catalogue
catalogue
1. How to call other people's remote services?
How to call remote services transparently?
1.2} how to encode and decode messages?
1.4 # why is there a requestID in the message?
2 how to publish your own services?
3. RPC instance analysis in Hadoop
3.1 how is the connection between client and server established?
3.2 how does the client send data to the server?
3.3} how does the client get the returned data from the server?
3.4 ipc.Server source code analysis
One background
In the past, we needed to call other people's interfaces remotely. This is what we did:
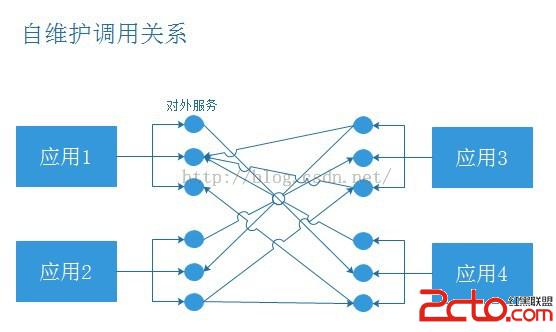
Once you step into the company, especially the large Internet company, you will find that the company's system is composed of thousands of large and small services, which are deployed on different machines and in the charge of different teams.
There are two problems:
- To build a new service, you have to rely on other people's services. Now other people's services are at the remote end. How can you call them?
- Other teams want to use our new services. How should our services be published for others to call? These two issues will be discussed below.
Second RPC
1. How to call other people's remote services?
Since the services are deployed on different machines, the call between services is inevitable in the process of network communication. Every time the service consumer calls a service, it has to write a piece of code related to network communication, which is not only complex but also very error prone.
If there is a way to call remote services like local services, and make the caller transparent to the details of network communication, it will greatly improve productivity. For example, the service consumer is executing helloworldservice When you say hello ("test"), you essentially call the remote service. This method is actually RPC (Remote Procedure Call Protocol), which is widely used in major Internet companies, such as Alibaba's hsf, dubbo (open source), Facebook's thrift (open source), Google grpc (open source), Twitter's finagle (open source), etc.
To make the network communication details transparent to users, we need to encapsulate the communication details. Let's first look at the communication details involved in the next RPC call process:
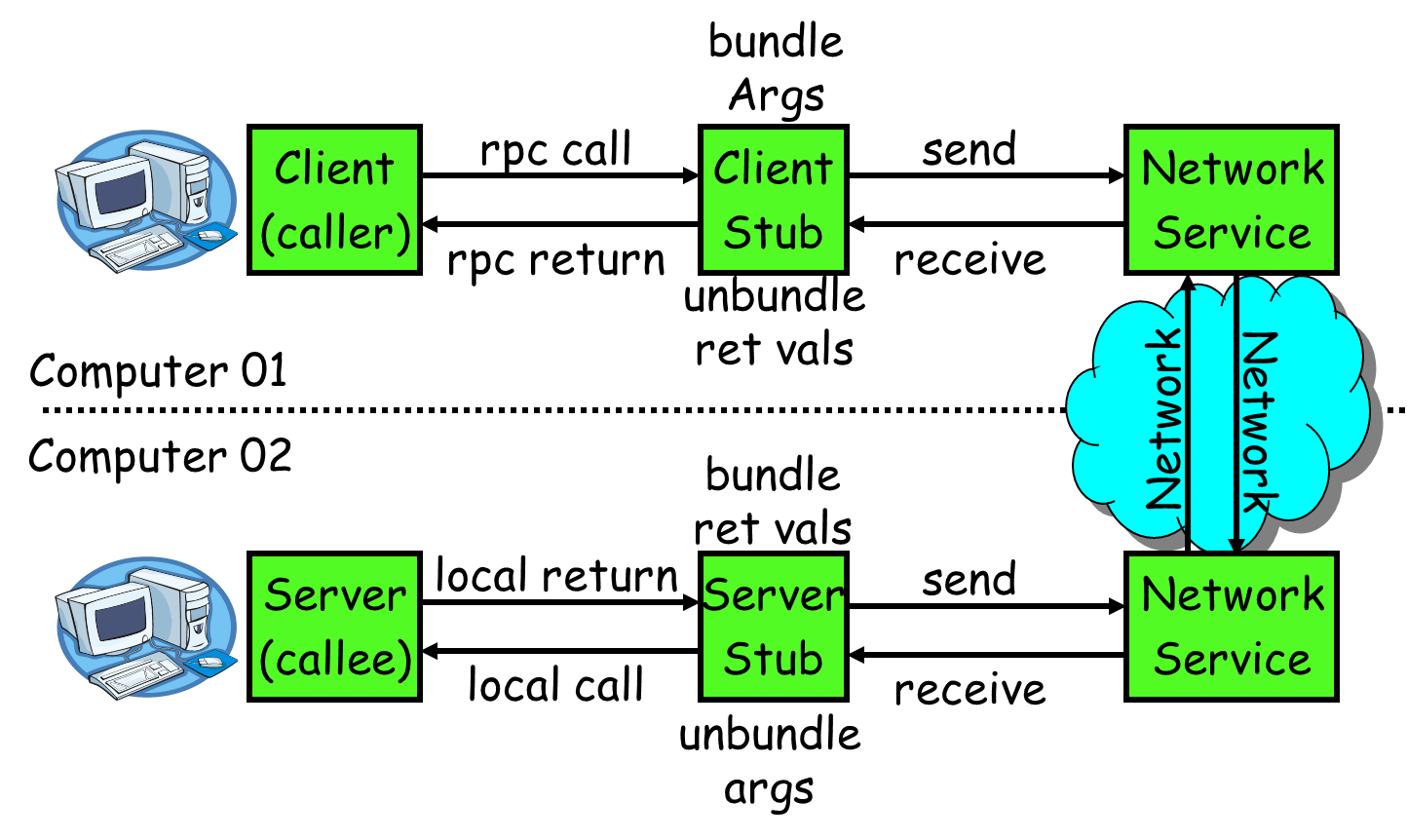
- The service consumer (client) invokes the service in a local way;
- After receiving the call, the client stub is responsible for assembling the methods, parameters, etc. into a message body capable of network transmission;
- The client stub finds the service address and sends the message to the server;
- The server stub decodes the message after receiving it;
- The server stub calls the local service according to the decoding result;
- The local service executes and returns the result to the server stub;
- server stub packages the returned result into a message and sends it to the consumer;
- The client stub receives the message and decodes it;
- Service consumers get the final result.
The goal of RPC is to 2~8 encapsulate these steps and make users transparent to these details.
1.1 how to make remote service calls transparent?
How to encapsulate communication details so that users can call remote services like local calls? For java, it is to use proxy! There are two ways of java proxy:
- jdk dynamic agent
- Bytecode generation
Although the proxy implemented by bytecode generation is more powerful and efficient, it is difficult to maintain the code. Most companies still choose dynamic proxy when implementing RPC framework.
The following is a brief introduction to how the dynamic agent realizes our requirements. We need to implement the RPCProxyClient proxy class. The invoke method of the proxy class encapsulates the details of communication with the remote service. The consumer first obtains the interface of the service provider from RPCProxyClient when executing helloworldservice The invoke method is called when the sayhello ("test") method.
public class RPCProxyClient implements java.lang.reflect.InvocationHandler{
private Object obj;
public RPCProxyClient(Object obj){
this.obj=obj;
}
/**
* Get the represented object;
*/
public static Object getProxy(Object obj){
return java.lang.reflect.Proxy.newProxyInstance(obj.getClass().getClassLoader(),
obj.getClass().getInterfaces(), new RPCProxyClient(obj));
}
/**
* Call this method to execute
*/
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
//Result parameters;
Object result = new Object();
// ... Execute communication related logic
// ...
return result;
}
}public class Test {
public static void main(String[] args) {
HelloWorldService helloWorldService = (HelloWorldService)RPCProxyClient.getProxy(HelloWorldService.class);
helloWorldService.sayHello("test");
}
}
1.2} how to encode and decode messages?
1.2.1 determining message data structure
The previous section talked about the need to encapsulate the communication details in invoke (the communication details will be discussed in detail in the following chapters), and the first step of communication is to determine the message structure of mutual communication between the client and the server. The request message structure of the client generally needs to include the following contents:
1) Interface name
In our example, the interface name is "HelloWorldService". If it is not transmitted, the server will not know which interface to call;
2) Method name
There may be many methods in an interface. If the method name is not passed, the server will not know which method to call;
3) Parameter type & parameter value
There are many parameter types, such as bool, int, long, double, string, map, list, and even struct (class); And corresponding parameter values;
4) Timeout
5) requestID, which identifies the unique request id. the use of requestID will be described in detail in the following section.
Similarly, the message structure returned by the server generally includes the following contents.
1) Return value
2) Status code
3)requestID
1.2.2 serialization
Once the data structure of the message is determined, the next step is to consider serialization and deserialization.
What is serialization? Serialization is the process of converting data structures or objects into binary strings, that is, the process of encoding.
What is deserialization? The process of converting a binary string generated during serialization into a data structure or object.
Why do I need serialization? Only after converting to binary string can network transmission be carried out!
Why deserialization? Convert binary to object for subsequent processing!
Nowadays, there are more and more serialization schemes. Each serialization scheme has advantages and disadvantages. They have their own unique application scenarios at the beginning of design. Which one to choose? From the perspective of RPC, there are three main points:
- Generality, such as whether it can support complex data structures such as Map;
- Performance, including time complexity and space complexity. Since RPC framework will be used by almost all services of the company, if serialization can save a little time, it will be very profitable for the whole company. Similarly, if serialization can save a little memory, it can also save a lot of network bandwidth;
- Scalability: for Internet companies, the business changes rapidly. If the serialization protocol has good scalability and supports the automatic addition of new business fields without affecting the old services, it will greatly provide the flexibility of the system.
At present, Internet companies widely use mature serialization solutions such as Protobuf, Thrift and Avro to build RPC framework, which are proven solutions.
1.3 communication
After the message data structure is serialized into binary string, the next step is network communication. At present, there are two common IO communication models: 1) BIO; 2) NIO . The general RPC framework needs to support these two IO models.
How to implement the IO communication framework of RPC?
- Using java nio for self-study, this method is more complex, and hidden bug s are likely to appear, but we have seen some Internet companies use this method;
- Based on mina, mina was quite popular in the early years, but the version has been updated slowly in recent years;
- Based on netty, many RPC frameworks are now directly based on netty, an IO communication framework, which is labor-saving and worry-saving, such as Alibaba's HSF, dubbo, Twitter's finagle, etc.
1.4 # why is there a requestID in the message?
If you use netty, you usually use channel Writeandflush() method to send the message binary string. After this method is called, it is asynchronous for the whole remote call (from sending the request to receiving the result), that is, for the current thread, after sending the request, the thread can execute later. As for the result of the server, it is after the server processing is completed, Then send it to the client in the form of message. So here are two problems:
- How to make the current thread "pause" and execute backward after the result comes back?
- If multiple threads make remote method calls at the same time, there will be many messages sent by both sides on the socket connection established between the client and server, and the sequence may also be random. After the server processes the result, it sends the result message to the client, and the client receives many messages. How do you know which message result is called by the original thread?
As shown in the figure below, thread A and thread B send requests requestA and requestB to the client socket at the same time. The socket sends requestB and requestA to the server successively, and the server may return responseA first, although the arrival time of requestA request is later. We need A mechanism to ensure that responseA is lost to ThreadA and responseB is lost to ThreadB.

How to solve it?
- Before calling the remote interface through the socket every time, the client thread generates a unique ID, that is, requestID (the requestID must be unique in a socket connection). Generally, AtomicLong is used to accumulate numbers from 0 to generate a unique ID;
- Store the callback object of the processing result into the global ConcurrentHashMap, put(requestID, callback);
- When a thread calls channel After writeandflush() sends the message, it executes the get() method of callback to try to get the result returned remotely. Inside get (), synchronized is used to get the lock of callback object callback, and then it is detected whether the result has been obtained. If not, then the wait() method of callback is called to release the lock on callback, so that the current thread is in wait state.
- After receiving and processing the request, the server sends the response result (which includes the previous requestID) to the client. The thread specially listening for the message on the client socket connection receives the message, analyzes the result, obtains the requestID, and then gets the requestID from the previous ConcurrentHashMap to find the callback object, and then synchronizes to obtain the lock on the callback, Set the method call result to the callback object, and then call callback Notifyall() wakes up the previously waiting thread.
public Object get() {
synchronized (this) { // Rotary lock
while (!isDone) { // Are there any results
wait(); //The result is to release the lock and put the current thread in a waiting state
}
}
}private void setDone(Response res) {
this.res = res;
isDone = true;
synchronized (this) { //Obtain the lock because the previous wait() has released the lock of the callback
notifyAll(); // Wake up the waiting thread
}
}2 how to publish your own services?
How to let others use our services? Some students said it was very simple. Just tell the user the IP and port of the service. Indeed, the key to the problem here is whether it is automatic notification or human flesh notification.
Human flesh notification method: if you find that one machine you serve is not enough, you need to add another one. At this time, you need to tell the caller that I now have two IPS. You need to poll the call to achieve load balancing; The caller clenched his teeth and changed it. As a result, one day a machine hung up. The caller found that half of the service was unavailable. He had to manually modify the code to delete the ip of the hung machine. Of course, human flesh will not be used in the real production environment.
Is there a way to realize automatic notification, that is, the addition and removal of machines are transparent to the caller, and the caller no longer needs to write the address of the service provider? Of course, nowadays, zookeeper is widely used to realize the function of automatic service registration and discovery!
In short, zookeeper can act as a Service Registry, allowing multiple service providers to form a cluster, and allowing service consumers to obtain specific service access addresses (ip + ports) through the Service Registry to access specific service providers. As shown in the figure below:
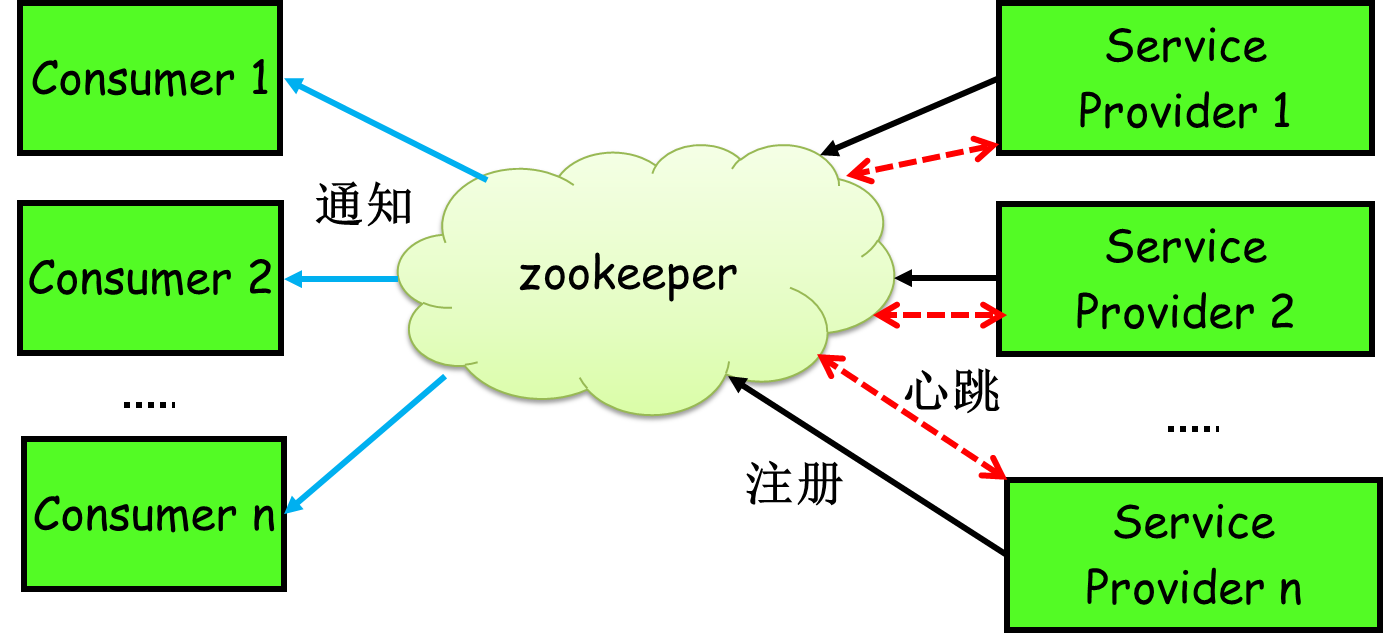
Specifically, zookeeper is a distributed file system. Every time a service provider deploys, it must register its services to a certain path of zookeeper: / {service}/{version}/{ip:port}. For example, our HelloWorldService is deployed to two machines, Then two directories will be created on zookeeper: respectively / HelloWorldService/1.0.0/100.19.20.01:16888 / HelloWorldService/1.0.0/100.19.20.02:16888.
Zookeeper provides the "heartbeat detection" function. It will send a request to each service provider regularly (in fact, a Socket long connection is established). If there is no response for a long time, the service center will think that the service provider has "hung up" and eliminate it. For example, if the machine 100.19.20.02 goes down, Then the path on zookeeper will only be / HelloWorldService/1.0.0/100.19.20.01:16888.
The service consumer will listen to the corresponding path (/ HelloWorldService/1.0.0). Once there is a task change (increase or decrease) in the data on the path, zoomeeper will notify the service consumer that the address list of the service provider has changed, so as to update it.
More importantly, the inherent fault tolerance and disaster tolerance capability of zookeeper (such as leader election) can ensure the high availability of the service registry.
3. RPC instance analysis in Hadoop
ipc. There are some internal classes in the RPC class. In order to give you a preliminary impression of the RPC class, let's first list and analyze some of the RPC classes we are interested in:
Invocation: used to encapsulate method names and parameters as the data transport layer.
ClientCache: used to store client objects. socket factory is used as hash key. The storage structure is HashMap < socketfactory, client >.
Invoker: it is the calling implementation class in the dynamic agent and inherits the InvocationHandler
Server: Yes IPC Implementation class of server.
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
•••
ObjectWritable value = (ObjectWritable)
client.call(new Invocation(method, args), remoteId);
•••
return value.get();
}If you find the implementation of the invoke() method a little strange, you are right. Generally what we see Dynamic agent There will always be method. In the invoke() method of invoke(ac, arg); This code. But not in the above code. Why? Actually, use method invoke(ac, arg); It is called in local JVM. In hadoop, the data is sent to the server, and the server returns the processing results to the client. Therefore, the invoke() method here must carry out network communication. The network communication is realized by the following code:
ObjectWritable value = (ObjectWritable) client.call(new Invocation(method, args), remoteId);
The Invocation class encapsulates the method name and parameters here. In fact, the network communication here only calls the call() method of the client class. Then let's analyze IPC Client source code. Like the first chapter, there are also three questions
- How is the connection between client and server established?
- How does the client send data to the server?
- How does the client get the returned data from the server?
3.1 how is the connection between client and server established?
public Writable call(Writable param, ConnectionId remoteId)
throws InterruptedException, IOException {
Call call = new Call(param); //Encapsulate the incoming data into a call object
Connection connection = getConnection(remoteId, call); //Get a connection
connection.sendParam(call); // Send a call object to the server
boolean interrupted = false;
synchronized (call) {
while (!call.done) {
try {
call.wait(); // Wait for the return of the result. In the callComplete() method of the Call class, there is a notify() method to wake up the thread
} catch (InterruptedException ie) {
// Terminate due to interrupt exception, set the flag interrupted to true
interrupted = true;
}
}
if (interrupted) {
Thread.currentThread().interrupt();
}
if (call.error != null) {
if (call.error instanceof RemoteException) {
call.error.fillInStackTrace();
throw call.error;
} else { // Local exception
throw wrapException(remoteId.getAddress(), call.error);
}
} else {
return call.value; //Return result data
}
}
}I have commented on the role of the specific code, so I won't repeat it here. But so far, you still don't know how the underlying network connection of RPC mechanism is established. After analyzing the code, we will find that the code related to network communication will only be the following two sentences:
Connection connection = getConnection(remoteId, call); //Get a connection connection.sendParam(call); // Send a call object to the server |
Let's take a look at how to get a connection to the server, and post IPC below getConnection() method in client class.
private Connection getConnection(ConnectionId remoteId,
Call call)
throws IOException, InterruptedException {
if (!running.get()) {
// If the client is closed
throw new IOException("The client is stopped");
}
Connection connection;
//If there is a corresponding connection object in the connections connection pool, there is no need to recreate it; If not, you need to recreate a connection object.
//However, please note that the / / connection object only stores the remoteId information, but has not established a connection with the server.
do {
synchronized (connections) {
connection = connections.get(remoteId);
if (connection == null) {
connection = new Connection(remoteId);
connections.put(remoteId, connection);
}
}
} while (!connection.addCall(call)); //Put the call object into the calls pool in the corresponding connection, and the source code will not be posted
//This code is the real completion of establishing a connection with the server~
connection.setupIOstreams();
return connection;
}The client is posted below setupIOstreams() method in connection class:
private synchronized void setupIOstreams() throws InterruptedException {
•••
try {
•••
while (true) {
setupConnection(); //Establish connection
InputStream inStream = NetUtils.getInputStream(socket); //Get input stream
OutputStream outStream = NetUtils.getOutputStream(socket); //Get output stream
writeRpcHeader(outStream);
•••
this.in = new DataInputStream(new BufferedInputStream
(new PingInputStream(inStream))); //Decorate the input stream as a DataInputStream
this.out = new DataOutputStream
(new BufferedOutputStream(outStream)); //Decorate the output stream as DataOutputStream
writeHeader();
// New activity time
touch();
//When the Connection is established, start the receiving thread and wait for the server to return data. Note: Connection inherits the tree
start();
return;
}
} catch (IOException e) {
markClosed(e);
close();
}
}The next step is to establish a client connection setupConnection() method in connection class:
private synchronized void setupConnection() throws IOException {
short ioFailures = 0;
short timeoutFailures = 0;
while (true) {
try {
this.socket = socketFactory.createSocket(); //Finally see the method of creating socket
this.socket.setTcpNoDelay(tcpNoDelay);
•••
// Set the connection timeout to 20s
NetUtils.connect(this.socket, remoteId.getAddress(), 20000);
this.socket.setSoTimeout(pingInterval);
return;
} catch (SocketTimeoutException toe) {
/* Set the maximum number of connection retries to 45.
* There is a total of 20s*45 = 15 minutes of retry time.
*/
handleConnectionFailure(timeoutFailures++, 45, toe);
} catch (IOException ie) {
handleConnectionFailure(ioFailures++, maxRetries, ie);
}
}
}Finally, we know how the client connection is established. In fact, it is to create an ordinary socket for communication.
3.2 how does the client send data to the server?
The client is posted below sendParam() method of connection class:
public void sendParam(Call call) {
if (shouldCloseConnection.get()) {
return;
}
DataOutputBuffer d=null;
try {
synchronized (this.out) {
if (LOG.isDebugEnabled())
LOG.debug(getName() + " sending #" + call.id);
//Create a buffer
d = new DataOutputBuffer();
d.writeInt(call.id);
call.param.write(d);
byte[] data = d.getData();
int dataLength = d.getLength();
out.writeInt(dataLength); //First write the length of the data
out.write(data, 0, dataLength); //Write data to the server
out.flush();
}
} catch(IOException e) {
markClosed(e);
} finally {
IOUtils.closeStream(d);
}
}3.3} how does the client get the returned data from the server?
The client is posted below Connection class and client Related methods in call class:
Method 1:
public void run() {
•••
while (waitForWork()) {
receiveResponse(); //Specific treatment methods
}
close();
•••
}
Method 2:
private void receiveResponse() {
if (shouldCloseConnection.get()) {
return;
}
touch();
try {
int id = in.readInt(); // Blocking read id
if (LOG.isDebugEnabled())
LOG.debug(getName() + " got value #" + id);
Call call = calls.get(id); //Find the object at the time of sending in the calls pool
int state = in.readInt(); // Blocking reading the state of the call object
if (state == Status.SUCCESS.state) {
Writable value = ReflectionUtils.newInstance(valueClass, conf);
value.readFields(in); // Read data
//Assign the read value to the call object, wake up the Client waiting thread, and paste the setValue() code method 3
call.setValue(value);
calls.remove(id); //Delete processed call s
} else if (state == Status.ERROR.state) {
•••
} else if (state == Status.FATAL.state) {
•••
}
} catch (IOException e) {
markClosed(e);
}
}
Method 3:
public synchronized void setValue(Writable value) {
this.value = value;
callComplete(); //Concrete implementation
}
protected synchronized void callComplete() {
this.done = true;
notify(); // Wake up the client waiting thread
}The main functions are: start a processing thread, read the call object from the Server, and wake up the client processing thread after reading the call object. It's that simple. The client gets the data returned by the Server ~. That's all for the source code analysis of the client. Let's analyze the source code of the Server.
3.4 ipc.Server source code analysis
In order to make everyone understand IPC We have a preliminary understanding of server. Let's first analyze its internal classes:
Call: used to store requests from clients
Listener: listening class, which is used to listen to requests from clients. At the same time, there is a static class inside listener, listener Reader: when the listener listens to the user request, it will let the reader read the user request.
Responder: response RPC request class. After the request is processed, the responder sends it to the requesting client.
Connection: connection class. The real client request reading logic is in this class.
Handler: request processing class, which will cyclically block reading and operating the call object in callQueue.
private void initialize(Configuration conf) throws IOException {
•••
// Create rpc server
InetSocketAddress dnSocketAddr = getServiceRpcServerAddress(conf);
if (dnSocketAddr != null) {
int serviceHandlerCount =
conf.getInt(DFSConfigKeys.DFS_NAMENODE_SERVICE_HANDLER_COUNT_KEY,
DFSConfigKeys.DFS_NAMENODE_SERVICE_HANDLER_COUNT_DEFAULT);
//Get serviceRpcServer
this.serviceRpcServer = RPC.getServer(this, dnSocketAddr.getHostName(),
dnSocketAddr.getPort(), serviceHandlerCount,
false, conf, namesystem.getDelegationTokenSecretManager());
this.serviceRPCAddress = this.serviceRpcServer.getListenerAddress();
setRpcServiceServerAddress(conf);
}
//Get server
this.server = RPC.getServer(this, socAddr.getHostName(),
socAddr.getPort(), handlerCount, false, conf, namesystem
.getDelegationTokenSecretManager());
•••
this.server.start(); //Start RPC server clients. Only this server can be connected
if (serviceRpcServer != null) {
serviceRpcServer.start(); //Start RPC serviceRpcServer server serving HDFS
}
startTrashEmptier(conf);
}Check the Namenode initialization source code and know that the server object of RPC is through IPC Obtained by getServer() method of RPC class. Let's take a look at IPC Source code of getServer() in RPC class:
public static Server getServer(final Object instance, final String bindAddress, final int port,
final int numHandlers,
final boolean verbose, Configuration conf,
SecretManager<? extends TokenIdentifier> secretManager)
throws IOException {
return new Server(instance, conf, bindAddress, port, numHandlers, verbose, secretManager);
}At this time, we found that getServer() is a factory method to create a server object, but it creates RPC Object of the server class. Ha ha, now you understand what I said earlier, "RPC.Server is the implementation class of ipc.Server". But RPC The constructor of server still calls IPC For the constructor of server class, due to space limitation, the relevant source code will not be posted.
After initializing the server, the server side will run. Take a look at IPC Server's start() source code:
/** Start service */
public synchronized void start() {
responder.start(); //Start responder
listener.start(); //Start listener
handlers = new Handler[handlerCount];
for (int i = 0; i < handlerCount; i++) {
handlers[i] = new Handler(i);
handlers[i].start(); //Start the Handler one by one
}
}Analyzed IPC After the Client source code, we know that the underlying communication of the Client side directly adopts blocking IO programming. At that time, we guessed whether the Server side also adopts blocking io. Now let's analyze it carefully. If the Server side also adopts blocking IO, the performance of the Server side is bound to be affected when there are many connected clients. hadoop implementers take this into account, so they use java NIO to implement the Server side. How does the Server side use java NIO to establish a connection? By analyzing the source code, we know that the Server side uses Listener to listen to the connection of the Client. Let's first analyze the Listener constructor:
public Listener() throws IOException {
address = new InetSocketAddress(bindAddress, port);
// Create ServerSocketChannel and set it to non blocking
acceptChannel = ServerSocketChannel.open();
acceptChannel.configureBlocking(false);
// Bind socket server to local port
bind(acceptChannel.socket(), address, backlogLength);
port = acceptChannel.socket().getLocalPort();
// Get a selector
selector= Selector.open();
readers = new Reader[readThreads];
readPool = Executors.newFixedThreadPool(readThreads);
//Start multiple reader threads to prevent the response delay of the server when there are many requests
for (int i = 0; i < readThreads; i++) {
Selector readSelector = Selector.open();
Reader reader = new Reader(readSelector);
readers[i] = reader;
readPool.execute(reader);
}
// Register connection events
acceptChannel.register(selector, SelectionKey.OP_ACCEPT);
this.setName("IPC Server listener on " + port);
this.setDaemon(true);
}When starting the Listener thread, the server will always wait for the connection of the client, and the server is posted below run() method of Listener class:
public void run() {
•••
while (running) {
SelectionKey key = null;
try {
selector.select();
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
key = iter.next();
iter.remove();
try {
if (key.isValid()) {
if (key.isAcceptable())
doAccept(key); //Specific connection method
}
} catch (IOException e) {
}
key = null;
}
} catch (OutOfMemoryError e) {
•••
}Server is posted below The key source code of the doAccept() method in the listener class:
void doAccept(SelectionKey key) throws IOException, OutOfMemoryError {
Connection c = null;
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel channel;
while ((channel = server.accept()) != null) { //Establish connection
channel.configureBlocking(false);
channel.socket().setTcpNoDelay(tcpNoDelay);
Reader reader = getReader(); //Get a reader from the readers pool
try {
reader.startAdd(); // Setting the selector to true and the selector to add
SelectionKey readKey = reader.registerChannel(channel);//Set read event as interest event
c = new Connection(readKey, channel, System.currentTimeMillis());//Create a connection object
readKey.attach(c); //Inject the connection object into the readKey
synchronized (connectionList) {
connectionList.add(numConnections, c);
numConnections++;
}
•••
} finally {
//Set adding to false and use notify() to wake up a reader. In fact, each reader started in code 13 makes
//The wait() method is used to wait. Due to the limited space, the source code will not be posted.
reader.finishAdd();
}
}
}When the reader is awakened, the reader then executes the doRead() method.
Server is posted below Listener. The doRead() method in the reader class and the server Source code of readAndProcess() method in connection class:
Method 1:
void doRead(SelectionKey key) throws InterruptedException {
int count = 0;
Connection c = (Connection)key.attachment(); //Get connection object
if (c == null) {
return;
}
c.setLastContact(System.currentTimeMillis());
try {
count = c.readAndProcess(); // Accept and process requests
} catch (InterruptedException ieo) {
•••
}
•••
}
Method 2:
public int readAndProcess() throws IOException, InterruptedException {
while (true) {
•••
if (!rpcHeaderRead) {
if (rpcHeaderBuffer == null) {
rpcHeaderBuffer = ByteBuffer.allocate(2);
}
//Read request header
count = channelRead(channel, rpcHeaderBuffer);
if (count < 0 || rpcHeaderBuffer.remaining() > 0) {
return count;
}
// Read request version number
int version = rpcHeaderBuffer.get(0);
byte[] method = new byte[] {rpcHeaderBuffer.get(1)};
•••
data = ByteBuffer.allocate(dataLength);
}
// Read request
count = channelRead(channel, data);
if (data.remaining() == 0) {
•••
if (useSasl) {
•••
} else {
processOneRpc(data.array());//Processing requests
}
•••
}
}
return count;
}
}Server is posted below The source code of processOneRpc() method and processData() method in connection class.
Method 1:
private void processOneRpc(byte[] buf) throws IOException,
InterruptedException {
if (headerRead) {
processData(buf);
} else {
processHeader(buf);
headerRead = true;
if (!authorizeConnection()) {
throw new AccessControlException("Connection from " + this
+ " for protocol " + header.getProtocol()
+ " is unauthorized for user " + user);
}
}
}
Method 2:
private void processData(byte[] buf) throws IOException, InterruptedException {
DataInputStream dis =
new DataInputStream(new ByteArrayInputStream(buf));
int id = dis.readInt(); // Attempt to read id
Writable param = ReflectionUtils.newInstance(paramClass, conf);//Read parameters
param.readFields(dis);
Call call = new Call(id, param, this); //Encapsulated as call
callQueue.put(call); // Save call into callQueue
incRpcCount(); // Increase the count of rpc requests
}4. RPC and web service
RPC:
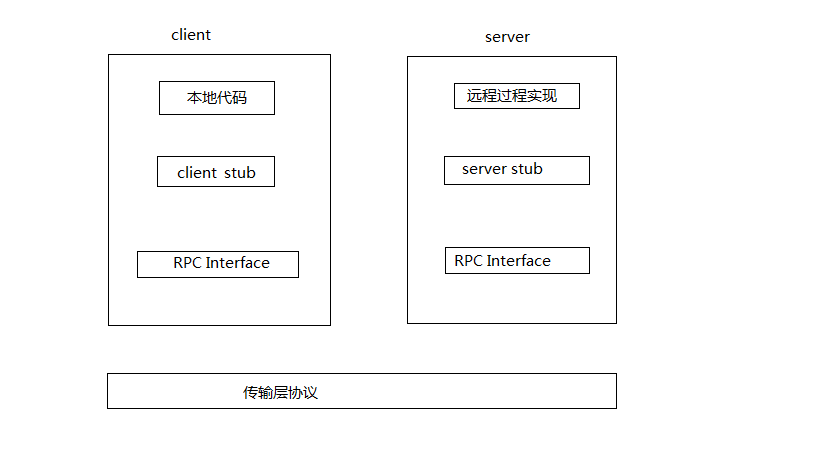
Web service
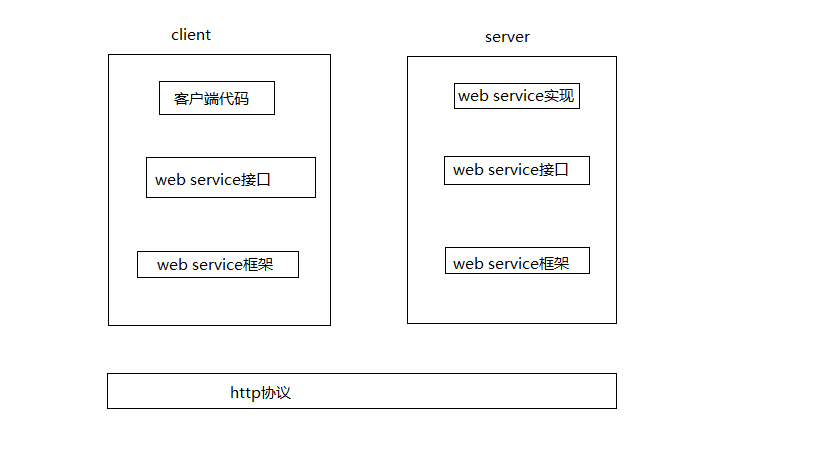
The web service interface is the stub component in RPC, which specifies the services (Web services) that the server can provide. This is consistent between the server and the client, but it is also cross language and cross platform. At the same time, due to the existence of the WSDL file in the web service specification, the web service framework of each platform can automatically generate the web service interface based on the WSDL file.
In fact, the two are similar, but the transmission protocol is different.