1. Understand scratch_ splash?
scrapy_splash is a component of scratch
- The loading of js data by scratch Splash is implemented based on Splash.
- Splash is a Javascript rendering service.
- The final response obtained by using scratch splash is equivalent to the web page source code after the browser is fully rendered.
splash official document Splash - A javascript rendering service — Splash 3.5 documentation
2. scrapy_ The role of splash
Scratch splash can simulate the browser to load js and return the data after js is run.
- splash is similar to selenium and can access the url address in the request object like a browser
- The request can be sent in sequence according to the response content corresponding to the url
- And render the multiple response content corresponding to multiple requests
- Finally, the rendered response object is returned
3. scrapy_splash environment installation
3.1 docker image using splash
dockerfile of splash https://github.com/scrapinghub/splash/blob/master/Dockerfile
Through observation, it is found that the dependency environment of splash is slightly complex, so it is recommended to directly use the docker image of splash. Of course, if you do not want to use the docker image, you can directly refer to the official documentation to install the corresponding environment: https://github.com/scrapinghub/splash/blob/master/Dockerfile
3.1. 1 install and start the docker service
Installation reference: Commodities of Mido Mall (preparing commodity data), Dockers container and FastDFS storage_ CSDN blog, one of the IT little guy's blogs
3.1. 2 get the image of splash
On the basis of correctly installing docker, pull to take the image of splash
sudo docker pull scrapinghub/splash

3.1. 3 verify that the installation is successful
Run splash's docker service and visit port 8050 through the browser to verify whether the installation is successful
-
Run sudo docker run -p 8050:8050 scrapinghub/splash in the foreground
-
Run sudo docker run -d -p 8050:8050 scrapinghub/splash in the background
Visit http://127.0.0.1:8050 If you see the following screenshot, it means success
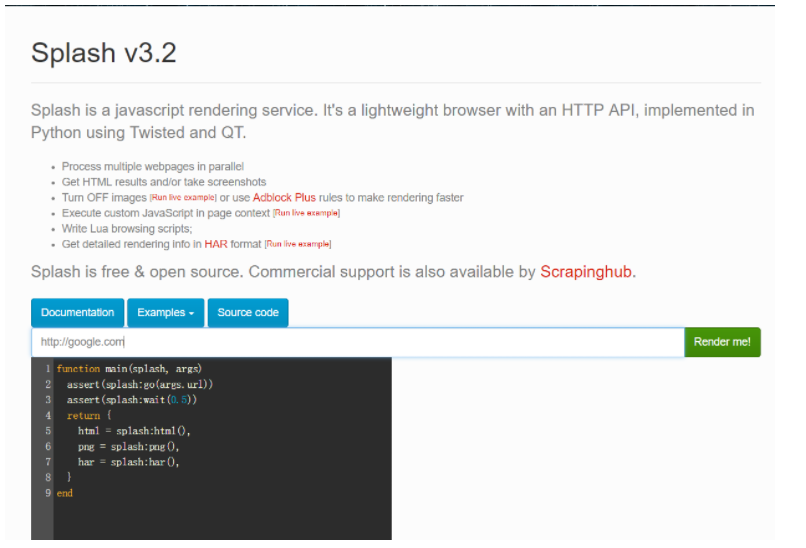
3.1. 4. Solve the timeout of image acquisition: modify the image source of docker
To Ubuntu 18 04 as an example
1. Create and edit the docker configuration file
sudo vi /etc/docker/daemon.json
2. Write to domestic docker CN Save and exit after configuring the image address of com
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
3. Restart the computer or docker service and re acquire the splash image
3.1. 5 close splash service
You need to close the container before deleting it
sudo docker ps -a sudo docker stop CONTAINER_ID sudo docker rm CONTAINER_ID
3.2 installing the scratch splash package in python virtual environment
pip install scrapy-splash
4. Use splash in the sketch
Take baidu as an example:
4.1 create project crawler
scrapy startproject test_splash cd test_splash scrapy genspider no_splash baidu.com scrapy genspider with_splash baidu.com
4.2 improve settings Py profile
In settings Py file to add splash configuration and modify robots protocol
# url of the rendering service
SPLASH_URL = 'http://127.0.0.1:8050'
# Downloader Middleware
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# De duplication filter
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# Http cache using Splash
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
Copy the above code directly to settings Py file
4.3 no splash
In spiders / no_ splash. Perfect in PY
import scrapy
class NoSplashSpider(scrapy.Spider):
name = 'no_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=123456789']
def parse(self, response):
with open('no_splash.html', 'w') as f:
f.write(response.body.decode())
4.4 using splash
import scrapy
from scrapy_splash import SplashRequest # Using scratch_ request object provided by splash package
class WithSplashSpider(scrapy.Spider):
name = 'with_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def start_requests(self):
yield SplashRequest(self.start_urls[0],
callback=self.parse_splash,
args={'wait': 10}, # Maximum timeout in seconds
endpoint='render.html') # Fixed parameters using splash service
def parse_splash(self, response):
with open('with_splash.html', 'w') as f:
f.write(response.body.decode())
4.5 run two reptiles respectively and observe the phenomenon
4.5. 1 run two crawlers separately
scrapy crawl no_splash scrapy crawl with_splash
4.5. 2. Observe the two html files obtained
Do not use splash:
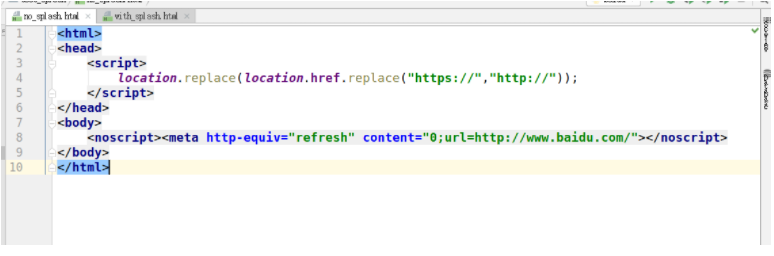
Using splash:
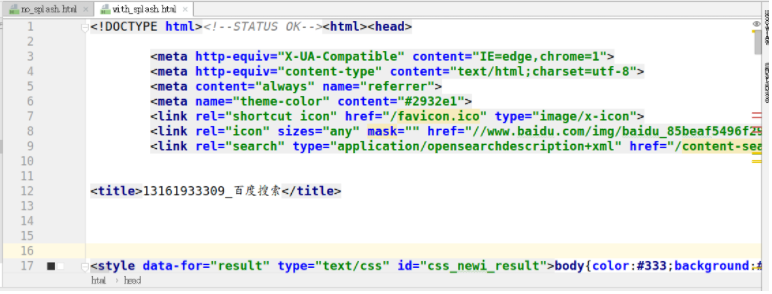
scrapy_ Usage Summary of splash component:
- splash service is required as support
- The constructed request object becomes splash SplashRequest
- It is used in the form of downloading middleware
- Requires a scratch_ Splash specific configuration
Recommended learning links: