Today, let's review the data reading mechanism of pytorch
torch.utils.data.DataLoader(); Build an iterative data loader. Each for loop and each iteration obtain a batch from the dataloader_ Size data.
Have you ever wondered how to load these classes, then read the data, and load them in batch? Today, let's study slowly and deeply to learn what is what.

There are several important parameters of DataLoader:
1. Dataset: it belongs to dataset class and determines where and how to read data.
2,num_works: multi process read
3. shuffle: is each epoch out of order
4. batchsize: batch size
5,drop_last: the composition batch is. Should the redundant be eliminated,
Let's understand epoch first
All training samples have been input into the model, which is called an epoch, iteration: a batch of samples are input into the model
Let's understand Batchsize:
The batch size determines how many iteration s an epoch has
Dataset review
torch.utils.data.Dataset(): Dataset abstract class. All custom datasets must inherit from it, and we need to review it__ getitem__ () and__ len__ () these two functions, so what is the first function for? What's the second one for? I understand this process by learning to check the data:
getitem: this function is mainly used to collect and return image and label information. This function has two parameters,
def __getitem__(self, item):
What does item do? This is an index and a heavy parameter. When we read information in this function, we find the information of each picture according to the item parameter. The process can be seen in its parent class
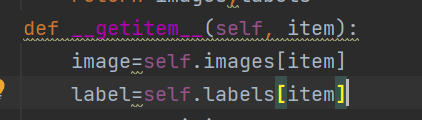
So what information does this rewritten function collect?
Its function is to collect the pictures of our training set or test set and the tag numbers corresponding to the pictures, and it also occurs in this function to convert the picture information into tensor information, which will be returned after conversion
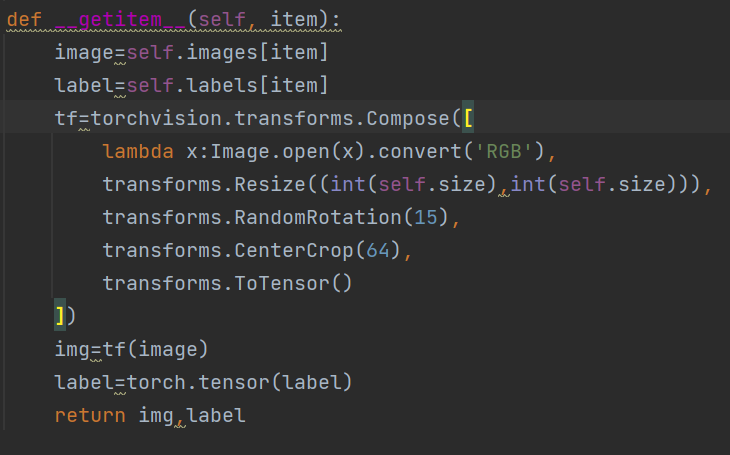
Where did he return the information?
That is to return to the custom data class you created
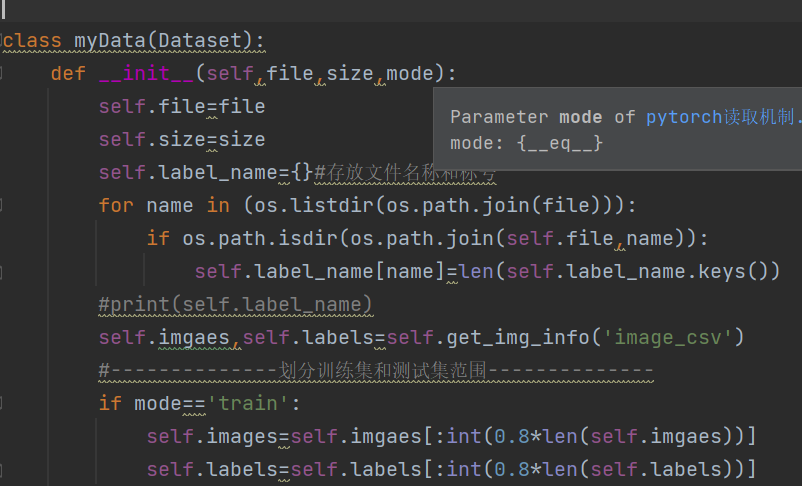
Only in this way can you instantiate the object and package the write data into batch or single.
**len_ () * * returns the length of the dataset. This is a simple return len(self.image)
There is another important point when we customize the dataset
How do we collect pictures?
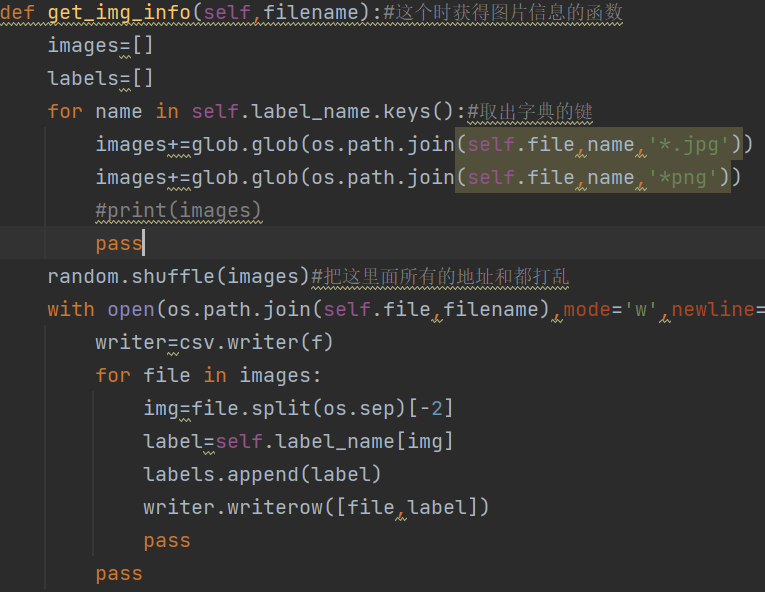
Look at this picture. The long picture means: I want to get the specific location of the picture (I have set it in ___) and the corresponding label of the picture, randomly disrupt the obtained information, put it into two lists, return it, and who will I return it to?
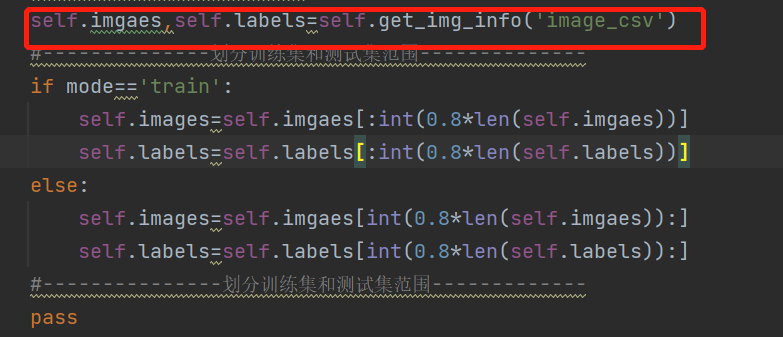
Return to__ init__ There are two custom variables, which are responsible for returning the contents of the data packet to the size of the clip data according to the training test you set. Do you want to think about what to do after editing? Where do you put it?
Remember what we mentioned above__ getitem__(self, item)?
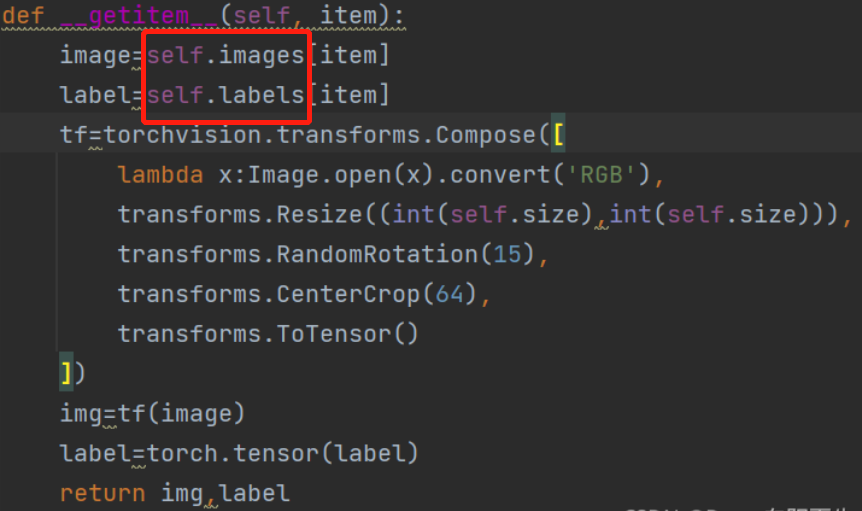
Return to him (circled by the red line), and then continue to execute, Zhang quantization. This is the whole process
Post all the code processes below.
import csv
import glob
import os
import random
import torch
import torchvision
import visdom
from PIL import Image
from torch.utils.data.dataset import Dataset
from torchvision import transforms
from torch.utils.data import DataLoader
class myData(Dataset):
def __init__(self,file,size,mode):
self.file=file
self.size=size
self.label_name={}#Name and label of stored documents
for name in (os.listdir(os.path.join(file))):
if os.path.isdir(os.path.join(self.file,name)):
self.label_name[name]=len(self.label_name.keys())
#print(self.label_name)
self.imgaes,self.labels=self.get_img_info('image_csv')
#--------------Divide the scope of training set and test set--------------
if mode=='train':
self.images=self.imgaes[:int(0.8*len(self.imgaes))]
self.labels=self.labels[:int(0.8*len(self.labels))]
else:
self.images=self.imgaes[int(0.8*len(self.imgaes)):]
self.labels=self.labels[int(0.8*len(self.labels)):]
#---------------Divide the scope of training set and test set-------------
pass
def __len__(self):
return len(self.images)
pass
def get_img_info(self,filename):#This is a function to get picture information
images=[]
labels=[]
for name in self.label_name.keys():#Take out the key of the dictionary
images+=glob.glob(os.path.join(self.file,name,'*.jpg'))
images+=glob.glob(os.path.join(self.file,name,'*png'))
#print(images)
pass
random.shuffle(images)#Mess up all the addresses and in here
with open(os.path.join(self.file,filename),mode='w',newline='') as f:
writer=csv.writer(f)
for file in images:
img=file.split(os.sep)[-2]
label=self.label_name[img]
labels.append(label)
writer.writerow([file,label])
pass
pass
#print(images)
return images,labels
def __getitem__(self, item):
image=self.images[item]
label=self.labels[item]
tf=torchvision.transforms.Compose([
lambda x:Image.open(x).convert('RGB'),
transforms.Resize((int(self.size),int(self.size))),
transforms.RandomRotation(15),
transforms.CenterCrop(64),
transforms.ToTensor()#This is the last operation. The previous ones are modified on the basis of the picture. This one transforms the modified ones into tensors
])
img=tf(image)
label=torch.tensor(label)
return img,label
def main():
#viz=visdom.Visdom()
mydata_train = myData('traindata', 64, 'train')
mydata_test=myData('traindata', 64, 'test')
#x,y=next(iter(mydata))
#viz.image(x,win='sample_x',opts=dict(title='sample_x'))
train=DataLoader(mydata_train,batch_size=32,shuffle=True)#Package data into batch size
test=DataLoader(mydata_test,batch_size=32)
'''
print(train)
for x,y in train:
viz.images(x,nrow=8,win='batch',opts=dict(title='bacht'))
'''
if __name__=='__main__':
main()
Here are a few knowledge points to record:
Data enhancement:
Transform the data set to make the model more generalized, such as
transforms.RandomRotation(15),
transforms.CenterCrop(64),
The above two operations can be found on the Internet
transforms.ToTensor()
Convert the image into tensor and normalize the tensor from 0-255 to 0-1
transforms.Normalize()
Speed up the convergence of the model
Summary:
Today, I reviewed the collection process of user-defined data, how to collect it, and then introduced the overall collection process step by step.