preface
Taking crawling github information as an example, this paper introduces the usage of Scrapy framework.
Objective: according to github keyword search, crawl all search results. Specifically, it includes name, link, stars, Updated and About information.
Project creation
Open the Terminal panel and create a project named powang's sketch:
scrapy startproject powang
Enter the created project directory:
cd powang
Create a crawler file named github in the spiders subdirectory:
scrapy genspider github www.xxx.com
Note: the website can be written freely first, and the details will be modified in the document
Execute crawler command:
scrapy crawl spiderName
For example, the execution command of this project is: scratch crawl GitHub
Project analysis and preparation
settings
First, look at the configuration file. Before writing a specific crawler, set some parameters:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Set to display only error type logs
LOG_LEVEL = 'ERROR'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56'
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'powang.middlewares.PowangDownloaderMiddleware': 543,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'powang.pipelines.PowangPipeline': 300,
}
# Set request retry
RETRY_TIMES = 100 # max retries
RETRY_ENABLED = True # Retry on (default on)
RETRY_HTTP_CODES = [500, 503, 504, 400, 403, 408, 429] # Error type of retry
# Download delay
DOWNLOAD_DELAY = 2 # Set the delay for sending requests
RANDOMIZE_DOWNLOAD_DELAY = True # Enable random request delayexplain:
- ROBOTSTXT_OBEY: robots protocol is followed by default. Many websites have this protocol (to prevent crawlers from crawling unnecessary information). Here, for project testing, select close (False)
- LOG_LEVEL: set the log printing level. Here, it is set to print only error type log information. (need to add manually)
- USER_AGENT: add UA information in the request header to skip UA interception. You can also directly configure the UA pool in the middleware (the latter is more recommended)
- DOWNLOADER_MIDDLEWARES: enable download middleware. In middlewars Py (Middleware) will set configurations such as UA pool and IP pool.
- ITEM_ Pipeline: used to enable item configuration. (the role of item will be discussed below)
- Request retry (sweep will automatically initiate a new round of attempts for failed requests):
- RETRY_TIMES: sets the maximum number of retries. After the project is started, if the request cannot succeed within the set number of retries, the project will stop automatically.
- RETRY_ENABLED: Failed Request retry (on by default)
- RETRY_HTTP_CODES: set to initiate a re request operation for a specific error code
- Download delay:
- DOWNLOAD_DELAY: sets the delay for sending requests
- RANDOMIZE_DOWNLOAD_DELAY: set random request delay
- The number of the configuration pipeline and middleware indicates the priority. The smaller the value, the higher the priority.
Crawler file
The default file is as follows:
import scrapy
class GithubSpider(scrapy.Spider):
name = 'github'
allowed_domains = ['www.xxx.com']
start_urls = []
def parse(self, response):
passexplain:
- Name: the name of the crawler file, which is a unique identifier of the crawler source file
- allowed_domains: used to qualify start_ Which URLs in the URLs list can send requests (usually not used)
- start_urls: list of starting URLs. The url stored in the list will be sent automatically by the script (multiple URLs can be set)
- parse: used for data parsing. The response parameter indicates the corresponding response object after the request is successful (and then directly operate the response)
analysis:
Take the search result hexo as an example:
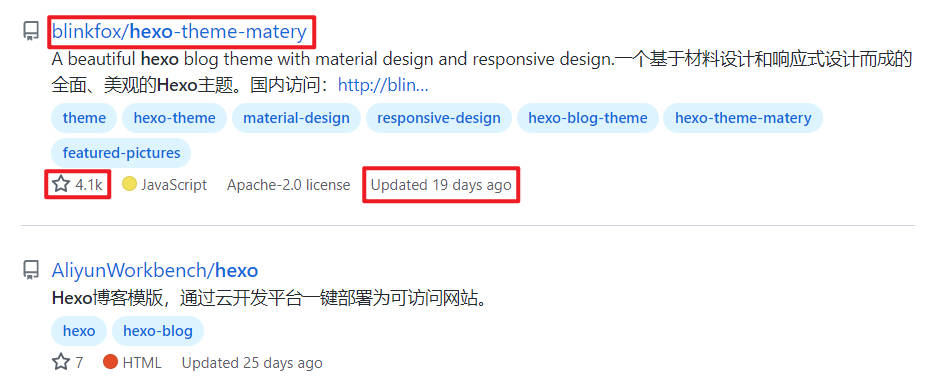
The name and link of each result, stars and Updated can be obtained directly on the search page,
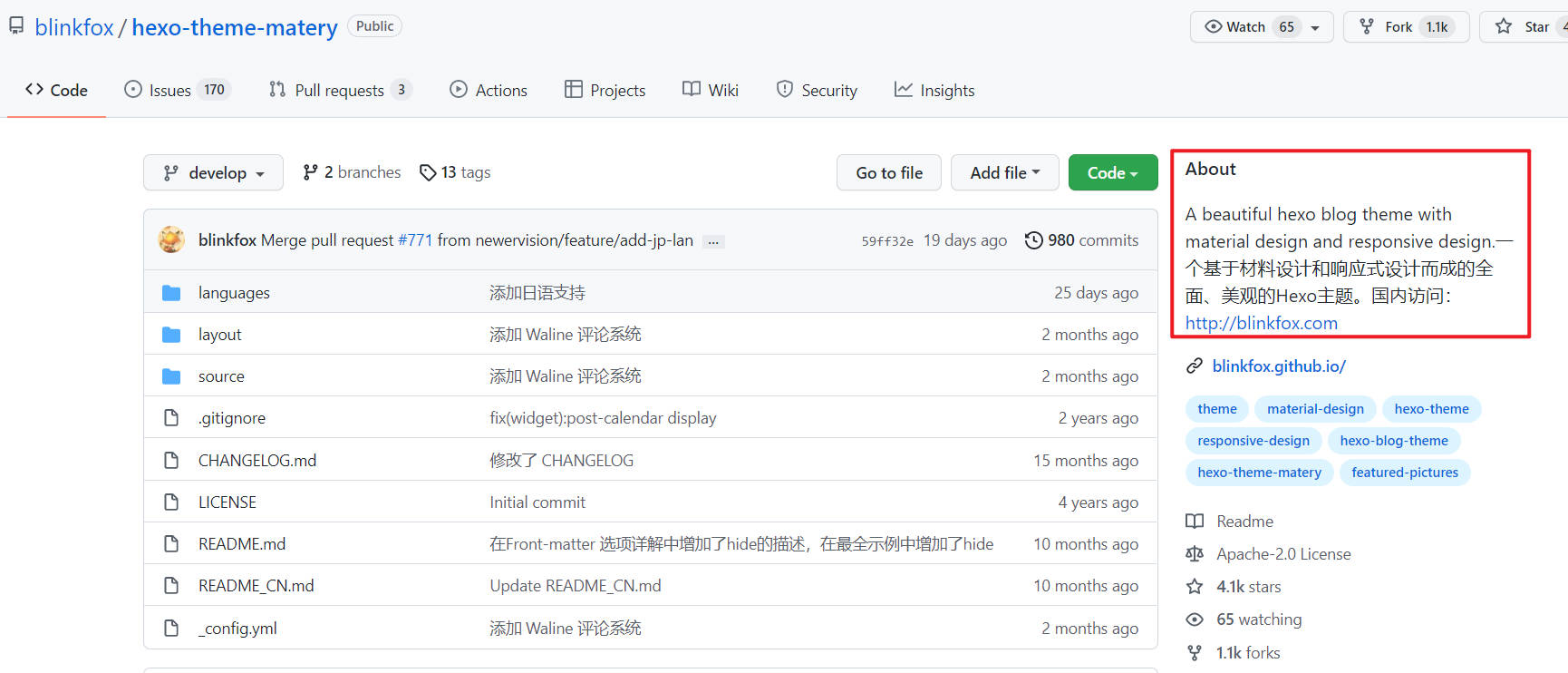
However, some long About information is not fully displayed on the search page, so you have to click the details page to obtain it.
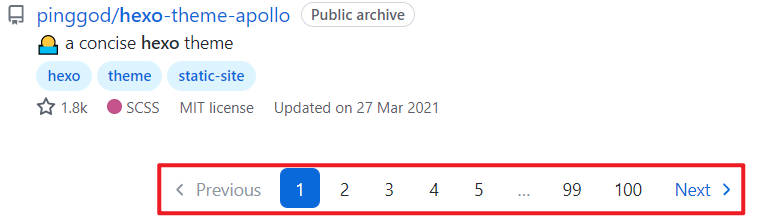
And finally, to crawl all the information, you need to crawl in pages.
Code writing
First, write a starting url and a general url template for paging:
# Search keywords
keyword = 'vpn'
# Number of start pages of query
pageNum = 1
# Start url
start_urls = ['https://github.com/search?q={keyword}&p={pageNum}'.format(keyword=keyword, pageNum=pageNum)]
# Generic url template
url = 'https://github.com/search?p=%d&q={}'.format(keyword)Write parse function (search result page analysis):
def parse(self, response):
status_code = response.status # Status code
#========Data analysis=========
page_text = response.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="js-pjax-container"]/div/div[3]/div/ul/li')
for li in li_list:
# Create item object
item = PowangItem()
# entry name
item_name = li.xpath('.//a[@class="v-align-middle"]/@href')[0].split('/', 1)[1]
item['item_name'] = item_name
# Project link
item_link = 'https://github.com' + li.xpath('.//a[@class="v-align-middle"]/@href')[0]
item['item_link'] = item_link
# Project last updated
item_updated = li.xpath('.//relative-time/@datetime')[0].replace('T', ' ').replace('Z', '')
item_updated = str(datetime.datetime.strptime(item_updated, '%Y-%m-%d %H:%M:%S') + datetime.timedelta(hours=8)) # Chinese time zone
item['item_updated'] = item_updated
# Problems not solved by star s
try:
item_stars = li.xpath('.//a[@class="Link--muted"]/text()')[1].replace('\n', '').replace(' ', '')
item['item_stars'] = item_stars
except IndexError:
item_stars = 0
item['item_stars'] = item_stars
else:
pass
# Request parameter passing: meta = {}. You can pass the meta dictionary to the callback function corresponding to the request
yield scrapy.Request(item_link, callback=self.items_detail,meta={'item':item})
# paging operation
new_url = format(self.url % self.pageNum)
print("===================================================")
print("The first" + str(self.pageNum) + "Page:" + new_url)
print("Status code:" + str(status_code))
print("===================================================")
self.pageNum += 1
yield scrapy.Request(new_url, callback=self.parse)explain:
- response.status: you can get the response status code
- In order to perform further operations (such as storage) on the crawled data in the later stage, each piece of data needs to be encapsulated with an item object
# Create item object item = PowangItem() # .... # encapsulation item['item_name'] = item_name item['item_link'] = item_link item['item_updated'] = item_updated item['item_stars'] = item_stars
- yield:
In order to obtain the About content, you need to access the crawled url to obtain the details page. At this time, you can use yield to send an access request:
Format: yield sweep Request(url, callback=xxx,meta={'xxx':xxx})
yield scrapy.Request(item_link, callback=self.items_detail,meta={'item':item})- url: the url of the details page
- Callback: callback function (you can write other functions or yourself (recursion)). That is, the request is initiated with the url and sent to the callback function for processing, in which the response process information
- meta: in dictionary form, the item object in this function can be handed over to the next callback function for further processing
- Paging operation: use yield to recursively initiate a request to process the data of different pages
Write items_detail function (result detail page analysis):
In order to obtain About information, the detail page of search results needs to be analyzed.
def items_detail(self, response):
# The callback function can receive item s
item = response.meta['item']
page_text = response.text
tree = etree.HTML(page_text)
# Project description
item_describe = ''.join(tree.xpath('//*[@id="repo-content-pjax-container"]/div/div[3]/div[2]/div/div[1]/div/p//text()')).replace('\n', '').strip().rstrip();
item['item_describe'] = item_describe
yield itemexplain:
- Use response Meta ['xxx '] can receive parameters from the previous function (e.g. receive item)
- If the item object is encapsulated after a series of callback function operations, the last function needs to use yield to hand over the item to the pipeline for processing
The complete crawler file is as follows:
import datetime
from lxml import html
etree = html.etree
import scrapy
from powang.items import PowangItem
class GithubSpider(scrapy.Spider):
name = 'github'
keyword = 'hexo' # Search keywords
# Number of start pages of query
pageNum = 1
start_urls = ['https://github.com/search?q={keyword}&p={pageNum}'.format(keyword=keyword, pageNum=pageNum)]
# Generic url template
url = 'https://github.com/search?p=%d&q={}'.format(keyword)
# Parse search result page (Level 1)
def parse(self, response):
status_code = response.status # Status code
#========Data analysis=========
page_text = response.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="js-pjax-container"]/div/div[3]/div/ul/li')
for li in li_list:
# Create item object
item = PowangItem()
# entry name
item_name = li.xpath('.//a[@class="v-align-middle"]/@href')[0].split('/', 1)[1]
item['item_name'] = item_name
# Project link
item_link = 'https://github.com' + li.xpath('.//a[@class="v-align-middle"]/@href')[0]
item['item_link'] = item_link
# Project last updated
item_updated = li.xpath('.//relative-time/@datetime')[0].replace('T', ' ').replace('Z', '')
item_updated = str(datetime.datetime.strptime(item_updated, '%Y-%m-%d %H:%M:%S') + datetime.timedelta(hours=8)) # Chinese time zone
item['item_updated'] = item_updated
# Project stars (solve the problem without star)
try:
item_stars = li.xpath('.//a[@class="Link--muted"]/text()')[1].replace('\n', '').replace(' ', '')
item['item_stars'] = item_stars
except IndexError:
item_stars = 0
item['item_stars'] = item_stars
else:
pass
# Request parameter passing: meta = {}. You can pass the meta dictionary to the callback function corresponding to the request
yield scrapy.Request(item_link, callback=self.items_detail,meta={'item':item})
# paging operation
new_url = format(self.url % self.pageNum)
print("===================================================")
print("The first" + str(self.pageNum) + "Page:" + new_url)
print("Status code:" + str(status_code))
print("===================================================")
self.pageNum += 1
yield scrapy.Request(new_url, callback=self.parse)
# Analyze project details page (Level 2)
def items_detail(self, response):
# The callback function can receive item s
item = response.meta['item']
page_text = response.text
tree = etree.HTML(page_text)
# Project description
item_describe = ''.join(tree.xpath('//*[@id="repo-content-pjax-container"]/div/div[3]/div[2]/div/div[1]/div/p//text()')).replace('\n', '').strip().rstrip();
item['item_describe'] = item_describe
yield itemitem
Before submitting an item to the pipeline, you need to define the following fields:
import scrapy
class PowangItem(scrapy.Item):
item_name = scrapy.Field()
item_link = scrapy.Field()
item_describe = scrapy.Field()
item_stars = scrapy.Field()
item_updated = scrapy.Field()
passexplain: In order to transfer the crawled data to the pipeline for operation in a more standardized way, Scrapy provides us with an Item class. It is more standardized and concise than a dictionary (which is a bit similar to a dictionary).
pipelines
Store the data passed by parse.
import csv
import os
from itemadapter import ItemAdapter
class PowangPipeline:
file = None # file
def open_spider(self,spider):
# File save path
path = './data'
isExist = os.path.exists(path)
if not isExist:
os.makedirs(path)
print("Start crawling and writing files....")
self.file = open(path + '/github.csv','a', encoding='utf_8_sig', newline="")
# Used to process item type objects
# This method can receive the item object submitted by the crawler file
# This method will be called every time it receives an item
def process_item(self, item, spider):
item_name = item['item_name']
item_link = item['item_link']
item_describe = item['item_describe']
item_stars = item['item_stars']
item_updated = item['item_updated']
fieldnames = ['item_name', 'item_link', 'item_describe', 'item_stars', 'item_updated']
w = csv.DictWriter(self.file, fieldnames=fieldnames)
w.writerow(item)
return item
def close_spider(self,spider):
print('End of crawling....')
self.file.close()explain:
- open_spider(): execute only once before the crawler starts (you need to rewrite this method yourself)
- process_item(): used to process the item object passed from parse. This method will be called every time it receives an item
- close_spider(): execute only once after the end of the crawler (you need to rewrite this method yourself)
- Return item: the pipe class can write multiple to perform different operations on the item object passed from parse. The order in which items are passed is the order in which classes are written. You can pass the item object to the next pipeline class to be executed through return item
Here, save the data to the csv file.
middlewares
Middleware can be used to process requests (including abnormal requests).
Pay direct attention to the PowangDownloaderMiddleware class (XXXDownloaderMiddleware):
class PowangDownloaderMiddleware:
# UA pool
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# Proxy IP pool
Proxys=['127.0.0.1:1087']
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
# Intercept request
def process_request(self, request, spider):
# UA camouflage
request.headers['User-Agent'] = random.choice(self.user_agent_list)
# agent
proxy = random.choice(self.Proxys)
request.meta['proxy'] = proxy
return None
# Intercept response
def process_response(self, request, response, spider):
return response
# Intercept requests with exceptions
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)explain:
- process_request(): used to intercept requests. You can set UA or IP and other information Since the project accesses github, the domestic ip is unstable, so the agent (local) is started
- process_response(): used to intercept the response
- process_exception(): used to intercept requests with exceptions
At this point, you can run the project by typing the start command.
Postscript
It's not difficult.
(I forgot the script I learned last year because I kept it on hold and didn't make records. Recently, the project needs to be picked up again)