Hello, I'm Xiaofu~
I found some interesting tools recently. I can't wait to share them with you.
How do you check Linux logs?
For example, I usually use classic system commands such as tail, head, cat, sed, more and less, or tripartite data filtering tools such as awk, which is very efficient. But one thing that bothers me in the process of using is that there are too many command parameter rules, which makes people's brains ache.
Is there a general way to check the log, such as using SQL query? After all, this is an expression familiar to programmers.
Today's shared tool q enables you to query and count text content by writing SQL. Let's see what's magical about this product.
Set up an environment
q is a command-line tool that allows us to directly execute SQL queries on any file or query results, such as the result set of ps -ef query process command.
The purpose is that the text is the database table, Er ~, of course, this sentence is my own understanding, ha ha ha
It takes ordinary files or result sets as database tables, supports almost all SQL structures, such as WHERE, GROUP BY, JOINS, etc., supports automatic column name and column type detection, and supports cross file connection query. These two are described in detail later and support a variety of codes.
The installation is relatively simple. In Linux CentOS environment, you only need to do it in the following three steps, and in Windows environment, you only need to install an exe.
wget https://github.com/harelba/q/releases/download/1.7.1/q-text-as-data-1.7.1-1.noarch.rpm # download version sudo rpm -ivh q-text-as-data-1.7.1-1.noarch.rpm # install q --version #View installed version
Official documents: harelba.github.io/q
grammar
q supports all SQLiteSQL syntax, standard command line format q + parameter Command + "SQL"
q <command> "<SQL>"
I want to query myfile Log file, directly q "SELECT * FROM myfile.log".
q "SELECT * FROM myfile.log"
q there is no problem in using without additional parameters, but using parameters will make the display result more beautiful, so here's a brief understanding. Its parameters are divided into two types.
Input command: refers to the operation of the file or result set to be queried, such as: - H command, which means that the input data contains the title line.
q -H "SELECT * FROM myfile.log"
In this case, the column name is automatically detected and can be used in the query statement. If this option is not provided, the column is automatically named cX, starting with c1, and so on.
q "select c1,c2 from ..."
- Output command: it is used to query the output result set, such as: - O, and let the query result display the column name.
[root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H "select count(UID) from - where UID='root'" 104 [root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H -O "select count(UID) from - where UID='root'" count(UID) 104
There are many parameters that will not be listed one by one. Interested students can see them on the official website. Next, we will focus on demonstrating how to use SQL to deal with various query logs.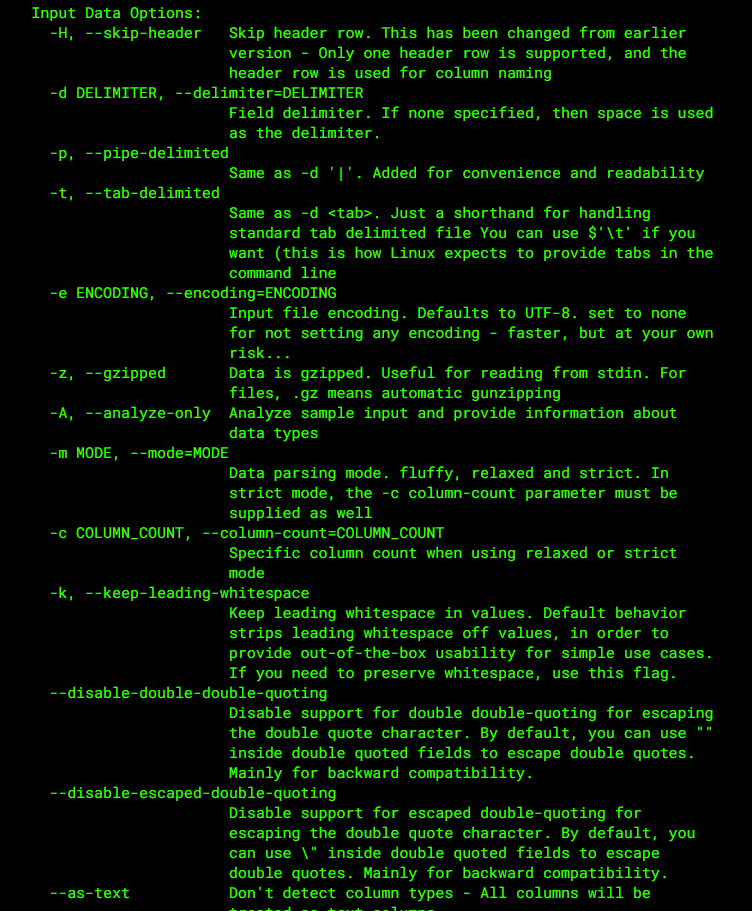
Many thieves play
Next, let's look at how to write this SQL in several common scenarios of query logs.
1. Keyword query
Keyword retrieval should be the most frequently used operation in daily development, but I personally think this q has no advantage, because it must specify a column when querying.
[root@iZ2zebfzaequ90bdlz820sZ software]# q "select * from douyin.log where c9 like '%' to be resolved% '" 2021-06-11 14:46:49.323 INFO 22790 --- [nio-8888-exec-2] c.x.douyin.controller.ParserController : To be resolved URL :url=https%3A%2F%2Fv.douyin.com%2Fe9g9uJ6%2F 2021-06-11 14:57:31.938 INFO 22790 --- [nio-8888-exec-5] c.x.douyin.controller.ParserController : To be resolved URL :url=https%3A%2F%2Fv.douyin.com%2Fe9pdhGP%2F 2021-06-11 15:23:48.004 INFO 22790 --- [nio-8888-exec-2] c.x.douyin.controller.ParserController : To be resolved URL :url=https%3A%2F%2Fv.douyin.com%2Fe9pQjBR%2F 2021-06-11 2
The grep command is full-text retrieval.
[root@iZ2zebfzaequ90bdlz820sZ software]# cat douyin.log | grep 'URL to be resolved' 2021-06-11 14:46:49.323 INFO 22790 --- [nio-8888-exec-2] c.x.douyin.controller.ParserController : To be resolved URL :url=https%3A%2F%2Fv.douyin.com%2Fe9g9uJ6%2F 2021-06-11 14:57:31.938 INFO 22790 --- [nio-8888-exec-5] c.x.douyin.controller.ParserController : To be resolved URL :url=https%3A%2F%2Fv.douyin.com%2Fe9pdhGP%2F
2. Fuzzy query
like fuzzy search: if there is a name in the text content column, it can be retrieved directly with the column name. If there is no name, it can be retrieved directly according to the column numbers c1, c2 and cN.
[root@iZ2zebfzaequ90bdlz820sZ software]# cat test.log abc 2 3 4 5 23 24 25 [root@iZ2zebfzaequ90bdlz820sZ software]# q -H -t "select * from test.log where abc like '%2%'" Warning: column count is one - did you provide the correct delimiter? 2 23 24 25
3. Intersection Union
UNION and UNION ALL operators are supported to take the intersection or UNION of multiple files.
Test is built as follows Log and test1 Log two files, the contents of which overlap, and the union is used for de duplication.
q -H -t "select * from test.log union select * from test1.log" [root@iZ2zebfzaequ90bdlz820sZ software]# cat test.log abc 2 3 4 5 [root@iZ2zebfzaequ90bdlz820sZ software]# cat test1.log abc 3 4 5 6 [root@iZ2zebfzaequ90bdlz820sZ software]# q -H -t "select * from test.log union select * from test1.log" Warning: column count is one - did you provide the correct delimiter? Warning: column count is one - did you provide the correct delimiter? 2 3 4 5 6
4. Content de duplication
For example, count the number of people under a certain path/ clicks. The total number of uuid fields in the CSV file after removing duplicates.
q -H -t "SELECT COUNT(DISTINCT(uuid)) FROM ./clicks.csv"
5. Automatic detection of column type
Note: q will understand whether each column is a number or a string, and judge whether to filter based on real value comparison or string comparison. The - t command will be used here.
q -H -t "SELECT request_id,score FROM ./clicks.csv WHERE score > 0.7 ORDER BY score DESC LIMIT 5"
6. Field operation
Read the system command query results and calculate the total value of each user and group in the / tmp directory. You can perform arithmetic processing on fields.
sudo find /tmp -ls | q "SELECT c5,c6,sum(c7)/1024.0/1024 AS total FROM - GROUP BY c5,c6 ORDER BY total desc" [root@iZ2zebfzaequ90bdlz820sZ software]# sudo find /tmp -ls | q "SELECT c5,c6,sum(c7)/1024.0/1024 AS total FROM - GROUP BY c5,c6 ORDER BY total desc" www www 8.86311340332 root root 0.207922935486 mysql mysql 4.76837158203e-06
7. Data statistics
The first three user ID s with the largest number of processes in the statistical system are sorted in descending order, which needs to be used in conjunction with the system command. Query all processes first, and then use SQL to filter. The q command here is equivalent to the grep command.
ps -ef | q -H "SELECT UID,COUNT(*) cnt FROM - GROUP BY UID ORDER BY cnt DESC LIMIT 3" [root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H "SELECT UID,COUNT(*) cnt FROM - GROUP BY UID ORDER BY cnt DESC LIMIT 3" root 104 www 16 rabbitmq 4 [root@iZ2zebfzaequ90bdlz820sZ software]# ps -ef | q -H -O "SELECT UID,COUNT(*) cnt FROM - GROUP BY UID ORDER BY cnt DESC LIMIT 3" UID cnt root 110 www 16 rabbitmq 4
We see the difference between adding and not adding the - O command is whether to display the title of the query result.
8. Check the documents
Generally, our log file will be divided into many sub files with fixed capacity by day. Without a unified log collection server, if we don't give an error reporting time interval to check a keyword, it's like looking for a needle in a haystack.
If the contents of all files can be merged, it will save a lot of trouble in the query, and q support the joint query of files like database tables.
q -H "select * from douyin.log a join douyin-2021-06-18.0.log b on (a.c2=b.c3) where b.c1='root'"
summary
After reading it, some people may complain: q isn't it fragrant to write so much code and use awk directly? Er ~ the original intention of introducing this tool is not to replace the existing tool, but to provide a more convenient log checking method.
I'm also using awk. It's really powerful. I don't have to say, but it involves a problem of learning cost. There are a wide range of commands and matching rules. If you want to play around, you still need to work hard. For novice programmers who have a little database experience and have little problem writing SQL, it will be much easier to get started q.
Hundreds of various technical e-books were sorted out and sent to our friends. Pay attention to the company's reply [666] and get it by yourself. We have set up a technical exchange group with some partners to discuss technology and share technical materials together in order to learn and progress together. If you are interested, join us!