TreeShking is to find and delete the code that will not be used in the source code through static analysis, so as to reduce the code volume of the compiled and packaged products.
In JS, we will use Webpack and Terser for Tree Shking, while in CSS, we will use PurgeCss.
PurgeCss will analyze the usage of css selectors in html or other code, and then delete unused css.
Are you curious about the principle of how PurgeCss finds useless css? Today, let's write a simple version of PurgeCss to explore it.
Train of thought analysis
PurgeCss specifies which html css is applied to. It will analyze the css selector in html and delete unused css according to the analysis results:
const { PurgeCSS } = require('purgecss')
const purgeCSSResult = await new PurgeCSS().purge({
content: ['**/*.html'],
css: ['**/*.css']
})
What we have to do can be divided into two parts:
- Extract the possible css selectors in html, including id, class, tag, etc
- Analyze the rule s in css and delete the unused parts according to whether the selector is used by html
The part that extracts information from html is called html extractor.
We can implement html extractor based on posthtml, which can parse, analyze and transform html. The api is similar to postcss.
The css part uses postcss, and each rule can be analyzed through ast.
Traverse the rules of css, and judge whether the selector of each rule is being extracted from html into the selector. If not, it means that it is not used, and delete the selector.
If all selectors of a rule are deleted, delete the rule.
This is the implementation idea of purgecss. Let's write the code.
code implementation
Let's write a postcss plug-in to do this. The postcss plug-in does css analysis and transformation based on AST.
const purgePlugin = (options) => {
return {
postcssPlugin: 'postcss-purge',
Rule (rule) {}
}
}
module.exports = purgePlugin;
The form of postcss plug-in is a function that receives the configuration parameters of the plug-in and returns an object. Object to declare listener s such as Rule, AtRule and Decl, that is, processing functions for different asts.
The postcss plug-in is called purge and can be called as follows:
const postcss = require('postcss');
const purge = require('./src/index');
const fs = require('fs');
const path = require('path');
const css = fs.readFileSync('./example/index.css');
postcss([purge({
html: path.resolve('./example/index.html'),
})]).process(css).then(result => {
console.log(result.css);
});
The path of html passed in through the parameter can be passed through option.html in the plug-in I got it.
Next, let's implement this plug-in.
As analyzed earlier, the implementation process is divided into two steps:
- Extract the id, class and tag in html through posthtml
- Traverse the ast of css and delete the part that is not used by html
We encapsulate an htmlExtractor to do extraction:
const purgePlugin = (options) => {
const extractInfo = {
id: [],
class: [],
tag: []
};
htmlExtractor(options && options.html, extractInfo);
return {
postcssPlugin: 'postcss-purge',
Rule (rule) {}
}
}
module.exports = purgePlugin;
The specific implementation of htmlExtractor is to read the content of html, parse html, generate AST, traverse AST, and record id, class and tag:
function htmlExtractor(html, extractInfo) {
const content = fs.readFileSync(html, 'utf-8');
const extractPlugin = options => tree => {
return tree.walk(node => {
extractInfo.tag.push(node.tag);
if (node.attrs) {
extractInfo.id.push(node.attrs.id)
extractInfo.class.push(node.attrs.class)
}
return node
});
}
posthtml([extractPlugin()]).process(content);
// Filter out null values
extractInfo.id = extractInfo.id.filter(Boolean);
extractInfo.class = extractInfo.class.filter(Boolean);
extractInfo.tag = extractInfo.tag.filter(Boolean);
}
The plug-in form of posthtml is similar to that of postcss. We traverse AST and record some information in the posthtml plug-in.
Finally, filter out the null values in id, class and tag to complete the extraction.
Let's not rush to the next step. Let's test the current function first.
We prepare such an html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div class="aaa"></div>
<div id="ccc"></div>
<span></span>
</body>
</html>
Information extracted under test:
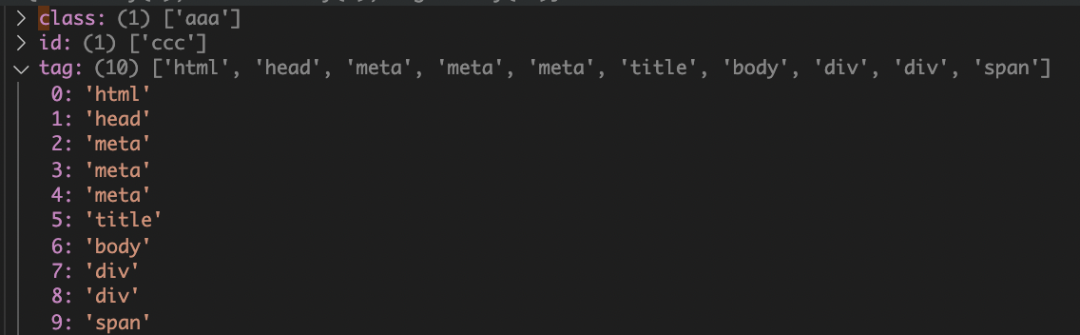
As you can see, id, class and tag are correctly extracted from html.
Next, we continue to do the next step: delete the unused part from the AST of css.
We have declared the listener of the rule and can get the AST of the rule. The selector part to be analyzed needs to be split according to "," and then processed for each selector.
Rule (rule) {
const newSelector = rule.selector.split(',').map(item => {
// Convert each selector
}).filter(Boolean).join(',');
if(newSelector === '') {
rule.remove();
} else {
rule.selector = newSelector;
}
}
Selectors can use postcss selector parser to parse, analyze, and transform.
If all selectors after processing are deleted, it means that the style of the rule is useless. Delete the rule. Otherwise, you may just delete some selectors, and the style will be used.
const newSelector = rule.selector.split(',').map(item => {
const transformed = selectorParser(transformSelector).processSync(item);
return transformed !== item ? '' : item;
}).filter(Boolean).join(',');
if(newSelector === '') {
rule.remove();
} else {
rule.selector = newSelector;
}
Next, implement the analysis and transformation of the selector, that is, the transformSelector function.
The logic of this part is to judge whether each selector is in the selector extracted from html. If not, delete it.
const transformSelector = selectors => {
selectors.walk(selector => {
selector.nodes && selector.nodes.forEach(selectorNode => {
let shouldRemove = false;
switch(selectorNode.type) {
case 'tag':
if (extractInfo.tag.indexOf(selectorNode.value) == -1) {
shouldRemove = true;
}
break;
case 'class':
if (extractInfo.class.indexOf(selectorNode.value) == -1) {
shouldRemove = true;
}
break;
case 'id':
if (extractInfo.id.indexOf(selectorNode.value) == -1) {
shouldRemove = true;
}
break;
}
if(shouldRemove) {
selectorNode.remove();
}
});
});
};
We have completed the extraction of selector information in html and the deletion of useless rule s by css according to the information extracted from html. The function of the plug-in has been completed.
Let's test the effect:
css:
.aaa, ee , ff{
color: red;
font-size: 12px;
}
.bbb {
color: red;
font-size: 12px;
}
#ccc {
color: red;
font-size: 12px;
}
#ddd {
color: red;
font-size: 12px;
}
p {
color: red;
font-size: 12px;
}
span {
color: red;
font-size: 12px;
}
html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div class="aaa"></div>
<div id="ccc"></div>
<span></span>
</body>
</html>
Logically, p, #ddd The selectors and styles of bbb, ee and ff will be deleted.
We use this plug-in:
const postcss = require('postcss');
const purge = require('./src/index');
const fs = require('fs');
const path = require('path');
const css = fs.readFileSync('./example/index.css');
postcss([purge({
html: path.resolve('./example/index.html'),
})]).process(css).then(result => {
console.log(result.css);
});
After testing, the function is correct:
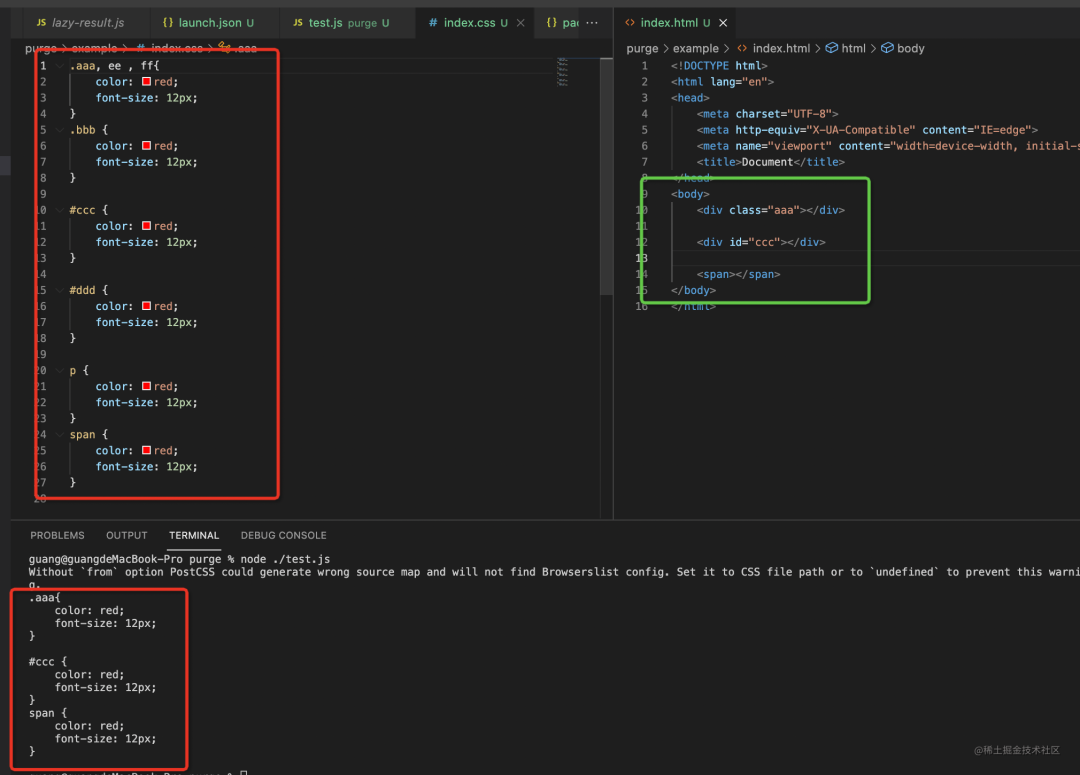

This is the implementation principle of PurgeCss. We have completed the three shaking of css!
The code was uploaded to GitHub: https://github.com/QuarkGluonPlasma/postcss-plugin-exercize
Of course, we only implement the simple version, and some places are not perfect:
- Only html extractors are implemented, while PurgeCss also has jsx, pug, tsx and other extractors (but the idea is the same)
- Only a single file is processed, not multiple files (just add a loop)
- Only id, class and tag selectors are processed, but attribute selectors are not processed (the processing of attribute selectors is slightly more complicated)
Although it is not perfect, the implementation idea of PurgeCss has been passed, isn't it ~
summary
The TreeShking of JS uses Webpack and Terser, while the TreeShking of CSS uses PurgeCss.
We implemented a simple version of PurgeCss to clarify its implementation principle:
The selector information in html is extracted through the HTML extractor, and then the AST of CSS is filtered. Unused rules are deleted according to whether the rule selector is used or not, so as to achieve the purpose of TreeShking.
In the process of implementing this tool, we learned the writing methods of postcss and posthtml plug-ins, which are very similar in form, but one is for css analysis and transformation, and the other is for html.
Postcss can analyze and transform css. For example, deleting useless css here is a good application. Have you seen other great application scenarios of postcss? Let's discuss them together ~