🍅 Supporting articles for Java learning route: Summary of java learning route, brick movers counter attack Java Architects (the strongest in the whole network)
🍅 Basic recommendations: Java foundation tutorial series
🍅 Practical recommendations: Spring Boot basic tutorial
🍅 Introduction: high quality creator in Java field 🏆, CSDN the author of the official account of the Na Zha ✌ , Java Architect striver 💪
🍅 Scan the QR code on the left of the home page, join the group chat, learn and progress together
🍅 Welcome to praise 👍 Collection ⭐ Leaving a message. 📝
🍅 Book delivery at the end of the text
1, Introduction to Elasticsearch
Elasticsearch is a distributed and RESTful search and data analysis engine, which can solve the emerging use cases. As the core of Elastic Stack, it centrally stores your data and helps you find unexpected and unexpected situations.
The Elastic Stack includes Elasticsearch, Kibana, Beats and logstack, also known as ELK Stack.
It can safely and reliably obtain data from any source and any format, and then search, analyze and visualize the data in real time.
Elastic search is called ES for short. ES is an open-source and highly extended distributed full-text search engine. It is the core of the entire Elastic Stack technology stack. It can store and retrieve data in near real time; It has good scalability and can be extended to hundreds of servers to process PB level data.
PB is the unit of data storage capacity, which is equal to the 50th power of 2 bytes, or about 1000TB in value.
2, Download and install
1. Download address of Elasticsearch official website
https://www.elastic.co/cn/downloads/elasticsearch
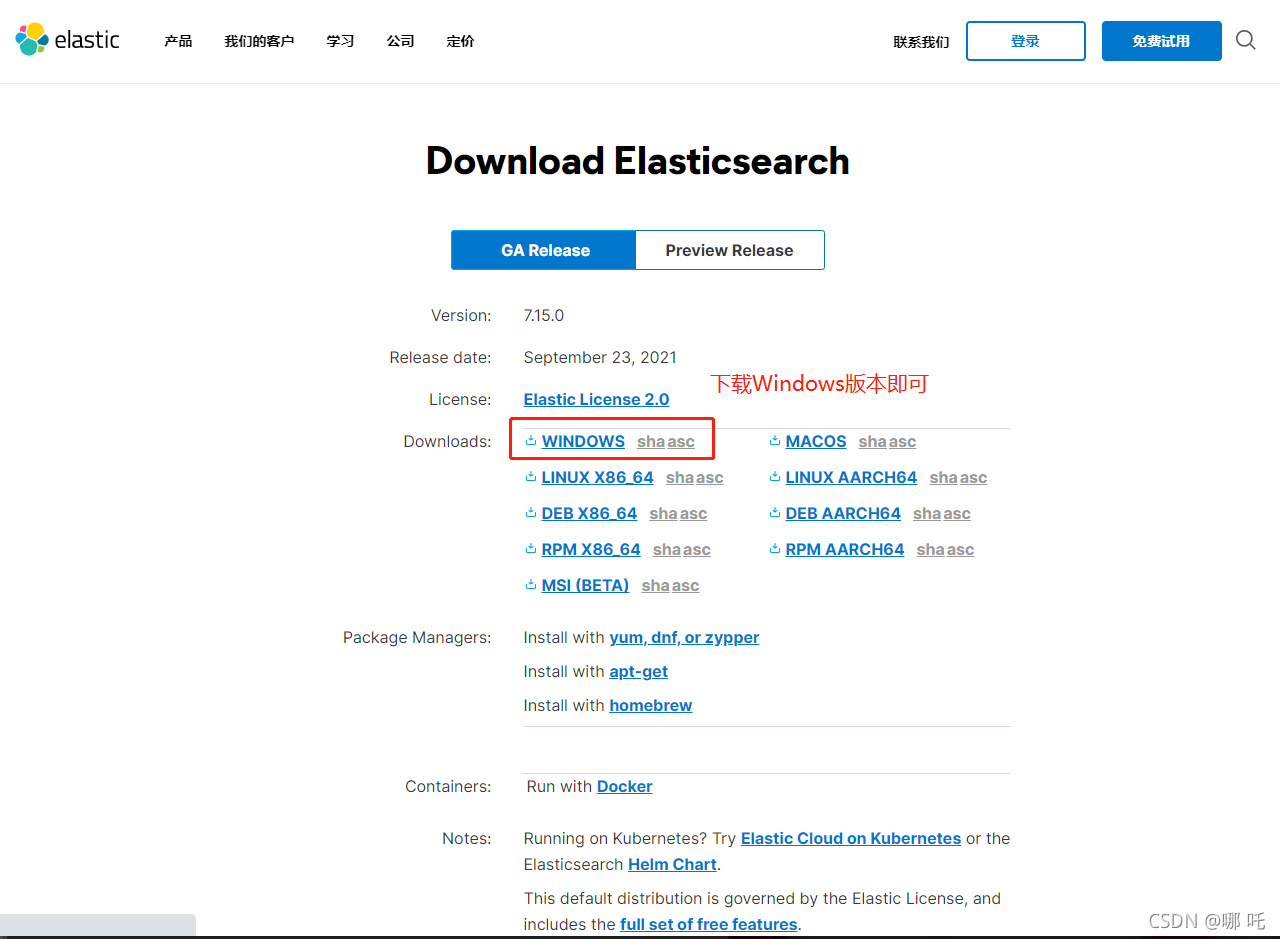
2. Download succeeded
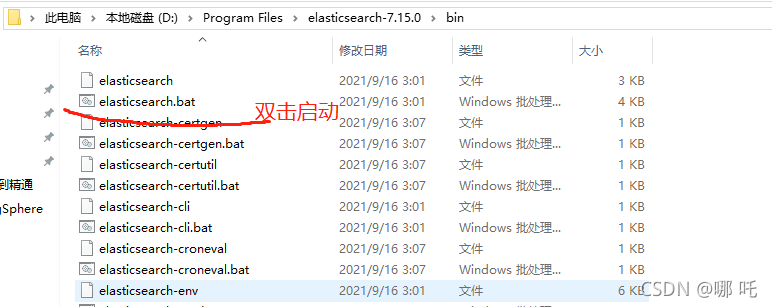
3. Double click elasticsearch Bat start
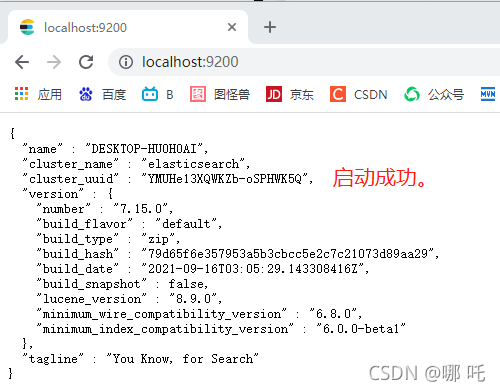
4. Start successful
3, Data format
Elastic search is a document oriented database, where a piece of data is a document. To facilitate your understanding, we make an analogy between the concepts of storing document data in Elasticsearch and storing data in relational database Mysql:
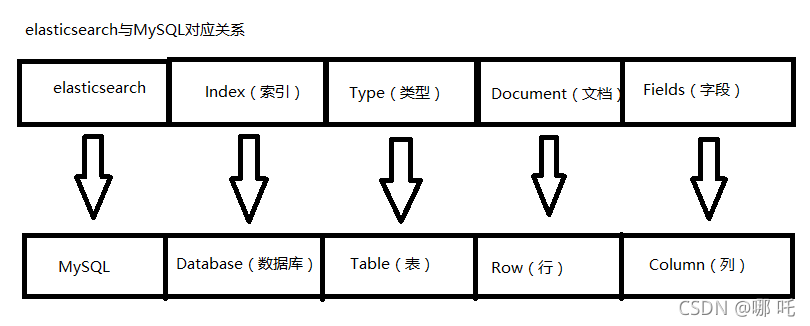
The Index in ES can be regarded as a library, while Types is equivalent to a table and Documents is equivalent to rows of a table.
Elasticsearch7. In X, the concept of Type has been deleted.
4, Index
1. Create index
In postman, send a PUT request to the ES server: 127.0 0.1:9200/work
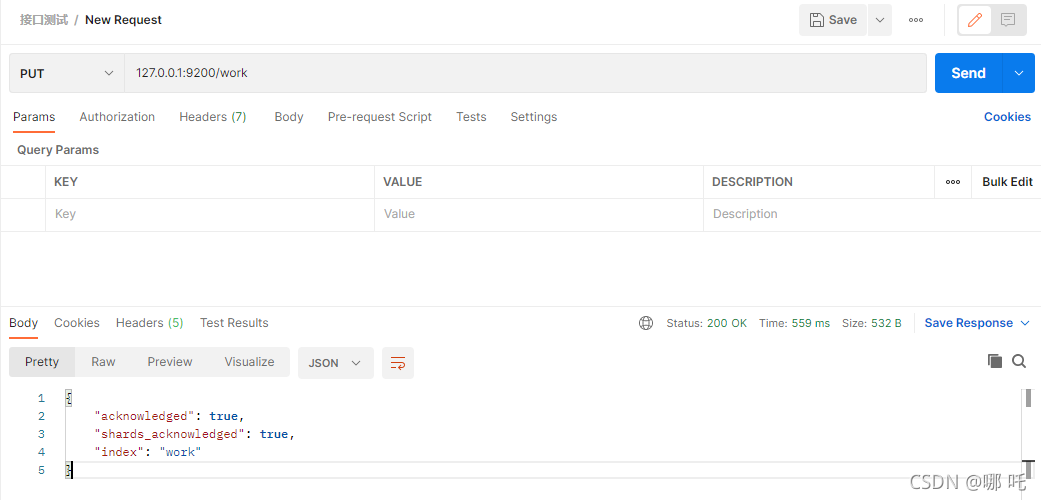
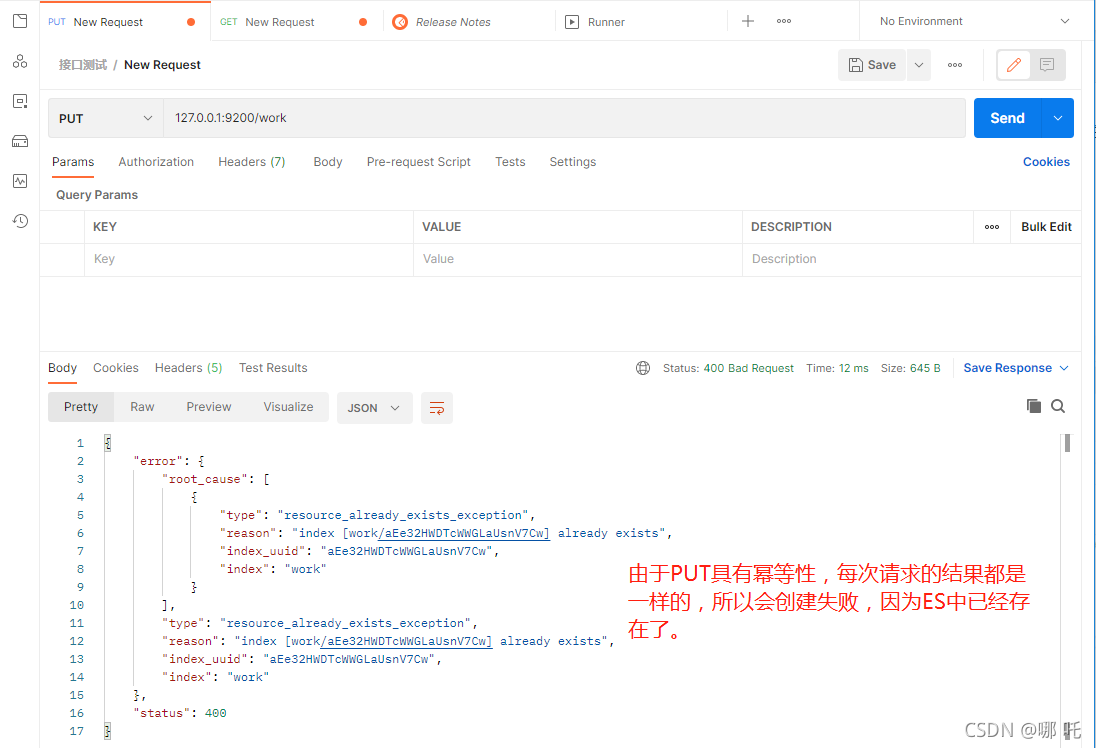
Because the PUT request is idempotent, the result of each PUT request creation is the same. When requesting again, the creation will fail because an index named work already exists in ES.
POST is not idempotent, so the results of POST requests may be different, so POST requests are not allowed when adding indexes.
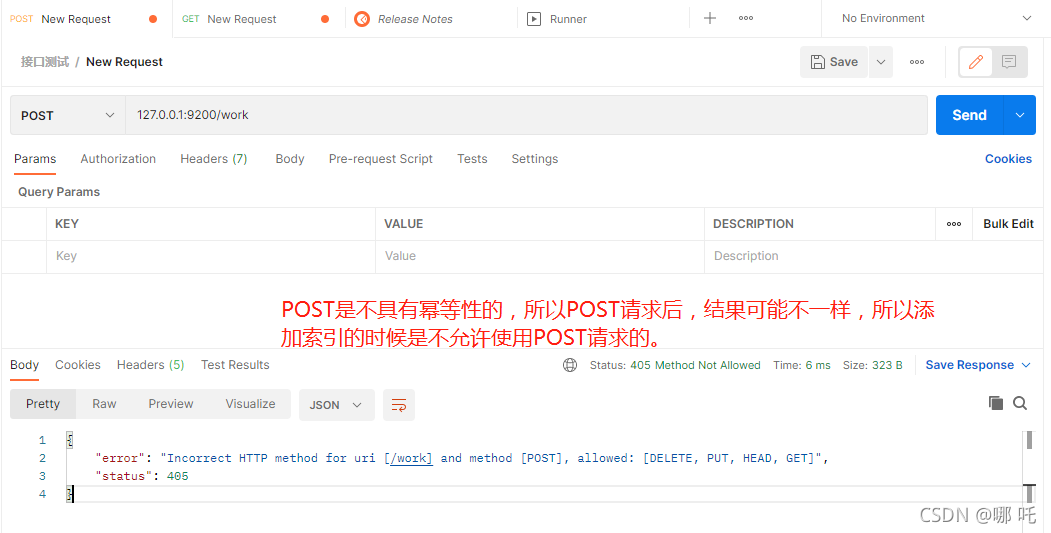
What is idempotency?
In programming, the characteristic of an idempotent operation is that the impact of any multiple execution is the same as that of one execution. Idempotent functions, or idempotent methods, refer to functions that can be executed repeatedly with the same parameters and obtain the same results. These functions will not affect the system state, and there is no need to worry that repeated execution will change the system.
2. Query index
(1) A single index can be obtained through a GET request
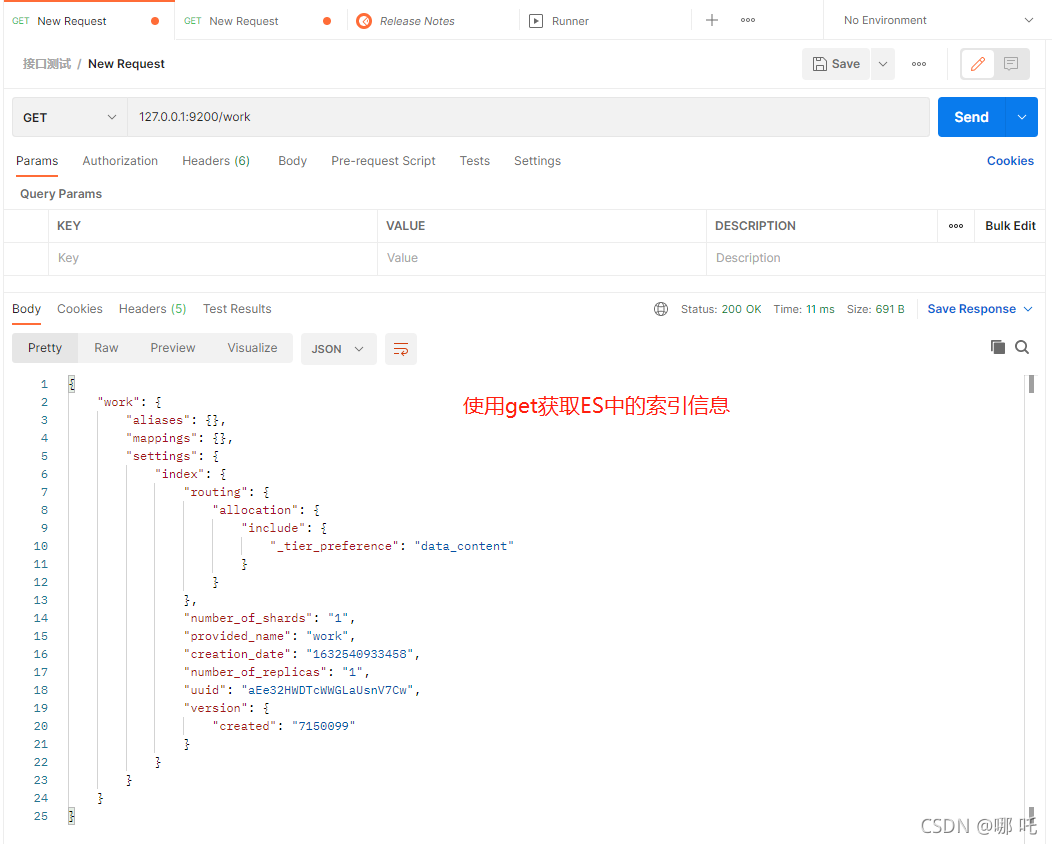
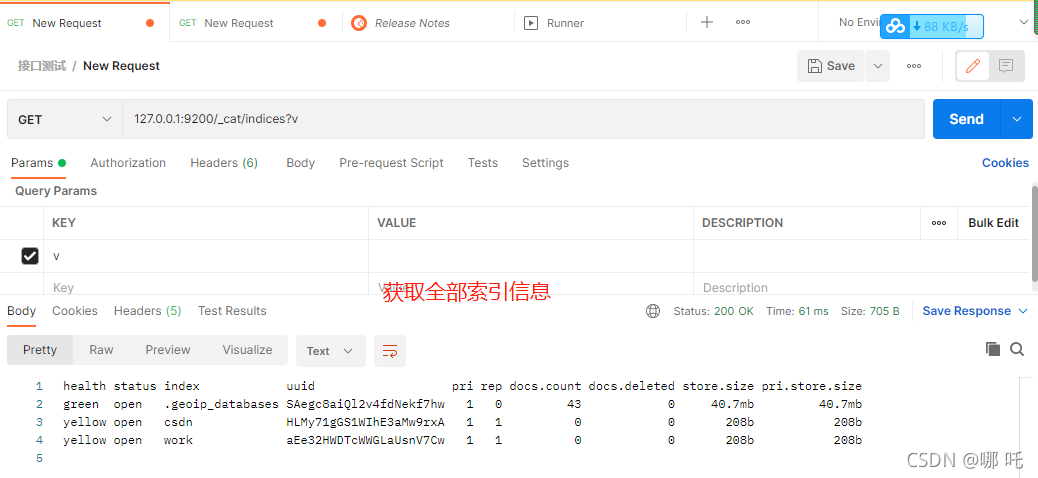
(2) Get all index information
127.0.0.1:9200/_cat/indices?v
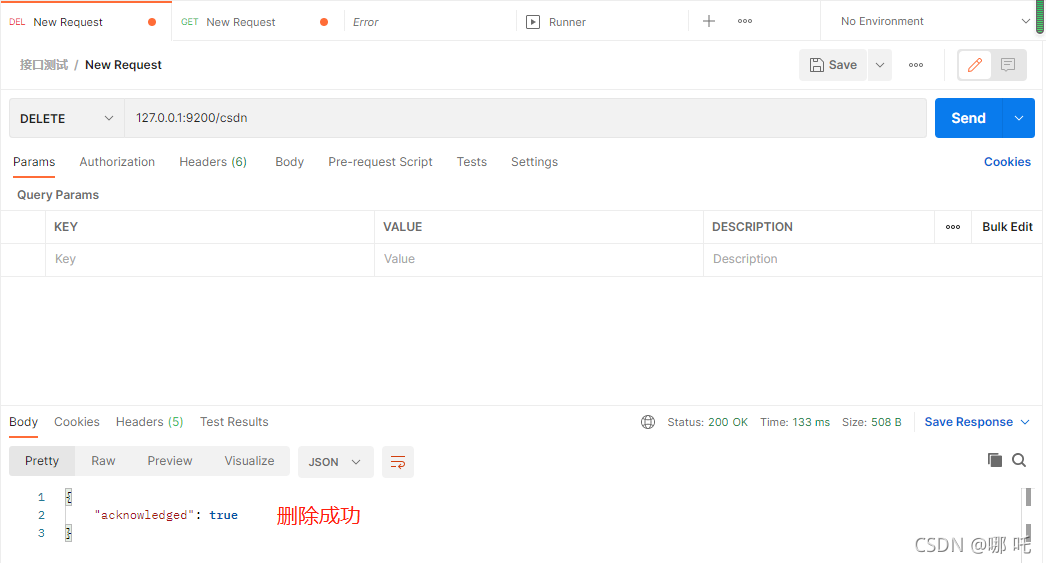
3. Delete index
5, Documentation
1. Create document
The document in ES is equivalent to the table data in MySQL, and the data format is JSON format.
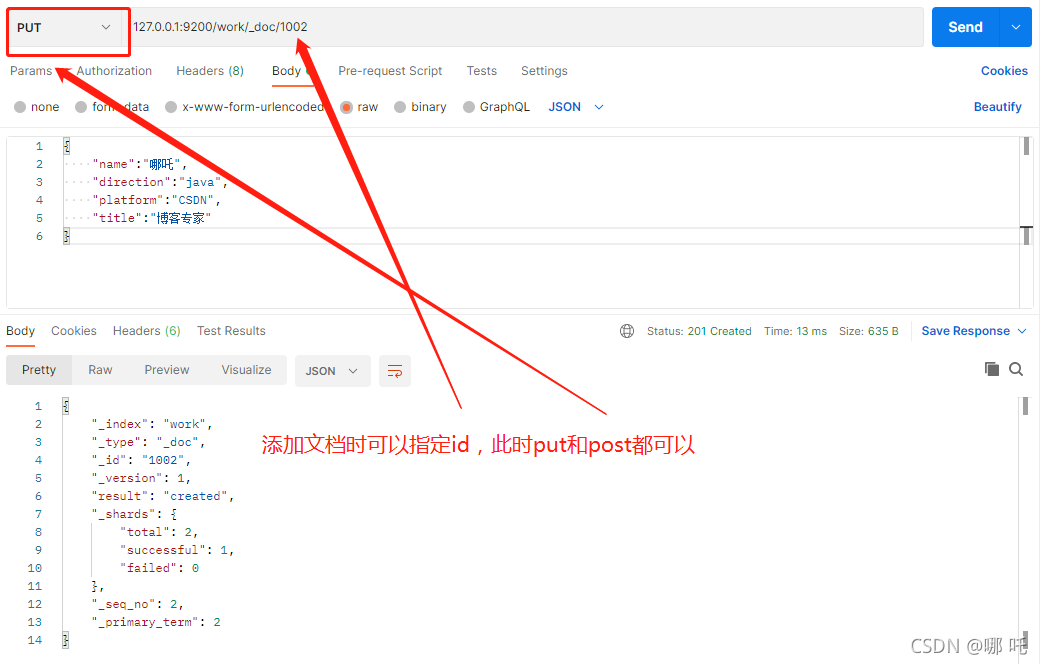
Since a unique identifier will be automatically created during document generation, because POST is not idempotent and PUT is idempotent, POST can only be used here.
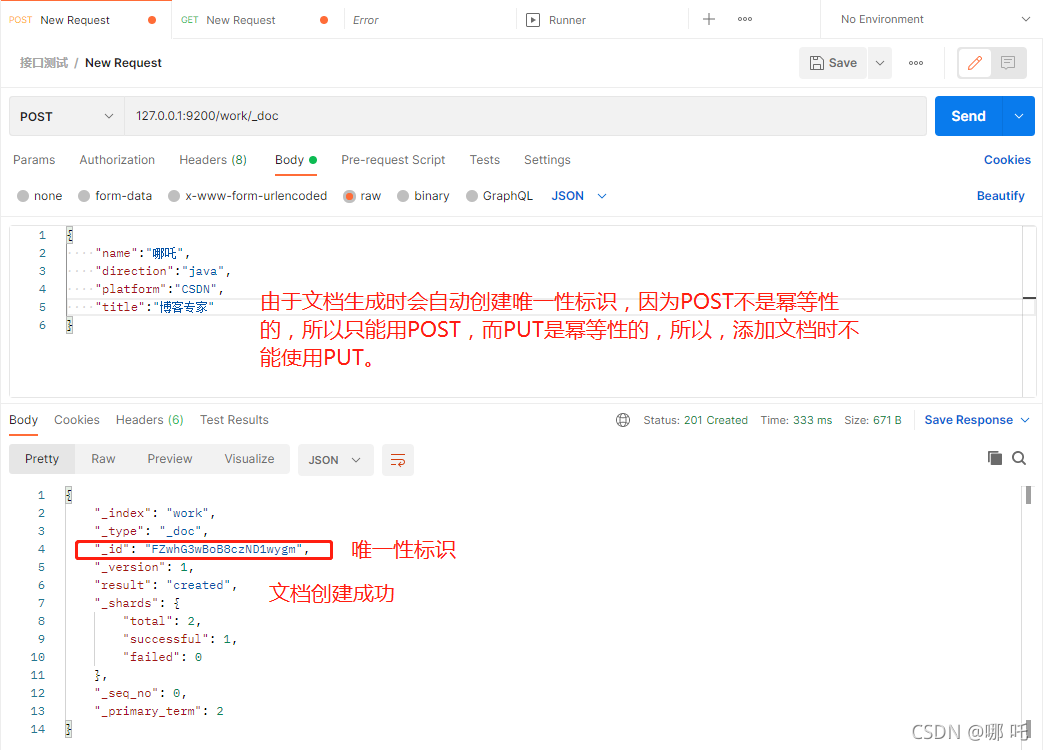
You can specify an id
2. Query document
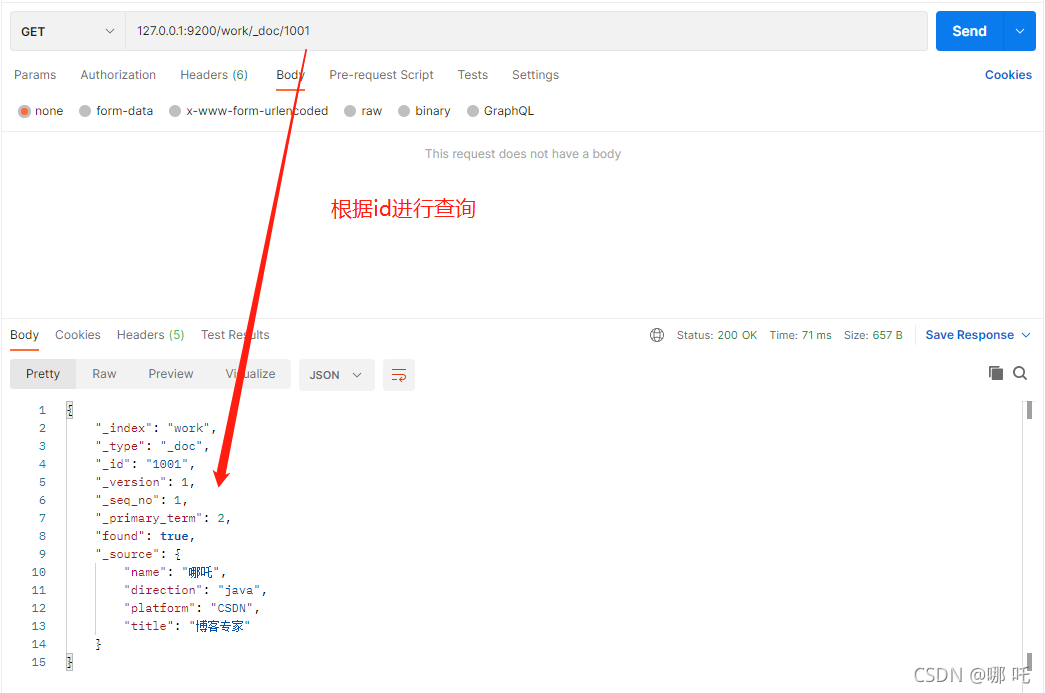
(1) Query by id
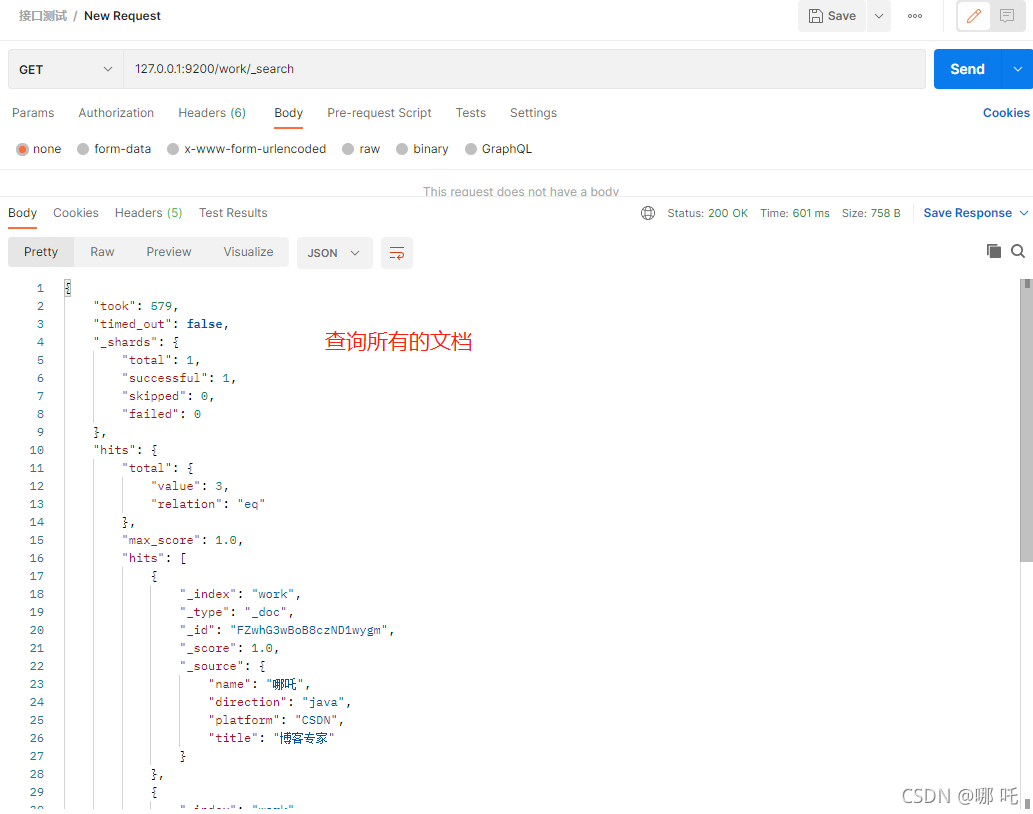
(2) Query all documents
127.0.0.1:9200/work/_search
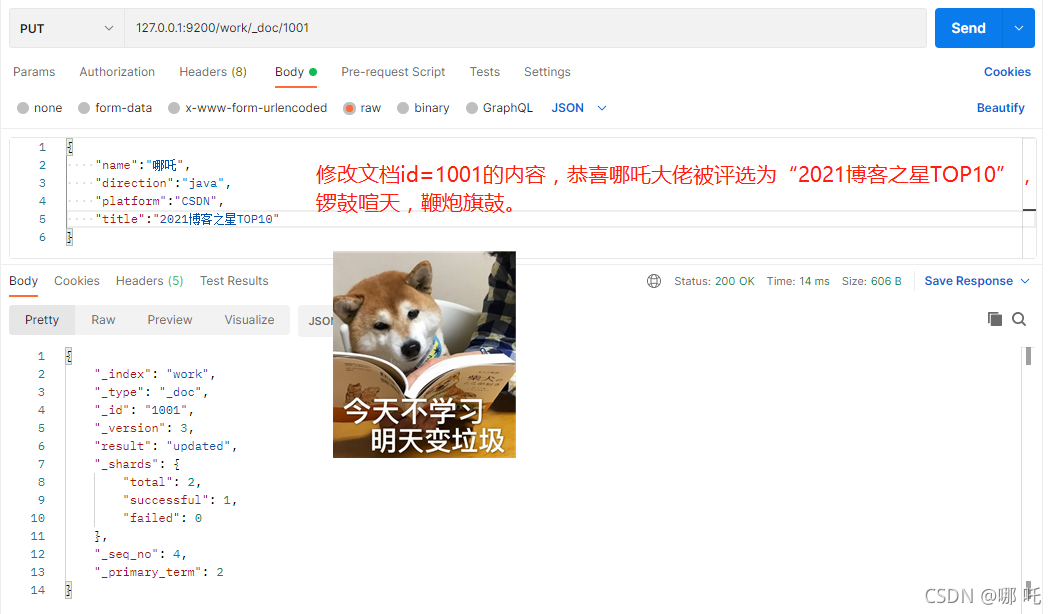
3. Change document content
(1) Modify the content of document id=1001. Congratulations on Nezha being selected as "2021 blog star TOP10", with gongs and drums, firecrackers and drums.
(2) Local update
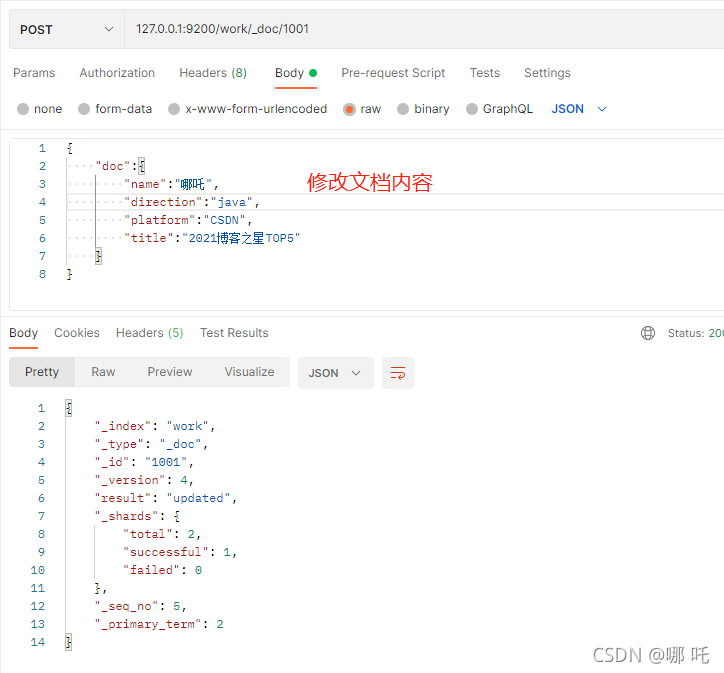
(3) Local updates are successful. Congratulations on Nezha's successful promotion to top 5.
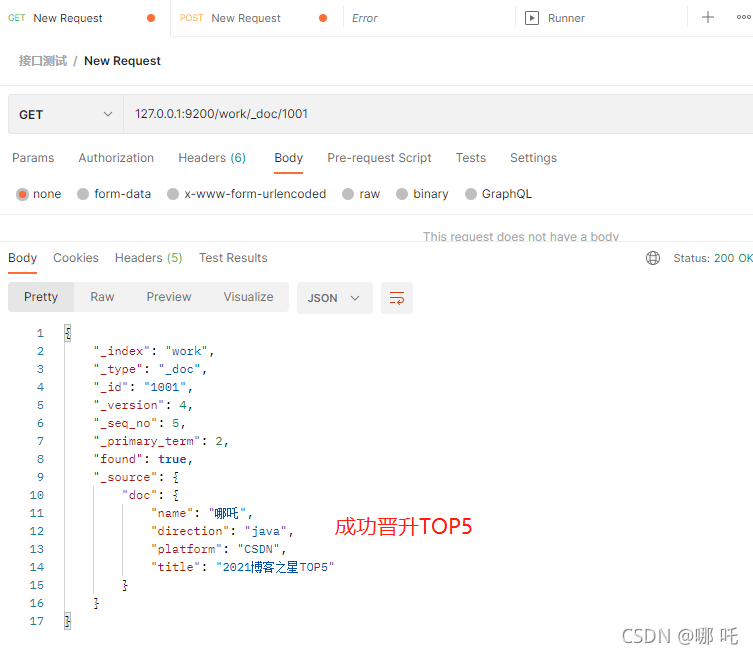
6, Complex query
1. Specify query criteria
(1) Query the index of Nezha with name (through the request path: 127.0.0.1:9200/work/_search?q=name: Nezha)
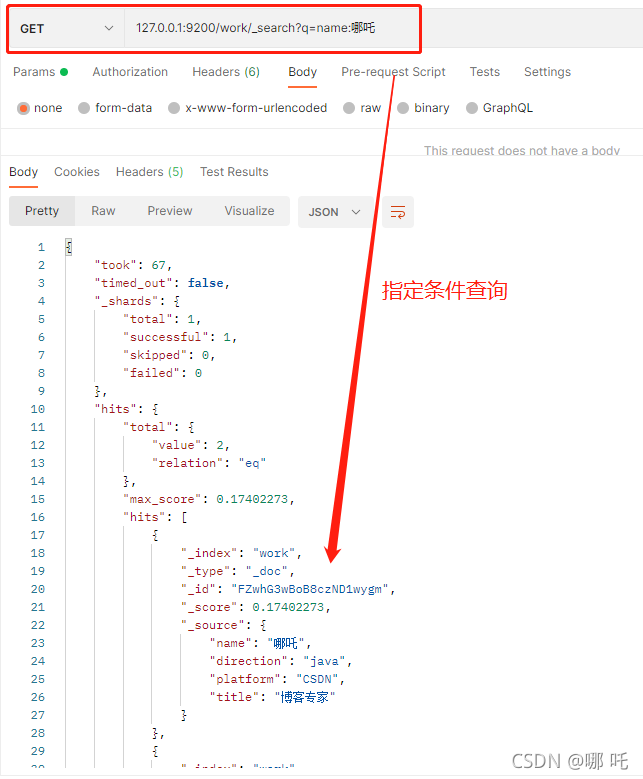
Note: the full article is full of screenshots, which are not good-looking. Please understand.
(2) Request body query
get request: 127.0 0.1:9200/work/_ search
Request body:
{
"query":{
"match":{
"name":"nezha"
}
}
}
(3) Paging query
get request: 127.0 0.1:9200/work/_ search
Request body:
{
"query":{
"match_all":{
}
} ,
"from":0,
"size":2
}
(4) Get only the specified field and sort by id
{
"query":{
"match_all":{
}
} ,
"from":0,
"size":2,
"_source":["title"],
"sort":{
"_id":"desc"
}
}
2. Multi condition query
must means and match
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"nezha"
}
},{
"match":{
"title":"Blog expert"
}
}
]
}
}
}
should indicates or match
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"nezha"
}
},{
"match":{
"name":"CSDN"
}
}
]
}
}
}
Range matching: salary greater than 10000
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"nezha"
}
},{
"match":{
"name":"CSDN"
}
}
],
"filter":{
"range":{
"money":10000
}
}
}
}
}
3. Partial vocabulary matching query
Each value is disassembled to form an inverted index to facilitate full-text retrieval.
{
"query":{
"match":{
"name":"which"
}
}
}
perfect match
{
"query":{
"match_phrase":{
"name":"which"
}
}
}
Highlight
{
"query":{
"match":{
"name":"which"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}
4. Aggregate query
(1) Grouping query
{
"aggs":{
"money_group":{
"terms":{
"field":"money"
}
}
},
"size":0
}
(2) Average query
{
"aggs":{
"money_avg":{
"avg":{
"field":"money"
}
}
},
"size":0
}
7, Code example
1. Introducing pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.guor</groupId>
<artifactId>es</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>es</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch Client for -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch Dependency 2.x of log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- junit unit testing -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2. Add index
package com.guor.es.test;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
public class ESTest {
public static void main(String[] args) throws Exception{
//Create es client
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//Create index
CreateIndexRequest request = new CreateIndexRequest("student");
CreateIndexResponse createIndexResponse = esClient.indices().create(request, RequestOptions.DEFAULT);
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println("Create index:"+acknowledged);
// Close the es client
esClient.close();
}
}
3. Run error
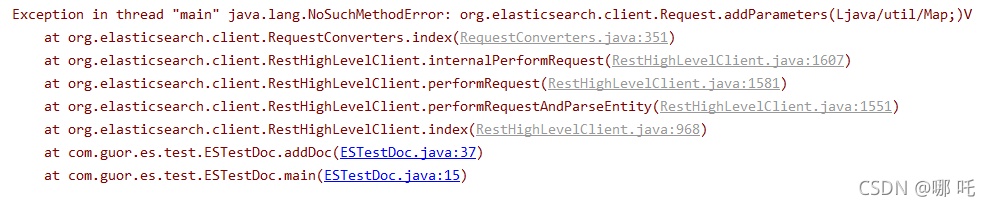
resolvent:
Put pom in
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
Replace with:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>
4. Query index
package com.guor.es.test;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
public class ESTest {
public static void main(String[] args) throws Exception{
//Create es client
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//Create index
GetIndexRequest request = new GetIndexRequest("student");
GetIndexResponse getIndexResponse = esClient.indices().get(request, RequestOptions.DEFAULT);
//Response status
System.out.println(getIndexResponse.getAliases());
System.out.println(getIndexResponse.getMappings());
System.out.println(getIndexResponse.getSettings());
// Close the es client
esClient.close();
}
}
5. Insert document
package com.guor.es.test;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.common.xcontent.XContentType;
public class ESTestDoc {
public static void main(String[] args) throws Exception{
addDoc();
}
private static void addDoc() throws Exception{
//Create es client
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
IndexRequest request = new IndexRequest();
request.index("work").id("1001");
Work work = new Work();
work.setName("nezha");
work.setAge(28);
work.setSex(0);
ObjectMapper mapper = new ObjectMapper();
String workJson = mapper.writeValueAsString(work);
IndexRequest response = request.source(workJson, XContentType.JSON);
System.out.println(response.getShouldStoreResult());
esClient.index(request, RequestOptions.DEFAULT);
// Close the es client
esClient.close();
}
}

6. Batch insert document
private static void addBatchDoc() throws Exception{
//Create es client
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
BulkRequest request = new BulkRequest();
request.add(new IndexRequest().index("work").id("1001").source(XContentType.JSON, "name", "csdn nezha"));
request.add(new IndexRequest().index("work").id("1002").source(XContentType.JSON, "name", "csdn Nezha 1"));
request.add(new IndexRequest().index("work").id("1003").source(XContentType.JSON, "name", "csdn Nezha 2"));
BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);
System.out.println(response.getTook());
System.out.println(response.getItems());
// Close the es client
esClient.close();
}
7. Query all data in the document according to criteria
/**
* Query all data in the index
*/
private static void getDoc() throws Exception{
//Create es client
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//Query all data in the index
SearchRequest request = new SearchRequest();
request.indices("work");
//Construct query criteria to match all
SearchSourceBuilder query = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
request.source(query);
//consult your documentation
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
//Query results
SearchHits hits = response.getHits();
//Number of queries
System.out.println(hits.getTotalHits());
//Query time
System.out.println(response.getTook());
//Query specific data
for (SearchHit hit : hits){
System.out.println(hit.getSourceAsString());
}
// Close the es client
esClient.close();
}
console output
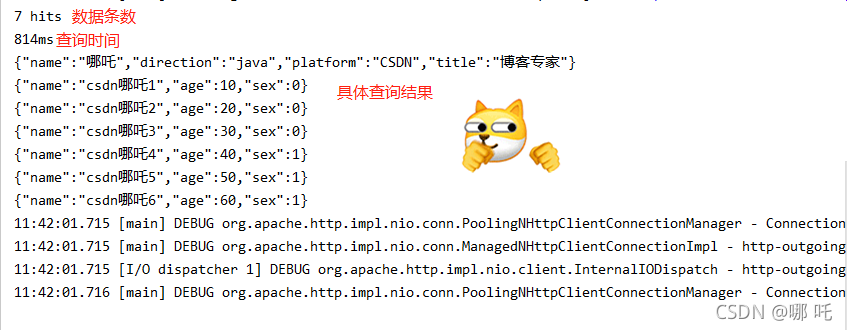
8. Query by criteria
SearchSourceBuilder query = new SearchSourceBuilder().
query(QueryBuilders.termQuery("name","csdn nezha"));
9. Paging query
//Construct query criteria, paging query SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()); //home page builder.from(0); //Amount of data per page builder.size(2); request.source(builder);
10. Sort by age
//Sort by age
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
builder.sort("age", SortOrder.DESC);
request.source(builder);
console output
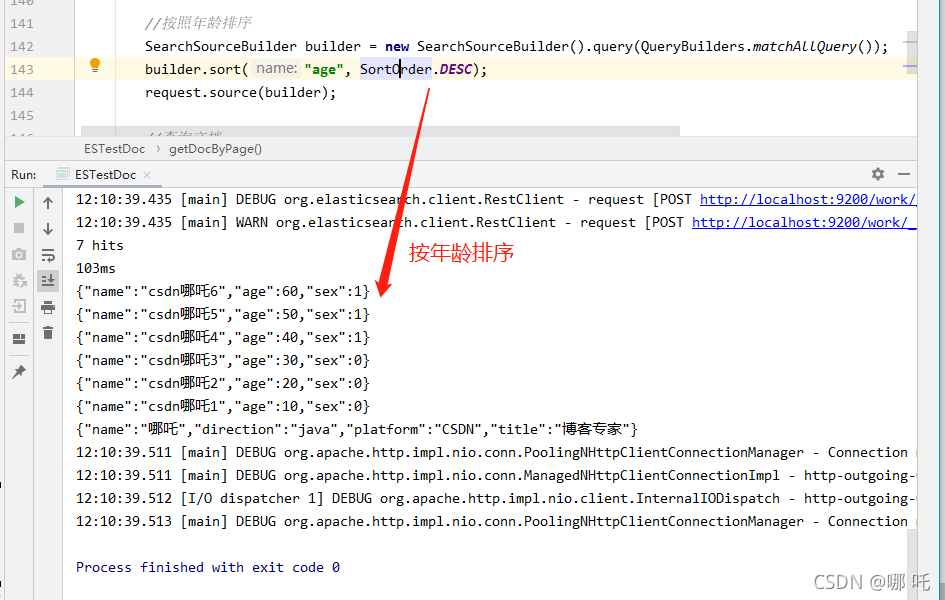
11. Query by criteria
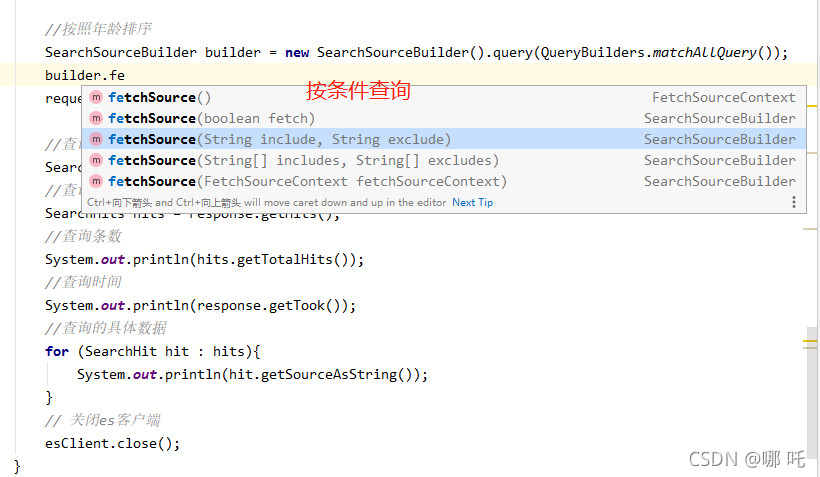
12. Combined condition query
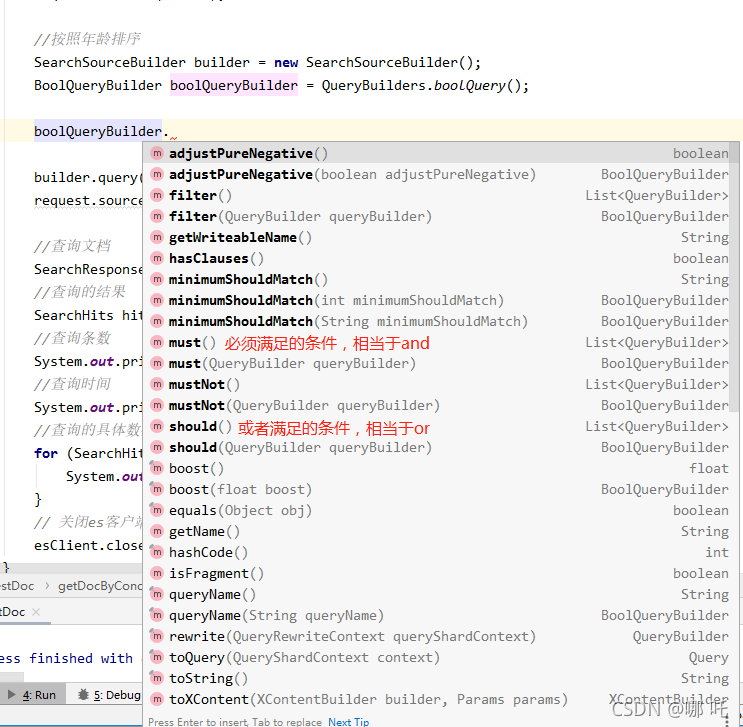
13. Fuzzy query
//It can match by one character
SearchSourceBuilder builder = new SearchSourceBuilder();
FuzzyQueryBuilder fuzziness = QueryBuilders.
fuzzyQuery("name", "nezha").fuzziness(Fuzziness.ONE);
builder.query(fuzziness);
request.source(builder);
14. Aggregate query
8, Introduction and practice of Elasticsearch search search engine construction
1. Content introduction
Start with the basic concept and principle of Elasticsearch, and then systematically introduce the use scenario of Elasticsearch to lead readers to get close to Elasticsearch.
This book comprehensively covers technologies such as the installation and use of Elasticsearch client, index creation, document operation, search matching, search sorting and aggregation, which can help readers master the relevant knowledge of Elasticsearch step by step.
There are 8 chapters, divided into 3 chapters.
Chapter 1 "Elasticsearch Basics", mainly introduces the basic knowledge and basic usage of Elasticsearch;
Chapter 2 "elastic search improvement", first introduces the principle of text search and sorting, and then introduces the use of aggregation;
Chapter 3 "Elasticsearch practice", taking hotel search as an example, introduces in detail the relevant technologies involved in the actual search application of Elasticsearch, so as to help readers fully understand the search engine and improve the development level.
2. Jingdong
Introduction and practice of Elasticsearch search search engine construction

Previous: [Spring Boot 28] Spring Boot integrates easyExcel
Next: SpringBoot learning route summary, follow the route and don't get lost (with mind map)
