preface
The last article introduced that there are two dispatchers in the} dispatcherList, one of which is buildIndex. As the name suggests, this is to establish an index to facilitate developers to query messages through keywords and judge whether the message content is correct or missing. This is also an advantage over kafka.
principle
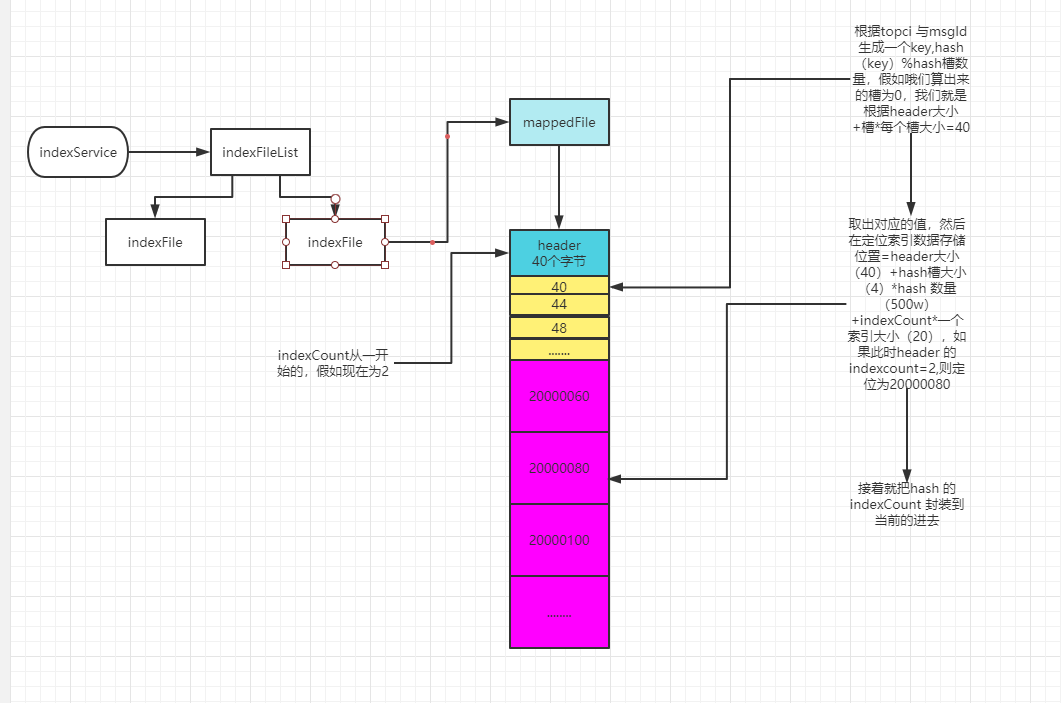
The overall design of buildIndex adopts the hashMap data structure, that is, data and linked list. An index file mappedFile has 500w hash slots, 2000w indexes and file header (40 bytes) by default. An index is 20 bytes and an index file is about 400m; The hash value is obtained according to the keyword, and the module is used to determine which hash slot is in. If the hash slot has a value, it indicates that there is a message. Then the conflict is solved through the linked list. Each hash slot maintains the latest index subscript value (indexCount) of the current key. indexCount is incremented globally, and the current index file stored in the header is the latest, The latest indexCount of the corresponding linked list stored in each hash slot;
Keyword -- key: there are two types. One is composed of topic and business unique value; The other is composed of msgId;
Briefly talk about the establishment of an index; Locate the hash slot according to the hash value of the key, and take out the value (hash_indexCount); Based on the indexcount of the header, it is named header_indexCount ; Index data storage location = header(40)+hash slot size (4) * number of hash slots (500w) + header_indexCount * an index size (20); After the location is calculated, we can store the index data. There are two main data, one is physicsofffset and the other is hash_ indexCount; Physicsofffset: you can use this value to find the corresponding message in the commitlog; And hash_ indexCount; You can query all index values on the chain according to the key, that is, through hash_ Indexcount reverses the previous index value, similar to the reverse linked list;
Suggestion: for structures similar to hashMap, it is recommended to look at the data structures and algorithms of arrays and linked lists; Better understanding, I also read it, and the understanding will be more in place;
The whole flow chart is as follows
Source code analysis of BuildIndex
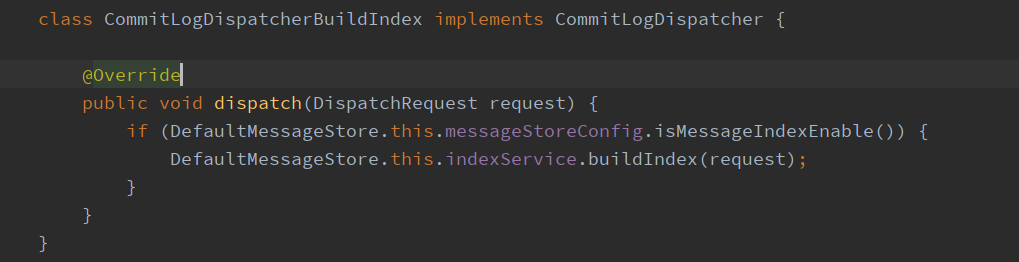
The entry is indexService. Next, we will analyze its method
public void buildIndex(DispatchRequest req) {
//Get the latest indexFile and create it when it is not or full
IndexFile indexFile = retryGetAndCreateIndexFile();
if (indexFile != null) {
long endPhyOffset = indexFile.getEndPhyOffset();
DispatchRequest msg = req;
String topic = msg.getTopic();
String keys = msg.getKeys();
//Less than indicates that it already exists, which also prevents duplication
if (msg.getCommitLogOffset() < endPhyOffset) {
return;
}
final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag());
switch (tranType) {
case MessageSysFlag.TRANSACTION_NOT_TYPE:
case MessageSysFlag.TRANSACTION_PREPARED_TYPE:
case MessageSysFlag.TRANSACTION_COMMIT_TYPE:
break;
//If the message status is rollback, there is no need to build an index
case MessageSysFlag.TRANSACTION_ROLLBACK_TYPE:
return;
}
//Create index through uniqkey + topic
if (req.getUniqKey() != null) {
indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()));
if (indexFile == null) {
log.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
return;
}
}
// Create an index through key+ topic. If there are multiple keys, separate them with commas
if (keys != null && keys.length() > 0) {
String[] keyset = keys.split(MessageConst.KEY_SEPARATOR);
for (int i = 0; i < keyset.length; i++) {
String key = keyset[i];
if (key.length() > 0) {
indexFile = putKey(indexFile, msg, buildKey(topic, key));
if (indexFile == null) {
log.error("putKey error commitlog {} uniqkey {}", req.getCommitLogOffset(), req.getUniqKey());
return;
}
}
}
}
} else {
log.error("build index error, stop building index");
}
}Get the indexFile first, that is, get the last indexFileList, judge whether it is full, and create one when it is full; Next, we will focus on building indexes. Building indexes with two input parameters calls putKey. We will focus on this method;

This can be understood as creating indexes in an endless loop
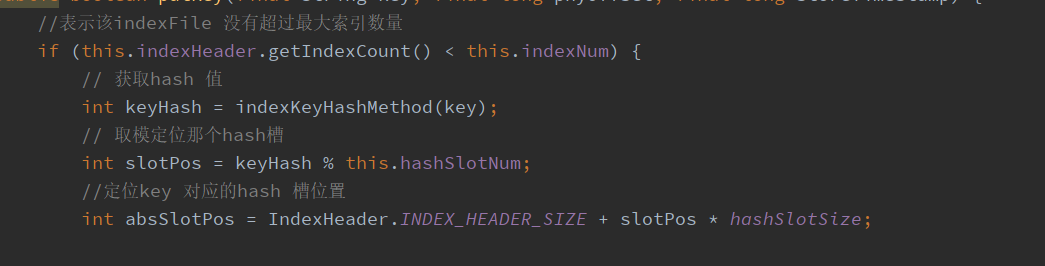
Get the hash value according to the key, locate the slot, and calculate the location of the slot in the current file

This is the implementation of getting keyHash

Get the value of the slot. This slotValue is actually the index of the stored index, which is the same as that of the header. The difference is that the header stores the latest index of the current file, while the slotValue stores the latest index of the chain corresponding to the current key
//Calculate the starting position of the index to be stored
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
//Append keyHash
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
//Append physicsofffset
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
//time difference
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
//The previous link value, slotValue equal to 0, indicates that this value is the first value of the link
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
//Stores the lower coordinates of the current index
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
// If it is 1, it indicates the first index
if (this.indexHeader.getIndexCount() <= 1) {
//Start physicsofffset
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
if (invalidIndex == slotValue) {
this.indexHeader.incHashSlotCount();
}
//Set index number + 1
this.indexHeader.incIndexCount();
//Physicsofffset at the end
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;After locating the storage index location, add index data, including keyhash value, physicsofffset and previous slotValue. Update the hash slot to the lower coordinate of the current index, update the header information, and the number of indexes + 1; The storage of the index is over. Isn't it very simple.
summary
The process of indexing can be understood as a put process of hashMap; Its index values include physicsofset and the coordinates under the index of a node on the linked list, which forms a reverse linked list; According to this principle, you can quickly locate the physicsofffset through topic + key, and quickly query the specific content of the message through physicsofffset.