1. Document summary
Source address: https://github.com/apache/rocketmq
Chinese documents: https://github.com/apache/rocketmq/tree/master/docs/cn
Commercial edition: https://www.aliyun.com/product/rocketmq
Official website translation: http://www.itmuch.com/books/rocketmq/
FAQ: http://rocketmq.apache.org/docs/faq/
RocketMQ common management commands: https://blog.csdn.net/gwd1154978352/article/details/80829534
RocketMQ default configuration: https://www.cnblogs.com/jice/p/11981107.html
2. Architecture design
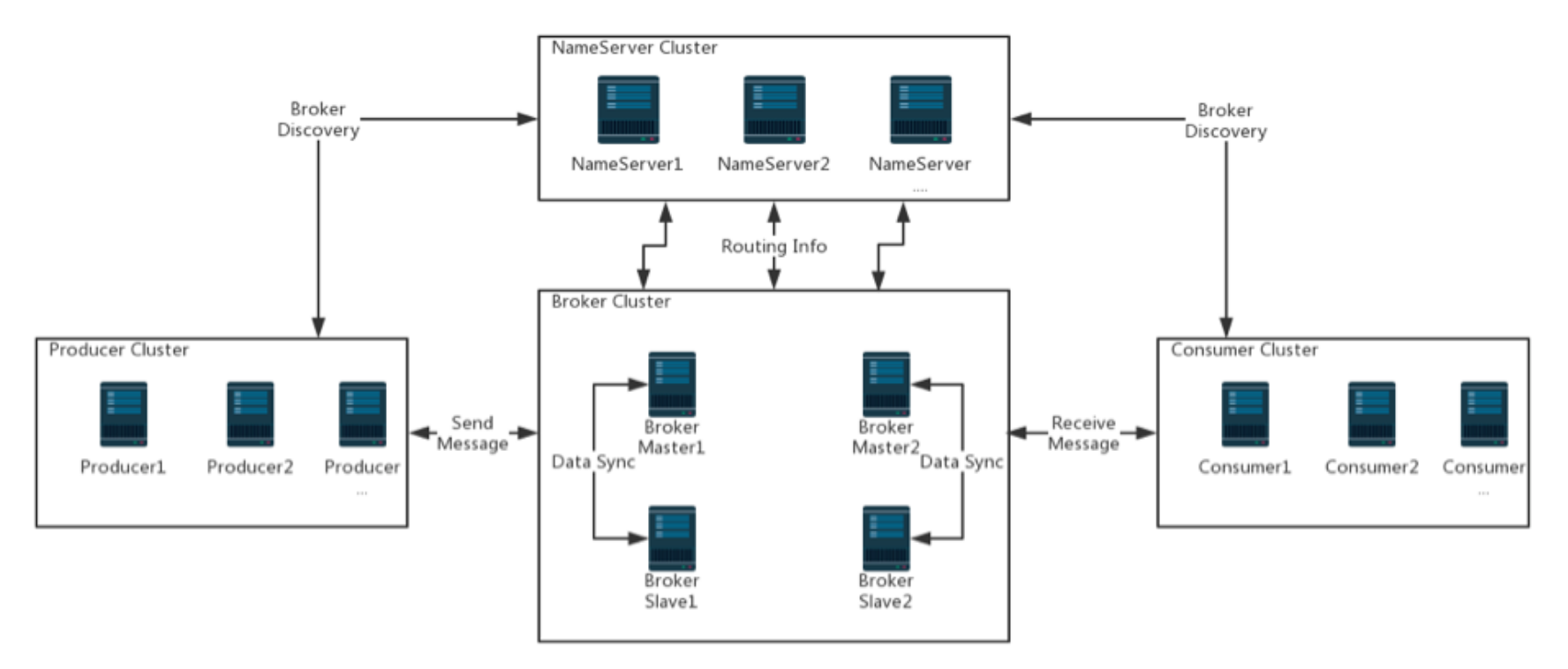
Generally, the architecture diagrams are like this. Let's take a look at the functions of various roles.
2.1 Broker
The RocketMQ service, or a process, is called a Broker. The role of Broker is to store and forward messages. The RocketMQ stand-alone machine can withstand about 100000 QPS requests.
In order to improve Broker availability (prevent single point of failure) and server performance (achieve load balancing), cluster deployment is usually done.
Like Kafka, each Broker node of the RocketMQ cluster saves a part of the total data, so it can scale horizontally.
In order to improve reliability (prevent data loss), each Broker has its own slave.
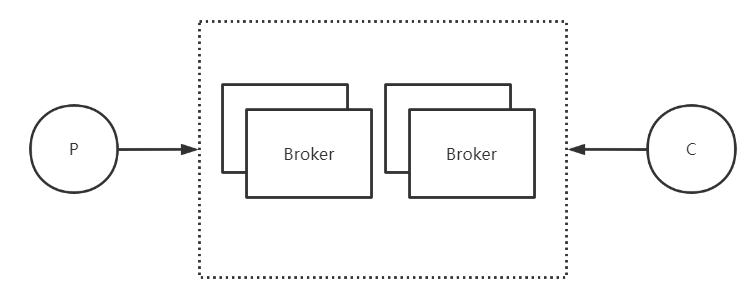
By default, all reads and writes are placed on the master. When slaveReadEnable=true, the slave can also participate in the read load. However, by default, only the slave with Broker=1 will participate in the read load, and when the master consumption is slow, it is determined by the parameter which broker whenconsumeslow.
2.2 Topic
Topic is used to divide messages by topic. Such as order message, logistics message, etc. Note that unlike Kafka, topic is a logical concept in RocketMQ, and messages are not stored according to topic.

The Producer sends the message to the specified Topic, and the Consumer can receive the corresponding message by subscribing to the Topic.
Like Kafka, if topic does not exist, it will be created automatically.
private Boolean autoCreateTopicEnable=tru;
topic s, producers and consumers are many to many relationships. A producer can send messages to multiple topics, and a consumer can subscribe to multiple topics.
2.3 NameServer
When different messages are stored on different brokers, the acquisition or routing of brokers by producers and consumers is a very key problem.
Therefore, like the registry in distributed services, RocketMQ also needs a role to uniformly manage Broker information.
In Kafka, zookeeper is used for unified management. However, RocketMQ did not do so. It implemented its own service NameServer.
We can understand it as the routing center of RocketMQ. Each NameServer node stores a full amount of routing information. In order to ensure high availability, NameServer itself can also be deployed as a cluster. The function is similar to Eureka or Redis Sentinel
In other words, the Broker will register itself on the NameServer, and producers and consumers use the NameServer to discover the Broker.
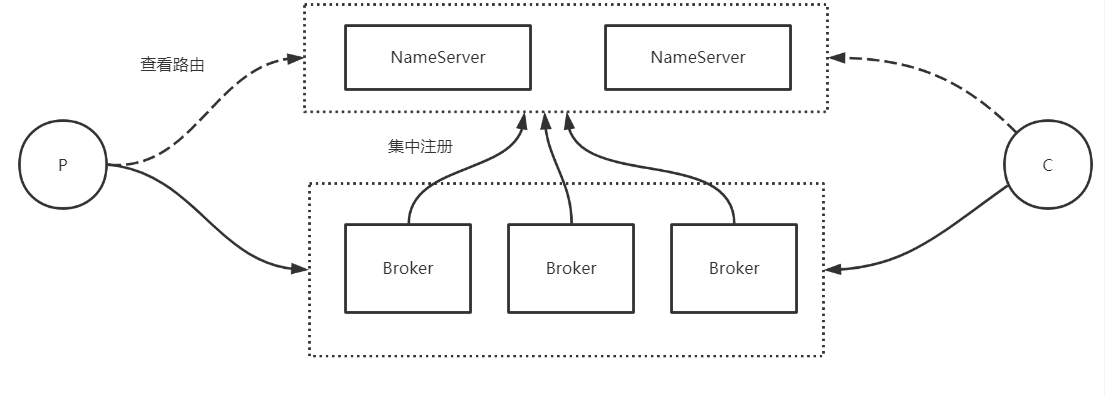
2.3. How does 1nameserver work as a routing center?
When each Broker node starts, it will traverse the NameServer list according to the configuration.
rocket/conf/broke.conf
namesrv=localhost:9876
Establish a long TCP connection with each NameServer, register your own information, and then send heartbeat information every 30S (service active registration).
If the Broker hangs up and does not send heartbeat, how can NameServer find it?
So in addition to active registration, there are regular activities. Each NameServer checks the latest heartbeat time of each Broker every 10S. If a Broker fails to send heartbeat for more than 120S, it is considered that the Broker has hung up and will be removed from the routing information.

Since they are all registration centers, why not use Zookeeper?
In fact, in earlier versions, RocketMQ also adopted the zookeeper, but removed the zookeeper dependency and chose to adopt its own NameServer.
This is because the architecture design of RocketMQ determines that only a lightweight metadata database is enough. It only needs to maintain the final consistency, rather than a strong consistency solution such as zookeeper, and does not need to rely on another middleware, so as to reduce the maintenance cost.
According to the famous CAP Theory: consistency, availability, partition, fault tolerance. zookeeper chose CP and NameServer chose AP, abandoning real-time consistency.
2.3. 2 consistency issues
Since nameservers do not communicate with each other and there is no master-slave, how do they maintain consistency?
We analyze from the following three points:
2.3. 2.1 service registration
If a Broker is added, how can it be added to all nameservers?
Because there is no master, the Broker will send heartbeat messages to all nameservers every 30 seconds, so it can be consistent.
2.3. 2.2 service rejection
If a Broker hangs, how can I remove information from all nameservers?
- If the Broker closes normally, the channel closing listener of Netty will listen to the disconnection event, and then reject the Broker information.
- If the Broker closes abnormally: the scheduled task of NameServer will scan the Broker list every 10 seconds. If the latest timestamp of a Broker's heartbeat packet exceeds the current time 120S, it will be removed.
Through the above two points, NameServer can maintain data consistency regardless of whether the Broker hangs, recovers, increases or decreases.
2.3. 2.3 route discovery
If the Broker information is updated (add or reduce nodes), how can the client get the latest Broker list?
Let's start with the producer. When sending the first message, get the routing message from the nameserver according to the Topic.
Then consumers. Consumers usually subscribe to fixed topics and need to obtain Broker information when starting.
After that, what should I do if the Broker information changes?
Because NameServer will not actively push service information to the client, and the client will not send heartbeat to NameServer, producers and consumers need to update regularly after the connection is established.
We can understand how it operates by looking at the source code.
In the send method of the MQClientInstance class, a scheduled task is started.
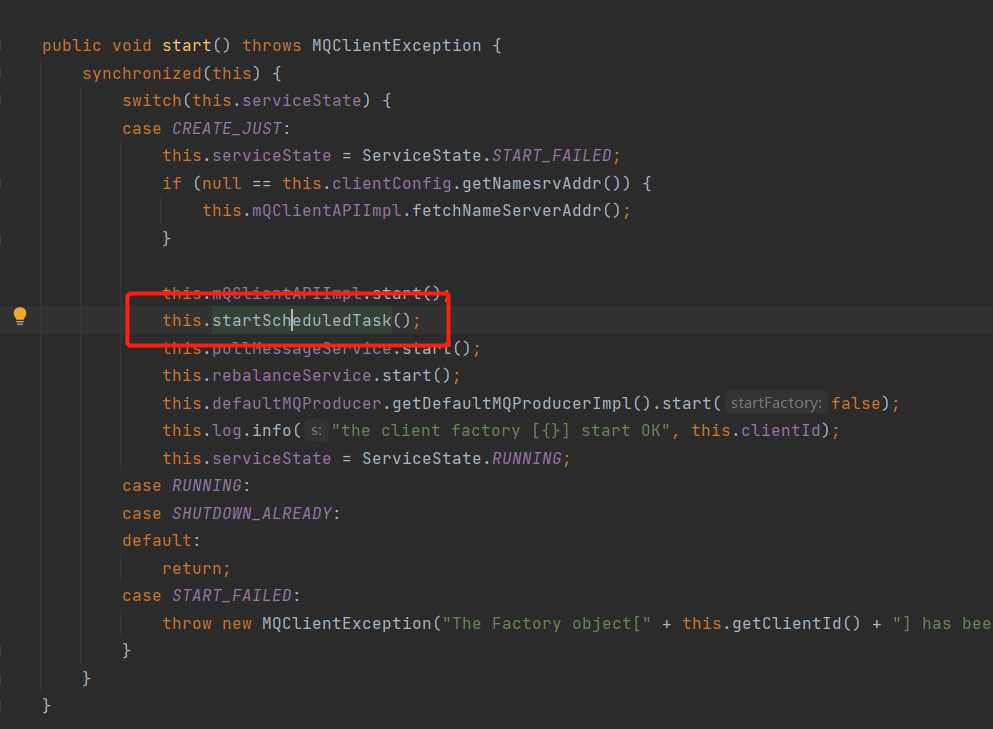
The second task is the updateTopicRouteInfoFromNameServer method, which is used to update the NameServer information regularly. By default, it is obtained once in 30S.
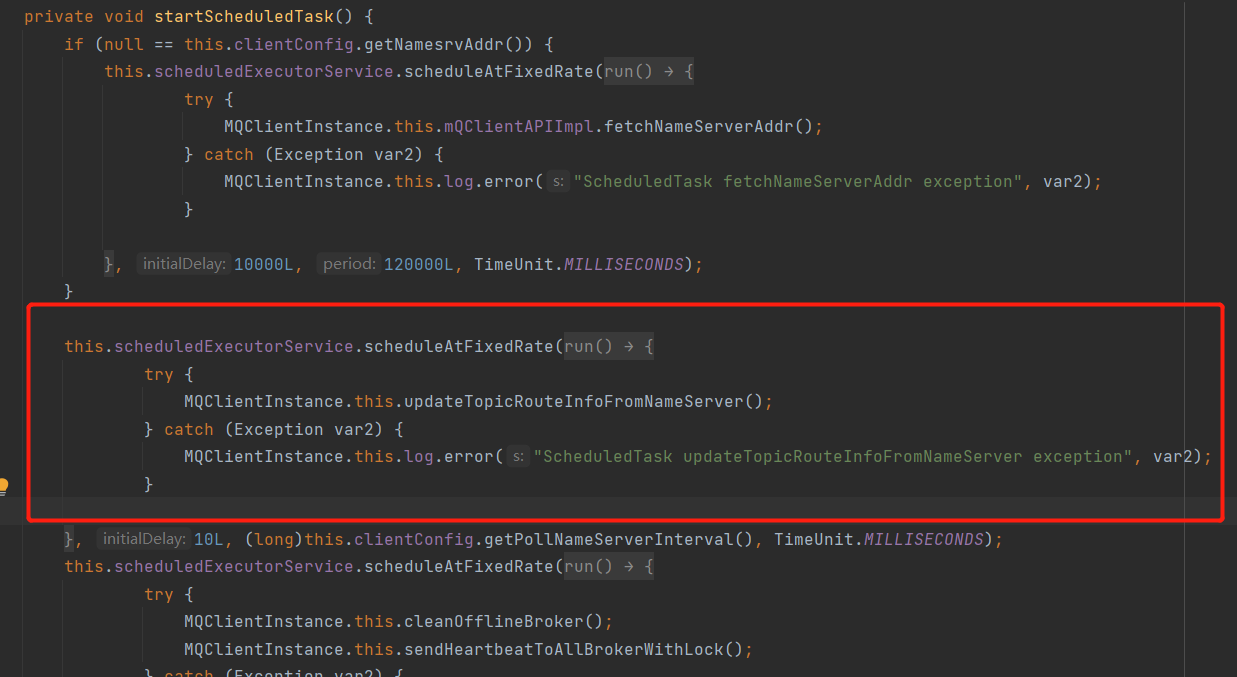
2.3. 2.4 summary
The data of each NameServer can be consistent through active registration and regular detection. Consumers and producers get the latest information by regularly updating the route.
Question 1: if the Broker hangs up and the client updates the routing information 30 seconds later, will there be a data delay of up to 30 seconds?
A: the following solutions
- retry
- Isolate unconnected brokers
- Or give priority to nodes with low latency to avoid connecting to brokers that are easy to hang up.
Question 2: what if all the nameservers as the routing center hang up and are not restored for the time being?
A: there is no problem with this. The client caches the Broker information and does not completely rely on the NameServer.
2.4 Producer
The Producer is used to produce messages. It will regularly pull routing information from the NameServer (without configuring the service address of RocketMQ), and then establish a TCP long connection with the specified Broker according to the routing information, so as to send messages to the Broker. Producers with the same sending logic can be grouped into a Group.
RocketMQ producers also support batch sending, but the List should be sent by itself.
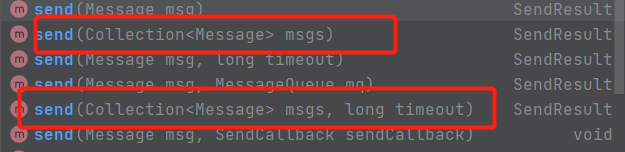
When the Producer writes data, it can only operate on the master node.
2.5 Consumer
The message Consumer obtains the routing information of the Topic through the NameServer cluster and connects to the corresponding Broker to consume the message. Consumers with consistent consumption logic can form a Group, and messages will be loaded among consumers.
Since both Master and Slave can read messages, the Consumer will establish a connection with both Master and Slave.
Note: consumers in the same consumer group should subscribe to the same topic. Or conversely, consumers who consume different topics should not use the same consumer group name. If it is different, the subscriptions of later consumers will overwrite the previous subscriptions.
Consumers have two consumption modes: cluster consumption (message polling) and broadcast consumption (all receive the same copy).
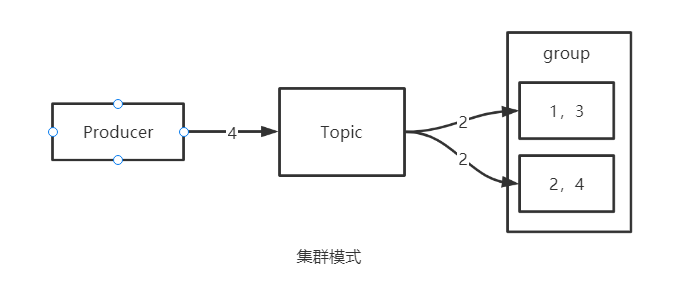

2.5.1 pull
In terms of consumption model, RocketMQ supports two modes: pull and push.
The Pull mode is that the consumer polls and pulls messages from the broker. Implementation class: defaultmqpullconsumer (obsolete), alternative class: DefaultLitePullConsumer.
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("my_test_consumer_group");
Pull can be implemented in two ways: one is ordinary polling. No matter whether the server data is updated or not, the client requests to pull the data every fixed length of time. There may be updated data return or nothing.
Disadvantages of ordinary polling: because there is no data most of the time, these invalid requests will greatly waste server resources. And when the interval of timing requests is too long, it will lead to message delay.
The pull of RocketMQ is implemented by long polling.
The client initiates Long Polling. If the server has no relevant data at this time, it will hold the request until the server has relevant data or waits for a certain time to timeout. After returning, the client will immediately initiate the next Long Polling again (the so-called hold request means that the server does not reply to the result temporarily, saves the relevant request, does not close the request connection, and writes back to the client when the relevant data is ready).
Long polling solves the problem of polling. The only disadvantage is that the server consumes more memory when it is suspended.
2.5.2 push
The Push mode is that the Broker pushes messages to consumers, and the implementation class is DefaultMQPushConsumer.
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("my_test_consumer_group");
The push mode of RocketMQ is actually implemented based on the pull mode, but it encapsulates a layer on the pull mode, so the RocketMQ push mode is not a real "push mode".
In RocketMQ, PushConsumer will register the MessageListener listener. After receiving the message, it will wake up the MessageListener's consumeMessage() to consume. For users, it feels that the message is pushed.
2.6 Message Queue
RocketMQ supports multi master architecture.
Consider this problem: when we have multiple masters, multiple messages sent to a Topic will be stored on the brokers of multiple masters.
So, do multiple messages sent to a Topic store exactly the same content on all brokers?
Definitely not. If all masters store the same content, and the slave stores the same content as the master: first, it wastes storage space. Second, the performance of the Broker cannot be linearly improved by increasing the number of machines, that is, it can only be expanded vertically. The performance can be improved by upgrading the hardware, and the horizontal (horizontal) expansion cannot be realized. Then, in a distributed environment, the performance of RocketMQ will be greatly limited.
In a word: it does not conform to the idea of segmentation.
So the key question is how to distribute messages sent to a Topic to different master s?
A partition is designed in kafka. A Topic can be divided into multiple partitions. These partitions can be distributed on different brokers, which not only realizes the fragmentation of data, but also determines that kafka can realize horizontal expansion.
Does RocketMQ have such a design?
On a Broker, RocketMQ has only one storage file, which is not stored separately according to different topics like Kafka. Data directory:
That is, if there are three brokers, there are only three commitlog s used to store different data. The question is, if the data is not distributed according to the partition, what should the data be distributed according to?
A logical concept called Message Queue is designed in RocketMQ, which is similar to partition.
First, when we create a Topic, we will specify the number of queues, one called writequeuenum (number of write queues) and one called readqueuenum (number of read queues).

The number of write queues determines how many message queues there are, and the number of read queues determines how many threads consume these message queues (only for load).
What about when MQ is not specified? How many MQ are there by default?
The server creates a Topic with 8 queues by default (BrokerConfig):
private int defaultTopicQueueNums=8
topi does not exist. The producer creates four queues by default when sending messages (DefaultMQProducer):
private volatile int defaultTopicQueueNums=4;
Messagequeues are visible on disk, but the number is only related to write queues.
For example, if I use producer to send messages, four directories will appear under the consumerqueue directory.

The client encapsulates a MessageQueue object, which is actually three pieces of content:
private String topic; private String brokerName; private int queueId;
Topic indicates which topic queue it is. Broker represents which broker it is on. For example, there are two master s, one is broker-a and the other is broker-b. queueld stands for the number of slices it is.
For example, a Topic has three message queues numbered 1, 2 and 3. There are exactly three brokers. The first MQ points to Broker1, the second MQ points to Broker2, and the third MQ points to Broker3.
When sending a message, the producer will obtain the MessageQueue according to certain rules. As long as he gets the queueld, he will know which Broker to send to, and then write the message in the commitlog.
The number of queues seen on the disk is determined by the number of write queues, and the number is the same on all master s (but the data storage is different).
Example: the cluster has two master s. If you create a topic, there are two write queues and one read queue (topic name: q-2-1).
Then two queues will appear in the consumequeue directory of the two machines, a total of four queues/ opt/rocketmq/store/broker-a/consumequeue/q-2-1, that is, the total number of queues is: number of write queues * number of nodes.

If we send 6 messages and number them in sequence, what queue will we choose to send them?
We test the following with code:
Start the consumer code first:
public class SimpleConsumer {
public static void main(String[] args) throws MQClientException {
// Instantiate with specified consumer group name.
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("my_test_consumer_group");
// Specify name server addresses.
consumer.setNamesrvAddr("192.168.44.163:9876;192.168.44.164:9876");
consumer.setMessageModel(MessageModel.BROADCASTING);
// Subscribe one more more topics to consume.
consumer.subscribe("q-2-1", "*");
// Register callback to execute on arrival of messages fetched from brokers.
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
for (MessageExt msg : msgs) {
String topic = msg.getTopic();
String messageBody = "";
try {
messageBody = new String(msg.getBody(), "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
// Re consumption
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
String tags = msg.getTags();
System.out.println("topic:" + topic + ",tags:" + tags + ",msg:" + messageBody);
}
// Consumption success
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
//Launch the consumer instance.
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
Then start the producer:
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("my_test_producer_group");
producer.setNamesrvAddr("192.168.44.163:9876;192.168.44.164:9876");
producer.start();
for (int i = 0; i < 6; i++) {
try {
// tags is used to filter the message keys. Multiple keys are separated by spaces. RocketMQ can quickly retrieve messages based on these keys
Message msg = new Message("q-2-1",
"TagA",
"2673",
("RocketMQ " + String.format("%05d", i)).getBytes());
SendResult sendResult = producer.send(msg);
System.out.println(String.format("%05d", i) + " : " + sendResult);
} catch (Exception e) {
e.printStackTrace();
}
}
producer.shutdown();
}
}
Because the consumer has only one read queue, it can only consume the queue with number 0.
Conversely, if there are 1 write queue and 2 read queues:
Then a queue will appear in the consumerqueue directory of the broker.

Because there are currently two read queues, all messages can be received.
summary
The number of read-write queues should be the same, otherwise it will not be consumed.
3. Java development
3.1 Java API
The official Java client API is provided. You only need to introduce relevant dependencies.
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.7.1</version>
</dependency>
The official also provided a detailed code case.
| package | effect |
|---|---|
| batch | Batch messages, sent with List |
| benchmart | performance testing |
| broadcast | Broadcast message |
| delay | Delay message MSG setDelayTimeLevel |
| filter | Filtering based on tag or sql expression |
| operation | command line |
| ordermessage | Sequential message |
| quickstart | introduction |
| rpc | Implement RPC calls |
| simple | ACL, asynchronous, assign,subscribe |
| tracemessage | Message tracking |
| transaction | Transaction message |
3.1. 1 producer
Let's look at the simple producer Code:
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("my_test_producer_group");
producer.setNamesrvAddr("192.168.44.163:9876;192.168.44.164:9876");
producer.start();
for (int i = 0; i < 6; i++) {
try {
// tags is used to filter the message keys. Multiple keys are separated by spaces. RocketMQ can quickly retrieve messages based on these keys
Message msg = new Message("q-2-1",
"TagA",
"2673",
("RocketMQ " + String.format("%05d", i)).getBytes());
SendResult sendResult = producer.send(msg);
System.out.println(String.format("%05d", i) + " : " + sendResult);
} catch (Exception e) {
e.printStackTrace();
}
}
producer.shutdown();
}
}
Code interpretation:
- Multiple producers sending the same type of message are called a producer group.
- The producer needs to obtain the routing information of all brokers through NameServer, and multiple brokers are separated by semicolons. Like the sentinel of Redis, obtain the server address through the sentinel.
- Message represents a message. Topic must be specified. It represents the classification of messages. It is a logical concept, such as order messages and fund messages.
- Tags: optional. It is used to filter messages on the consumer side. It is a breakdown of the purpose of messages. For example, Topic is an order message, and tag can be create, update and delete.
- Keys: Message keywords. If there are more than one, separate them with spaces. RocketMQ can quickly retrieve messages based on these keys, which is equivalent to the message index and can be set as the unique number (primary key) of the message.
- SendResult is the encapsulation of the sending result, including message status, message ld, selected queue, etc. as long as no exception is thrown, it means that the sending is successful.
SendResult [sendStatus=SEND_OK, msgId=COA8006F5B6418B4AAC299CF37140009, offsetMsgld=null,messageQueue=MessageQueue [topic=ransaction-test-topic, brokerName=broker-b, queueld=3], queueOffset=5]
msgld: the unique number generated by the producer, which is globally unique, also known as uniqld.
offsetMsgld: Message offset ID, which records the physical address of the cluster where the message is located, mainly including the address (IP and port number) of the stored Broker server and the physical offset of the commitlog file.
3.1. 2 consumers
public class SimpleConsumer {
public static void main(String[] args) throws MQClientException {
// Instantiate with specified consumer group name.
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("my_test_consumer_group");
// Specify name server addresses.
consumer.setNamesrvAddr("192.168.44.163:9876;192.168.44.164:9876");
consumer.setMessageModel(MessageModel.BROADCASTING);
// Subscribe one more more topics to consume.
consumer.subscribe("q-2-1", "*");
// Register callback to execute on arrival of messages fetched from brokers.
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
for (MessageExt msg : msgs) {
String topic = msg.getTopic();
String messageBody = "";
try {
messageBody = new String(msg.getBody(), "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
// Re consumption
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
String tags = msg.getTags();
System.out.println("topic:" + topic + ",tags:" + tags + ",msg:" + messageBody);
}
// Consumption success
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
//Launch the consumer instance.
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
Interpretation of consumer code:
1. Consumer groups are consumer groups that consume the same topic.
2. The consumer needs to get the Broker address of the topic queue from the nameServer, and multiple are separated by semicolons.
3. Consumers can be started in two modes, broadcast and cluster. In broadcast mode, one message will be sent to all consumers, and in cluster mode, only one message will be sent to one Consumer
4. Wildcards can be used for subscriptions. The parameters after the topic name correspond to the tag of the producer message. Wildcards can be used, * represents matching all messages|| Separate multiple.
consumer.subscribe("q-2-1", "*");
5,return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; This sentence tells the Broker that the consumption is successful and the offset can be updated. That is, send ACK.
3.2 Spring boot
3.2. 1 Dependence
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.4</version>
</dependency>
Using RocketMQ in spring boot can simplify configuration, manage objects and provide template methods.
3.2. 2 configuration
The configuration of the client can be written directly in the configuration file
server.port=9096 spring.application.name=demo rocketmq.name-server=localhost:9876 rocketmq.producer.group=test-group rocketmq.producer.send-message-timeout=3000
3.2. 3 consumers
Create a consumer class and add the @ RocketMQMessageListener annotation to listen for messages.
/**
* MessageModel: Cluster mode; Broadcast mode
* ConsumeMode: Sequential consumption; Disorderly consumption
*/
@Component
@RocketMQMessageListener(topic = "springboot-topic", consumerGroup = "consumer-group",
//selectorExpression = "tag1",selectorType = SelectorType.TAG,
messageModel = MessageModel.CLUSTERING, consumeMode = ConsumeMode.CONCURRENTLY)
public class MessageConsumer implements RocketMQListener<String> {
@Override
public void onMessage(String message) {
try {
System.out.println("----------Received rocketmq news:" + message);
} catch (Exception e) {
e.printStackTrace();
}
}
}
1. Filter the message using the selectorExpression property in the annotation.
2. The MessageModel in the annotation attribute is the message model, with two values:
Sorting: multiple messengers poll for consumption messages (default).
BROADCASTING: all consumers receive the same message.
3. consumeMode is a consumption model with two values:
- Concurrent: concurrent (default). The consumer side consumes CONCURRENTLY, and the message order cannot be guaranteed. How many threads consume CONCURRENTLY depends on the size of the thread pool.
- Order: ordered. ORDERLY consumption at the consumer side, that is, the order sent by producers is consistent with the order consumed by consumers.
The difference between the two: sequential consumption requires locking the queue to be processed to ensure that only one consumption thread is allowed to process the same queue at the same time. Obviously, concurrent consumption is more efficient.
3.2. 4 producers
@Component
public class MessageSender {
@Autowired
private RocketMQTemplate rocketMQTemplate;
public void syncSend() {
SendResult result = rocketMQTemplate.syncSend("springboot-topic:tag", "This is a synchronization message", 10000);
System.out.println(result);
}
}
The producer's code is simpler. You only need to inject RocketMQTemplate to send messages.
There are several types of messages sent:
1. Synchronization (syncSend method): refers to the communication method in which the message sender sends data and sends the next data packet after receiving the response from the receiver.
2. Asynchronous (asyncSend method): it refers to the communication mode in which the sender sends data, does not wait for the receiver to send back the response, and then sends the next data packet. The asynchronous sending of MQ requires the user to implement the asynchronous sending callback interface (SendCallback). When executing the asynchronous sending of messages, the application can directly return without waiting for the server response, receive the server response through the callback interface, and process the server response results.
3. One way (sendOneWay method): it is only responsible for sending messages without waiting for a response from the server, and there is no callback function trigger, that is, it only sends requests without waiting for a response. The time-consuming process of sending messages in this way is very short, generally at the microsecond level. Application scenario: it is applicable to some scenarios that take a very short time but do not require high reliability, such as log collection.
How to select the sending method?
- When the message sent is not important, the one-way method is adopted to improve the throughput;
- When the sent message is important and insensitive to the response time, sync mode is adopted;
- async is used when the message sent is very important and sensitive to response time.