Scratch + recruitment website crawler notes
First look at the website to climb: https://sou.zhaopin.com/?jl=719&kw=%E8%8D%AF%E7%89%A9
Objective: to obtain the time, region, city, company, education requirements, experience requirements, salary level and other information of each city
Check the source code. The source code can be extracted with html tags, but there is too little information. Now let's enter the detailed page to extract.

First look at the detailed page. The detailed page only has some required information, and it takes too much time to crawl into each page. Consider capturing bags.
First look at the package. I looked at each package carefully and there was no data. Also used two browsers, none.
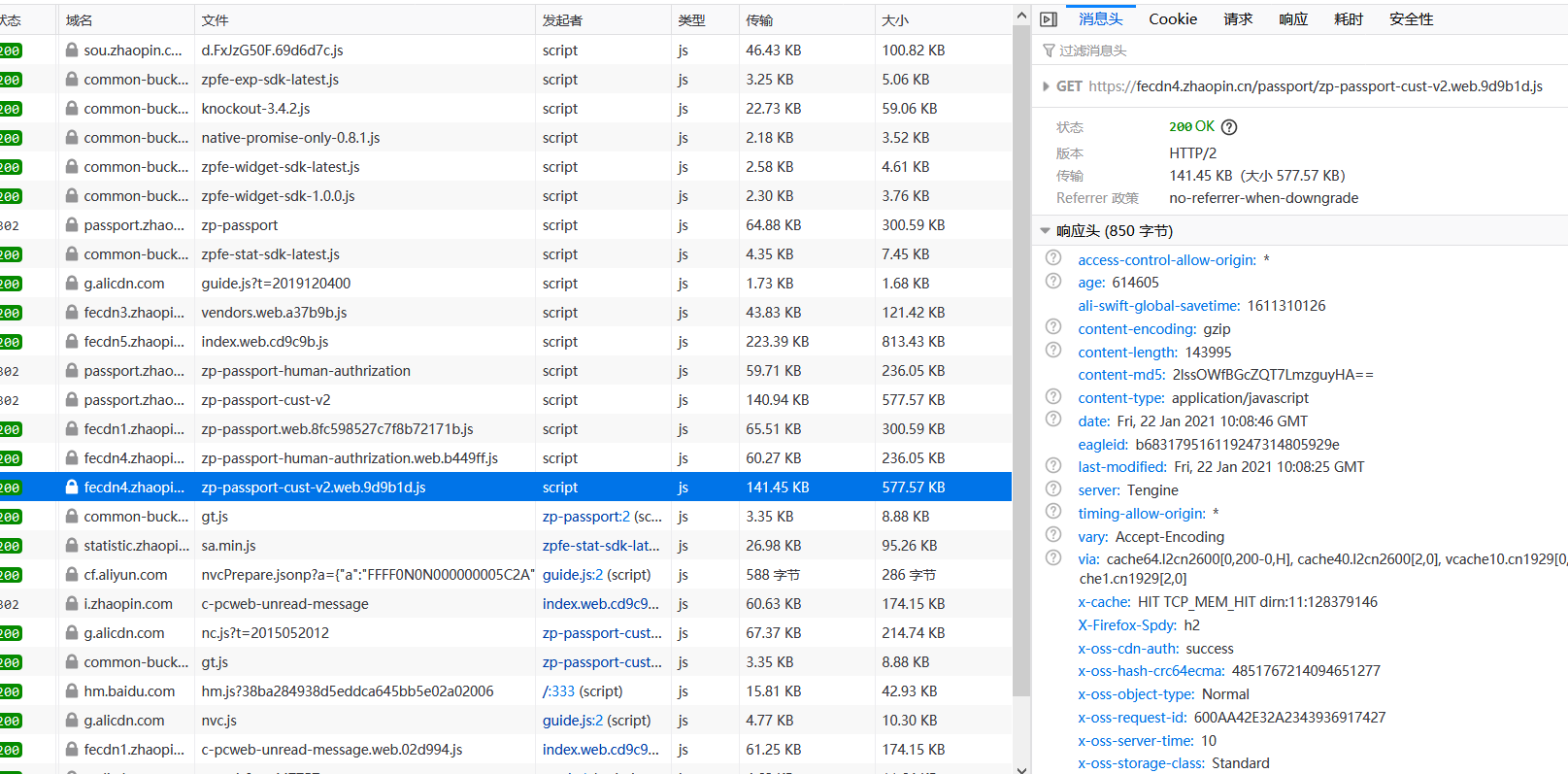
Finally, when I came back to the web page source code, I found that there was data in line 323 and began to try to grab it.

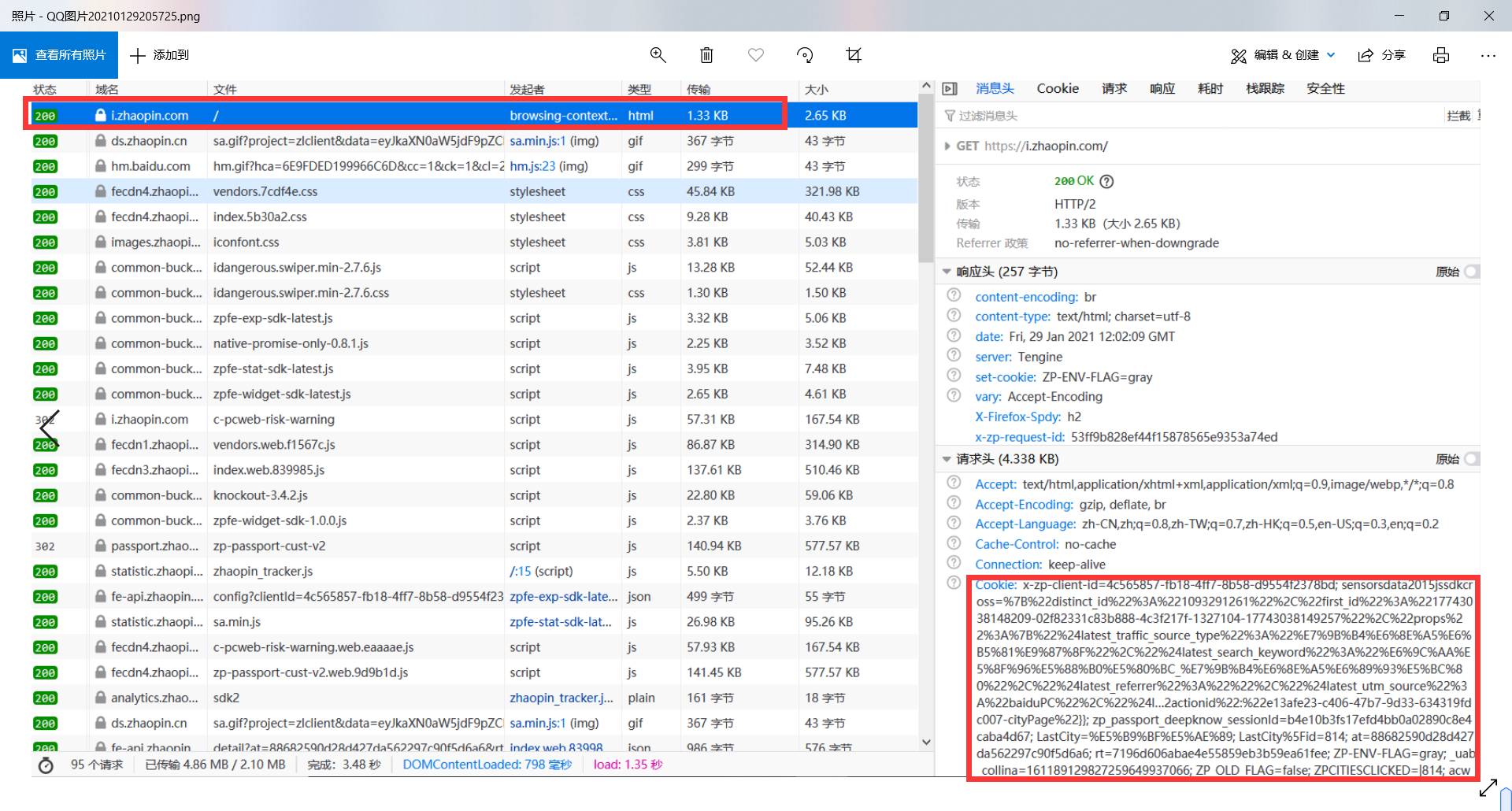
Before crawling, you need to log in. You can't catch it without logging in. I use the cookie after logging in to simulate login. Open F12 to the personal center in the upper right corner, and then the cookie of the first message header can be used
Through the analysis, jl = is followed by the city code and & P = is the page number. In fact, the city code is 501 and up to 949. The page turning part needs to cycle to obtain the hyperlink of each page of each city. The code given is as follows

Set headers, and cookies, and then get a link to each page.
Before using, you need to modify the robots protocol in the python file of settings to get the data
class ZhilianSpider(scrapy.Spider):
name = 'zhilian'
allowed_domains = ['zhaopin.com']
start_urls = ['https://sou.zhaopin.com/?jl={}&p={}']
key = True
def start_requests(self):
# headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
cookies = "x-zp-client-id=4c565857-fb18-4ff7-8b58-d9554f2378bd; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221093291261%22%2C%22first_id%22%3A%2217743038148209-02f82331c83b888-4c3f217f-1327104-17743038149257%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_utm_source%22%3A%22baiduPC%22%2C%22%24l...%2C%22recommandActionidShare%22:%22060e61f3-1a2d-4c37-b982-12157031df14-job%22}%2C%22//www%22:{%22seid%22:%22a0c073c751d247b59151bf0bed24ef21%22%2C%22actionid%22:%22db4a2f68-5db4-49e6-b852-a71265977168-cityPage%22}}; zp_passport_deepknow_sessionId=b4e10b3fs17efd4bb0a02890c8e4caba4d67; LastCity=%E5%B9%BF%E5%AE%89; LastCity%5Fid=814; at=88682590d28d427da562297c90f5d6a6; rt=7196d606abae4e55859eb3b59ea61fee; sts_evtseq=6; sts_sid=1774c354e42412-041f49500590368-4c3f217f-1327104-1774c354e4332a; ZP_OLD_FLAG=false"
cookies = {i.split("=")[0]: i.split("=")[1] for i in cookies.split("; ")}
startCityCode = 501
endCityCode = 949
urls = []
for code in range(startCityCode, endCityCode, 1):
self.key = True
for pages in range(1, 50):
url = self.start_urls[0].format(code, pages)
if self.key == False:
print(1111111,url)
break
else:
yield scrapy.Request(url, cookies=cookies, callback=self.parse)
The crawled source code is messy and needs regular matching. Then use the json library to convert it into a dictionary. By observing the source code, you can use the re module: "{" navigationList ": [" "" to find out the part and end with "< / script >", and then add parentheses to match all the contents in it. Then you can use the json library to convert it into a dictionary
res = response.body.decode()
new = re.findall("({\"navigationList\":.*?)</script>", res)
The above are all countries and regions and HTML tags, but the content is too much to show. Then observe the content and find the red part, which is the detailed content of each occupation in each region.
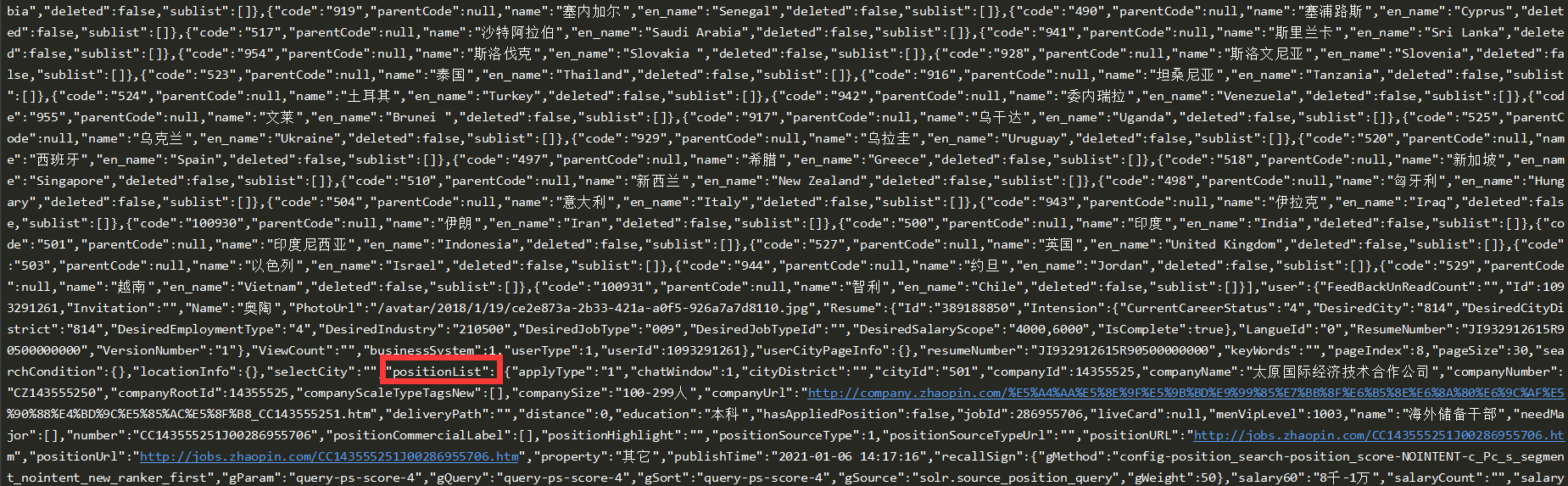
Then I sorted out this part. In the picture, there are 30 information corresponding to 30 positions on one page. By observing the structure, I found that there are all the information I want. The code is shown in the following figure.
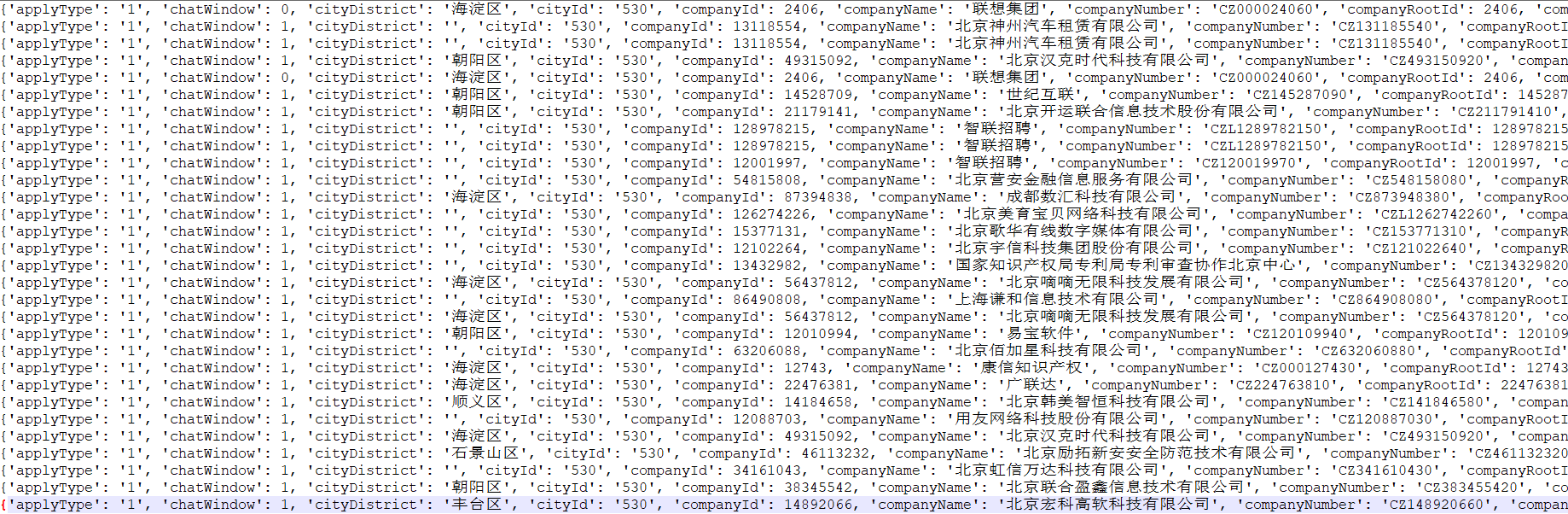
This is the whole content. Finally, the file is stored through the pipeline.
def parse(self, response):
if response.status == 200:
res = response.body.decode()
new = re.findall("({\"navigationList\":.*?)</script>", res)
js = json.loads(new[0])
workInfo = js["positionList"]
# print(len(workInfo))
if len(workInfo) >= 1:
detInfo = []
item = {}
for i in workInfo:
cityDistrict = "Null" if i["cityDistrict"] == "" else i["cityDistrict"] #Urban area
companyName = "Null" if i["companyName"] == "" else i["companyName"] #corporate name
companyUrl = "Null" if i["companyUrl"] == "" else i["companyUrl"] #company website
education = "Null" if i["education"] == "" else i["education"] #Degree requirements
title = "Null" if i["name"] == "" else i["name"] #Job title
positionUrl = "Null" if i["positionUrl"] == "" else i["positionUrl"] #Position URL
publishTime = "Null" if i["publishTime"] == "" else i["publishTime"] #Publication time
salaryReal = "Null" if i["salaryReal"] == "" else i["salaryReal"] #Pay level
workCity = "Null" if i["workCity"] == "" else i["workCity"] #Work city
workType = "Null" if i["workType"] == "" else i["workType"] #Type of work (part-time / full-time)
workingExp = "Null" if i["workingExp"] == "" else i["workingExp"] #hands-on background
welfareLabel = ":".join([i["value"] for i in i["welfareLabel"]]) #fringe benefits
detInfo.append("\t".join(
[title, companyName, workCity,cityDistrict, education, workingExp, salaryReal, welfareLabel, companyUrl,positionUrl, publishTime,
workType, "\n"]))
item["data"] = detInfo
yield item
else:
self.key = False
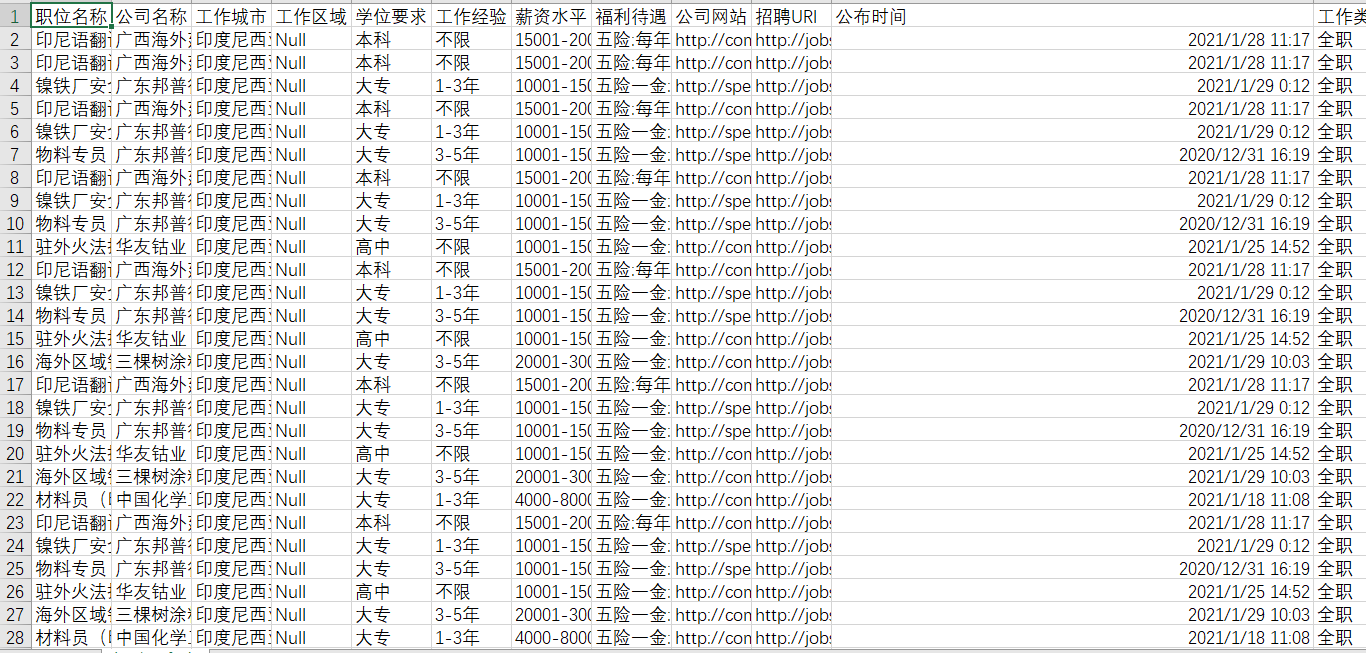
The results are as follows. The Null part is that some occupations have some occupations that do not.
Here are all the codes:
#coding:utf-8
import scrapy
import re
import json
class ZhilianSpider(scrapy.Spider):
name = 'zhilian'
allowed_domains = ['zhaopin.com']
start_urls = ['https://sou.zhaopin.com/?jl={}&p={}']
key = True
def start_requests(self):
# headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
cookies = "x-zp-client-id=4c565857-fb18-4ff7-8b58-d9554f2378bd; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221093291261%22%2C%22first_id%22%3A%2217743038148209-02f82331c83b888-4c3f217f-1327104-17743038149257%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_utm_source%22%3A%22baiduPC%22%2C%22%24l...%2C%22recommandActionidShare%22:%22060e61f3-1a2d-4c37-b982-12157031df14-job%22}%2C%22//www%22:{%22seid%22:%22a0c073c751d247b59151bf0bed24ef21%22%2C%22actionid%22:%22db4a2f68-5db4-49e6-b852-a71265977168-cityPage%22}}; zp_passport_deepknow_sessionId=b4e10b3fs17efd4bb0a02890c8e4caba4d67; LastCity=%E5%B9%BF%E5%AE%89; LastCity%5Fid=814; at=88682590d28d427da562297c90f5d6a6; rt=7196d606abae4e55859eb3b59ea61fee; sts_evtseq=6; sts_sid=1774c354e42412-041f49500590368-4c3f217f-1327104-1774c354e4332a; ZP_OLD_FLAG=false"
cookies = {i.split("=")[0]: i.split("=")[1] for i in cookies.split("; ")}
startCityCode = 501
endCityCode = 949
urls = []
for code in range(startCityCode, endCityCode, 1):
self.key = True
for pages in range(1, 50):
url = self.start_urls[0].format(code, pages)
if self.key == False:
print(1111111,url)
break
else:
yield scrapy.Request(url, cookies=cookies, callback=self.parse)
# urls.append(url)
# for url in urls:
def parse(self, response):
if response.status == 200:
res = response.body.decode()
new = re.findall("({\"navigationList\":.*?)</script>", res)
print(new)
js = json.loads(new[0])
workInfo = js["positionList"]
# print(len(workInfo))
if len(workInfo) >= 1:
detInfo = []
item = {}
for i in workInfo:
cityDistrict = "Null" if i["cityDistrict"] == "" else i["cityDistrict"] #Urban area
companyName = "Null" if i["companyName"] == "" else i["companyName"] #corporate name
companyUrl = "Null" if i["companyUrl"] == "" else i["companyUrl"] #company website
education = "Null" if i["education"] == "" else i["education"] #Degree requirements
title = "Null" if i["name"] == "" else i["name"] #Job title
positionUrl = "Null" if i["positionUrl"] == "" else i["positionUrl"] #Position URL
publishTime = "Null" if i["publishTime"] == "" else i["publishTime"] #Publication time
salaryReal = "Null" if i["salaryReal"] == "" else i["salaryReal"] #Pay level
workCity = "Null" if i["workCity"] == "" else i["workCity"] #Work city
workType = "Null" if i["workType"] == "" else i["workType"] #Type of work (part-time / full-time)
workingExp = "Null" if i["workingExp"] == "" else i["workingExp"] #hands-on background
welfareLabel = ":".join([i["value"] for i in i["welfareLabel"]]) #fringe benefits
detInfo.append("\t".join(
[title, companyName, workCity,cityDistrict, education, workingExp, salaryReal, welfareLabel, companyUrl,positionUrl, publishTime,
workType, "\n"]))
item["data"] = detInfo
yield item
else:
self.key = False
Summary:
At present, I feel that it is not difficult for crawlers to write code, mainly because they have more ability to analyze and process web pages. These two days, they have just received the task of crawlers, and they will go to watch videos immediately, which is also learning and selling now. The main problem encountered is the anti crawler mechanism, which feels strange. Sometimes it can climb to, sometimes it is blocked, and then wait for a few hours or a while. There are three main anti crawling methods on the Internet: first, set user agent, Cookie and other information; second, find IP agent pool and set IP agent pool. This method has less risk but low success rate; third, configure login information yourself to simulate login, which is troublesome but not easy to collapse.