3, RDD action operator
The so-called action operator is actually a method that can trigger Job execution
1,reduce
function signature
def reduce(f: (T, T) => T): T
function description
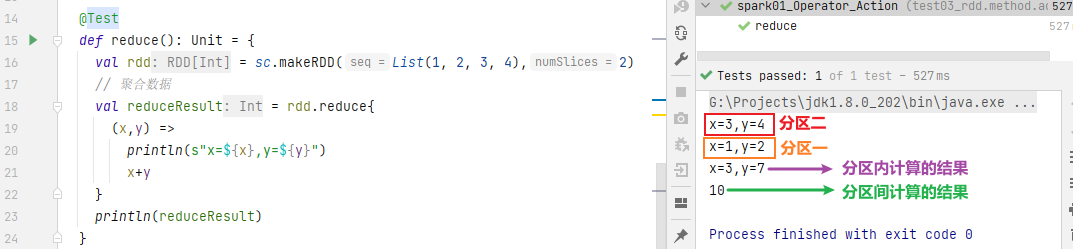
Aggregate all elements in RDD, first aggregate data in partitions, and then aggregate data between partitions
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // Aggregate data val reduceResult: Int = rdd.reduce(_+_) println(reduceResult) 10
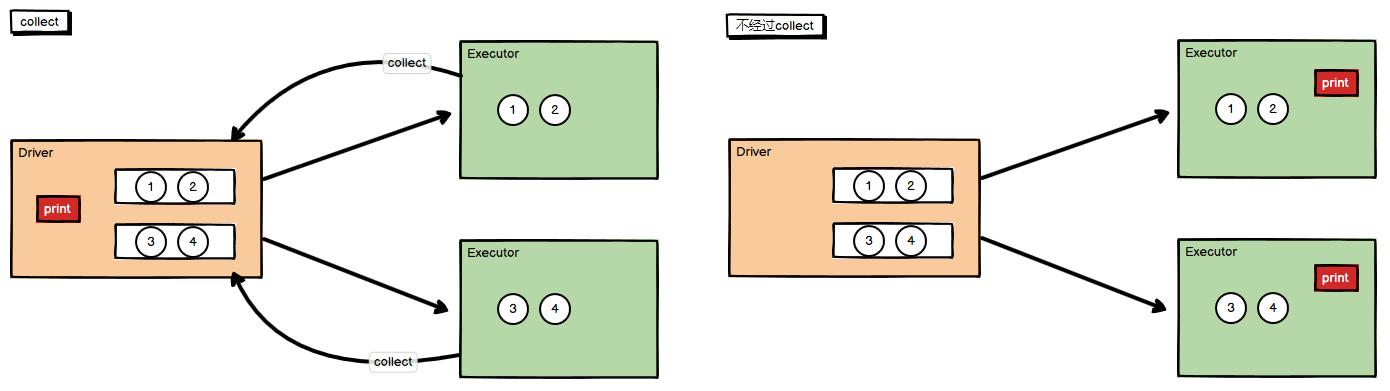
2,collect
function signature
def collect(): Array[T]
function description
In the driver, all elements of the dataset are returned in the form of Array array
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // Collect data to Driver rdd.collect().foreach(println) 1 2 3 4
Underlying source code:
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
// runJob()
def runJob[T, U: ClassTag](rdd: RDD[T], func: Iterator[T] => U): Array[U] = {
runJob(rdd, func, 0 until rdd.partitions.length)
}
// runJob()
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: Iterator[T] => U,
partitions: Seq[Int]): Array[U] = {
val cleanedFunc = clean(func)
runJob(rdd, (ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it), partitions)
}
// runJob()
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int]): Array[U] = {
val results = new Array[U](partitions.size)
runJob[T, U](rdd, func, partitions, (index, res) => results(index) = res)
results
}
// dagScheduler.runJob() starts the job through a directed acyclic graph
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
// submitJob submit job
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
// eventProcessLoop.post(JobSubmitted(...)) Submit job event
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
// new ActiveJob() creates a new job
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
...
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
...
}
3,count
function signature
def count(): Long
function description
Returns the number of elements in the RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // Returns the number of elements in the RDD val countResult: Long = rdd.count() 4
4,first
function signature
def first(): T
function description
Returns the first element in the RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // Returns the number of elements in the RDD val firstResult: Int = rdd.first() println(firstResult) 1
5,take
function signature
d,ef take(num: Int): Array[T]
function description
Returns an array of the first n elements of an RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// Number of RDD elements returned
val takeResult: Array[Int] = rdd.take(2)
println(takeResult.mkString(","))
1,2
6,takeOrdered
function signature
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
function description
Returns an array of the first n elements sorted by the RDD
val rdd: RDD[Int] = sc.makeRDD(List(4, 2, 1, 3))
// Returns the number of elements in the RDD
val result: Array[Int] = rdd.takeOrdered(2)
println(result.mkString(","))
1,2
7,aggregate
function signature
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
function description
The partitioned data is aggregated through the initial value and the data in the partition, and then the data between partitions is aggregated with the initial value
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) // Add all the elements of the RDD to get the result //val result: Int = rdd.aggregate(0)(_ + _, _ + _) val result: Int = rdd.aggregate(10)(_ + _, _ + _) 40
Note: if the result here is calculated according to the aggregateByKey, the result will be 30, but the actual result will be 40. This is because the initial value in the aggregateByKey will only participate in the calculation in the partition once, and the aggregate will also participate in the calculation between partitions after participating in the calculation in the partition.
Similarly, if the number of partitions is set to 8, the result should be:
8,fold
function signature
def fold(zeroValue: T)(op: (T, T) => T): T
function description
Folding operation, simplified version of aggregate operation
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val foldResult: Int = rdd.fold(0)(_+_) 30
9,countByKey & countByValue
function signature
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
}
def countByValue()(implicit ord: Ordering[T] = null): Map[T, Long] = withScope {
map(value => (value, null)).countByKey()
}
function description
Count the number of each key & value
val rdd1= sc.makeRDD(List(1, 2, 3, 4), 2) val rdd2 = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"),(2, "b"), (3, "c"), (3, "c"))) // Count the number of key s of each type val result1 = rdd2.countByKey() // Count the number of each value val result2 = rdd1.countByValue() println(result1) println(result2) Map(1 -> 3, 2 -> 1, 3 -> 2) Map(4 -> 1, 2 -> 1, 1 -> 1, 3 -> 1)
10,save...
function signature
def saveAsTextFile(path: String): Unit def saveAsObjectFile(path: String): Unit def saveAsSequenceFile(path: String,codec: Option[Class[_ <: CompressionCodec]] = None): Unit
function description
Save data to files in different formats
// Save as Text file
rdd.saveAsTextFile("output")
// Serialized objects are saved to a file
rdd.saveAsObjectFile("output1")
// Save as Sequencefile file
rdd.map((_,1)).saveAsSequenceFile("output2")
Note: the saveAsSequenceFile() method requires that the data must be of K-V key value pair type
Back to top
11,foreach
function signature
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
function description
Distributed traversal of each element in RDD and calling the specified function; It is a method of looping through the memory collection on the Driver side
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// Print after collection
rdd.map(num=>num).collect().foreach(println)
println("****************")
// Distributed printing
rdd.foreach(println)
1
2
3
4
****************
3
1
2
4
Note: if the collect operator is used, the data is collected according to the partition first, and then printed out, which is the output in the Driver side memory; The direct use of foreach operator is not to collect data in sequence and then print out. In fact, it is a distributed print out at the Executor end