The algorithm from Shang Tang is used for KIE and integrated in mmocr package. It needs to be used together with mmcv. Aside from the topic, mmcv uses hook programming, which is still very difficult to debug. I'll share the framework logic of mmcv when I'm free in the future.
model structure
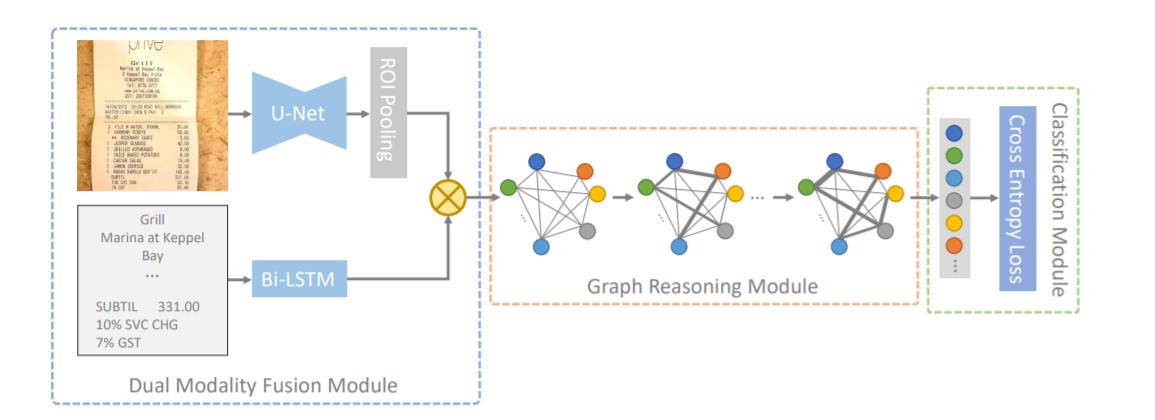
The whole structure can be divided into three modules: dual-mode fusion module, graph reasoning module and classification module.
The input data of the model consists of the picture, the corresponding text detection coordinate area and the text content of the corresponding text area, such as:
{"file_name": "xxxx.jpg", "height": 1191, "width": 1685, "annotations": [{"box": [566, 113, 1095, 113, 1095, 145, 566, 145], "text": "yyyy", "label": 0}, {"box": [1119, 130, 1472, 130, 1472, 147, 1119, 147], "text": "aaaaa", "label": 1}, {"box": [299, 146, 392, 146, 392, 170, 299, 170], "text": "cccc", "label": 2}, {"box": [1447, 187, 1545, 187, 1545, 201, 1447, 201], "text": "dddd", "label": 0},]}
The first is the bimodal fusion module. The visual features are extracted by Unet and ROI pooling, and the semantic features are extracted by Bi LSTM. Then the multi-modal features are fused by Kronecker product, and then input into the spatial multi-modal reasoning model (graph reasoning module) to extract the final node features. Finally, the multi-classification task is carried out through the classification module;
Dual mode fusion module
Detailed steps of visual feature extraction:
- Input the original picture and resize it to a fixed input size (512x512 in this paper);
- Input to Unet and use Unet as the visual feature extractor to obtain the feature map of the last layer of CNN;
- Mapping the text area coordinates () of the input size to the last layer of CNN feature map, and extracting the features through ROI pooling method to obtain the visual features of the corresponding text area image;
Corresponding code:
Location: mmocr \ models \ KIE \ extractors \ sdmgr py
def extract_feat(self, img, gt_bboxes):
if self.visual_modality:
# Visual feature extraction
x = super().extract_feat(img)[-1]
feats = self.maxpool(self.extractor([x], bbox2roi(gt_bboxes)))
return feats.view(feats.size(0), -1)
return None
Unet network: an algorithm for image segmentation
Detailed explanation: Deep understanding of deep learning segmentation net work Unet
Corresponding code location: mmocr \ models \ common \ backbones \ UNET py
ROI Pooling: it is a kind of Pooling layer, and it is aimed at the Pooling of RoIs. Its feature is that the size of the input feature map is not fixed, but the size of the output feature map is fixed.
Detailed explanation: ROI Pooling layer analysis
Detailed steps of text semantic feature extraction:
- Firstly, the character set table is collected. This paper collects 91 length character tables, covering numbers (0-9), letters (A-Z, A-Z), and special character sets of related tasks (such as "/", "n", "and". "), "$", "AC", "," "," ¥ ",": "," - "," * "," # ", etc.), characters not in the character table are uniformly marked as" unkown ";
- Then, the text character content is mapped to the encoding form of one hot semantic input in 32 dimensions;
- Then input it into Bi LSTM model to extract 256 dimensional semantic features;
Corresponding code:
Location: mmocr\models\kie\heads\sdmgr_head.py
def forward(self, relations, texts, x=None):
node_nums, char_nums = [], []
for text in texts:
node_nums.append(text.size(0))
char_nums.append((text > 0).sum(-1))
max_num = max([char_num.max() for char_num in char_nums])
all_nodes = torch.cat([
torch.cat(
[text,
text.new_zeros(text.size(0), max_num - text.size(1))], -1)
for text in texts
])
embed_nodes = self.node_embed(all_nodes.clamp(min=0).long())
rnn_nodes, _ = self.rnn(embed_nodes)
nodes = rnn_nodes.new_zeros(*rnn_nodes.shape[::2])
all_nums = torch.cat(char_nums)
valid = all_nums > 0
nodes[valid] = rnn_nodes[valid].gather(
1, (all_nums[valid] - 1).unsqueeze(-1).unsqueeze(-1).expand(
-1, -1, rnn_nodes.size(-1))).squeeze(1)
Visual + text semantic feature fusion steps:
Multimodal feature fusion: feature fusion is carried out through Kronecker product. The specific formula is as follows:

Corresponding code:
# Block is a custom class in the code. It is estimated that it is the Kronecker product written
self.fusion = Block([visual_dim, node_embed], node_embed, fusion_dim)
# Fusion of image features and text features
if x is not None:
nodes = self.fusion([x, nodes])
Graph reasoning module
In this paper, the document image is treated as a graph, and the final node features are completed through the multimodal graph reasoning model. The formula is as follows:
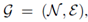


The calculation source code corresponding to the relationship code between nodes is as follows:
# The boxes here are all text boxes in a document. The dimension is [number of text boxes, 8]. 8 is the four coordinate values of the box, from left to right and from top to bottom
def compute_relation(boxes, norm: float = 10.):
"""Compute relation between every two boxes."""
# Get minimal axis-aligned bounding boxes for each of the boxes
# yapf: disable
bboxes = np.concatenate(
[boxes[:, 0::2].min(axis=1, keepdims=True),
boxes[:, 1::2].min(axis=1, keepdims=True),
boxes[:, 0::2].max(axis=1, keepdims=True),
boxes[:, 1::2].max(axis=1, keepdims=True)],
axis=1).astype(np.float32)
# yapf: enable
x1, y1 = boxes[:, 0:1], boxes[:, 1:2]
x2, y2 = boxes[:, 4:5], boxes[:, 5:6]
w, h = np.maximum(x2 - x1 + 1, 1), np.maximum(y2 - y1 + 1, 1)
dx = (x1.T - x1) / norm
dy = (y1.T - y1) / norm
xhh, xwh = h.T / h, w.T / h
whs = w / h + np.zeros_like(xhh)
relation = np.stack([dx, dy, whs, xhh, xwh], -1).astype(np.float32)
# bboxes = np.concatenate([x1, y1, x2, y2], -1).astype(np.float32)
return relation, bboxes
Then, the information between text nodes is embedded into the weight of the edge. According to the following formula, the corresponding source code of this part is mainly located in GNNLayer class
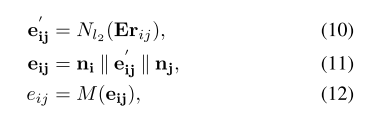
This part mentioned in the paper is mainly to gradually optimize the node characteristics in an iterative way. See formula (13 ~ 14) in the paper for details:
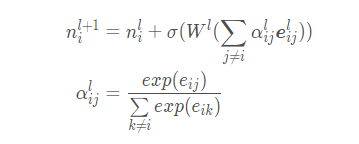
# Graph reasoning module
# Equation 10
all_edges = torch.cat(
[rel.view(-1, rel.size(-1)) for rel in relations])
embed_edges = self.edge_embed(all_edges.float())
embed_edges = F.normalize(embed_edges)
for gnn_layer in self.gnn_layers:
nodes, cat_nodes = gnn_layer(nodes, embed_edges, node_nums)
class GNNLayer(nn.Module):
def __init__(self, node_dim=256, edge_dim=256):
super().__init__()
self.in_fc = nn.Linear(node_dim * 2 + edge_dim, node_dim)
self.coef_fc = nn.Linear(node_dim, 1)
self.out_fc = nn.Linear(node_dim, node_dim)
self.relu = nn.ReLU()
def forward(self, nodes, edges, nums):
start, cat_nodes = 0, []
for num in nums:
sample_nodes = nodes[start:start + num]
cat_nodes.append(
torch.cat([
sample_nodes.unsqueeze(1).expand(-1, num, -1),
sample_nodes.unsqueeze(0).expand(num, -1, -1)
], -1).view(num**2, -1))
start += num
# Formula 11
cat_nodes = torch.cat([torch.cat(cat_nodes), edges], -1)
# Equation 12-13
cat_nodes = self.relu(self.in_fc(cat_nodes))
coefs = self.coef_fc(cat_nodes)
# Equation 14
start, residuals = 0, []
for num in nums:
residual = F.softmax(
-torch.eye(num).to(coefs.device).unsqueeze(-1) * 1e9 +
coefs[start:start + num**2].view(num, num, -1), 1)
residuals.append(
(residual *
cat_nodes[start:start + num**2].view(num, num, -1)).sum(1))
start += num**2
nodes += self.relu(self.out_fc(torch.cat(residuals)))
return nodes, cat_nodes
Multi classification module
This part consists of two Linear layers, one corresponding node and one corresponding edge:
self.node_cls = nn.Linear(node_embed, num_classes)
self.edge_cls = nn.Linear(edge_embed, 2)
# edge_cls shape is [node_num*2,2]
node_cls, edge_cls = self.node_cls(nodes), self.edge_cls(cat_nodes)
Source code:
class SDMGRHead(BaseModule):
def __init__(self,
num_chars=92,
visual_dim=64,
fusion_dim=1024,
node_input=32,
node_embed=256,
edge_input=5,
edge_embed=256,
num_gnn=2,
num_classes=26,
loss=dict(type='SDMGRLoss'),
bidirectional=False,
train_cfg=None,
test_cfg=None,
init_cfg=dict(
type='Normal',
override=dict(name='edge_embed'),
mean=0,
std=0.01)):
super().__init__(init_cfg=init_cfg)
# Text and visual information fusion module
self.fusion = Block([visual_dim, node_embed], node_embed, fusion_dim)
self.node_embed = nn.Embedding(num_chars, node_input, 0)
hidden = node_embed // 2 if bidirectional else node_embed
# Single layer lstm
self.rnn = nn.LSTM(
input_size=node_input,
hidden_size=hidden,
num_layers=1,
batch_first=True,
bidirectional=bidirectional)
# Graph reasoning module
self.edge_embed = nn.Linear(edge_input, edge_embed)
self.gnn_layers = nn.ModuleList(
[GNNLayer(node_embed, edge_embed) for _ in range(num_gnn)])
# Classification module
self.node_cls = nn.Linear(node_embed, num_classes)
self.edge_cls = nn.Linear(edge_embed, 2)
self.loss = build_loss(loss)
def forward(self, relations, texts, x=None):
# Relationship is the relation ship code between nodes. shape is [batch, number of text boxes, number of text boxes, 5], where 5 is fixed and represents the value corresponding to formula 7-9 above
# texts is text information, and shape is [batch, number of text boxes, maximum value of characters in text box]
# x is a graph feature
node_nums, char_nums = [], []
for text in texts:
node_nums.append(text.size(0))
char_nums.append((text > 0).sum(-1))
# The length of the longest text in a batch of data
max_num = max([char_num.max() for char_num in char_nums])
# Perform padding operation
all_nodes = torch.cat([
torch.cat(
[text,
text.new_zeros(text.size(0), max_num - text.size(1))], -1)
for text in texts
])
# Encoded text information
embed_nodes = self.node_embed(all_nodes.clamp(min=0).long())
rnn_nodes, _ = self.rnn(embed_nodes)
nodes = rnn_nodes.new_zeros(*rnn_nodes.shape[::2])
all_nums = torch.cat(char_nums)
valid = all_nums > 0
nodes[valid] = rnn_nodes[valid].gather(
1, (all_nums[valid] - 1).unsqueeze(-1).unsqueeze(-1).expand(
-1, -1, rnn_nodes.size(-1))).squeeze(1)
# Fusion of visual features and text features
if x is not None:
nodes = self.fusion([x, nodes])
# Graph reasoning module
# Encode the edge relationship according to the spatial position relationship between the input two text boxes (important influence)
all_edges = torch.cat(
[rel.view(-1, rel.size(-1)) for rel in relations])
embed_edges = self.edge_embed(all_edges.float())
embed_edges = F.normalize(embed_edges)
for gnn_layer in self.gnn_layers:
# Although the input here is batch, the results of batch are spliced together when outputting
# nodes.shape = [sum(batch_box_num),256]
# cat_nodes.shape = [sum(batch_box_num^2),256]
nodes, cat_nodes = gnn_layer(nodes, embed_edges, node_nums)
# Multi classification module
# node_cls.shape = [sum(batch_box_num),label_num]
# edge_cls .shape = [sum(batch_box_num^2),2]
node_cls, edge_cls = self.node_cls(nodes), self.edge_cls(cat_nodes)
return node_cls, edge_cls
Model application
- It is applicable to documents with relatively fixed layout
- The visual module can be closed. Just declare it in the configuration file
model = dict(
type='SDMGR',
backbone=dict(type='UNet', base_channels=16),
bbox_head=dict(
# Num here_ Chars is a dictionary
type='SDMGRHead', visual_dim=16, num_chars=123, num_classes=23, num_gnn=4),
visual_modality=False, # This parameter controls whether the visual module is used
train_cfg=None,
test_cfg=None,
class_list=f'{data_root}/../class_list.txt')
Ask and answer yourself
- How is the relationship between edges in the dataset initialized?
It is a matrix of [box_num,box_num], which is - 1 except for yourself and yourself, and all others are 1. Source code location: mmocr \ datasets \ KIE_ dataset. List in PY_ to_ Numpy function
if labels is not None:
labels = np.array(labels, np.int32)
edges = ann_infos.get('edges', None)
if edges is not None:
labels = labels[:, None]
edges = np.array(edges)
edges = (edges[:, None] == edges[None, :]).astype(np.int32)
if self.directed:
edges = (edges & labels == 1).astype(np.int32)
np.fill_diagonal(edges, -1)
labels = np.concatenate([labels, edges], -1)
- edge_ The use of PRED?
It is calculated in loss and compared with the edge after initialization_ Gold performs the operation of cross entropy and returns loss_edge and acc_edge, it should be noted that acc_edge does not include the relationship value between itself and itself in the calculation, acc_edge is always 100%, loss_edge takes into account the loss of its relationship with itself, so it is valuable, but relative to loss_ The value of node is very small, and the final loss is loss_node+loss_edge, relevant codes are as follows:
Location: mmocr\models\kie\losses\sdmgr_loss.py
# Subdivision loss reasoning
def forward(self, node_preds, edge_preds, gts):
node_gts, edge_gts = [], []
for gt in gts:
node_gts.append(gt[:, 0])
edge_gts.append(gt[:, 1:].contiguous().view(-1))
node_gts = torch.cat(node_gts).long()
edge_gts = torch.cat(edge_gts).long()
node_valids = torch.nonzero(
node_gts != self.ignore, as_tuple=False).view(-1)
edge_valids = torch.nonzero(edge_gts != -1, as_tuple=False).view(-1)
return dict(
loss_node=self.node_weight * self.loss_node(node_preds, node_gts),
loss_edge=self.edge_weight * self.loss_edge(edge_preds, edge_gts),
acc_node=accuracy(node_preds[node_valids], node_gts[node_valids]),
acc_edge=accuracy(edge_preds[edge_valids], edge_gts[edge_valids]))
Location: mmdet \ models \ detectors \ base PY_ parse_losses function
def _parse_losses(self, losses):
"""Parse the raw outputs (losses) of the network.
Args:
losses (dict): Raw output of the network, which usually contain
losses and other necessary infomation.
Returns:
tuple[Tensor, dict]: (loss, log_vars), loss is the loss tensor \
which may be a weighted sum of all losses, log_vars contains \
all the variables to be sent to the logger.
"""
log_vars = OrderedDict()
for loss_name, loss_value in losses.items():
if isinstance(loss_value, torch.Tensor):
log_vars[loss_name] = loss_value.mean()
elif isinstance(loss_value, list):
log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
else:
raise TypeError(
f'{loss_name} is not a tensor or list of tensors')
# loss addition
loss = sum(_value for _key, _value in log_vars.items()
if 'loss' in _key)
log_vars['loss'] = loss
for loss_name, loss_value in log_vars.items():
# reduce loss when distributed training
if dist.is_available() and dist.is_initialized():
loss_value = loss_value.data.clone()
dist.all_reduce(loss_value.div_(dist.get_world_size()))
log_vars[loss_name] = loss_value.item()
return loss, log_vars