtractor);
// [concat, upper]
System.out.println(functions);
}The above is the implementation of the standard visitor mode. Intuitively, it is much more troublesome than the SqlBasicVisitor of Calcite before. Let's implement SqlBasicVisitor next.
Visitor mode and observer mode
In the FunctionExtractor implemented with calculate, visit(SqlCall) implemented by us will be called every time the function is parsed by calculate. It seems more appropriate to call it listen(SqlCall) than visit. This also shows the close relationship between visitor mode and observer mode.
In our own function extractor, most of the code is traversing various structures in a certain order. This is because the visitor mode gives the user enough flexibility to let the implementer decide the traversal order or prune the parts that do not need to be traversed.
However, our requirement to "parse all functions in SQL" does not care about the traversal order. Just notify us when passing through the "function". For this simple requirement, the visitor mode is a little over designed, and the observer mode will be more appropriate.
Most open source projects using visitor mode will provide a default implementation for "standard visitors", such as SqlBasicVisitor of calculate. The default implementation will traverse the SQL structure in the default order, and the implementer only needs to rewrite the part it cares about. This is equivalent to implementing observer mode on the basis of visitor mode, That is, the flexibility of visitor mode is not lost, and the convenience of observer mode is also obtained.
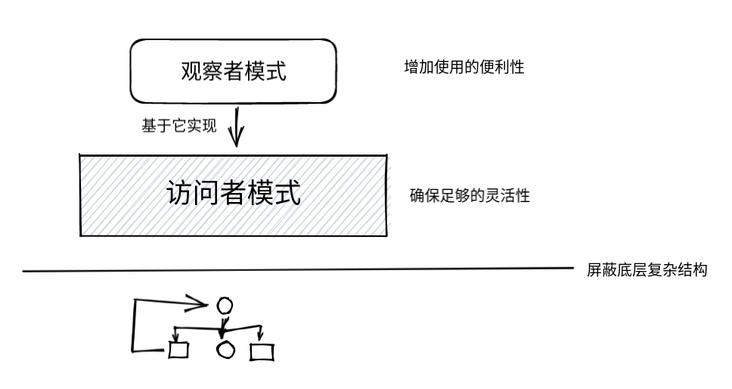
Let's add a SqlBasicVisitor to our implementation:
class SqlBasicVisitor< R> extends SqlVisitor< R> {
@Override
R visit(SelectNode selectNode) {
selectNode.getFields().accept(this);
selectNode.getWhere().accept(this);
return null;
}
@Override
R visit(FieldsNode fieldsNode) {
for (Expression field : fieldsNode.getFields()) {
field.accept(this);
}
return null;
}
@Override
R visit(WhereNode whereNode) {
for (Expression condition : whereNode.getConditions()) {
condition.accept(this);
}
return null;
}
@Override
R visit(IdExpression idExpression) {
return null;
}
@Override
R visit(FunctionCallExpression functionCallExpression) {
for (Expression argument : functionCallExpression.getArguments()) {
argument.accept(this);
}
return null;
}
@Override
R visit(OperatorExpression operatorExpression) {
operatorExpression.getLeft().accept(this);
operatorExpression.getRight().accept(this);
return null;
}
@Override
R visit(LiteralExpression literalExpression) {
return null;
}
}SqlBasicVisitor provides a default access order for each structure. Using this class, we implement the second version of FunctionExtractor:
class FunctionExtractor2 extends SqlBasicVisitor< Void> {
private final List< String> functions = new ArrayList<>();
@Override
Void visit(FunctionCallExpression functionCallExpression) {
functions.add(functionCallExpression.getName());
return super.visit(functionCallExpression);
}
public List< String> getFunctions() {
return functions;
}
}Its use is as follows:
class Main {
public static void main(String[] args) {
SqlNode sql = new SelectNode(
new FieldsNode(Arrays.asList(
new FunctionCallExpression("concat", Arrays.asList(
new LiteralExpression("test-"),
new FunctionCallExpression(
"upper",
Arrays.asList(new IdExpression("name"))
)
))
)),
Arrays.asList("test"),
new WhereNode(Arrays.asList(new OperatorExpression(
new IdExpression("age"),
">",
new LiteralExpression("20")
)))
);
FunctionExtractor2 functionExtractor = new FunctionExtractor2();
sql.accept(functionExtractor);
System.out.println(functionExtractor.getFunctions());
}
}IV. visitor model and responsibility chain model
ASM is also a class library providing visitor mode API, which is used to parse and generate Java class files. It can be found in all well-known Java open source projects. The Lambda expression feature of Java 8 is even realized through it. If you can only parse and generate Java class files, ASM may not be so popular. More importantly, its excellent abstraction abstracts common functions into small visitor tool classes, making complex bytecode operations as simple as building blocks.
Suppose you need to modify the class file as follows:
- Delete name attribute
- Add @ NonNull annotation to all attributes
However, from the perspective of reuse and modularization, we want to separate the two steps into independent functional modules instead of writing the code together. In ASM, we can implement two small visitors respectively, and then string them together to become visitors who can meet our needs.
To delete an accessor with the name attribute:
class DeleteFieldVisitor extends ClassVisitor {
// The deleted attribute name is "name" for our requirements
private final String deleteFieldName;
public DeleteFieldVisitor(ClassVisitor classVisitor, String deleteFieldName) {
super(Opcodes.ASM9, classVisitor);
this.deleteFieldName = deleteFieldName;
}
@Override
public FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {
if (name.equals(deleteFieldName)) {
// If this attribute is not passed to the downstream, it will be "deleted" for the downstream
return null;
}
// super.visitField will continue to call the visitField method of the downstream Visitor
return super.visitField(access, name, descriptor, signature, value);
}
}Accessors who annotate all properties with @ NonNull:
class AddAnnotationVisitor extends ClassVisitor {
public AddAnnotationVisitor(ClassVisitor classVisitor) {
super(Opcodes.ASM9, classVisitor);
}
@Override
public FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {
FieldVisitor fieldVisitor = super.visitField(access, name, descriptor, signature, value);
// Pass an additional @ NonNull annotation to the downstream Visitor
fieldVisitor.visitAnnotation("javax/annotation/Nonnull", false);
return fieldVisitor;
}
}In main, we string them together:
public class AsmTest {
public static void main(String[] args) throws URISyntaxException, IOException {
Path clsPath = Paths.get(AsmTest.class.getResource("/visitordp/User.class").toURI());
byte[] clsBytes = Files.readAllBytes(clsPath);
// Series Visitor
// finalVisitor = DeleteFieldVisitor -> AddAnnotationVisitor -> ClassWriter
// ClassWriter itself is a subclass of ClassVisitor
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES);
ClassVisitor finalVisitor = new DeleteFieldVisitor(new AddAnnotationVisitor(cw),
"name");
// ClassReader is the object being accessed
ClassReader cr = new ClassReader(clsBytes);
cr.accept(finalVisitor, ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES);
byte[] bytes = cw.toByteArray();
Files.write(clsPath, bytes);
}
}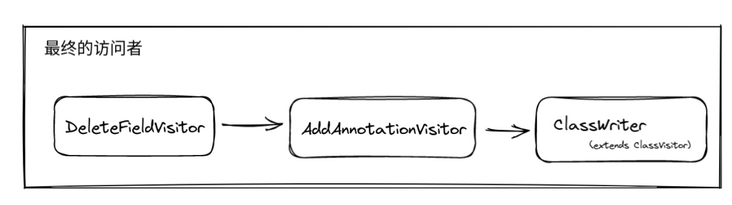
Through the combination of visitor mode and responsibility chain mode, we no longer need to write all logic in one visitor. We can split multiple general visitors and realize more diverse needs by combining them.
V. visitor mode and callback mode
"Callback" can be regarded as "design pattern of design pattern". It has its ideas in a large number of design patterns, such as "Observer" in observer mode "," command "in command mode and" state "in state mode. In essence, it can be regarded as a callback function.
The "visitor" in the visitor mode is obviously also a callback. The biggest difference from other callback modes is that the "visitor mode" is a callback with "navigation". We give the implementer the "navigation" of the next callback through the incoming object structure, and the implementer determines the order of the next callback according to the "navigation".
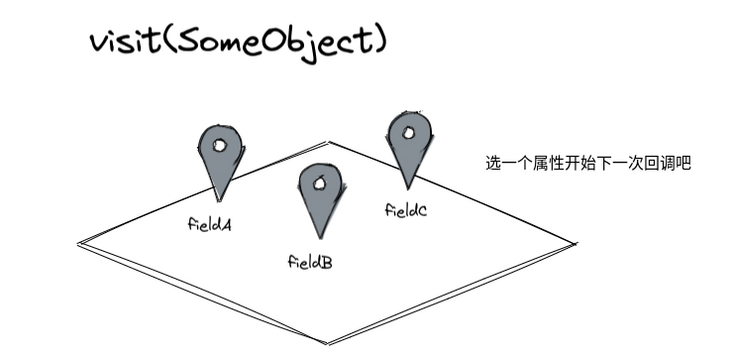
If I want to access fieldA first, then fieldB, and finally fieldC, the implementation corresponding to the visitor is:
visit(SomeObject someObject) {
someObject.fieldA.accept(this);
someObject.fieldB.accept(this);
someObject.fieldC.accept(this);
}In practice, the application is HATEOAS (Hypermedia as the Engine of Application State). Besides returning the data requested by the user, the HTTP interface of HATEOAS style will also contain the URL that the user should visit in the next step. If the API of the whole application is compared to a home, if the user requests the data of the living room, the interface will not only return the data of the living room, It also returns the URLs of "kitchen", "bedroom" and "bathroom" connected to the living room:
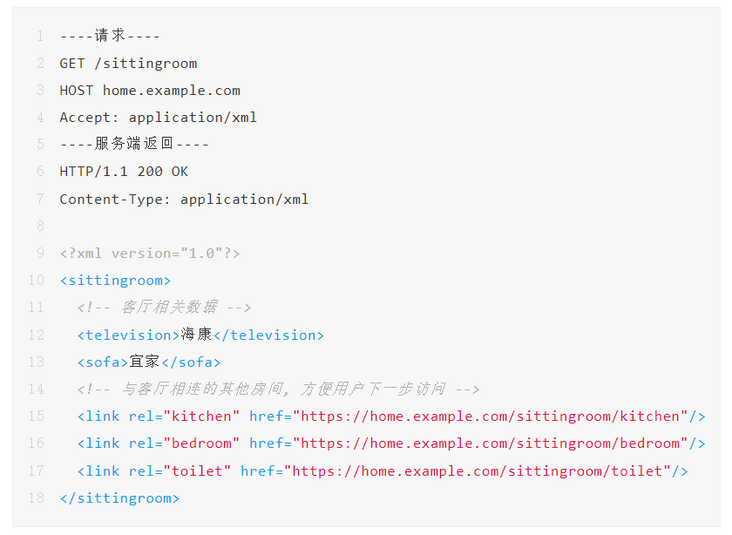
The advantage of this is that the URLs of resources can be upgraded and changed seamlessly (because these URLs are returned by the server). Moreover, developers can explore and learn the use of API by following the navigation without documents, and solve the problem of chaotic API organization. For a more practical example of HATEOAS, see How to GET a Cup of Coffee[1].
Vi. practical application
The previous examples may be more inclined to the application of open source basic class library. How should it be applied in a wider range of application systems?
1 complex nested structure access
In order to meet the bizarre customization needs of different enterprises, toB applications now provide more and more complex configuration functions. The configuration items are no longer simple orthogonal and independent relationships, but nested and recursive with each other, which is the occasion for the visitor mode to play.
Nailing approval process configuration is a very complex structure:
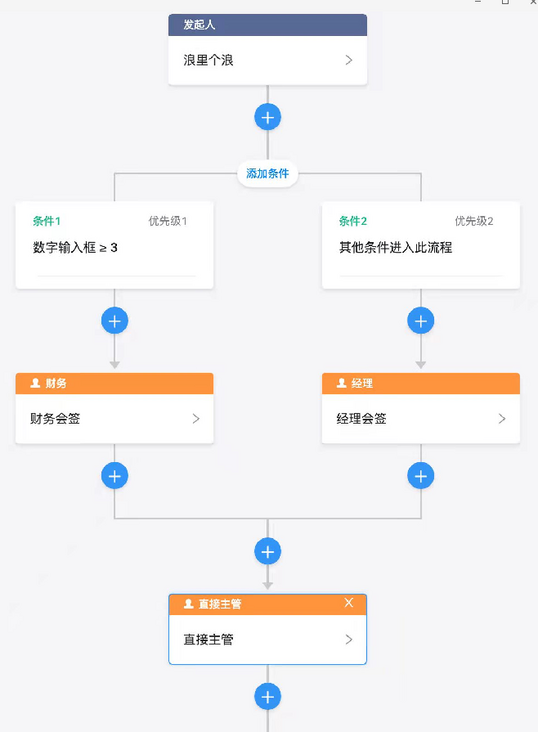
The simplified approval process model is as follows:
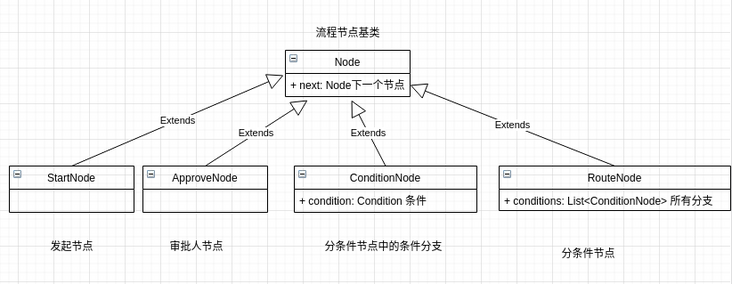
The corresponding relationship between model and process configuration is shown in the figure below:
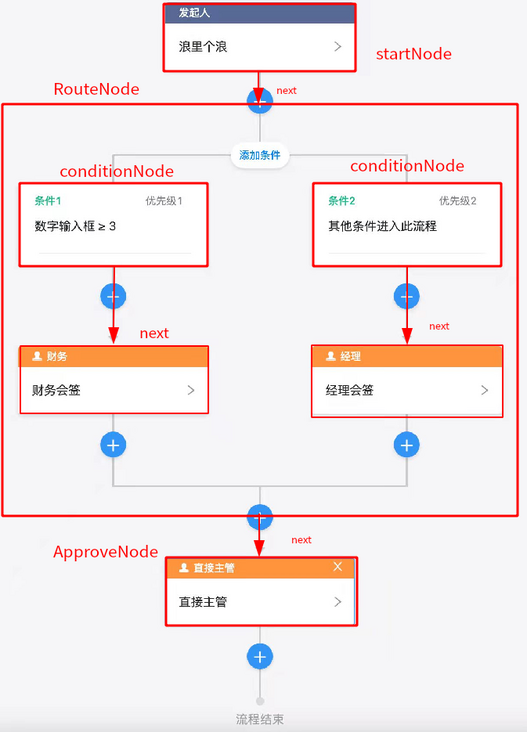
RouteNode connects the next node through next like an ordinary node, and each condition contained in it is a complete process configuration (recursive definition). It can be seen that the approval node model is a complex nested structure.
In addition to the complex overall structure, the configuration of each node is also quite complex:
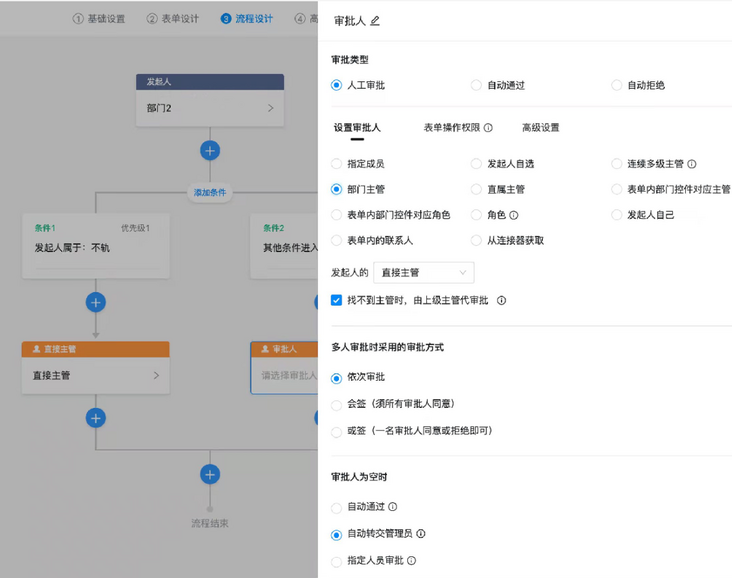
In the face of such a complex configuration, it is best to mask the complexity of the configuration of the application layer through the configuration analysis of the two-party package (hereinafter referred to as SDK). If the SDK only returns a graph structure to the application layer, the application layer will have to perceive the association between nodes and need to write an error prone traversal algorithm every time. At this time, the visitor mode has become our best choice.
The implementation routine of visitor mode is the same as before. I won't say more. Let's take an example of application layer:
Simulation: the user can see the execution branch of the process without actually running the process, which is convenient for debugging
class ProcessSimulator implements ProcessConfigVisitor {
private List< String> traces = new ArrayList<>();
@Override
public void visit(StartNode startNode) {
if (startNode.next != null) {
startNode.next.accept(this);
}
}
@Override
public void visit(RouteNode routeNode) {
// Calculate the branches that meet the conditions
for (CondtionNode conditionNode : routeNode.conditions) {
if (evalCondition(conditionNode.condition)) {
conditionNode.accept(this);
}
}
if (routeNode.next != null) {
routeNode.next.accept(this);
}
}
@Override
public void visit(ConditionNode conditionNode) {
if (conditionNode.next != null) {
conditionNode.next.accept(this);
}
}
@Override
public void visit(ApproveNode approveNode) {
// Record the approval nodes accessed in the simulation
traces.add(approveNode.id);
if (approveNode.next != null) {
approveNode.next.accept(this);
}
}
}2 SDK isolate external calls
In order to ensure the purity of the SDK, the external interface will not be called in the SDK, but we have to do so in order to realize some requirements. At this time, we can put the external call in the implementation of the application layer visitor, and then pass it into the SDK to execute the relevant logic.
In the process simulation mentioned above, conditional computation often includes external interface calls, such as calling a user specified interface through the connector to decide the process branch. In order to ensure the purity of the process configuration to parse SDK, it is impossible to invoke in the SDK package, so it is called in the visitor.
VII. Implement visitor mode with Java 18
Back to the original proposition, use the visitor pattern to obtain all function calls in SQL. As mentioned earlier, the common pattern matching in functional programming language can be realized more conveniently, and it has been well supported in the latest Java 18.
Starting from Java 14, Java supports a new Record data type. Examples are as follows:
// sealed indicates the capsule type, that is, Expression is only allowed to be Num and Add in the current file
sealed interface Expression {
// Record keyword instead of class is used to define the record data type
record Num(int value) implements Expression {}
record Add(int left, int right) implements Expression {}
}Once TestRecord is instantiated, the fields are immutable, and its equals and hashCode methods will be rewritten automatically. As long as the internal fields are equal, they are equal:
public static void main(String[] args) {
Num n1 = new Num(2);
// n1.value = 10; This line of code will lead to compilation
Num n2 = new Num(2);
// true
System.out.println(n1.equals(n2));
}More conveniently, the latest pattern matching function in Java 18 can be used to disassemble the attributes:
public int eval(Expression e) {
return switch (e) {
case Num(int value) -> value;
case Add(int left, int right) -> left + right;
};
}We first redefine our SQL structure using the Record type:
sealed interface SqlNode {
record SelectNode(FieldsNode fields, List< String> from, WhereNode where) implements SqlNode {}
record FieldsNode(List< Expression> fields) implements SqlNode {}
record WhereNode(List< Expression> conditions) implements SqlNode {}
sealed interface Expression extends SqlNode {
record IdExpression(String id) implements Expression {}
record FunctionCallExpression(String name, List< Expression> arguments) implements Expression {}
record LiteralExpression(String literal) implements Expression {}
record OperatorExpression(Expression left, String operator, Expression right) implements Expression {}
}
}Then, using pattern matching, one method can realize the previous access and obtain all function calls:
public List< String> extractFunctions(SqlNode sqlNode) {
return switch (sqlNode) {
case SelectNode(FieldsNode fields, List< String> from, WhereNode where) -> {
List< String> res = new ArrayList<>();
res.addAll(extractFunctions(fields));
res.addAll(extractFunctions(where));
return res;
}
case FieldsNode(List< Expression> fields) -> {
List< String> res = new ArrayList<>();
for (Expression field : fields) {
res.addAll(extractFunctions(field));
}
return res;
}
case WhereNode(List< Expression> conditions) -> {
List< String> res = new ArrayList<>();
for (Expression condition : conditions) {
res.addAll(extractFunctions(condition));
}
return res;
}
case IdExpression(String id) -> Collections.emptyList();
case FunctionCallExpression(String name, List< Expression> arguments) -> {
// Get function name
List< String> res = new ArrayList<>();
res.add(name);
for (Expression argument : arguments) {
res.addAll(extractFunctions(argument));
}
return res;
}
case LiteralExpression(String literal) -> Collections.emptyList();
case OperatorExpression(Expression left, String operator, Expression right) -> {
List< String> res = new ArrayList<>();
res.addAll(extractFunctions(left));
res.addAll(extractFunctions(right));
return res;
}
}
}Comparing the code in the second section, the biggest difference is sqlnode Accept (Visitor) is replaced by a recursive call to extractFunctions. In addition, the behavior originally encapsulated by classes has become a lighter function. We will explore its deeper meaning in the next section.
VIII. Re understanding the visitor model
In GoF's original design pattern, the visitor pattern is described as follows:
Represents an operation that acts on elements in an object structure. It allows you to define new operations on elements without changing their classes.
It can be seen from this sentence that all the functions realized by the visitor mode can be realized by adding new member methods to each object. Using the characteristics of object-oriented polymorphism, the parent structure calls and aggregates the return results of the corresponding methods of the substructure. Take the previous extraction of all SQL functions as an example, this time without visitors, Instead, add an extractFunctions member method to each class:
class SelectNode extends SqlNode {
private final FieldsNode fields;
private final List< String> from;
private final WhereNode where;
SelectNode(FieldsNode fields, List< String> from, WhereNode where) {
this.fields = fields;
this.from = from;
this.where = where;
}
public FieldsNode getFields() {
return fields;
}
public List< String> getFrom() {
return from;
}
public WhereNode getWhere() {
return where;
}
public List< String> extractFunctions() {
List<String> res = new ArrayList<>();
// Continue to call the extractFunctions of the substructure
res.addAll(fields.extractFunctions());
res.addAll(selectNode.extractFunctions());
return res;
}
}Visitor mode essentially abstracts all member methods in a complex class hierarchy into one class:
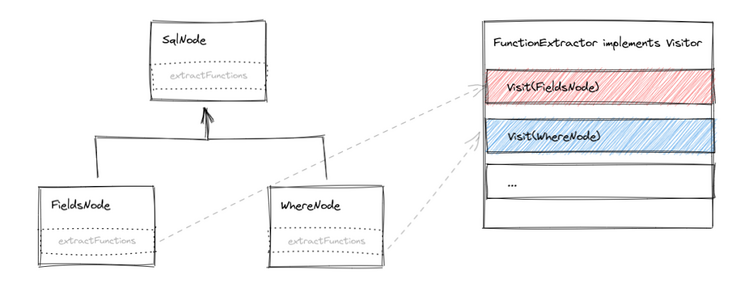
What is the difference between the two writing methods? Although the name Visitor looks like a noun, from the previous examples and discussions, its implementation classes are all abstractions about operations, which can be seen more from the implementation of pattern matching. ASM even arranges and combines visitors as abstractions of small operations. Therefore, the two writing methods also correspond to two world views:
- Object oriented: it is considered that the operation must be bound with the data, that is, it exists as a member method of each class, rather than being extracted separately as a visitor
- Functional programming: separate data and operations, arrange and combine basic operations into more complex operations, and the implementation of a visitor corresponds to an operation
These two methods seem to have little difference when writing. Only when you need to add and modify functions can they show their great difference. Suppose we want to add a new operation to each class now:
This scenario seems to be more convenient to increase visitors. Let's look at the next scenario. Suppose we want to add a new class in the class hierarchy:
These two scenarios correspond to two ways to split the software. One is to split according to data, and the other is to split according to function points. Take each branch venue and function of Alibaba's double 11 as an example: HEMA, hungry and jucost-effective participated in the promotion of double 11 as a branch venue respectively. They all need to provide coupons, orders, payments and other functions.
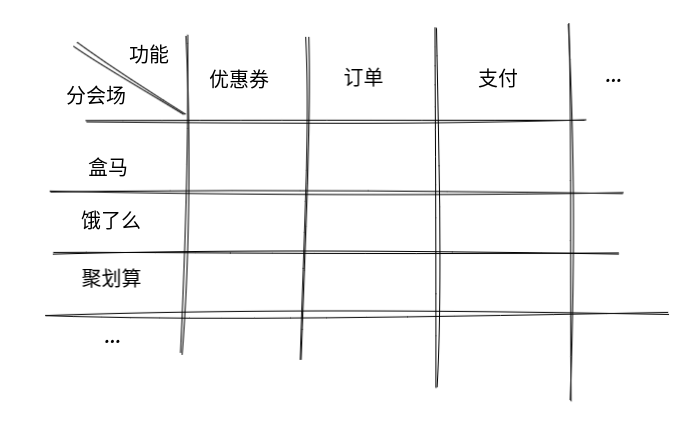
Although in the view of users, HEMA, hungry and jucost-effective are three different applications, the underlying system can be divided in two ways:
Any division method must bear the disadvantages brought by this method. All real applications, whether architecture or coding, are not as extreme as the above examples, but a mixture of the two. For example, HEMA, hungry or cost-effective, can reuse the system divided by function such as coupons while having their own system. It is the same with the project that we decide whether to adopt abstract or abstract coding according to the visitor. More often, we need to mix the two, take some core methods as object members, and use the visitor mode to realize the trivial and messy requirements of the application layer.
Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.