one 🛒 Determine the amount of data to synthesize
Refer to PaddlePaddle's WeChat official account:
Baijiazhuantan | phase I: 100 questions on OCR character recognition

For the recognition task, it is necessary to ensure that each character in the recognition dictionary appears in the line text image of different scenes, and the number needs to be greater than 200.
For example, if there are five words in the dictionary and each word needs to appear in more than 200 pictures, the minimum number of images required should be between 200-1000, which can ensure the basic recognition effect
My scene is 26 in English, 10 numbers, and some punctuation marks x and so on, almost 50 characters, that is, at least 2w pictures. Anyway, the more, the better.
In addition, according to StyleText describes the application case part of the document
The following takes two scenes of metal surface English number recognition and general Korean recognition as examples to illustrate the actual case of using style text synthetic data to improve the effect of text recognition. The following figure shows some examples of real scene images and composite images:

After adding the above synthetic data for training, the effect of recognition model is improved, as shown in the following table:

It can be seen that the accuracy of this kind of scene with some blurred pictures is not high.
Moreover, 2w pieces of synthetic data are used to identify English and numbers on the metal surface.
Therefore, it is determined that the number of pictures generated for the scene of English, numbers and characters is 2w-2.5w.
2. 🧧TextRender
- TextRender2. Version of 0, github link,
The blog records I used before,
PaddleOCR digital instrument identification - 2 (New) Textfinder is used and modified to conform to the PaddleOCR data standard. - TextRender1. Version 0, in fact, has more functions, github link , the next use mainly focuses on the 1.0 version.
It is recommended to run locally first, and then run on the server. The following contents are run in win10 system and py35 environment.
2.1 installation
Run the following command:
# Download repo and extract a text from the directory_ It is recommended to copy the directory of renderer, because things will be changed later... git clone https://github.com.cnpmjs.org/Sanster/text_renderer.git # Install dependency, switch to text_ Under the renderer directory, install dependencies. I use Python 3 5 environment, # If you feel slow, add the mirror image of Tsinghua University pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
2.2 use
Unexpected search text_ Using renderer, I didn't find anything useful. Alas, the sadness of niche areas.
Only:
CV learning notes (18): text_renderer
and CV learning notes (19): data set splicing generation
You'd better rely on yourself.
2.2.0 testing
Don't change anything, just switch to text_ In the renderer folder, run the following command
python3 main.py
Then a prompt message like this will be output:
(py35) C:XXXX\ocr\SFTP\TextRenderer_copy>python main.py Total fonts num: 1 Background num: 1 Loading corpus from: ./data/corpus Loading chn corpus: 1/1 Total fonts num: 1 Background num: 1 Loading corpus from: ./data/corpus Loading chn corpus: 1/1 Generate text images in ./output\default Total fonts num: 1 Total fonts num: 1 Background num: 1 Background num: 1 Loading corpus from: ./data/corpus Loading chn corpus: 1/1 Total fonts num: 1 Loading corpus from: ./data/corpus Loading chn corpus: 1/1 Total fonts num: 1 Background num: 1 Total fonts num: 1 Background num: 1 Loading corpus from: ./data/corpus Loading chn corpus: 1/1 Background num: 1
You can see the output 20 images and corresponding labels in the output/default / folder. The production is good. It feels like a real scene except that there is no color.

2.2.1 help documents
Use Python 3 main Py -- help view document information and translate a wave. Or go to parse directly_ args. Py file to see the meaning of each parameter (and the default value)
--num_img NUM_IMG Number of pictures to generate
--length LENGTH The number of words (Chinese) or words (English) in each figure. For English corpus, the default length is 3
--clip_max_chars Train one CRNN When modeling, the maximum number of characters in a graph should be less than the last layer CNN Width of layer
--img_height IMG_HEIGHT
--img_width IMG_WIDTH If it is 0, the output image will have different widths
--chars_file CHARS_FILE The character set allowed in the image
--config_file CONFIG_FILE Set parameters when rendering images
--fonts_list FONTS_LIST The path of the font file to be used
--bg_dir BG_DIR Background image folder, corresponding to yaml configuration file
--corpus_dir CORPUS_DIR When the corpus mode is chn or eng The text on the image will be randomly selected from the corpus. Recursively find all in the corpus directory txt file
-- corpus_mode {random,chn,eng,list} Different corpus types have different Load/get_sample method, random: Randomly select characters from the character file, chn: Select consecutive characters from the corpus, eng: Select continuous words from the corpus with their own spaces.
--output_dir OUTPUT_DIR Directory where images are saved
--tag TAG The output image is exposed output_dir/{tag}Under the directory
--debug Output uncut image( cropped Product of intermediate process during transformation
--viz
--strict Check font support for characters when generating images
--gpu use CUDA Generate image
--num_processes NUM_PROCESSED The number of processes used when generating images. None If so, use all CPU Number of cores.
It still seems unclear after reading. Just use it. Just look at the source code
2.2.2 configuration file
There are two files in the configs folder, default Yaml and test Yaml, the configuration file mainly contains some text effects, including: perspective transformation, random clipping, bending, light border, word edge brightening (there is a layer of white on the outer layer of text strokes), Dark border (there is a layer of black on the outer layer of text strokes), random character blank (large), character spacing becomes larger, random character blank (small), character spacing becomes smaller, Middle line (similar to delete line), table line, underline, relief, reverse color (opposite color), blur, text color, line color

three 👑 Use your own data to generate images
In fact, the steps are very simple. My goal is to produce an image similar to the following figure
3.1. Prepare the data and put it in the corresponding folder
It mainly includes background image, font file, corpus content and recognition character set. It is recommended to copy a copy of text before operation_ Render folder, because you need to change some of them. If you make a mistake, you can start again..
3.1.1 background
- The background image of the example given is 292x338 in size, 32 in bit depth and 82.9KB in size
- Similarly, put your own bg file into text_ In the renderer \ data \ bg folder. (the size of the figure I put is also similar to the example, corresponding to the above two figures)

This is configured because of the running parameters:
--bg_dir='./data/bg (this is the default parameter, because your BG diagram is placed here by default, so this parameter can not be written when running)
3.1.2 font
The self-contained English font is hack regular TTF, you can put the font you need into text_ In the renderer \ data \ fonts folder, I only focus on English here and put it under the eng folder. Like this:

You can double-click the ttf file to view the font form. If you think the default font is quite different from your own scene, you can delete it.
After putting the font into the font\eng folder, you need to add the font in \ data \ fonts_ In the file list \ eng.txt, write the relative paths of those font files just now, similar to:

This is configured because of the running parameters:
--fonts_list='./data/fonts_list/eng.txt
3.1.3 character set to be recognized
Because in the scene I am facing, in addition to English and numbers, there are some additional characters, such as [,], ℃, °, μ, *, - . , (,) etc.
Therefore, it is not enough to only use the default character set text file \ data\chars\eng.txt, which needs to be slightly modified. The content of this file is: lowercase letters + uppercase letters + numbers + other symbols. Just change the parts of other symbols.
+ - ² % ℃ : . ° / [ ] * ( ) × μ θ # This is a space
There is also a problem of spaces. The Hello World in the example has its own spaces. This may be due to the choice of the English model corpus, but the subsequent experiments found that using the Chinese model, as long as the English character set writes spaces, there will also be spaces.
Note the font support character set problem
In addition, people familiar with fonts should know that some fonts only provide some characters, and some characters cannot be displayed (for example, in matplotlib, if the Chinese font is not specified, the Chinese can not be displayed in the drawn image, and the frame will be displayed). You can use check_font.py this script checks how many unsupported characters there are in a font.
""" This script has three parameters: 1.--chars_file='./data/chars/eng.txt' 2. --font_dir='./data/fonts/eng' Font folder 3. --delete'=False,(Delete fonts that do not fully support character sets) """ # Use double quotation marks. In addition, use the parameter space value instead of the equal sign python tools/check_font.py --chars_file "data/chars/eng.txt" --font_dir "data/fonts/eng"
The output results are as follows:
font: data/fonts/eng\YuGothR.ttc ,chars unsupported: 0 font: data/fonts/eng\segoeui.ttf ,chars unsupported: 1 font: data/fonts/eng\consola.ttf ,chars unsupported: 1 font: data/fonts/eng\Deng.ttf ,chars unsupported: 0 font: data/fonts/eng\msgothic.ttc ,chars unsupported: 0 3 fonts support all chars(79) in data/chars/eng.txt: ['data/fonts/eng\\YuGothR.ttc', 'data/fonts/eng\\Deng.ttf', 'data/fonts/eng\\msgothic.ttc']
There are no unsupported characters output as in the example...
Consider generating in two batches, because it is determined that the font of a picture is console font
3.1.4 about corpus
The parameter specifies the length parameter, which is used to control the number of characters in the generated image. The relevant parameters are:
--corpus_dir CORPUS_DIR When the corpus mode is chn or eng The text on the image will be randomly selected from the corpus. Recursively find all in the corpus directory txt file
-- corpus_mode {random,chn,eng,list} Different corpus types have different Load/get_sample method, random: Randomly select characters from the character file, chn: Select consecutive characters from the corpus, eng: Select continuous words from the corpus with their own spaces.
- Corresponding to the data folder, there is one in data\corpus\eng or data\corpus\chn txt file
- If -- corpus_ The mode parameter is chn or eng, which is from the corresponding txt file (chapter and paragraph) select continuous characters (English is continuous words, with spaces)
- If -- corpus_ If the mode parameter is list, it is from list_ Select one item randomly in corpus (one for each behavior)
- If -- corpus_ If the mode parameter is random, characters are randomly selected from the chars file.
I had to make complaints about it, because I didn't find a document about how to use list, and I wanted to search for issue on github. What the result was, what was the problem of the wonderful flower? 🤐
Measure:
python main.py --corpus_dir "data/list_corpus" --corpus_mode "list"
You guessed right. If you run like this, you will indeed use list_ Each item in the text file in corpus is used to generate text (independent of the specified text length, -- length parameter is invalid). Because the list tested has only 14 items, the data in it will be used in turn to produce different effects.

3.1.5 put your own corpus
The content at the article / chapter level is put into the data\corpus folder. All txt files in this folder will be read in circularly, and then randomly and continuously select -- length characters from these articles. If it is Chinese, it is X characters, if it is English, it is X words (see your own needs to make it)
python main.py --fonts_list "data/fonts_list/eng.txt" --chars_file "data/chars/eng.txt" --corpus_mode "chn"
This generates these fonts data/fonts_list/eng.txt supports the character data/chars/eng.txt. Select consecutive length characters from the text file in the data\corpus file (although they are all English, as long as the mode is Chinese, you can also select consecutive characters). You can generate effects similar to the following:

Although the generated characters look semantically ambiguous and have no spaces.
Add spaces in the English character set and regenerate it. You can see

In addition, the list corpus is put into data\list_corpus \, and then run with the following parameters:
python main.py --corpus_dir "data/list_corpus" --corpus_mode "list"
After calculation, it is necessary to produce 2.4w pictures, and each picture currently has 5 kinds of special effects. Modify the English character set (with and without spaces) to obtain random continuous length text from corpus, from list_corpus gets the text of each item. You need to prepare well and produce a list with a program_ Corpus is ready.
3.2. Modify profile
You can look at default YML file, you can find that there are no special effects used:
# Color effects not available font_color: enable: false # Random character spacing is not available (character spacing should be easily confused with spaces) random_space: enable: false # Curve (I can't meet this in my scene, and CTC is not good at dealing with this kind of character) curve: enable: false # Randomly crop text height (may cause incomplete character display) crop: enable: false
The special effects used (I changed them according to my own needs and tried to fit the actual scene). In fact, I only have five special effects used
text_border:# Add a layer of white or black to the strokes of the text. I need to add white in my scene ......
3.3. function
My pictures here are actually generated in batches, so they have different parameters and run many times. Combined with my scenario, the preliminary data design is as follows:
- For the time being, space recognition is not considered. English corpus, English character set and Chinese sampling (continuous sampling of length characters) are used as the first way to generate images.
It may be that the length of the text chapter is not enough, so the error is always reported when producing data: valueerror: possibilities do not sum to 1, but it does not affect the generated content...
The character length shall be controlled within 5-12, in which each of the length [5,9] produces 600 pieces (the same text content can have different styles), a total of 3k pieces, and each of the length [10,12] produces 1200 pieces, a total of 3600 pieces, a total of 6600 pieces.
In practice, it is found that when the text length in the picture is 12, it is already a lot, so the length of more than 12 is abandoned.
python main.py --fonts_list "data/fonts_list/eng.txt" --chars_file "data/chars/eng.txt" --corpus_mode "chn" --length "5" --num_img "600" python main.py --fonts_list "data/fonts_list/eng.txt" --chars_file "data/chars/eng.txt" --corpus_mode "chn" --length "10" --num_img "1200"
- For the list corpus, 1.8w pictures and 3-5 special effects should be generated, and the length of the corpus list should be about 6k
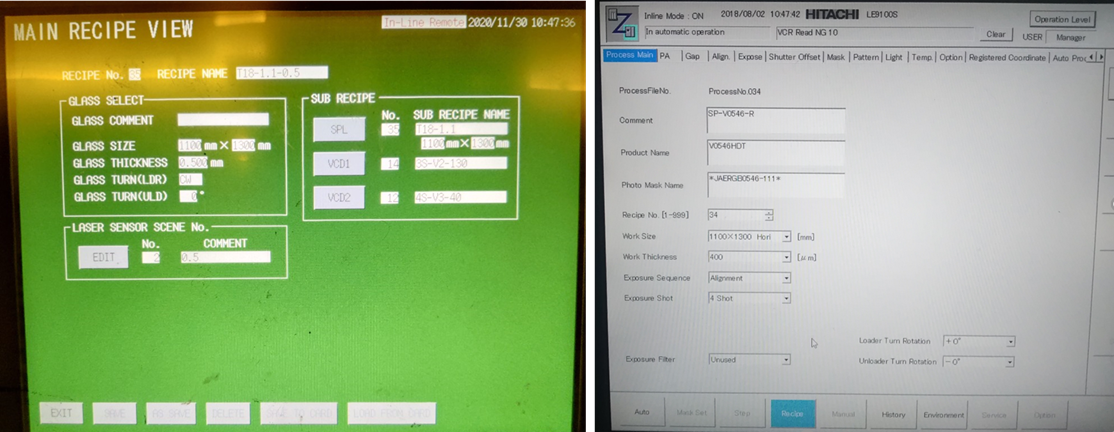
- First, take LE9100S and processno 034,SP-V0546-R,*JAERGb0546-111*,Recipe No.[1-999],1100 × 1300 Hori,Gap Tolerance(Calc)[ μ m],CP1 Temp. Based on the 10 basic styles of setting [℃], 3s-v2-130 and 4s-v3-40, replace letters / numbers, and each style has 400 words.
- Secondly, 2k kinds of numbers + letters + characters are randomly combined, and the length is between 10-15.
- In the pictures generated by the corpus, it is found that the perspective of the picture is relatively large. Here, modify the configuration file a little lower.
The final list corpus has 6558 items
python main.py --corpus_dir "data/list_corpus" --corpus_mode "list" --num_img "18000"
ValueError: probabilities do not sum to 1 is also reported during operation, but it does not affect the generated content..
The training set is 1.8w+6600=2.46w
- In addition, we should consider the problem of training set and test set. We need to mark part of the data of those real images and process them into gray images.
Referring to the training of other projects, the test set and training set are basically 1:4 (in the past, the test_train_split function was often 80% and 20% in machine learning scikit learn).
All need about 5k test set pictures, and some real data can be put in here.
3.4. Other interesting points
View main Py script, you can find:
- generate_ In the IMG function, you can see the base_name = '{:08d}'.format(img_index), when saving the picture, it is 8 numbers
- restore_ exist_ In the labels function, you can see the following code
def restore_exist_labels(label_path): # If labels. Exists in the target directory Txt adds pictures to the directory start_index = 0 if os.path.exists(label_path): start_index = len(utils.load_chars(label_path)) print('Generate more text images in %s. Start index %d' % (flags.save_dir, start_index)) else: print('Generate text images in %s' % flags.save_dir) return start_index
In other words, it can be generated multiple times, but it will be appended automatically. (I tried it myself. Running the sample code twice in a row will produce 40 pictures, and the serial number and label files are correct)
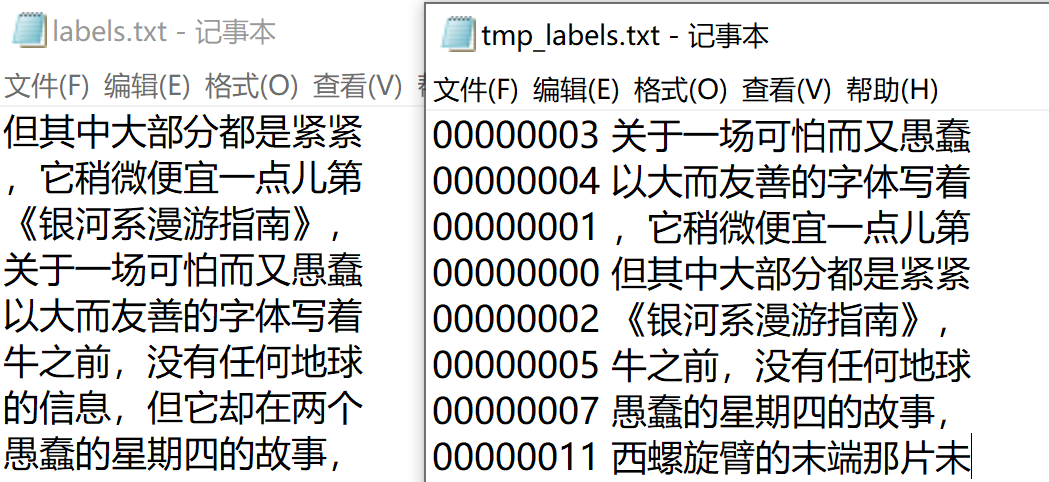
In addition, about the two label files generated, one is labels Txt, the other is tmp_lables.txt, there are two files because the images generated here use multiple processes of CPU by default, so the order of generation may be inconsistent. Therefore, save the image name and the corresponding label (text content) first, and then sort, and only store the label (access on demand, some people may not need such a file name)
4. Comparison of common text synthesis image tools
2021.4.12 record
| Name and github link | Number of star s | Latest update time |
|---|---|---|
| TextRecognitionDataGenerator | 1.7K | 2020.5.10 |
| SynthText | 1.6K | 3 months ago |
| text_renderer1.0 | 941 | last month |