1, Background cache optimization idea
The performance of a website is good or bad, and the impact of network IO and disk IO is relatively large. The purpose of introducing cache now is to improve the performance of the website. In fact, the essence is not to use the disk memory to reduce the disk IO to improve the performance. But have we thought about it? While doing so, we also increase the network operation. Can we also optimize this one.
We can consider the local cache and cache the commodity data into the local cache.
2, Introducing local cache to reduce Redis network IO
2.1 using concurrent HashMap to build local cache
The easiest local cache we can think of is map. Considering concurrency security, we can think of concurrent HashMap.
At this time, the pseudo code of query is implemented as follows:
private Map<String,PmsProductParam> cacheMap = new ConcurrentHashMap<>();
// L1 cache
productInfo = cacheMap.get(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id);
if(productInfo != null){
return productInfo;
}
// Find it from the secondary cache Redis
productInfo = redisOpsUtil.get(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE+id,PmsProductParam.class);
if(productInfo != null){
//Cache to L1 cache
cacheMap.put(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE+id,productInfo);
return productInfo;
}
// Find the query from the database and cache it in redis and local cache (note that the concurrency problem leads to a large number of requests hitting the database, and a distributed lock should be added)
......
Problem analysis:
Using concurrentHashMap can cache data, but if some products are accessed less and less, there is no need to cache at this time. How can I clean up the local cache now?
Some students said that you can use the remove in the map. Can you clear it if you use it directly? Yes, it can be deleted, but how do you know which data is deleted and which data does not need to be deleted? Do you need an algorithm to count the visits, and then select to delete some data according to the sorting. If we want to implement these by ourselves, it is still troublesome to compare prices, so we consider using Google encapsulated tool Guava to realize the function of local cache.
2.2 Guava implements local caching tools
2.2.1 Guava build local cache class
Import dependency:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22</version>
</dependency>
@Slf4j
@Component
public class LocalCache<T> {
private Cache<String,T> localCache = null;
@PostConstruct
private void init(){
localCache = CacheBuilder.newBuilder()
//Sets the initial capacity of the local cache container
.initialCapacity(10)
//Sets the maximum capacity of the local cache
.maximumSize(500)
//Set the number of seconds after write cache expires
.expireAfterWrite(60, TimeUnit.SECONDS).build();
}
// The put method uses reentrantLock to ensure thread safety
public void setLocalCache(String key,T object){
localCache.put(key,object);
}
/***
* Return value returns null if it does not exist
* @param key
* @param <T>
* @return
*/
public <T> T getCache(String key){
return (T) localCache.getIfPresent(key);
}
public void remove(String key){
localCache.invalidate(key);
}
}
2.2.3 code after introducing local cache
Details refer to: seckill system - product details page multi-level cache practice (II): https://blog.csdn.net/qq_43631716/article/details/122309782
@Autowired
private LocalCache cache;
/*
* zk Distributed lock
*/
@Autowired
private ZKLock zkLock;
private String lockPath = "/load_db";
/**
* Obtain product details, distributed lock, local cache and redis cache
*
* @param id Product ID
*/
public PmsProductParam getProductInfo3(Long id) {
PmsProductParam productInfo = null;
// 1. Query product information from local cache
productInfo = cache.get(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id);
if (null != productInfo) {
return productInfo;
}
// 2. Query commodity information from Redis
productInfo = redisOpsUtil.get(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id, PmsProductParam.class);
if (productInfo != null) {
log.info("get redis productId:" + productInfo);
// Set to local cache
cache.setLocalCache(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id, productInfo);
return productInfo;
}
// 3. There is no commodity information in the local cache or Redis. Lock the query database
try {
// If the lock is obtained successfully
if (zkLock.lock(lockPath + "_" + id)) {
productInfo = portalProductDao.getProductInfo(id);
if (null == productInfo) {
return null;
}
// Get data from database
checkFlash(id, productInfo);
log.info("set db productId:" + productInfo);
// Cache data to redis
redisOpsUtil.set(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id, productInfo, 3600, TimeUnit.SECONDS);
// Cache data to local cache
cache.setLocalCache(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id, productInfo);
} else { // If lock acquisition fails
log.info("get redis2 productId:" + productInfo);
// Try to get from Redis
productInfo = redisOpsUtil.get(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id, PmsProductParam.class);
if (productInfo != null) {
// Add to local cache
cache.setLocalCache(RedisKeyPrefixConst.PRODUCT_DETAIL_CACHE + id, productInfo);
}
}
} finally {
log.info("unlock :" + productInfo);
zkLock.unlock(lockPath + "_" + id);
}
return productInfo;
}
private void checkFlash(Long id, PmsProductParam productInfo) {
FlashPromotionParam promotion = flashPromotionProductDao.getFlashPromotion(id);
if (!ObjectUtils.isEmpty(promotion)) {
productInfo.setFlashPromotionCount(promotion.getRelation().get(0).getFlashPromotionCount());
productInfo.setFlashPromotionLimit(promotion.getRelation().get(0).getFlashPromotionLimit());
productInfo.setFlashPromotionPrice(promotion.getRelation().get(0).getFlashPromotionPrice());
productInfo.setFlashPromotionRelationId(promotion.getRelation().get(0).getId());
productInfo.setFlashPromotionEndDate(promotion.getEndDate());
productInfo.setFlashPromotionStartDate(promotion.getStartDate());
productInfo.setFlashPromotionStatus(promotion.getStatus());
}
}
3, Guava implements bloom filter
3.1 Guava construction of Bloom filter
Referring to my previous articles, Redisson can also be used to build Bloom filters, which is simpler to implement: Redis cache design (key and value design) and performance optimization (CACHE breakdown, cache penetration, cache avalanche): https://blog.csdn.net/qq_43631716/article/details/118495104
Storage: bloomfilterconfig#afterpropertieset
@Slf4j
@Configuration
public class BloomFilterConfig implements InitializingBean{
@Autowired
private PmsProductService productService;
@Autowired
private RedisTemplate template;
@Bean
public BloomFilterHelper<String> initBloomFilterHelper() {
return new BloomFilterHelper<>((Funnel<String>) (from, into) -> into.putString(from, Charsets.UTF_8)
.putString(from, Charsets.UTF_8), 1000000, 0.01);
}
/**
* Bloom filter bean injection
* @return
*/
@Bean
public BloomRedisService bloomRedisService(){
BloomRedisService bloomRedisService = new BloomRedisService();
bloomRedisService.setBloomFilterHelper(initBloomFilterHelper());
bloomRedisService.setRedisTemplate(template);
return bloomRedisService;
}
@Override
public void afterPropertiesSet() throws Exception {
List<Long> list = productService.getAllProductId();
log.info("Load the product into the bloom filter,size:{}",list.size());
if(!CollectionUtils.isEmpty(list)){
list.stream().forEach(item->{
//LocalBloomFilter.put(item);
bloomRedisService().addByBloomFilter(RedisKeyPrefixConst.PRODUCT_REDIS_BLOOM_FILTER,item+"");
});
}
}
}
Intercept match: BloomFilterInterceptor
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.util.AntPathMatcher;
import org.springframework.util.PathMatcher;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Map;
@Slf4j
public class BloomFilterInterceptor implements HandlerInterceptor {
@Autowired
private BloomRedisService bloomRedisService;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String currentUrl = request.getRequestURI();
PathMatcher matcher = new AntPathMatcher();
//Parse pathvariable
Map<String, String> pathVariable = matcher.extractUriTemplateVariables("/pms/productInfo/{id}", currentUrl);
//The bloom filter is stored in redis to determine whether the current commodity ID exists in the bloom filter
if(bloomRedisService.includeByBloomFilter(RedisKeyPrefixConst.PRODUCT_REDIS_BLOOM_FILTER,pathVariable.get("id"))){
return true;
}
/**
* In order to optimize, a local bloom filter can be added to reduce network IO
*
* Stored in the local jvm bloom filter
*/
/*if(LocalBloomFilter.match(pathVariable.get("id"))){
return true;
}*/
/*
* If it is not in the local bloom filter, the verification failure is returned directly
* Set response header
*/
response.setHeader("Content-Type","application/json");
response.setCharacterEncoding("UTF-8");
String result = new ObjectMapper().writeValueAsString(CommonResult.validateFailed("Product does not exist!"));
response.getWriter().print(result);
return false;
}
}
For optimization, a local bloom filter can be added to reduce network IO.
Problem summary
1. Will there be multiple interfaces on one server? How to handle multiple different interfaces, such as the commodity id query interface and the order id query interface? Should the interceptor declare multiple Bloom filters for processing when judging? (no, redis is used for storage)
2. How much is the concurrency of 4-core 8G machines suitable (200-500)
3. If there are 10 million commodities, isn't there a redis big key problem in the bloom filter (key does not exist: value)
4, Termination scheme
4.1 current deficiencies - mainly front-end problems
4.1.1 low flow architecture
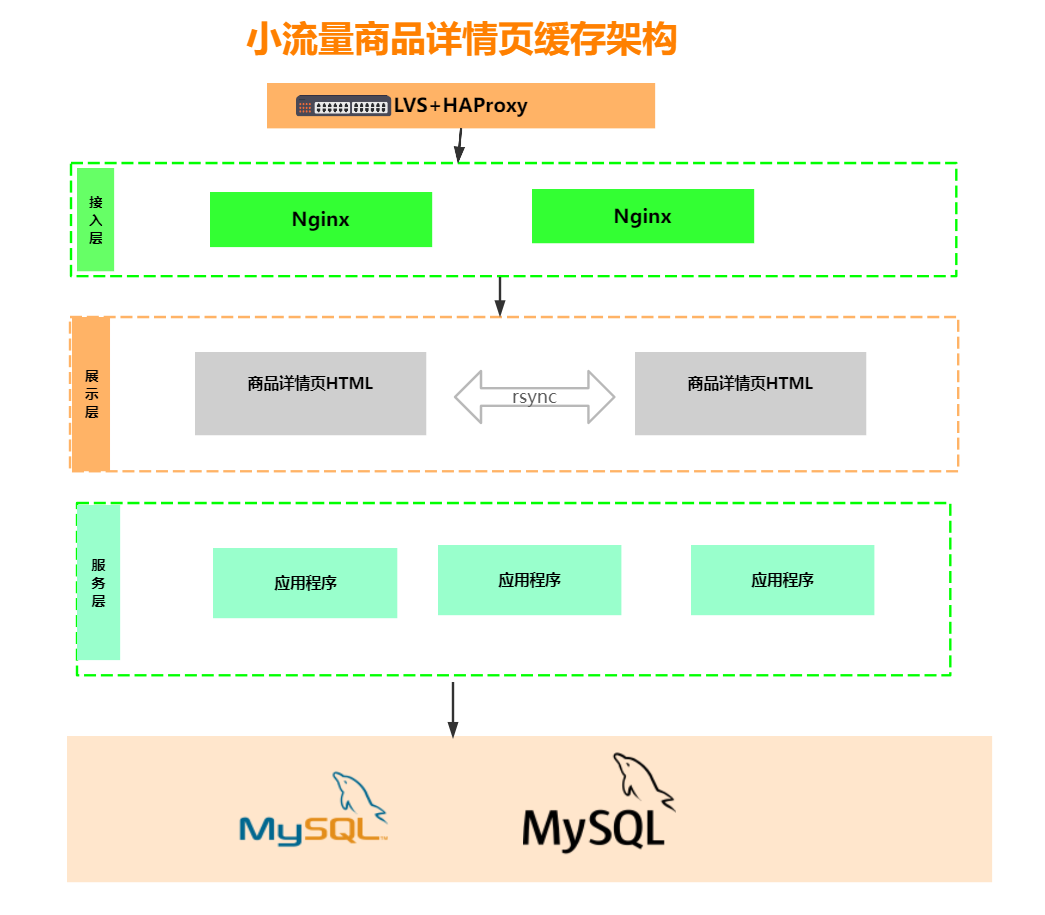
Problem analysis:
What if the background data changes? How to synchronize to other servers in time? How are pages synchronized between services?
If the page is static, we search and open a product details page. How do we know the static page I need to visit?
What if our template needs to be modified?
Pull one and start the whole body.
Therefore, this static technology is not suitable for large traffic architecture.
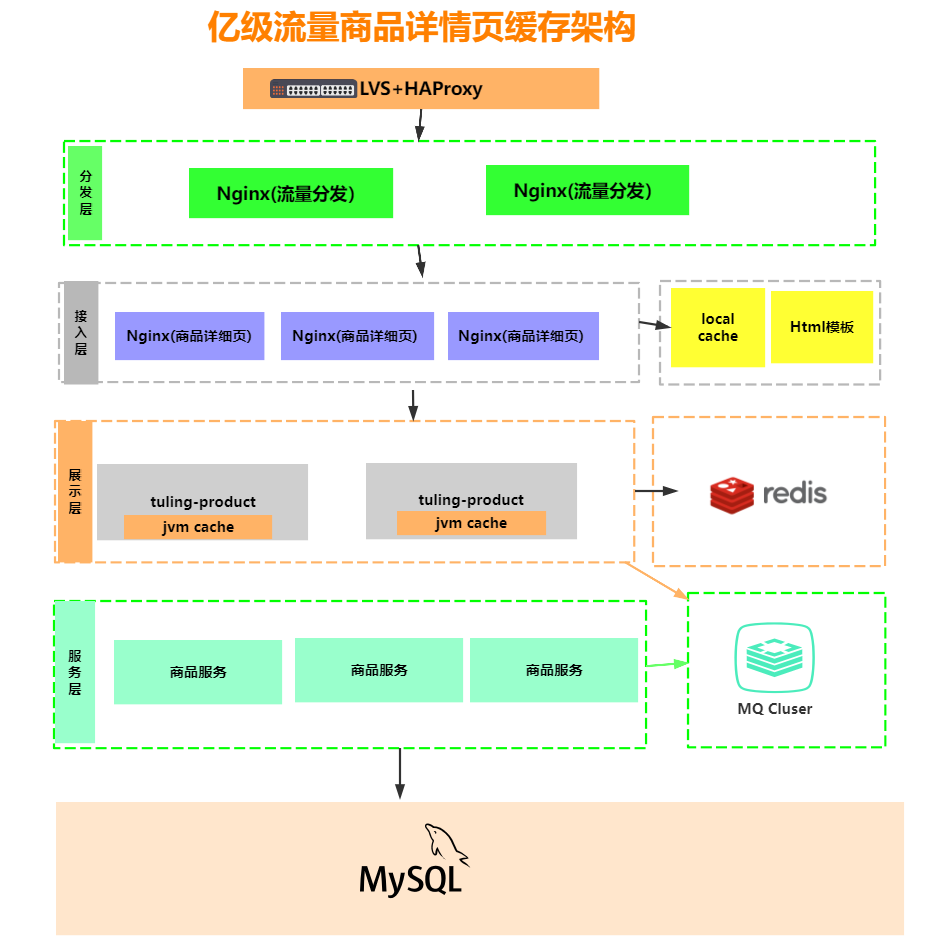
4.1.2 large website architecture
Large site architecture:
4.2 introduction to openresty
Official website address: http://openresty.org/cn/
OpenResty ® Is based on Nginx With Lua's high-performance Web platform, it integrates a large number of sophisticated Lua libraries, third-party modules and most dependencies. It is used to easily build dynamic Web applications, Web services and dynamic gateways that can handle ultra-high concurrency and high scalability.
OpenResty ® By bringing together a variety of well-designed Nginx Module (mainly independently developed by OpenResty team), so as to effectively turn Nginx into a powerful general-purpose Web application platform. In this way, Web developers and system engineers can use Lua script language to mobilize various C and Lua modules supported by Nginx to quickly construct a high-performance Web application system capable of 10K or even 1000K single machine concurrent connection.
OpenResty ® The goal is to make your Web service run directly inside the Nginx service, make full use of the non blocking I/O model of Nginx, and make consistent high-performance responses not only to HTTP client requests, but also to remote backend such as MySQL, PostgreSQL, Memcached and Redis.
4.3 lua demonstration effect
nginx commands required:
taskkill /im nginx.exe /f
4.3.1 actual combat
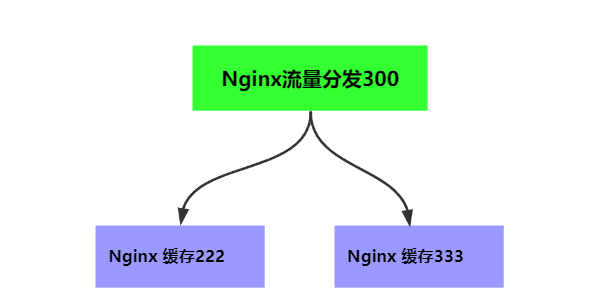
The nginx of traffic distribution will send http requests to the application layer nginx of the backend, so the lua http lib package should be introduced first:
wget https://raw.githubusercontent.com/pintsized/lua‐resty‐http/master/lib/resty/http_headers.lua wget https://raw.githubusercontent.com/pintsized/lua‐resty‐http/master/lib/resty/http.lua
If the network is unstable, you can also start from: https://github.com/bungle/lua-resty-template Download these two lua scripts.
After downloading, put the file under: openresty-1.15.8.2-win642\lualib\resty (openresty-1.15.8.2-win643 should also be put)
4.3.2 operation
In nginx Import lua related packages into the http module in conf:
lua_package_path '../lualib/?.lua;;'; lua_package_cpath '../lualib/?.so;;'; include lua.conf;
Let's take a look at Lua In the conf file:
server {
listen 300;
location /product {
default_type 'text/html;charset=UTF-8';
lua_code_cache on;
content_by_lua_file D:/ProgramData/nginx/dis.lua;
}
}
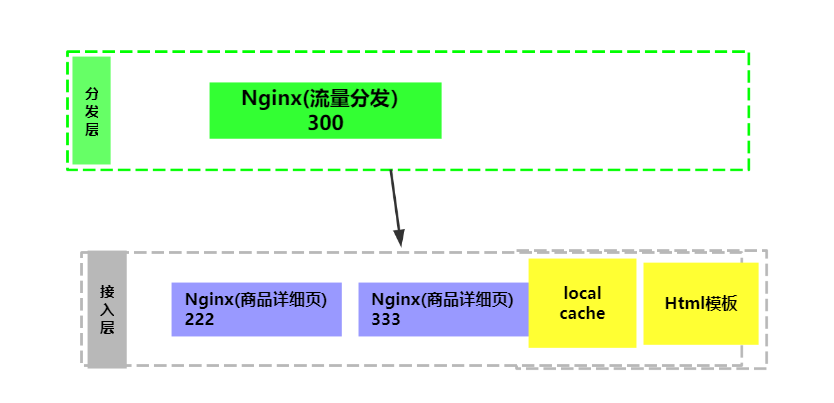
We listen to the port number 300. If the request path is product, we let it contain dis The contents of the Lua file.
And the lua cache is enabled.
Next, let's look at dis Lua script: dis lua
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local host = {"127.0.0.1:222","127.0.0.1:333"}
local hash = ngx.crc32_long(productId)
hash = (hash % 2) + 1
backend = "http://"..host[hash]
local method = uri_args["method"]
local requestBody = "/"..method.."?productId="..productId
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri(backend, {
method = "GET",
path = requestBody,
keepalive=false
})
if not resp then
ngx.say("request error :", err)
return
end
ngx.say(resp.body)
httpc:close()
Look at this file and read the source code. It roughly means to intercept the passed productid, then hash one of the services from the host service I configured, then get the corresponding data through the service request, and then output the data.
Next, let's look at 222 and 333 services. Let's take a look at nginx Conf configuration:
lua_package_path '../lualib/?.lua;;'; lua_package_cpath '../lualib/?.so;;'; include lua.conf;
lua.conf configuration:
lua_shared_dict my_cache 128m;
server {
listen 222;
set $template_location "/templates";
set $template_root "D:/ProgramData/nginx/";
location /product {
default_type 'text/html;charset=UTF-8';
lua_code_cache on;
content_by_lua_file D:/ProgramData/nginx/product.lua;
}
}
Take a look at product lua:
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local productInfo = nil
if productInfo == "" or productInfo == nil then
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri("http://127.0.0.1:8866",{
method = "GET",
path = "/pms/productInfo/"..productId
})
productInfo = resp.body
end
ngx.say(productInfo);
At this time, we can normally access the background and get the data from the background. Then our requests will be requested to the background, which will not work.
Add cache (upgraded): product Lua file:
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local cache_ngx = ngx.shared.my_cache
local productCacheKey = "product_info_"..productId
local productCache = cache_ngx:get(productCacheKey)
if productCache == "" or productCache == nil then
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri("http://127.0.0.1:8866",{
method = "GET",
path = "/pms/productInfo/"..productId
})
productCache = resp.body
local expireTime = math.random(600,1200)
cache_ngx:set(productCacheKey, productCache, expireTime)
end
local cjson = require("cjson")
local productCacheJSON =cjson.decode(productCache)
ngx.say(productCache);
local context = {
id = productCacheJSON.data.id,
name = productCacheJSON.data.name,
price = productCacheJSON.data.price,
pic = productCacheJSON.data.pic,
detailHtml = productCacheJSON.data.detailHtml
}
local template = require("resty.template")
template.render("product.html", context)
Join the cache. Now let's look at the running effect.
html template:
<html>
<head>
<meta http‐equiv="Content‐Type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>
commodity id: {* id *}<br/>
Trade name: {* name *}<br/>
commodity price: {* price *}<br/>
Commodity inventory: <img src={* pic *}/><br/>
Product description: {* detailHtml *}<br/>
</h1>
</body>
</html>
4.4 summary
Data hotspot
Tier 3 cache:
- lua+nginx: the amount of data is small and the number of visits is relatively high
- jvm local cache: the data volume is large and the access volume is relatively high
- redis: the data is relatively large and the number of visits is relatively low
LRU algorithm: Hottest data cache
Lru-k (linked list K): the hottest data recently is very hot, and it has been accessed for more than 3 consecutive times
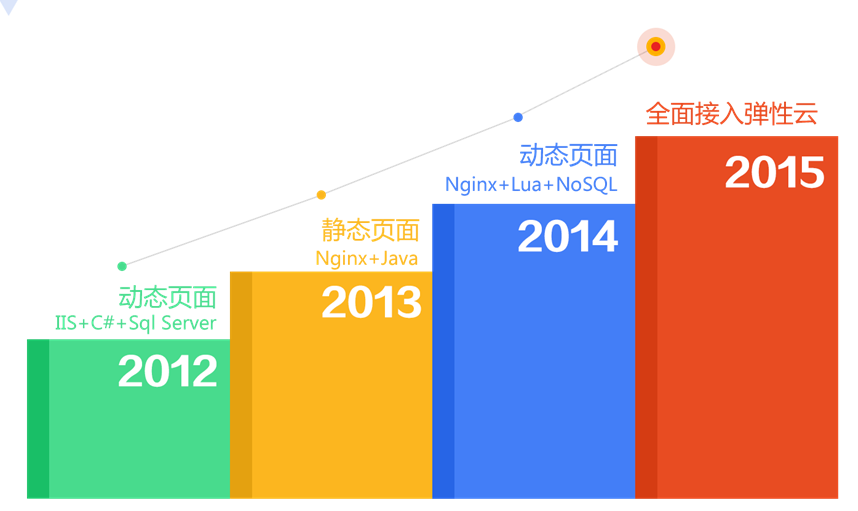
5, Jingdong architecture evolution analysis
Architecture 1.0
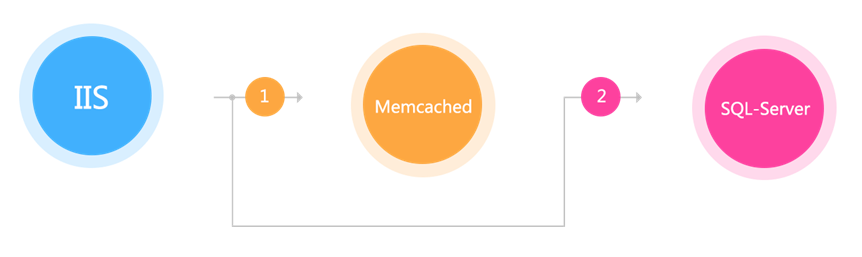
IIS+C#+Sql Server, the most original architecture, directly calls the commodity library to obtain the corresponding data. When it can't carry it, a layer of memcached is added to cache the data. This approach is often subject to performance jitter caused by the instability of dependent services.
Note: the cache is added, but the problem is limited by the cache server and is unstable.
Architecture 2.0
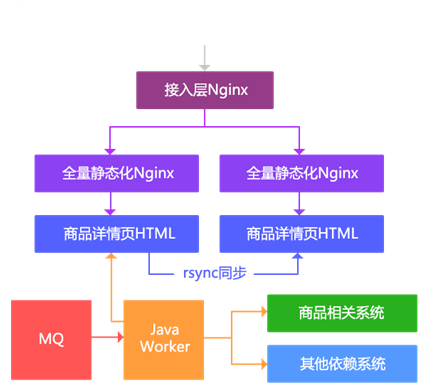
The scheme uses static technology to generate static HTML according to the commodity dimension. Main ideas:
1. Get change notice through MQ;
2. Call multiple dependent systems through Java Worker to generate detail page HTML;
3. Synchronize to other machines through rsync;
4. Output static pages directly through Nginx;
5. The access layer is responsible for load balancing.
Note: the main disadvantages of this scheme are:
1. Assuming that only the classification and template have been changed, all relevant commodities should be repainted;
2. With the increase of commodity quantity, rsync will become a bottleneck;
3. Unable to quickly respond to some page requirements changes, most of them are dynamically changing page elements through JavaScript.
With the increase of the number of goods, the storage capacity of this architecture has reached the bottleneck, and the problem of generating the whole page according to the commodity dimension is that if the classification dimension changes, we have to brush all the information under this classification. Therefore, we have transformed a version to route to multiple machines according to the tail number.
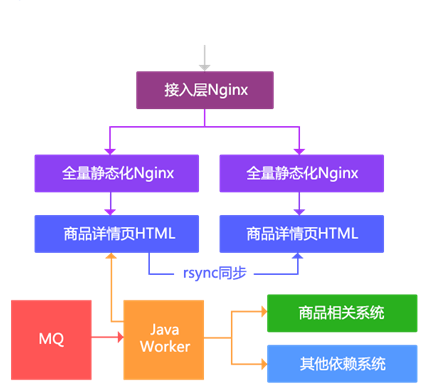
Main ideas:
1. The capacity problem is distributed to multiple machines by routing according to the tail number of goods, a single machine according to self operated goods, and 11 third-party goods according to the tail number;
2. Generate HTML fragments by dimension (framework, product introduction, specification parameters, bread crumbs, relevant classification and store information), rather than a large HTML;
3. Merge fragment output through Nginx SSI;
4. The access layer is responsible for load balancing;
5. Multi machine room deployment cannot be synchronized through rsync, but is implemented by deploying multiple sets of the same architecture.
The main disadvantages of this scheme are as follows:
1. There are too many fragmented files to rsync;
2. During SSI consolidation of mechanical disks, the performance is poor when the concurrency is high. At this time, we have not tried to use SSD;
3. If the template needs to be changed, hundreds of millions of goods need several days to be painted;
4. When we reach the capacity bottleneck, we will delete some static commodities, and then output them through dynamic rendering. The dynamic rendering system will lead to high pressure on the dependent system at the peak;
5. Still unable to respond quickly to some business needs.
Our pain points:
1. There is a capacity problem with the previous architecture. It will soon appear that it can not be fully static, but still needs dynamic rendering; However, for full static, this problem can be solved through distributed file system, which has not been tried;
2. The main problem is that with the development of business, it can not meet the rapidly changing and abnormal needs.
Architecture 3.0
Problems to be solved:
1. Can quickly respond to transient needs and various abnormal needs;
2. Support various vertical page revision;
3. Page modularization;
4. AB test;
5. High performance and horizontal expansion;
6. Multi machine room and multi activity, multi activity in different places.
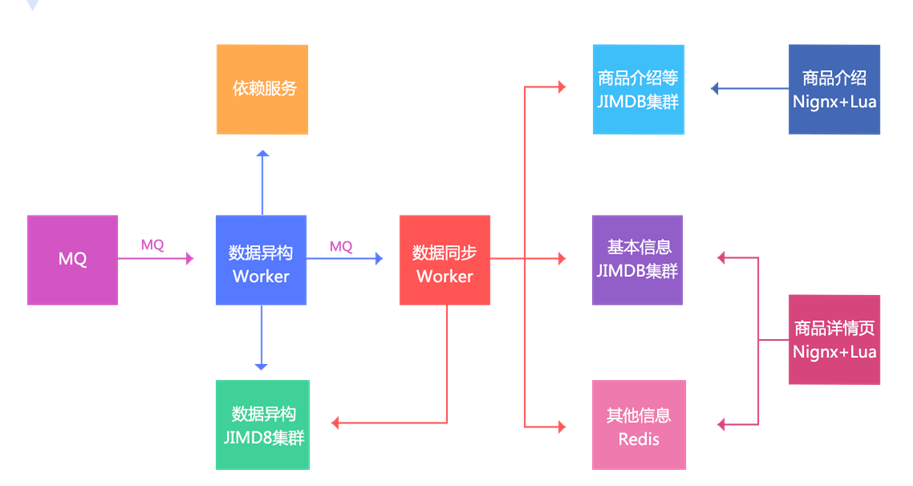
Main ideas:
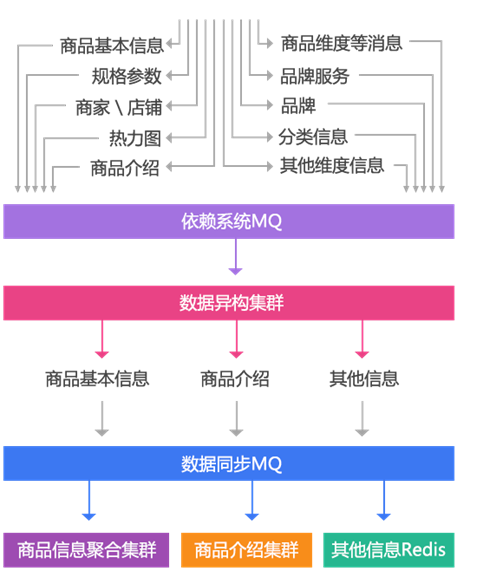
1. Data change or notification through MQ;
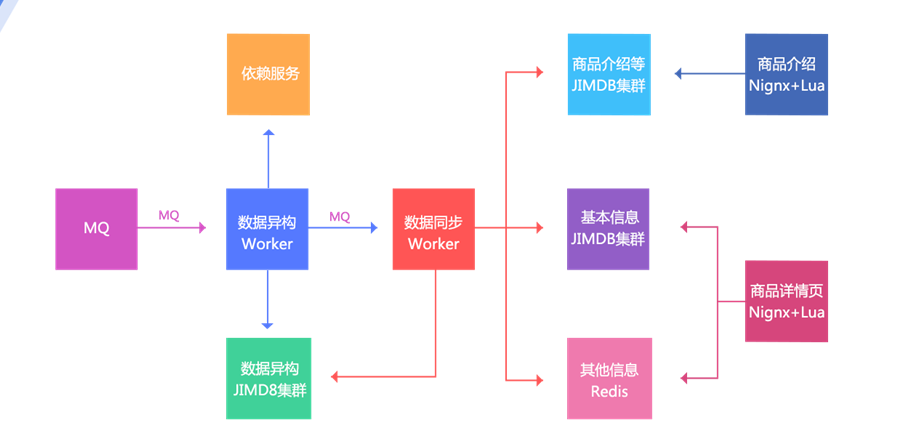
2. The data heterogeneous Worker is notified, and then stores the data according to some dimensions in the data heterogeneous JIMDB cluster (JIMDB: Redis + persistence engine). The stored data are unprocessed atomic data, such as commodity basic information, commodity extended attributes, other relevant information of commodities, commodity specification parameters, classification, merchant information, etc;
3. After the heterogeneous data Worker is successfully stored, it will send an MQ to the data synchronization Worker. The data synchronization Worker can also be called the data aggregation Worker, which aggregates the data according to the corresponding dimensions and stores it in the corresponding JIMDB cluster; Three dimensions: basic information (an aggregation of basic information + extended attributes), product introduction (PC version and mobile version), and other information (classification, merchant and other dimensions, with small amount of data and direct Redis storage);
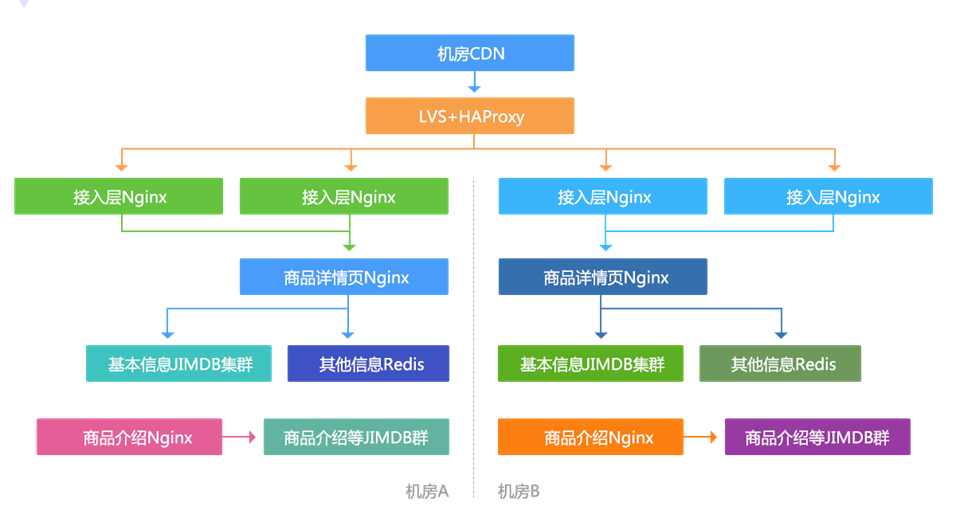
4. The front-end display is divided into two parts: product details page and product introduction. It uses Nginx+Lua technology to obtain data and render template output.
In addition, the goal of our current architecture is not only to provide data for the commodity details page, but also to provide services as long as it is obtained by key value rather than relationship. We call it dynamic service system.
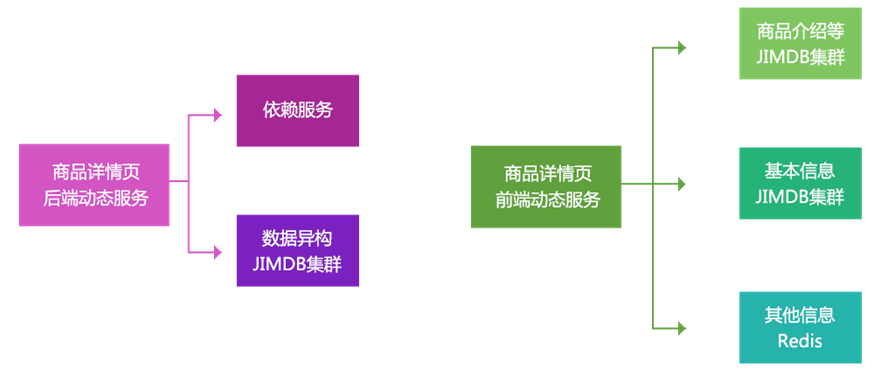
The dynamic service is divided into front-end and back-end, that is, public network or intranet. For example, at present, the dynamic service provides corresponding data for list page, commodity comparison, wechat single product page, general agent, etc. to meet and support its business.
Architecture principles
Data closed loop: that is, the self-management of data, or the maintenance of data in their own system, independent of any other system and de dependent; The advantage of this is that others have nothing to do with me.
Data heterogeneity: it is the first step of data closed loop. Take the data of each dependent system and store it according to your own requirements;
Data atomization: heterogeneous data is atomized data, so that we can reprocess and reprocess these data in response to changing needs in the future;
Data aggregation: aggregate multiple atomic data into one large JSON data, so that the front-end display only needs one get. Of course, the system architecture should be considered. For example, the Redis transformation we use, and Redis is a single threaded system. We need to deploy more Redis to support higher concurrent development. In addition, the stored value should be as small as possible;
Data storage: we use JIMDB and Redis supported long-term storage engine, which can store more than N times the amount of data in memory. At present, some of our systems are stored by Redis+LMDB engine, which is currently stored together with SSD; In addition, we use the Hash Tag mechanism to hash the relevant data to the same partition, so that there is no need to merge across partitions in mget.
Our current heterogeneous data time key value structure is used to query by commodity dimension, and a set of heterogeneous time relational structure is used for relational query.
Detailed page architecture design principles / data Dimensionalization
Data should be dimensionalized according to dimensions and functions, so that it can be stored separately and used more effectively. The dimension of our data is relatively simple:
1. Basic information of goods, title, extended attributes, special attributes, pictures, colors, sizes, specifications, etc;
2. Commodity introduction information, commodity dimension, merchant template, commodity introduction, etc;
3. Other information of non commodity dimension, such as classification information, merchant information, store information, store header, brand information, etc;
4. Other information of commodity dimension (asynchronous loading), price, promotion, distribution to, advertising words, recommended accessories, best combination, etc.
Split system
Splitting the system into multiple subsystems increases the complexity, but it can get more benefits. For example, the data stored in heterogeneous data systems is atomized data, which can provide services according to some dimensions; The data synchronization system stores aggregated data, which can provide high-performance reading for front-end display. The front-end display system is separated into commodity details page and commodity introduction, which can reduce the interaction; At present, the commodity introduction system also provides some other services, such as the whole site asynchronous footer service.
Multilevel cache optimization
Browser cache: when pages jump back and forth, go to local cache, or open the page with last modified to CDN to verify whether it is expired, so as to reduce the amount of data transmitted back and forth;
CDN cache: users go to the nearest CDN node to get data, instead of going back to the Beijing computer room to get data, so as to improve access performance;
Server side application local cache: we use Nginx+Lua architecture and use the shared dict Of HttpLuaModule module as local cache (reload is not lost) or memory level Proxy Cache, so as to reduce bandwidth;
In addition, we also use consistent hash (such as commodity number / classification) for load balancing, and rewrite the URL internally to improve the hit rate;
We have optimized mget, such as removing other dimension data of goods, classification, bread crumbs, merchants, etc. if the performance of mget is poor and the amount of data is large, more than 30KB; There is no problem caching these data for half an hour. Therefore, we design to read the local cache first, and then return the missed data to the remote cache for acquisition. This optimization reduces the remote cache traffic by more than half;
Server distributed cache: we use memory + SSD+JIMDB persistent storage.
Dynamic
Dynamic data acquisition, commodity details page: obtain data by dimension, commodity basic data and other data (classification, merchant information, etc.); Moreover, we can make logic on demand according to the data attributes. For example, virtual goods need their own customized details page, so we can jump to jd.com, for example, for global purchases HK domain name, then there is no problem;
Template rendering is real-time and supports changing template requirements at any time;
Restart the application in seconds. Using the Nginx+Lua architecture, the restart speed is fast and the shared dictionary cache data is not lost;
Online speed is required, because we use the Nginx+Lua architecture, which can quickly go online and restart applications without jitter; In addition, Lua itself is a scripting language. We are also trying to version and store the code, and directly internally drive Lua code update online without restarting Nginx.
Elasticity
All our application services are connected to the Docker container, storage or physical machine; We will create some basic images and make the required software into images, so that we don't have to install and deploy software every time we go to the O & M; In the future, it can support automatic capacity expansion, such as automatic capacity expansion of machines according to CPU or bandwidth. At present, some services of JD support automatic capacity expansion in one minute.
Degraded switch
The push server pushes the degradation switch, centralized maintenance of the switch, and then pushes it to each server through the push mechanism;
Degraded multi-level read service, front-end data cluster - > Data heterogeneous cluster - > dynamic service (call dependent system); In this way, the service quality can be guaranteed. Assuming that a disk in the front-end data cluster is broken, you can also go back to the source data heterogeneous cluster to obtain data;
Pre switch, such as Nginx – à Tomcat. If the switch is made on Nginx, the request can not reach the back end, reducing the pressure on the back end;
The degradable business thread pool isolation supports the asynchronous model from Servlet3 and Tomcat7/Jetty8. The same concept is the Continuations of Jetty6. We can decompose the process into events. By dividing requests into events, we can have more control. For example, we can create different thread pools for different services for control: that is, we only rely on Tomcat thread pool for request parsing, and we hand over the processing of requests to our own thread pool; In this way, Tomcat thread pool is not our bottleneck, resulting in the current situation that cannot be optimized. By using this asynchronous event model, we can improve the overall throughput and prevent slow A service processing from affecting other service processing. Slow or slow, but it does not affect other businesses. Through this mechanism, we can also take out the monitoring of Tomcat thread pool. When there is A problem, we can directly empty the business thread pool. In addition, we can customize the task queue to support some special businesses.
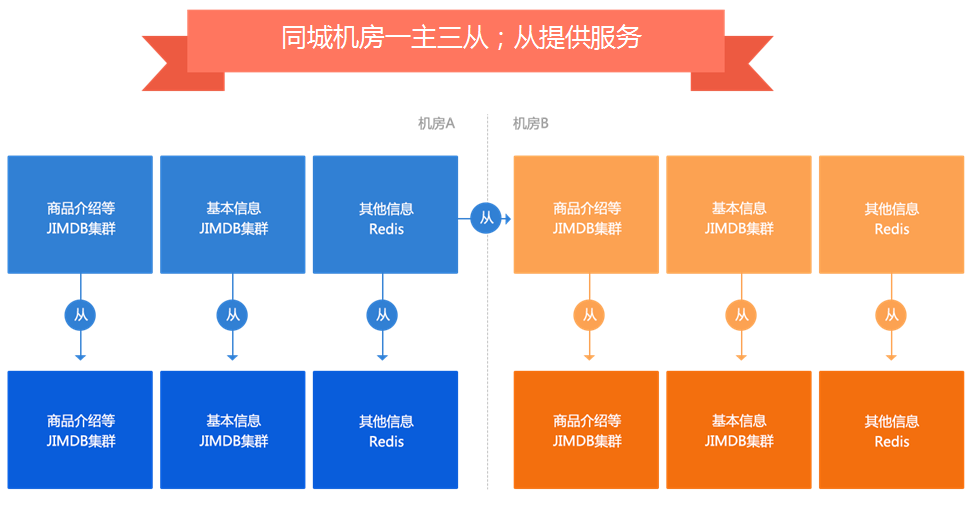
Multi machine room and multi activity
The application is stateless, and the data reading is completed by configuring the data cluster of each computer room in the configuration file.
The data cluster adopts a master-slave and three slave structure to prevent jitter when one machine room is hung and the other machine room is under great pressure.
Various pressure measurement schemes
Offline pressure measurement, Apache ab and Apache Jmeter, is a fixed url pressure measurement. Generally, some URLs are collected through the access log for pressure measurement. It can simply measure the peak throughput of a single machine, but it can not be used as the final pressure measurement result. Because the bold style is this pressure measurement, there will be hot issues;
For online pressure measurement, Tcpcopy can be used to directly import the online traffic to the pressure measurement server. In this way, the performance of the machine can be measured, and the traffic can be amplified. The Nginx+Lua coordination mechanism can also be used to distribute the traffic to multiple pressure measurement servers, or directly embed points on the page to allow users to conduct pressure measurement. This pressure measurement method can not return content to users.