objective
Write a real crawler, and save the crawled data to txt, json and existing mysql database.
PS note: many people will encounter various problems in the process of learning python. No one can easily give up. For this reason, I have built a python full stack for free answer. Skirt: seven clothes, 977 bars and five (homophony of numbers) can be found under conversion. The problems that I don't understand are solved by the old driver and the latest Python practical course. We can supervise each other and make progress together!
Objective analysis:
This time we are going to climb China weather net: http://www.weather.com.cn/
Click the weather of a city, such as Hefei: http://www.weather.com.cn/weather/101220101.shtml
What we need to climb is the picture: Hefei's seven day forecast:
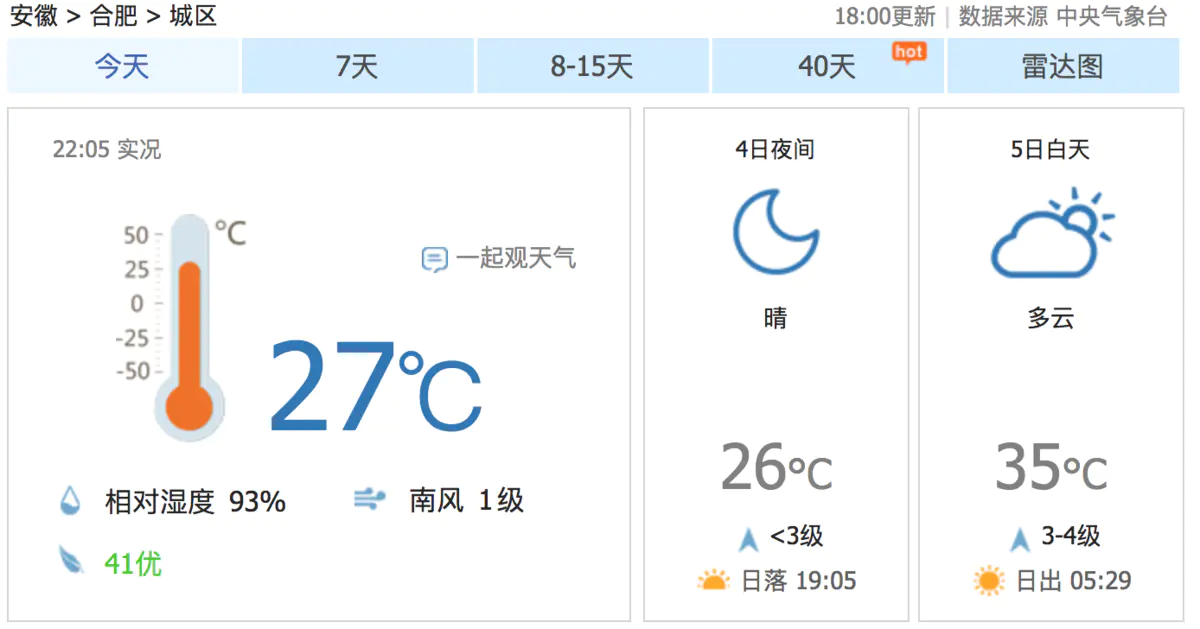
Data filtering:
We use the chrome developer tool to simulate mouse positioning to the corresponding location:
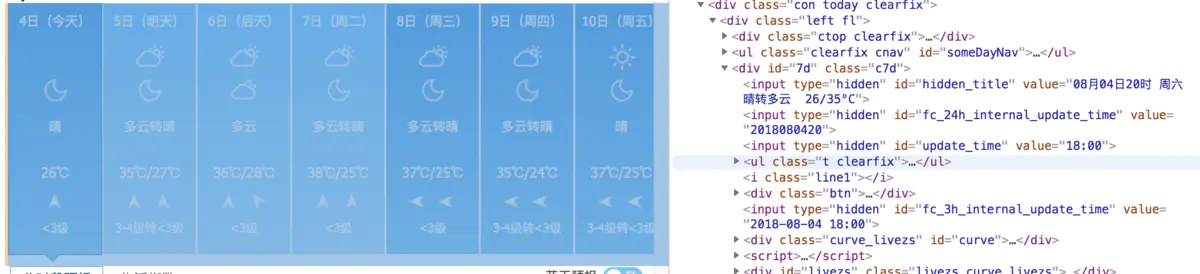
You can see the data we need, all wrapped in
<ul class="t clearfix">
in
We use bs4, xpath, css and other selectors to locate here and filter the data.
Based on the principle of learning new knowledge, the code in this article will use xpath to locate.
Here we can:
response.xpath('//ul[@class="t clearfix"]')
Implementation of the Scrapy framework:
-
To create a scratch project and crawler:
$ scrapy startproject weather $ cd weather $ scrapy genspider HFtianqi www.weather.com.cn/weather/101220101.shtml
In this way, we have finished the preparatory work.
Take a look at the current directory:. ├── scrapy.cfg └── weather ├── __init__.py ├── __pycache__ │ ├── __init__.cpython-36.pyc │ └── settings.cpython-36.pyc ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py └── spiders ├── HFtianqi.py ├── __init__.py └── __pycache__ └── __init__.cpython-36.pyc 4 directories, 11 files -
Write items.py:
This time, let's write items first. It's very simple. Just fill in the field name you want to get:
import scrapy class WeatherItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() date = scrapy.Field() temperature = scrapy.Field() weather = scrapy.Field() wind = scrapy.Field() -
Write Spider:
This part makes the core of our whole reptile!!
The main objectives are:
Send Downloader to our Response to filter data and return it to PIPELINE for processing
Let's look at the code:
# -*- coding: utf-8 -*- import scrapy from weather.items import WeatherItem class HftianqiSpider(scrapy.Spider): name = 'HFtianqi' allowed_domains = ['www.weather.com.cn/weather/101220101.shtml'] start_urls = ['http://www.weather.com.cn/weather/101220101.shtml'] def parse(self, response): ''' //Function to filter information: date = date temperature = Temperature of the day weather = Weather of the day wind = Wind direction of the day ''' # First, create a list to save daily information items = [] # Find the div with weather information day = response.xpath('//ul[@class="t clearfix"]') # Loop through the daily information: for i in list(range(7)): # First apply for a weatheritem type to save the results item = WeatherItem() # Look at the web page and find the data you need item['date'] = day.xpath('./li['+ str(i+1) + ']/h1//text()').extract()[0] item['temperature'] = day.xpath('./li['+ str(i+1) + ']/p[@class="tem"]/i/text()').extract()[0] item['weather'] = day.xpath('./li['+ str(i+1) + ']/p[@class="wea"]/text()').extract()[0] item['wind'] = day.xpath('./li['+ str(i+1) + ']/p[@class="win"]/em/span/@title').extract()[0] + day.xpath('./li['+ str(i+1) + ']/p[@class="win"]/i/text()').extract()[0] items.append(item) return items -
Write PIPELINE:
We know that pipelines.py is used to process the data captured by the finishing crawler,
In general, we store data locally:- Text form: the most basic storage method
- json format: easy to call
- Database: the storage method selected when the data volume is large
TXT (text) format:
import os import requests import json import codecs import pymysql class WeatherPipeline(object): def process_item(self, item, spider): print(item) # print(item) # Get current working directory base_dir = os.getcwd() # The file exists in the weather.txt file under the data directory. The data directory and the txt file need to be established in advance filename = base_dir + '/data/weather.txt' # Open the file by appending from memory and write the corresponding data with open(filename, 'a') as f: f.write(item['date'] + '\n') f.write(item['temperature'] + '\n') f.write(item['weather'] + '\n') f.write(item['wind'] + '\n\n') return itemjson format data:
We want to output json format data. The most convenient thing is to customize a class in PIPELINE:
class W2json(object): def process_item(self, item, spider): ''' //Save crawled information to json //Convenient for other programmers to call ''' base_dir = os.getcwd() filename = base_dir + '/data/weather.json' # Open the json file and inhale the data in the way of dumps # Note that there needs to be a parameter, ensure Υ ASCII = false, otherwise the data will be stored directly in utf encoding mode, such as: "/ xe15" with codecs.open(filename, 'a') as f: line = json.dumps(dict(item), ensure_ascii=False) + '\n' f.write(line) return itemDatabase format (mysql):
Python has good support for all kinds of database operations on the market,
But now mysql, a free database, is commonly used.-
To install mysql locally:
Both linux and mac have powerful package management software, such as apt, brew, etc
Windows can download the installation package directly from the official website.
Since I'm a Mac, I mean the way the MAC is installed.
$ brew install mysql
During the installation, he will ask you to fill in the password of the root user,
root here is not the super user at the system level, but the super user of mysql database.
After installation, mysql service is started by default,
If you restart your computer, you need to start it like this (mac):$ mysql.server start
-
Log in to mysql and create a database for the summary:
# Log in to mysql $ mysql -uroot -p # Create database: ScrapyDB, in utf8 bit encoding format, each statement ends with ';' CREATE DATABASE ScrapyDB CHARACTER SET 'utf8'; # Select the table you just created: use ScrapyDB; # Create the fields we need: the fields should correspond to our code one by one, so that we can write sql statements later CREATE TABLE weather( id INT AUTO_INCREMENT, date char(24), temperature char(24), weather char(24), wind char(24), PRIMARY KEY(id) )ENGINE=InnoDB DEFAULT CHARSET='utf8'
Let's see what the weather table looks like:
show columns from weather //Or: desc weather
-
Install mysql module of Python:
pip install pymysql
Finally, we edit the following code:
class W2mysql(object): def process_item(self, item, spider): ''' //Save the crawled information to mysql ''' # Take out the data in the item date = item['date'] temperature = item['temperature'] weather = item['weather'] wind = item['wind'] # Establish a connection with the local scrapyDB database connection = pymysql.connect( host='127.0.0.1', # Connected to local database user='root', # Own mysql user name passwd='********', # Own password db='ScrapyDB', # Database name charset='utf8mb4', # Default encoding method: cursorclass=pymysql.cursors.DictCursor) try: with connection.cursor() as cursor: # Create sql statement to update value sql = """INSERT INTO WEATHER(date,temperature,weather,wind) VALUES (%s, %s, %s, %s)""" # Execute sql statement # The second parameter of extract can complete the sql default statement, generally in the format of tuple cursor.execute( sql, (date, temperature, weather, wind)) # Submit the record inserted this time connection.commit() finally: # Close connection connection.close() return item
-
Write Settings.py
We need to add our PIPELINE in Settings.py,
It's only when you can runOnly one item in dict format is needed here,
The number value can be customized, and the smaller the number, the higher the priorityBOT_NAME = 'weather' SPIDER_MODULES = ['weather.spiders'] NEWSPIDER_MODULE = 'weather.spiders' ROBOTSTXT_OBEY = True ITEM_PIPELINES = { 'weather.pipelines.WeatherPipeline': 300, 'weather.pipelines.W2json': 400, 'weather.pipelines.W2mysql': 300, } -
Get the project running:
$ scrapy crawl HFtianqi
-
Results:
Text format:

json format:

Database format:

This is the case. It mainly introduces how to save the crawled data in different ways by customizing PIPELINE. Note: many people will encounter all kinds of problems in the process of learning python. No one can easily give up. For this reason, I have built a python full stack for free answer. Skirt: seven clothes, 977 bars and five (homophony of numbers) can be found under conversion. The problems that I don't understand are solved by the old driver and the latest Python practical course. We can supervise each other and make progress together!
The text and pictures of this article come from the Internet and my own ideas. They are only for learning and communication. They have no commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.