Preface
I don't know what website I've recently crawled, so I'd like to use the vertical and horizontal web to crawl my favorite snowy knife to practice my hand.
Get ready
- python3
- scrapy
Project creation:
cmd command line switch to working directory to create scrapy project. Two commands scarpy start project and scrapy genspider are used to open the project with pycharm
D:\pythonwork>scrapy startproject zongheng New Scrapy project 'zongheng', using template directory 'c:\users\11573\appdata\local\programs\python\python36\lib\site-packages\scrapy\templates\project', created in: D:\pythonwork\zongheng You can start your first spider with: cd zongheng scrapy genspider example example.com D:\pythonwork>cd zongheng D:\pythonwork\zongheng>cd zongheng D:\pythonwork\zongheng\zongheng>scrapy genspider xuezhong http://book.zongheng.com/chapter/189169/3431546.html Created spider 'xuezhong' using template 'basic' in module: zongheng.spiders.xuezhong
Determine content
First, open the web page and see what we need to crawl.
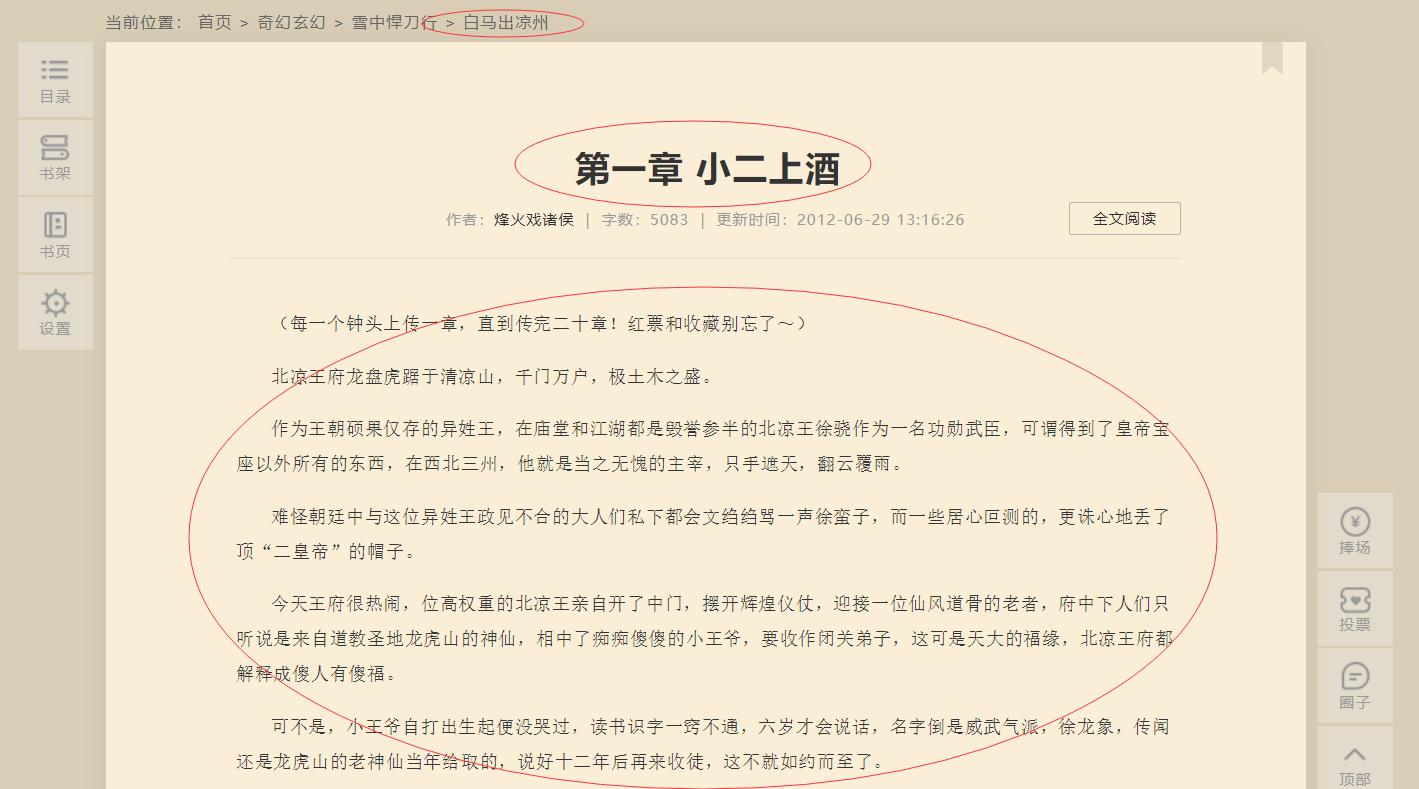
In fact, the discourse structure of the novel is relatively simple, with only three sections.
So items.py code:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ZonghengItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() book = scrapy.Field() section = scrapy.Field() content = scrapy.Field() pass
Content extraction spider file writing
Or do we first create a main.py file to facilitate our testing of the code?
from scrapy import cmdline cmdline.execute('scrapy crawl xuezhong'.split())
Then we can write in the spider file first.
# -*- coding: utf-8 -*- import scrapy class XuezhongSpider(scrapy.Spider): name = 'xuezhong' allowed_domains = ['http://book.zongheng.com/chapter/189169/3431546.html'] start_urls = ['http://book.zongheng.com/chapter/189169/3431546.html/'] def parse(self, response): print(response.text) pass
Run main.py to see if there is any output
It is found that the content of the whole page can be crawled down, which shows that there is no anti-crawling mechanism in this page. We don't even need to modify the user-agent, so let's start directly.
Open page F12 to view element location and write xpath path path, then write spider file
It should be noted that we need to do a certain amount of data cleaning for the content of the novel, because we need to remove some html tags.
# -*- coding: utf-8 -*- import scrapy import re from zongheng.items import ZonghengItem class XuezhongSpider(scrapy.Spider): name = 'xuezhong' allowed_domains = ['book.zongheng.com'] start_urls = ['http://book.zongheng.com/chapter/189169/3431546.html/'] def parse(self, response): xuezhong_item = ZonghengItem() xuezhong_item['book'] = response.xpath('//*[@id="reader_warp"]/div[2]/text()[4]').get()[3:] xuezhong_item['section'] = response.xpath('//*[@id="readerFt"]/div/div[2]/div[2]/text()').get() content = response.xpath('//*[@id="readerFt"]/div/div[5]').get() #content Content needs to be processed because it will be displayed<p></p>Label and<div>Label content = re.sub(r'</p>', "", content) content = re.sub(r'<p>|<div.*>|</div>',"\n",content ) xuezhong_item['content'] = content yield xuezhong_item nextlink = response.xpath('//*[@id="readerFt"]/div/div[7]/a[3]/@href').get() print(nextlink) if nextlink: yield scrapy.Request(nextlink,callback=self.parse)
Sometimes we find that we can't get to the next link, which may be filtered out by allowed_domains and we can modify it.
Alas, I suddenly found more than one hundred chapters in Volume 1 and then we need VIP, so we can only get more than one hundred chapters first, but we can also go to other websites to crawl for free. This time, we will crawl more than one hundred chapters first.
Content preservation
The next step is to save the content. This time, save it directly as a local txt file.
First go to the settings.py file to open ITEM_PIPELINES
Then write pipelines.py file
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html class ZonghengPipeline(object): def process_item(self, item, spider): filename = item['book']+item['section']+'.txt' with open("../xuezhongtxt/"+filename,'w') as txtf: txtf.write(item['content']) return item
Because of the mislocation, we can only crawl more than 100 free chapters, embarrassing, but we can apply analogy to other websites to crawl full-text free books.
How to use scrapy crawl is not very convenient?