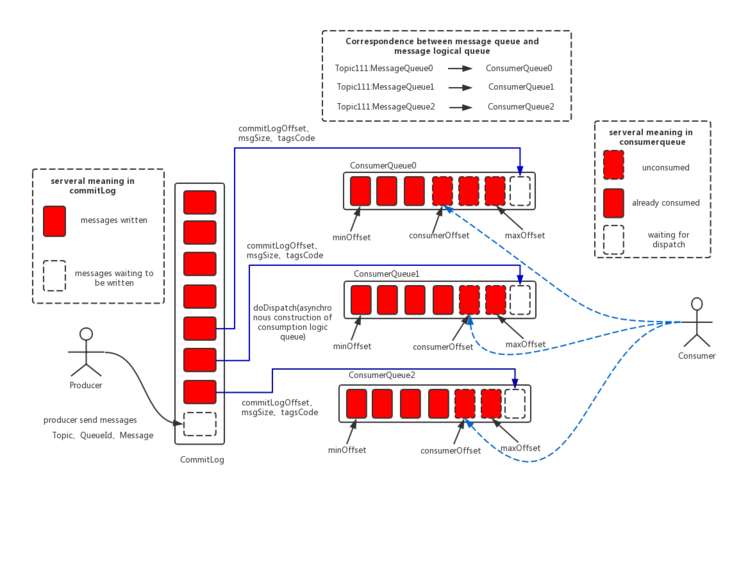
The above is a picture found on the official website. After the producer sends the message, the broker generates the commitlog and ConsumerQueue files, and then the consumer obtains the message according to the starting physical address + message size in the commitlog in the ConsumerQueue, and then obtains the message for consumption.
The following three files are CommitLog,ConsumerQueue and IndexFile.
1, CommitLog file
Store the message body content written by the Producer side. The message content is not of fixed length. The default size of a single file is 1G, the length of the file name is 20 bits, the left is filled with zero, and the rest is the starting offset. The offset here is the byte representation of the file size. The advantage is that as long as we know the offset of the message, we can quickly know which file the message is in. Assuming that the physical offset of a message is 1073741830, the relative offset is 6 (6 = 1073741830 - 1073741824), so it is determined that the message is located on the second commitLog file.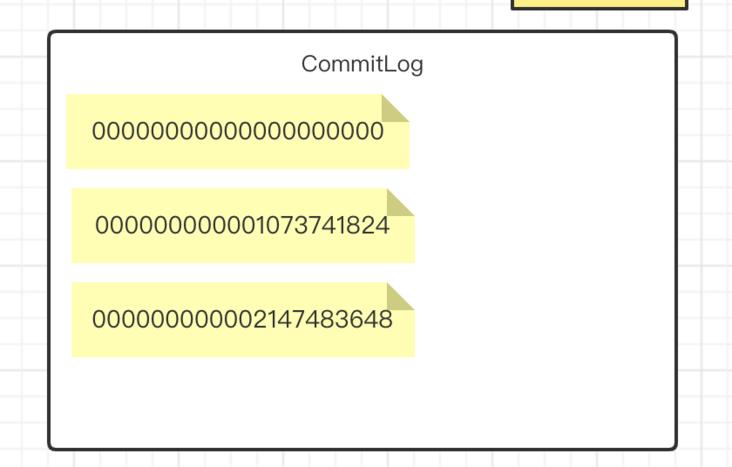
It has the following features:
- Write in sequence. When one file is full, write the next one
- There will be a mappedFile memory mapping file before disk brushing. The message is written to the memory mapping file first, and then written to the hard disk according to the disk brushing strategy
- header+body format, where the header is fixed length and records the length of the message
- When reading a message, first parse the header, get the message length from it, and then read the message body
2, ConsumerQueue file
Before introducing the ConsumerQueue file, you need to mention the consumption progress, which is the progress of each consumer consumption topic managed by the Broker. This progress may be generated after normal consumption or reset consumption. In both cases, the consumer will report the progress and the Broker will record it. The reason to manage the consumption progress is to ensure that consumers can accurately follow the progress of the last consumption under normal state, restart and abnormal shutdown, that is, to ensure that the message can be "consumed at least once", so consumers need idempotent measures to ensure that they will not consume again. This will be mentioned later.
Then go back to the ConsumerQueue file, which records the location information of a message delivered to a queue. We know that the message exists in the CommitLog file, but we must first obtain the offset of the message, and then query in the CommitLog according to the offset, and the offset of the message is recorded in the ConsumerQueue file, It can also be understood as follows: ConsumerQueue is an index file of CommitLog.
ConsumerQueue is stored according to the topic dimension. There are four queues for each topic by default, and the consumequeue files are stored in them.
It records the initial physical offset offset, message size and HashCode value of the message Tag in the CommitLog of the message in the queue under a Topic.
It has the following features:
- Each topic has 4 queues by default
- There can be a maximum of 30W entries in a single queue, and the size of each consumqueue file (entry) is about 5.72M
- The consumequeue file adopts a fixed length design, with a total of 20 bytes. Enables it to quickly locate data in a way similar to accessing arrays.
The ConsumerQueue does not store the tag of the message, but the hashCode of the tag, mainly to ensure the fixed length of the entry.
In this way, the process of locating a message has two steps:
- First read the ConsumeQueue to get the offset of the message in the CommitLog
- Then find the message content corresponding to CommitLog through offset
Consumers can get messages in ConsumeQueue through the offset saved by the broker (the subscript of ConsumerQueue saved in the offsetTable.offset json file), which will be described in detail in the next chapter.
ConsumerQueue has two functions besides basic message retrieval:
- Filter messages through tag. Filtering tags is also achieved by traversing ConsumeQueue (first compare the hash(tag) that meets the conditions, and then go to the consumer to compare the original tag)
- ConsumeQueue can also use the PageCache of the operating system to cache and improve the retrieval performance
3, IndexFile file
Messages can also be retrieved by key or time. Of course, we can't directly search from CommitLog, but need to use IndexFile.
The file name fileName in the IndexFile is named after the timestamp when it is created. The size of a fixed single IndexFile is about 400M. An IndexFile can store 2000W indexes. The underlying storage of the IndexFile is designed to implement the HashMap structure in the file system. Therefore, the underlying implementation of the index file of rocketmq is hash index.
- IndexFile generation principle
Whenever the index of a new message comes in, first take the hashCode of the MessageKey, and then use the hashCode to model the total number of slots to get which slot should be placed. The total number of slots is 500W by default. As long as you take a hash, you will inevitably face the problem of hash conflict. Like HashMap, IndexFile also uses a linked list structure to solve hash conflict. The only slight difference between this and HashMap is that the pointer of the latest index is placed in the slot, that is, the latest index after a conflict is placed in the slot. This is because the most recent information must be checked first in general query.
The pointer value placed in each slot is the offset of the index in the indexFile, and the size of each index is 20 bytes. Therefore, it is easy to locate the position of the index according to the number (offset) of the current index in the file. Then, each index saves the position of the previous index in the same slot, and so on to form a linked list structure. - IndexFil composition
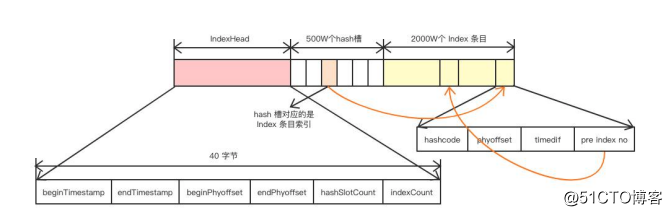
IndexFile consists of three parts:
1) The index file consists of an index header. The header file consists of 40 bytes of data, mainly including:
//8-bit storage time (disk dropping time) of the first message of the index file this.byteBuffer.putLong(beginTimestampIndex, this.beginTimestamp.get()); //8-bit storage time (disk dropping time) of the last message of the index file this.byteBuffer.putLong(endTimestampIndex, this.endTimestamp.get()); //8-bit physical location offset of the first message of the index file in the commitlog (message storage file) (the message can be obtained directly through the physical offset) this.byteBuffer.putLong(beginPhyoffsetIndex, this.beginPhyOffset.get()); //8-bit physical location offset of the last message of the index file in the commitlog (message storage file) this.byteBuffer.putLong(endPhyoffsetIndex, this.endPhyOffset.get()); //4-bit the current number of hash slot s of the index file this.byteBuffer.putInt(hashSlotcountIndex, this.hashSlotCount.get()); //Current index number of 4-bit index files this.byteBuffer.putInt(indexCountIndex, this.indexCount.get());
2) Slot
Next to the IndexHeader, the default number of slots is 5 million, each with a fixed size of 4 bytes. An int value is stored in the slot, indicating the latest index sequence number under the current slot.
When calculating the corresponding slot, the Hashcode of the MessageKey will be calculated first, and then the total number of slots will be modeled with the Hashcode to determine the location of the message key. The total number of slots is 500W by default.
As long as you take the hash, you will inevitably face the problem of hash conflict. The indexfile also uses the linked list structure to solve the hash conflict (note that 500w slots are large, and the conflict situation is generally not large, so the red black tree is not used). The value of the slot corresponds to the serial number of the latest index under the current slot. The index stores the serial number of the previous index under the current slot and the current index, which links all indexes under the slot
//slot data storage location 40 + keyHash% (500W) * 4 int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize; //Slot Table 4 bytes //Record the current index of the slot. If the hash conflicts (i.e. the absSlotPos are consistent), it will be used as the pre index of the next new slot this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
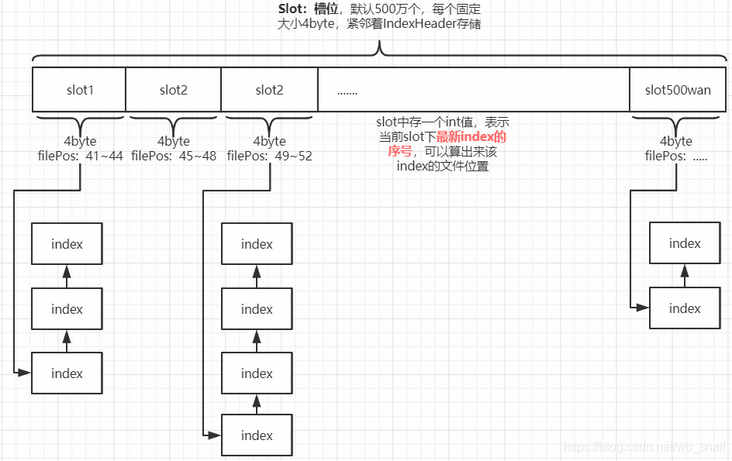
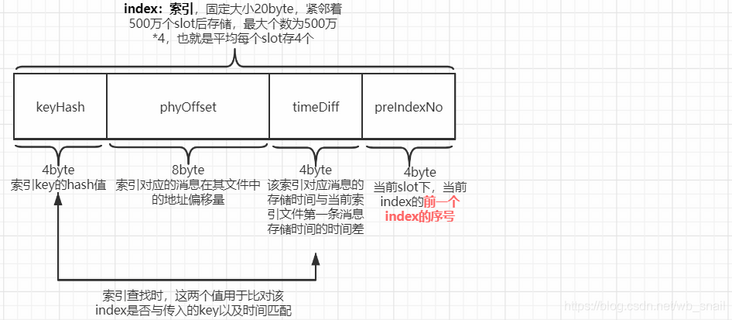
3) Index content of the message
//Index Linked list //hash value of topic+message key this.mappedByteBuffer.putInt(absIndexPos, keyHash); //The message is in the physical file address of CommitLog, and you can directly query the message (the core mechanism of index) this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset); //The difference between the drop time of the message and the beginTimestamp in the header (in order to save storage space, if the drop time of the message is directly saved, it has to be 8 bytes) this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff); //9. Record the last index of the slot //The key to hash conflict handling is the index of the previous message index of the same hash value (if the current message index is the first index of the hash value, prevIndex=0, which is also the stop condition for message index search). The prevIndex of the first message in each slot position is 0 this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
4, Query process
Since the indexHeader, slot and index are fixed in size, so:
- Formula 1: the starting position of the nth slot in the indexFile is as follows: 40+(n-1)*4
- Formula 2: the starting position of the s-th index in the indexFile is as follows: 40+50000004+(s-1)20
- In addition to the key, the incoming value of the query also includes a time start value and an end value. Why do you need to send the time range?
After an indexFile is written, it will continue to write the next one. Only one key cannot locate the specific indexFile. The time range is to locate the specific indexFile more accurately and narrow the search range. The indexFile file name is a timestamp. According to this date, you can locate which or which indexfiles correspond to the incoming date range.
Therefore, the overall query process is as follows:
Key -- > calculate the hash value -- > hash value% 500w, calculate the corresponding slot sequence number -- > calculate the position of the slot in the file according to 40 + (n-1) 4 (formula 1) -- > read the slot value, that is, the index sequence number -- > calculate the position of the index in the file according to 40 + 50000004 + (s-1) * 20 (formula 2) -- > read the index -- > compare the hash value of key and the passed in time range with the keyHash value and timeDiff value of index. If not, find the previous index according to the preIndexNo in the index and continue to the previous step; If yes, get the message in commitLog according to the phyOffset in index
Why do you have to bring the time range when comparing? Can't it just be better than key? The answer is no, because the key may be repeated. producer can specify the key of the message during message production. Obviously, this key cannot guarantee uniqueness. What about the automatically generated msgId? There is no guarantee of uniqueness.
5, Process of building two index files
IndexFile the construction of the two index files is placed in the same background task ReputMessageService. The specific process is as follows:
The index construction process of indexFile is as follows:
- Get the msgid -- > hash value of the message -- > calculate the corresponding slot serial number for the 5 million remainder -- > calculate the file location of the slot according to 40+(n-1)*4 -- > read the slot value, that is, the index serial number
- Add an index data, keyHash, phyOffset and timeDiff. Needless to say, preIndexNo is the sequence number of the previous index, that is, the current value of the slot. If there is no value, there is no index under the slot
- Update the slot value to the serial number of the inserted index (the serial number of the last index is saved before updating or empty, and the serial number of the newly inserted index is saved after updating)
- Update endTimestamp, endPhyOffset, indexCount and hashslotcount in IndexHeader (this item may not be updated)
If one or more key attributes are set in the message, repeat the above process to build the index.
1) The code for building index is as follows:
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
//1. Judge that the index number of the index file is less than the maximum index number. If > = the maximum index number, IndexService will try to create a new index file
if (this.indexHeader.getIndexCount() < this.indexNum) {
//2. Calculate the hash value of the message key
int keyHash = indexKeyHashMethod(key);
//3. Hash into a hash slot according to the hash value of message key
int slotPos = keyHash % this.hashSlotNum;
//4. Calculate the actual Position of the file
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
try {
//5. Get the value in the slot according to the actual file location absSlotPos of the hash slot
//There are two situations:
//1). slot=0, the key of the current message is the first message index of the hash value
//2). Slot > 0, the key hash value is the position of the last message index
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
//6. Data verification and correction
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
//7. Calculate the specific storage location of the current message index (Append mode)
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
//8. Store the message index
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
//9. Key points: store the location of the current message index in the key hash slot. When searching through the key next time
//The key hash slot - > slot value - > curindex - >
//If (curindex. Previndex > 0) pre index (cycle until curIndex.prevIndex==0)
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
} catch (Exception e) {
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
}
} else {
log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ "; index max num = " + this.indexNum);
}
return false;
}
2) The index search code of indexfile is as follows:
The search is for the physical offset of the message
public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum,
final long begin, final long end, boolean lock) {
if (this.mappedFile.hold()) {
//1. Calculate the hash of the key
int keyHash = indexKeyHashMethod(key);
//2. Calculate the hash slot position corresponding to the hash value
int slotPos = keyHash % this.hashSlotNum;
//3. Calculate the physical file location of the hash slot corresponding to the hash value
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
if (lock) {
// fileLock = this.fileChannel.lock(absSlotPos,
// hashSlotSize, true);
}
//4. Take out the value of the hash slot
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
// if (fileLock != null) {
// fileLock.release();
// fileLock = null;
// }
//5. If the slot value < = 0, it means that there is no message index corresponding to the key, and the search is ended directly
//The slot value > maxindexcount means that the message index corresponding to the key exceeds the maximum
//Error in data search, direct end
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()
|| this.indexHeader.getIndexCount() <= 1) {
} else {
6. From current slot value Start search
for (int nextIndexToRead = slotValue; ; ) {
if (phyOffsets.size() >= maxNum) {
break;
}
7. Find current slot value(that is index count)Physical file location
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
8. Read message index data
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
//9. Get the previous message index of the message index (which can be regarded as the reference of the prev of the linked list to the previous chain node)
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
10. data verification
if (timeDiff < 0) {
break;
}
timeDiff *= 1000L;
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
//10. Data verification and comparison of hash value and disk dropping time
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
//Stop searching when previndex < = 0 or previndex > maxindexcount or prevIndexRead == nextIndexToRead or timeread < begin
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
nextIndexToRead = prevIndexRead;
}
}
} catch (Exception e) {
log.error("selectPhyOffset exception ", e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
this.mappedFile.release();
}
}
}
Reference article: Thoroughly understand the storage principle of rocketmq through these three files
rocketMq storage model_ indexFile