Thesis Name: segnet: a deep revolutionary encoder decoder architecture for image
Segmentation
Paper link: SegNet
Project address: Segnet Cafe version
Motivation
1. Deep learning needs to extract the high-order semantic features of the image and needs continuous down sampling. Continuous down sampling will lead to the loss of image boundary information. How to retain the boundary information of high-order semantic features as much as possible and better achieve the mapping relationship between high-order semantic features and the original input resolution image is the main content of this paper.
2. How to design the segmentation model to achieve end-to-end, and the model needs to take into account the problems of memory and computation? This paper mainly draws lessons from FCN and has made a lot of innovations.
Contributions
- An efficient deep convolution neural network for semantic segmentation is proposed
- It is compared with the current mainstream segmentation networks FCN and Deeplab.
Methods

1. Encoder:
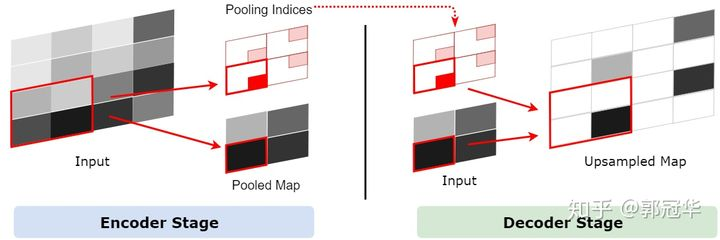
SegNet uses the first 13 convolution layers of VGGNet16 and removes the corresponding full connection layer. Similar to our current backbone network, convolution layer + BN layer + ReLU layer, Encoder is to obtain the high-order semantic features of the image. It should be noted that SegNet will retain the position of each max pool (i.e. the corresponding position of 2x2 area - > 1x1 area)
2. Decoder encoder
There is an uncertainty in the up sampling, that is, a 1x1 feature point will become a 2x2 feature area after up sampling, one 1x1 area in this area will be replaced by the original 1x1 feature point, and the other three areas are empty. But which 1x1 region will be replaced by the original feature points? One way is to randomly assign the feature point to any position, or simply assign it to a fixed position. But doing so will undoubtedly introduce some errors, and these errors will be passed to the next layer. The deeper the number of layers, the greater the range of error influence. Therefore, it is very important to put 1x1 feature points in the correct position.
SegNet saves the source information of pooling points through a method called pooling indexes. In the pooling layer processing of the Encoder, it will record which area of 2x2 each pooled 1x1 feature point comes from. This information is called pooling indexes in the paper. Pooling indexes will be used in the Decoder. Since SegNet is a symmetric network, when the feature map needs to be upsampled in the Decoder, we can use the pool indexes of its corresponding pool layer to determine where a 1x1 feature point should be placed in the 2x2 area after upsampling. The of this process is shown in the figure below.
Here is the difference between UNet and Deconv:
-
Difference from U-Net:
Instead of using pooled location index information, U-Net transmits the whole feature map of the coding stage to the corresponding decoder (at the expense of more memory), connects it, and then upsamples (through deconvolution) to obtain the decoder feature map. -
Difference from Deconv:
Deconvnet has more parameters, requires more computing resources, and is difficult to carry out end-to-end training, mainly because of the use of the full connection layer.
It may be easier to understand through the code. Combine the above contents with the code to basically complete this paper.
import numpy as np
a = [[1,2,1,2], [3,4,3,4],[1,2,1,2],[3,4,3,4]]
b = torch.Tensor(a) # Initialize tensor
print(b)
--------------------------------------------------------------------------
Output:
tensor([[1., 2., 1., 2.],
[3., 4., 3., 4.],
[1., 2., 1., 2.],
[3., 4., 3., 4.]])
---------------------------------------------------------------------------
import torch.nn as nn
pool_test = nn.MaxPool2d(2, 2, return_indices=True, ceil_mode=True)
b = b.reshape(1, 1, 4, 4)
c, inx = pool_test(b) # Max the tensor_ pooling
print(c)
print(inx)
---------------------------------------------------------------------------
Output:
c: tensor([[[[4., 4.],
[4., 4.]]]])
inx : tensor([[[[ 5, 7],
[13, 15]]]])
---------------------------------------------------------------------------
unpool_test = nn.MaxUnpool2d(2, 2)
shape_b = b.size()[2:]
up = unpool_test(c, inx, shape_b)
print(up)
print(b + up)
---------------------------------------------------------------------------
Output:
up : tensor([[[[0., 0., 0., 0.],
[0., 4., 0., 4.],
[0., 0., 0., 0.],
[0., 4., 0., 4.]]]])
up + b : tensor([[[[1., 2., 1., 2.],
[3., 8., 3., 8.],
[1., 2., 1., 2.],
[3., 8., 3., 8.]]]])
The above is the most important Decoder idea of SegNet, unpooling. At present, many networks use bilinear interpolation to do upsample. If you are interested, you can try two ways to affect the results~