1. Foreword
People keep asking me, RxHttp What are the advantages over Retrofit? Here, I would like to talk about my ideas in terms of stability, functionality and ease of use.
First of all, let me state that the emergence of RxHttp is not to kill anyone, but to give you more choices and different choices.
stability
I always think that Retrofit is the player with the highest comprehensive score at present, and RxHttp is also very excellent, but the score is lower than Retrofit. What's the difference? The difference lies in the stability. After all, Retrofit is a world-famous project. There is 37k+ star on github. It goes without saying that the stability. In contrast, RxHttp is the only one 2.6k+ star , only a little famous in China.
The stability is not as stable as Retrofit, but it does not mean that RxHttp is unstable. As of December 27, 2020, RxHttp has submitted more than 1000 times on github, closed more than 200 issue s and released more than 40 versions. Although these data can not directly indicate the stability of a project, they can also be used as a reference. Personally, for a project that has been open source for only 1.5 years, It has been very good. It can be said that RxHttp is very stable. I will actively repair any problems.
Functionality
In fact, all functions are realized in different ways. There's nothing to say about this. I've seen a certain domestic network framework, saying that Retrofit is good for nothing, saying that Retrofit does not have this function and that function does not (actually all have it), and then I'm talking about myself. I don't know whether I don't understand Retrofit or do it deliberately. In my opinion, It is shameless to deliberately belittle others and elevate oneself.
Ease of use
In terms of usability, I personally believe that RxHttp is a divine existence. No matter you are encrypting requests, uploading, downloading, progress monitoring, failure retry, dynamic Baseurl, custom parser and other request scenarios, you follow the request trilogy. As long as you remember the request trilogy, you will master the essence of RxHttp and write the request code with ease, especially for newcomers, Very friendly and can start quickly.
In contrast, for many scenarios, Retrofit needs to be encapsulated again to be better used. For example, file upload / download / progress monitoring, etc., and Retrofit has more than 20 annotations, which is not very friendly to newcomers. For veterans, they sometimes forget what an annotation is used for, and when multiple annotations are used illegally together, Only during compilation can we be given clear errors, which is also a headache for me when I first started Retrofit.
in summary
RxHttp The ease of use is far better than Retrofit, but the stability is not as good as Retrofit. It can be realized in terms of functions, which is a draw.
Rxhttp & rxlife communication group (group number: 378530627, there are often technical exchanges, welcome to the group)
This article only introduces the use of RxHttp + synergy. Please check for more functions
RxHttp is a bright Http request framework in front of you
RxHttp perfectly adapts to Android 10/11 upload / download / progress monitoring
Optimal solution of RxHttp cache in the whole network
gradle dependency
1. Required
Add jitpack to the project's build In the gradle file, as follows:
allprojects {
repositories {
maven { url "https://jitpack.io" }
}
}Note: rxhttp has been fully migrated from JCenter to jitpack since version 2.6.0
//When using kapt to rely on rxhttp compiler, you must
apply plugin: 'kotlin-kapt'
android {
//Must be java 8 or higher
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}
dependencies {
implementation 'com.squareup.okhttp3:okhttp:4.9.1'
implementation 'com.github.liujingxing.rxhttp:rxhttp:2.7.3'
kapt 'com.github.liujingxing.rxhttp:rxhttp-compiler:2.7.3' //Generate RxHttp class, pure Java project, please use annotationProcessor instead of kapt
}2. Optional
android {
kapt {
arguments {
//When relying on RxJava, rxhttp_rxjava parameter is required, and RxJava version number is passed in
arg("rxhttp_rxjava", "3.1.1")
arg("rxhttp_package", "rxhttp") //Specify RxHttp class package name, not required
}
}
//If the project does not integrate kotlin, pass the parameters through the javaCompileOptions method under the defaultConfig tag
annotationProcessorOptions {
arguments = [
rxhttp_rxjava: '3.1.1',
rxhttp_package: 'rxhttp'
]
}
}
dependencies {
//Rxjava2 (one of rxjava2 / rxjava3, required when using asXxx method)
implementation 'io.reactivex.rxjava2:rxjava:2.2.8'
implementation 'io.reactivex.rxjava2:rxandroid:2.1.1'
implementation 'com.github.liujingxing.rxlife:rxlife-rxjava2:2.2.1' //Manage RxJava2 life cycle, page destruction, and close requests
//rxjava3
implementation 'io.reactivex.rxjava3:rxjava:3.1.1'
implementation 'io.reactivex.rxjava3:rxandroid:3.0.0'
implementation 'com.github.liujingxing.rxlife:rxlife-rxjava3:2.2.1' //Manage RxJava3 life cycle, page destruction, and close requests
//Not required. Choose RxHttp according to your needs. By default, GsonConverter is built in
implementation 'com.github.liujingxing.rxhttp:converter-fastjson:2.7.3'
implementation 'com.github.liujingxing.rxhttp:converter-jackson:2.7.3'
implementation 'com.github.liujingxing.rxhttp:converter-moshi:2.7.3'
implementation 'com.github.liujingxing.rxhttp:converter-protobuf:2.7.3'
implementation 'com.github.liujingxing.rxhttp:converter-simplexml:2.7.3'
}It doesn't matter if you still know a little about the collaborative process, it's because you haven't found the application scenario, and the network request is a good entry scenario. This article will teach you how to open the collaborative process gracefully and safely, and use the collaborative process to deal with multi tasks. You will be able to use it.
2. RxHttp co process usage
2.1 request Trilogy
Students who have used RxHttp know that any request sent by RxHttp follows the request trilogy, as follows:
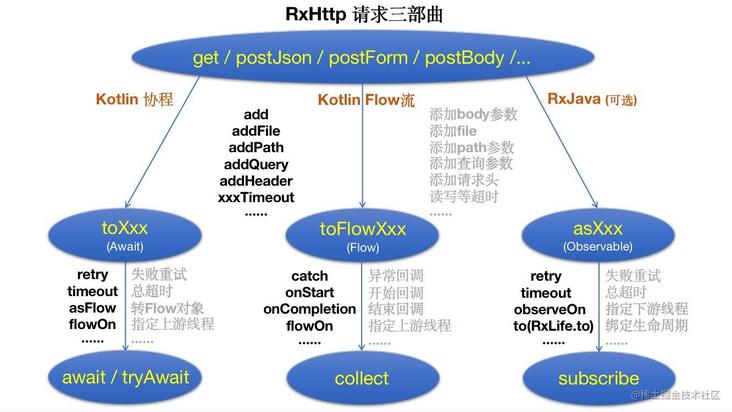
Code representation
//Kotlin synergy
val str = RxHttp.get("/service/...") //The first step is to determine the request method. You can choose postForm, postjason and other methods
.toStr() //The second step is to confirm the return type, which represents the return String type
.await() //Step 3: use the await method to get the return value
//RxJava
RxHttp.get("/service/...") //The first step is to determine the request method. You can choose postForm, postjason and other methods
.asString() //The second step is to use the asXXX series of methods to determine the return type
.subscribe(s -> { //The third step is to subscribe to observers
//Successful callback
}, throwable -> {
//Failed callback
});Note: await() is a suspend hang up method and needs to be invoked in another suspend method or a co environment.
Detailed explanation of Xiecheng request Trilogy
- In the first step, select get, postForm, postjason and other methods to determine the request method, and then add parameters, files, request headers and other information through add, addFile, addHeader and other methods
- The second step is to call the toXxx series of methods to determine the return type. The commonly used methods are toStr, toClass and toList. Then you can call more than 30 operators such as asFlow, retry, timeout, flowOn, filter, distinct and sort to execute different business logic. This article will introduce them one by one later
- The third step is to call any of await, tryAwait and awaitResult to get the return value. This step can only be called in the collaborative environment
Next, if we want to obtain any data type such as a Student object or a list < Student > collection object, we also use the await() method, as follows:
//Student object
val student = RxHttp.get("/service/...")
.toClass<Student>()
.await()
//List < student > object
val students = RxHttp.get("/service/...")
.toClass<List<Student>>()
.await()Note: the toClass() method is versatile. You can pass any data type in the past
The above is the most routine operation of RxHttp in the cooperation process. Mastering the request trilogy will master the essence of RxHttp
2.2 BaseUrl processing
RxHttp configures the default Domain name and non default Domain name through @ DefaultDomain and @ Domain annotations, as follows:
public class Url {
@DefaultDomain //Use this annotation to set the default domain name
public static String BASE_URL = "https://www.wanandroid.com";
// The name parameter will generate the setDomainToGoogleIfAbsent method here. You can specify the name at will
// The className parameter will generate RxGoogleHttp class here. You can specify the name at will
@Domain(name = "Google", className = "Google")
public static String GOOGLE = "https://www.google.com";
}The above configuration is www.wanandroid.com COM is the default domain name, www.google.com COM is a non default domain name
Multi BaseUrl processing
//Send request using default domain name
RxHttp.get("/service/...")
.toSrt().await()
//Method 1 of using google domain name: the incoming url directly brings the google domain name
RxHttp.get("https://wwww.google.com/service/...")
.toSrt().await()
//Method 2 of using google domain name: call setDomainToGoogleIfAbsent method
RxHttp.get("/service/...")
.setDomainToGoogleIfAbsent()
.toSrt().await()
//Method 3 of using google domain name: send the request directly using RxGoogleHttp class
RxGoogleHttp.get("/service/...")
.toSrt().await()Note: the domain name passed in manually has the highest priority, followed by calling the setDomainToXxx method, and then the default domain name will be used
Dynamic domain name processing
//You can directly re assign the url, and the change will take effect immediately
Url.BASE_URL = "https://www.baidu.com";
RxHttp.get("/service/...")
.toSrt().await()
//The url of the request is https://www.baidu.com/service/...2.3 unified judgment of business code
I think most people's interface return format is like this
class BaseResponse<T> {
var code = 0
var msg : String? = null
var data : T
}The first step to get the object is to judge the code. If code= 200 (assuming that 200 represents the correct data), you will get the msg field to give the user some error prompts. If it is equal to 200, you will get the data field to update the UI. The normal operation is like this
val response = RxHttp.get("/service/...")
.toClass<BaseResponse<Student>>()
.await()
if (response.code == 200) {
//Get the data field (Student) to refresh the UI
} else {
//Get the msg field and give an error prompt
} Imagine that there are at least 30 such interfaces in a project. If each interface reads such a judgment, it will be not elegant enough. It can also be said to be a disaster. I believe no one will do so. Moreover, for the UI, only the data field is needed, and I can't control the error prompt.
Is there any way to get the data field directly and make a unified judgment on the code? Yes, directly on the code
val student = RxHttp.get("/service/...")
.toResponse<Student>() //Call this method to get the data field directly, that is, the Student object
.awaitResult {
val student = it
//Update UI
}.onFailure {
val msg = it.msg
val code = it.code
}As you can see, by calling the toResponse() method, you can directly get the data field, that is, the Student object.
At this time, I believe many people will have questions,
- Where is the business code judged?
- What is the it object in the exception callback? Why can I get the msg and code fields?
Let's answer the first question first. Where is the business code judged?
In fact, the toResponse() method is not provided internally by RxHttp, but is marked by the user through a custom Parser and annotated with @ Parser. Finally, it is automatically generated by the annotation processor RxHttp compiler. Do you understand? It doesn't matter. Just look at the code
@Parser(name = "Response")
open class ResponseParser<T> : TypeParser<T> {
//The following two construction methods are necessary
protected constructor() : super()
constructor(type: Type) : super(type)
@Throws(IOException::class)
override fun onParse(response: okhttp3.Response): T {
val data: BaseResponse<T> = response.convertTo(BaseResponse::class, *types)
val t = data.data //Get data field
if (data.code != 200 || t == null) { //If code is not equal to 200, the data is incorrect and an exception is thrown
throw ParseException(data.code.toString(), data.msg, response)
}
return t
}
}The above code only needs to focus on two points,
First, we use the @ Parser annotation at the beginning of the class and name the Parser Response. At this time, rxhttp compiler will generate the toresponse < T > () method, and the naming rule is to{name}
Second, in the if statement, code= When 200 or data == null, a ParseException exception is thrown with msg and code fields, so we can get these two fields through forced rotation in the exception callback
Then answer the second question: what is the it object in the exception callback? Why can I get the msg and code fields?
In fact, it is a Throwable object, while msg and code are Throwable extension fields. We need to extend them ourselves. The code is as follows:
val Throwable.code: Int
get() =
when (this) {
is HttpStatusCodeException -> this.statusCode //Http status code exception
is ParseException -> this.errorCode.toIntOrNull() ?: -1 //Business code exception
else -> -1
}
val Throwable.msg: String
get() {
return if (this is UnknownHostException) { //Network exception
"There is no network at present. Please check your network settings"
} else if (
this is SocketTimeoutException //okhttp global setting timeout
|| this is TimeoutException //Timeout method timeout in rxjava
|| this is TimeoutCancellationException //Collaboration timeout
) {
"connection timed out,Please try again later"
} else if (this is ConnectException) {
"The network suck up. Please try again later."
} else if (this is HttpStatusCodeException) { //Request failure exception
"Http Abnormal status code"
} else if (this is JsonSyntaxException) { //The request was successful, but Json syntax exception caused parsing failure
"Data parsing failed,Please check whether the data is correct"
} else if (this is ParseException) { // ParseException indicates that the request was successful, but the data is incorrect
this.message ?: errorCode //msg is empty and code is displayed
} else {
"The request failed. Please try again later"
}
}At this point, the unified judgment of business code is introduced. Most people can simply modify the above code and directly use it in their own projects, such as ResponseParser parser. They only need to change the judgment conditions of if statement
2.4 introduction to operators
awaitResult returns kotlin Result
awaitResult is the most commonly used character. It can handle the callback of request success / failure, as follows:
val result: Result<Student> = RxHttp
.postForm("/service/...")
.toClass<Student>()
.awaitResult {
//The request is successful. Get the Student object through it
}.onFailure {
//Request exception, get Throwable object through it
} Get kotlin After the result object, the related logic of success / failure is processed subsequently
tryAwait exception returned null
tryAwait will return null when an exception occurs, as follows:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.timeout(100) //The timeout duration is 100 milliseconds
.tryAwait() //Return to Student here? Object. If an exception occurs, it is null Of course, tryAwait also supports exception callback, as follows
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.timeout(100) //The timeout duration is 100 milliseconds
.tryAwait { //Similarly, if an exception occurs, null is returned
//Here we get Throwable objects through it
} onErrorReturn, onErrorReturnItem exception default values
In some cases, we don't want to go directly to the exception callback when an exception occurs in the request. At this time, we can give the default value through two operators, as follows:
//Give default values based on exceptions
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.timeout(100) //The timeout duration is 100 milliseconds
.onErrorReturn {
//If the timeout exception occurs, the default value will be given. Otherwise, the original exception will be thrown
return@onErrorReturn if (it is TimeoutCancellationException)
Student()
else
throw it
}
.await()
//The default value is returned whenever an exception occurs
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.timeout(100) //The timeout duration is 100 milliseconds
.onErrorReturnItem(Student())
.await()repeat rotation request
The repeat operator has three parameters, as follows:
/**
* @param times Rotation training times, default long MAX_ Value, i.e. continuous rotation training
* @param period Rotation training cycle, default 0
* @param stop Rotation training termination condition: false by default, that is, unconditional rotation training times
*/
fun <T> IAwait<T>.repeat(
times: Long = Long.MAX_VALUE,
period: Long = 0,
stop: suspend (T) -> Boolean = { false }
)The above three parameters can be used together at will. The usage is as follows:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.repeat(10, 1000) { //Rotate 10 times, with an interval of 1s
return it.id == 8888 //If the student id is 8888, stop rotation training
}
.await() Retry failed to retry
The retry operator has three parameters: retry times, retry cycle and retry condition, as follows:
/**
* Failed to retry. This method is only valid when using a coroutine
* @param times Number of retries, default Int.MAX_VALUE represents constant retries
* @param period Retry cycle: 0 by default; unit: milliseconds
* @param test The retry condition is true by default. Try again whenever there is an exception
*/
fun retry(
times: Int = Int.MAX_VALUE,
period: Long = 0,
test: suspend (Throwable) -> Boolean = { true }
)The three parameters can be used together at will. We need to retry twice with an interval of 1 second when the network is abnormal. The code is as follows:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.retry(2, 1000) { //Retry twice with an interval of 1s
it is ConnectException //If it is a network exception, try again
}
.await() Timeout timeout
OkHttp provides global read, write and connection timeouts. Sometimes we need to set different timeout lengths for a request. In this case, RxHttp's timeout(Long) method can be used, as follows:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.timeout(3000) //The timeout duration is 3s
.await() map conversion symbol
The map operator is easy to understand. RxJava and the Flow of the coroutine have the same functions and are used to convert objects, as follows:
val student = RxHttp.postForm("/service/...")
.toStr()
.map { it.length } //String to Int
.tryAwait() //Return to Student here? Object, that is, it may be empty filter filtering operation
If the server returns list data, we can filter the list as follows:
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.filter{ it.age > 20 } //Filter students older than 20
.await() You can also select the filterTo operator to add the filtered data to the specified list, as follows:
val list = mutableListOf<Student>()
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.filterTo(list){ it.age > 20 } //Filter students older than 20
.await() //At this time, the returned list object is the list object we passed indistinct de duplication
This operator can de duplicate the list returned by the server, as follows:
//De duplication according to the hashCode of the Student object
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.distinct()
.await()
//De duplication according to the id of the Student object
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.distinctBy { it.id }
.await()
//Add the data after de duplication to the specified list, and judge the data in the specified list when de duplication
val list = mutableListOf<Student>()
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.distinctTo(list) { it.id }
.await() Sort sort
Sorting has two types of operators: sortXxx and sortedXxx. The difference is that sortXxx sorts in the list and returns itself after sorting, while sortedXxx sorts out of the list and returns a new list after sorting. Only sortXxx is introduced here, as follows:
//Sort by id
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.sortBy { it.id }
.await()
//Sort according to the order of id and age. id takes precedence, followed by age
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.sortBy({ it.id }, { it.age })
.await()
//Return two sorting objects and implement the sorting rules by yourself
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.sortWith { student1, student2 ->
student1.id.compareTo(student2.id)
}
.await() flowOn specifies the upstream thread
Like the flowOn operator in Flow, this operator is used to specify the upstream thread, as follows:
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.sortBy { it.id } //IO thread execution
.flowOn(Dispatchers.IO)
.distinctBy { it.id } //Default thread execution
.flowOn(Dispatchers.Default)
.filter{ it.age > 20 } //IO thread execution
.flowOn(Dispatchers.IO)
.flowOn(Dispatchers.Default)
.await() asFlow to Flow object
If you like kotlin's flow flow, asFlow comes in handy, as follows:
RxHttp.postForm("/service/...")
.toList<Student>()
.asFlow()
.collect {
//Here you get the list < student > object
} Note: after using asFlow operator, you need to use collect instead of await operator
subList, take intercept list
subList is used to intercept a certain section of the list. If the interception range is out of range, an out of range exception will be thrown; Take is used to take n data from 0. When there are less than N data, it returns all, as follows:
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.subList(1,10) //Intercept 9 data
.take(5) //Take the first 5 out of the 9
.await() async asynchronous operation
If two requests need to be parallel, we can use this operator, as follows:
//Get the information of two students at the same time
suspend void initData() {
val asyncStudent1 = RxHttp.postForm("/service/...")
.toResponse<Student>()
.async(this) //this is the CoroutineScope object. Here, deferred < student > will be returned
val asyncStudent2 = RxHttp.postForm("/service/...")
.toResponse<Student>()
.async(this) //this is the CoroutineScope object. Here, deferred < student > will be returned
//The await method is then called to get the object.
val student1 = asyncStudent1.await()
val student2 = asyncStudent2.await()
} Delay, startDelay delay
The delay operator is to delay the return for a period of time after the request ends; The startDelay operator delays the request for a period of time, as follows:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.delay(1000) //After the request comes back, the return is delayed by 1s
.await()
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.startDelay(1000) //Send the request after 1 s delay
.await() Custom operator
RxHttp has built-in a series of powerful and easy-to-use operators, but it certainly can not meet all business scenarios. At this time, we can consider custom operators
Custom takeLast operator
If we have such a requirement, we need to take n pieces of data at the end of the list for customization. If there are less than n pieces, all items will be returned
Earlier, we introduced the take operator, which starts from 0 and takes n pieces of data. If there are less than n pieces, all of them will be returned. Let's take a look at the source code
fun <T> IAwait<out Iterable<T>>.take(
count: Int
): IAwait<List<T>> = newAwait {
await().take(count)
}Code interpretation,
1. IAwait is an interface, as follows:
interface IAwait<T> {
suspend fun await(): T
}The interface has only one await() method that returns the declared T
2. The newwait operator just creates an implementation of the IAwait interface, as follows:
inline fun <T, R> IAwait<T>.newAwait(
crossinline block: suspend IAwait<T>.() -> R
): IAwait<R> = object : IAwait<R> {
override suspend fun await(): R {
return this@newAwait.block()
}
}3. Since we are the take method extended for the iawait < out iterative < T > > object, internally, we call the await() method, which returns the iterative < T > object, and finally execute the extended method take(Int) of the iterative < T > object to obtain n pieces of data from 0. take(Int) is the method provided by the system. The source code is as follows:
public fun <T> Iterable<T>.take(n: Int): List<T> {
require(n >= 0) { "Requested element count $n is less than zero." }
if (n == 0) return emptyList()
if (this is Collection<T>) {
if (n >= size) return toList()
if (n == 1) return listOf(first())
}
var count = 0
val list = ArrayList<T>(n)
for (item in this) {
list.add(item)
if (++count == n)
break
}
return list.optimizeReadOnlyList()
}ok, back to the previous topic, how to customize an operation to get n pieces of data at the end of the list. If there are less than n pieces, return all
After reading the take(int) source code above, we can easily write the following code:
fun <T> IAwait<out List<T>>.takeLast(
count: Int
): IAwait<List<T>> = newAwait {
await().takeLast(count)
}First, we extend the takeLast(Int) method to IAwait<out List<T>>, then call newAwait to create the instance object of IAwait interface, then call the await() method to return List<T> object, and finally call the takeLast(Int) method extended by the system for List<T>.
Once defined, we can use it directly, as follows:
val students = RxHttp.postForm("/service/...")
.toList<Student>()
.takeLast(5) //Take the 5 data at the end of the list. If it is insufficient, all the data will be returned
.await() The above operators can be matched at will
The above operators can be used together at will, but the effects are different due to different calling sequences. Let me tell you first that the above operators will only affect the upstream code.
Such as timeout and retry:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.timeout(50)
.retry(2, 1000) { it is TimeoutCancellationException }
.await() The above code will be retried as long as there is a timeout, and it can be retried twice at most.
However, if timeout and retry are interchanged, it will be different, as follows:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.retry(2, 1000) { it is TimeoutCancellationException }
.timeout(50)
.await() At this time, if the request is not completed within 50 milliseconds, a timeout exception will be triggered, and the exception callback will be taken directly without retry. Why is that? The reason is very simple. The timeout and retry operators only work for upstream code. Such as the retry operator, the downstream exception cannot be caught, which is why the timeout mechanism is not triggered when the timeout is in retry.
Look at the timeout and startDelay operators
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.startDelay(2000)
.timeout(1000)
.await() The above code will trigger the timeout exception. Because startDelay is delayed by 2000 milliseconds and the timeout is only 1000 milliseconds, the timeout must be triggered. However, it is different to exchange the following positions:
val student = RxHttp.postForm("/service/...")
.toResponse<Student>()
.timeout(1000)
.startDelay(2000)
.await() Under normal circumstances, the above codes can get the return value correctly. Why? The reason is very simple. As mentioned above, the operator will only affect the upstream. The startDelay delay in the downstream is ignored and can not be controlled.
3. Upload / download
RxHttp's elegant operation of files is innate. In the collaborative process environment, it is still the case. Nothing is more convincing than code and directly access the code
3.1 file upload
val result = RxHttp.postForm("/service/...")
.addFile("file", File("xxx/1.png")) //Add a single file
.addFiles("fileList", ArrayList<File>()) //Add multiple files
.toResponse<String>()
.await() Just add the File object through the addFile series methods. It's so simple and crude. To monitor the upload progress, you need to call the toFlow method and pass in the progress callback, as follows:
RxHttp.postForm("/service/...")
.addFile("file", File("xxx/1.png"))
.addFiles("fileList", ArrayList<File>())
.toFlow<String> { //Here, you can also select the toFlowXxx method corresponding to the custom parser
val process = it.progress //Uploaded progress 0-100
val currentSize = it.currentSize //Uploaded size, unit: byte
val totalSize = it.totalSize //Total size to upload unit: byte
}.catch {
//Exception callback
}.collect {
//Successful callback
}3.2 file download
Then let's take a look at the download and paste the code directly
val localPath = "sdcard//android/data/..../1.apk"
val path = RxHttp.get("/service/...")
.toDownload(localPath) //Download needs to pass in the local file path
.await() //Returns the local storage path, which is also called localPathTo download, call the toDownload(String) method and pass in the local file path. Do you want to monitor the download progress? It is also simple, as follows:
val localPath = "sdcard//android/data/..../1.apk"
val path = RxHttp.get("/service/...")
.toDownload(localPath) {
//it is a Progress object
val process = it.progress //Downloaded progress 0-100
val currentSize = it.currentSize //Downloaded size in byte s
val totalSize = it.totalSize //Total size to download unit: byte
}
.await()Take a look at the complete signature of the toDownload method
/**
* @param destPath Local storage path
* @param append Whether to add download, that is, whether to download at breakpoint
* @param capacity Queue size, effective only when listening to progress callback
* @param progress Progress callback
*/
fun CallFactory.toDownload(
destPath: String,
append: Boolean = false,
capacity: Int = 1,
progress: (suspend (Progress) -> Unit)? = null
): Await<String>If you need a breakpoint download, just pass "true" to append, as follows:
val localPath = "sdcard//android/data/..../1.apk"
val path = RxHttp.get("/service/...")
.toDownload(localPath, true) {
//it is a Progress object
val process = it.progress //Downloaded progress 0-100
val currentSize = it.currentSize //size has been down, unit: byte
val totalSize = it.totalSize //Total size to download unit: byte
}
.await()At this point, the basic Api of RxHttp collaboration process has been basically introduced. The problem is that the APIs introduced above all depend on the collaboration environment. How can I start the collaboration process? In other words, I don't know much about the cooperation process. You just need to tell me how to use it on the premise of ensuring safety. ok, how to safely open a cooperation process to achieve automatic exception capture, and automatically close the cooperation process and request when the page is destroyed
4. Process opening and closing
The Jetpack library provides two frameworks: lifecycle runtime KTX and lifecycle ViewModel KTX, which are very convenient to start the collaboration and automatically close the collaboration when the page is destroyed, as follows:
// FragmentActivity, Fragment environment
lifecycleScope.launch {
RxHttp.get("/server/...")
.toClass<Student>()
.awaitResult {
//The request is successful. Get the Student object through it
}.onFailure {
//Request exception, get Throwable object through it
}
}
// ViewModel environment
viewModelScope.launch {
RxHttp.get("/server/...")
.toClass<Student>()
.awaitResult {
//The request is successful. Get the Student object through it
}.onFailure {
//Request exception, get Throwable object through it
}
} If you want to close it manually, get the Job object returned by the launch method. You can close the collaboration through this object. When the collaboration is closed, the request will be closed automatically, as follows:
//ViewModel environment
val job = lifecycleScope.launch {
RxHttp.get("/server/...")
.toClass<Student>()
.awaitResult {
//The request is successful. Get the Student object through it
}.onFailure {
//Request exception, get Throwable object through it
}
}
//Close the coordination process at the right time
job.cancel()5. Collaborative multitasking
As we know, the biggest advantage of cooperative process is that it can write asynchronous logic in seemingly synchronous code, which makes us very elegant to realize multi task scenarios, such as parallel / serial multi request
5.1. Multiple requests in CO process serial
Suppose we have a scenario in which we first obtain the Student object, and then obtain the Student's family member list through the studentId. The latter depends on the former, which is a typical serial scenario
See how to solve this problem through the collaborative process, as follows:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState);
//Start the process and send the request
lifecycleScope.launch { sendRequest() }
}
suspend fun sendRequest() {
//Get the student object. If it is null, it will be returned directly
val student = getStudent() ?: return
//Query family member information through student Id
val personList = getFamilyPersons(student.id)
//After getting the relevant information, you can directly update the UI, such as:
tvName.text = student.name
}
//Hang up method to get student information
suspend fun getStudent(): Student? {
return RxHttp.get("/service/...")
.add("key", "value")
.addHeader("headKey", "headValue")
.toClass<Student>()
.tryAwait() //tryAwait, null is returned in case of exception
}
//Hang up method to get family member information
suspend fun getFamilyPersons(studentId: Int): List<Person> {
return RxHttp.get("/service/...")
.add("studentId", "10000")
.toClass<List<Person>>()
.onErrorReturnItem(ArrayList()) //When an exception occurs, an empty List is returned
.await()
}
}Let's focus on the next collaborative process code block. First, get the Student object through the first request, then get the studentId, and send the second request to get the list of learning family members. After getting it, you can directly update the UI. How about it? Does it look like synchronous code and write asynchronous logic.
In the serial request, as long as one of the requests is abnormal, the coroutine will close (and the request will also be closed), stop the execution of the remaining code, and then go through the exception callback
5.2. Concurrent multiple requests
Request parallelism is also common in real development. In an Activity, we often need to get a variety of data to show to users, and these data are distributed through different interfaces.
For example, we have a page with a horizontally scrolling Banner bar at the top, and the learning list is displayed below the Banner bar. At this time, there are two interfaces, one to obtain the Banner bar list and the other to obtain the learning list. They are independent of each other and can be executed in parallel, as follows:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState);
//Start the process and send the request
lifecycleScope.launch { sendRequest(this) }
}
//Currently running in UI thread
suspend fun sendRequest(scope: CoroutineScope) {
val asyncBanner = getBanners(scope) //The deferred < list < banner > > object is returned here
val asyncPersons = getStudents(scope) //The deferred < list < student > > object is returned here
val banners = asyncBanner.tryAwait() //List < banner > is returned here? object
val students = asyncPersons.tryAwait() //List < student >? Is returned here? object
//Start updating UI
}
//Hang up method to get student information
suspend fun getBanners(scope: CoroutineScope): Deferred<List<Banner>> {
return RxHttp.get("/service/...")
.add("key", "value")
.addHeader("headKey", "headValue")
.toClass<List<Banner>>()
.async(scope) //Note that the async asynchronous operator is used here
}
//Hang up method to get family member information
suspend fun getStudents(scope: CoroutineScope): Deferred<List<Student>> {
return RxHttp.get("/service/...")
.add("key", "value")
.toClass<List<Student>>()
.async(scope) //Note that the async asynchronous operator is used here
}
}In the two hang up methods of the above code, the async asynchronous operator is used. At this time, the two requests send requests in parallel, then get the deferred < T > object, call its await() method, finally get the list of banks and students, and finally directly update the UI.
Focus
Parallel is the same as serial. If one of the requests has an exception, the coroutine will automatically close (close the request at the same time), stop executing the remaining code, and then go to the exception callback. If multiple requests do not affect each other, you can use the onErrorReturn and onErrorReturnItem operators described above to give a default object in case of exception, or use the tryAwait operator to obtain the return value. In case of exception, null is returned, so that the execution of other requests will not be affected.
6. Principle analysis
RxHttp uses the popular Annotation Processing Tool (hereinafter referred to as APT). For example, the well-known Eventbus, ButterKnife, Dagger2, Glide and Jetpack libraries are very easy to use the Room database framework. APT is used. It can retrieve annotation information during compilation and generate Java classes through the javapool framework Methods and other related codes (to generate Kotlin related codes, use kotlinpoet), and therefore achieve zero performance loss at runtime.
So, what advantages does APT bring to RxHttp? How does RxHttp use APT? Keep looking down
Speaking of APT, the first thing that comes to mind may be decoupling. Yes, decoupling is one of its advantages. In fact, it also has a greater advantage, that is, generating different code logic according to the configuration; For example, RxHttp does not rely on RxJava by default, but if you need to send a request using RxHttp + RxJava, you can use RxHttp in the annotation processor Options tab_ The RxJava parameter is used to configure the RxJava large version. RxJava2 or RxJava3 can be passed in. Different codes are generated internally according to the incoming RxJava version. In this way, a set of codes can be used to connect RxJava2 and RxJava3 at the same time. If RxJava4, RxJava5 and other new versions are issued later, they can be compatible and very simple.
In RxHttp v2 In the versions below 4.2, this method is also used to adapt okhttp versions for okhttp compatibility. Therefore, RxHttp adapts okhttp v3 12.0 to v4.0 Any version of 9.0 (the latest version up to December 27, 2020) (except v4.3.0, which has a bug and cannot be adapted). Therefore, there is no need to worry about okhttp version conflict when using RxHttp.
At the same time, it is compatible with different versions of RxJava and OkHttp, which is the first advantage brought by APT to RxHttp.
How does RxHttp use APT? In RxHttp, a total of 6 annotations are defined as follows:
- @DefaultDomain: use it to specify the default baseUrl, which can only be used once
- @Domain: specifies a non default baseUrl, which can be used multiple times
- @Parser: specify a custom parser that can be used multiple times. This is very powerful. You can write your own data parsing logic in the parser and return any type of data, which perfectly solves the problem of non-standard data returned by the server
- @Param: specifies a custom param that can be used multiple times. It is used when sending unified encryption requests
- @OkClient: configure different OkHttpClient objects for different requests, which can be used multiple times
- @Converter: configure different converter objects for different requests, which can be used multiple times
RxHttp compiler is the annotation processor of RxHttp. Its primary task is to generate RxHttp classes. The second task is to retrieve the above six annotations and generate corresponding classes and methods. This enables us to follow the request trilogy when writing the request code no matter how we customize it. If we want to send a unified encrypted request, we can directly use the @ Param annotation generation method, As follows:
//Send an encrypted post form request, and the method name can be arbitrarily specified through the @ Param annotation
val student = RxHttp.postEncryptForm("/service/...")
.add("key", "value")
.toClass<Student>()
.await()The advantages brought by the other five annotations will not be introduced one by one. In short, it is another major advantage, decoupling, so that any request follows the request trilogy
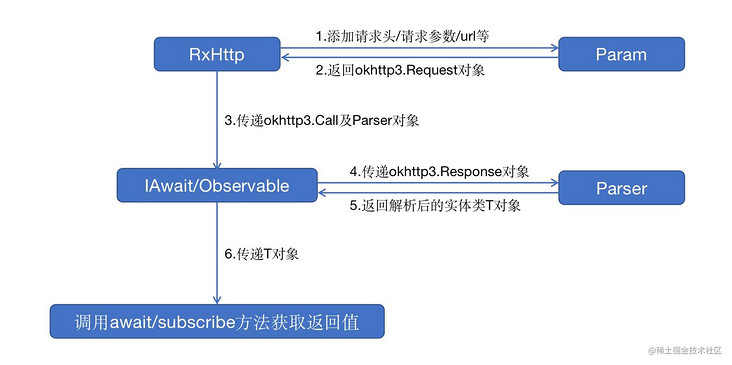
RxHttp workflow
Next, let's talk about the workflow of RxHttp, which has five important roles, namely:
- RxHttp: This is the most important role, so the only entry of the request holds a Param object. Its responsibilities are to process the request parameters / request header / BaseUrl, schedule the request thread, provide the method of annotation generation, etc. the ultimate mission is to build an okhttp3 through Param Request object, and then build an okhttp3 Call object, and throw the call object to Observable or IAwait, and then Observable or IAwait will actually execute the request
- Param: its responsibility is to handle request parameters / request headers / URLs, etc., which are used to build okhttp3 What request needs, the ultimate mission is to build okhttp3 Request object, which is held by RxHttp class. RxHttp builds okhttp3 All the things required by the request object are handed over to param to implement
- IAwiat: the object that actually executes the network request when sending a request in combination with the cooperation process. The specific implementation class is AwaitImpl. It holds the Parser object internally. After the request is returned, it will okhttp3 The response is sent to the Parser for parsing, and the parsed object is returned
- Observable: the object that actually executes the network request when sending the request in combination with RxJava. The specific implementation classes include ObservableCallExecute, ObservableCallEnqueue and ObservableParser, which are respectively used for synchronous request, asynchronous request and okhttp3 after request return For the data parsing of the response object, ObservableParser holds the Parser object internally, and the specific parsing work is left to the Parser
- Parser: it is responsible for data parsing and parsing the data into the data type we want. This is an interface object. There is only onParse(response: Response): T method inside. There are four specific implementation classes: SimpleParser, StreamParser, SuspendStreamParser and BitmapParser. The first is the universal parser, the internal asClass/toClss method, It is through it to achieve; The second and third is the parser used when downloading files. The difference is that the former is downloaded in combination with RxJava and the latter is downloaded in combination with collaborative process; The last one is used to parse Bitmap objects. asBitmap/toBitmap is implemented through it
The work flow chart is as follows:
Related learning video recommendations:
Android advanced system learning -- Gradle introduction and project practice bilibili bilili