Previous review: https://blog.csdn.net/weixin_44718708/article/details/121683066
catalogue
3, Description of new functions
3. Prompt information column No
1, Synopsis
GetExcelUtil4.2. The import tool updates and optimizes a record according to the requirements of the actual work application scenario:
1. Add @ DynamicRank annotation function to support obtaining dynamic header and corresponding fields. At present, only the dynamic header after the fixed header is supported.
2. Add support for repeatability detection.
3. Add @ Transform annotation function to support the conversion of field values.
4. Optimization:
(1) when annotating the numeric format (@ ExcelNumberFormat), the field will be automatically converted to 0 in case of null value
(2) when the start mark is set, the calibration position is changed to subject to the title bar (take the data line and push one line ahead)
(3) the serial number of the digital column prompted by the abnormal information is calibrated to the corresponding alphabetic serial number
2, Scenario requirements
Our fourth version of the tool only supports entity classes to receive data.
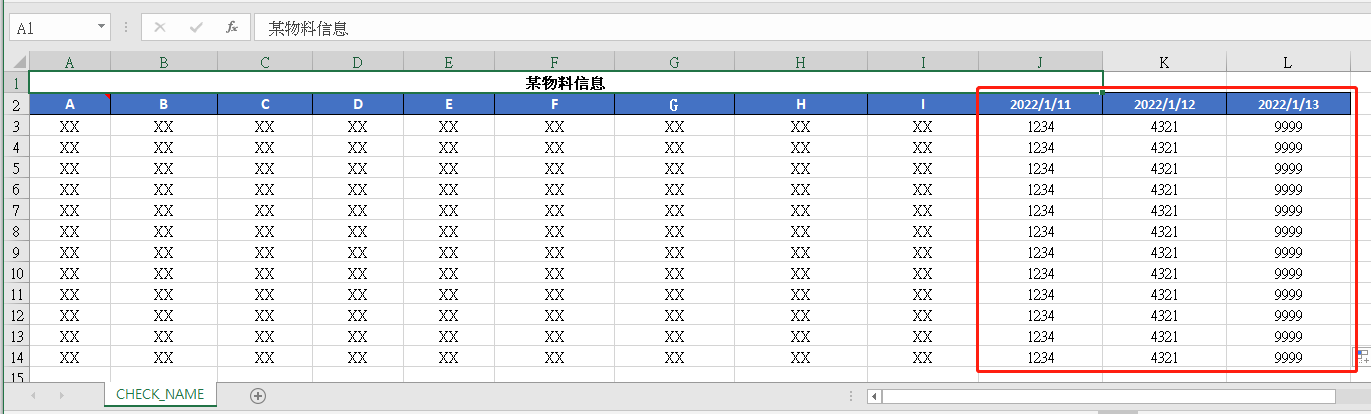
As shown in the figure, A-I is a fixed field, and the date in the red box behind it is the arrival date and quantity written according to the actual arrival information. It is not a fixed field.
The data of column A-I can be obtained by defining the corresponding number and type of entity class fields. The dynamic fields after column I cannot be defined and obtained within the same entity class. According to the original version 4.1, directly use List < string > to obtain the dynamic header, and then use List < double > to traverse and obtain the data under the corresponding column of the header according to the length of the dynamic header List. Assemble the fixed column data, dynamic header data and data under the header column according to the order.
According to the previous version 4.1 method, the amount of code is a little large, and secondary traversal is generated. Therefore, version 4.2 is added, and the function of obtaining dynamic fields is added.
3, Description of new functions
1. @DynamicRank
/**
* excel When taking value, get the dynamic header and the header fields corresponding to this line (/ column)
* 1. Annotations apply to List type fields
* 2. titleRank Indicates the row (/ column) of the header, which is required (horizontal table represents row order, vertical table represents column order)
* 3. From the current to the last header and corresponding data field
* 4. As for the last field of the entity class, other fields after this field will not be assigned
* 5. enableDuplicateCheck Reproducibility check:
* (1)Implementation of equals method depending on entity class
* (2)It will affect the value selection efficiency to a certain extent (depending on the amount of data). It is not necessary to open it
*/
@Target(value = ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DynamicRank {
int titleRank();
boolean enableDuplicateCheck() default false;
}@The DynamicRank annotation is used to obtain the dynamic field after the fixed field, which is compatible with horizontal and vertical tables. This annotation acts on the field of List type in the entity class. The field using this annotation will be regarded as the last assignment field of the entity class. To ensure the successful acquisition of the value of the dynamic field, it is important to ensure that the field type used for the value is List < dto >.
@DynamicRank contains two parameters, titleRank and enabledduplicatecheck:
(1) titleRank is a numeric type, indicating the column (row / column, numeric sequence number) where the header is located. The field annotated by @ DynamicRank will get the corresponding field value of dynamic header and header by default. The column where the header is located needs to be provided correctly. DTO in annotated list < DTO > usually contains only two fields, header and field value. When assigning values to fields in this DTO, the @ DynamicRank annotation will be ignored.
(2) Enabledduplicatecheck is of boolean type, indicating whether to enable data repeatability detection. When the value is true, a DataDuplicationException will be thrown if the currently obtained DTO data is repeated with other obtained DTOs. The rules for judging repetition will be described later.
Receive Excel data entity:
@Data
public class Test1DTO {
... ...
@DynamicRank(titleRank = 2, enableDuplicateCheck = true)
private List<Test2DTO> dataList;
... ...
}Receive dynamic field entity:
@Data
public class Test2DTO {
@ExcelDateFormat(message = "Date format must be yyyy/MM/dd!")
private String arriveDate;
@ExcelNumberFormat(format = "#", message =" quantity must be a positive integer! ")
private Integer arriveQty;
// Customize equals according to business needs
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj instanceof Test2DTO) {
Test2DTO another = (Test2DTO) obj;
return this.arriveDate.equals(another.getArriveDate());
}
return false;
}
}2. Repeatability test
The value method of version 4.1 is as follows:
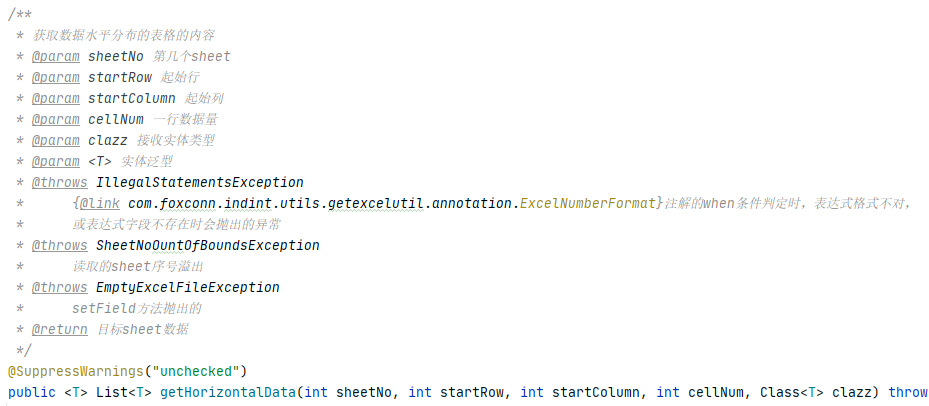
Version 4.2 is like this:
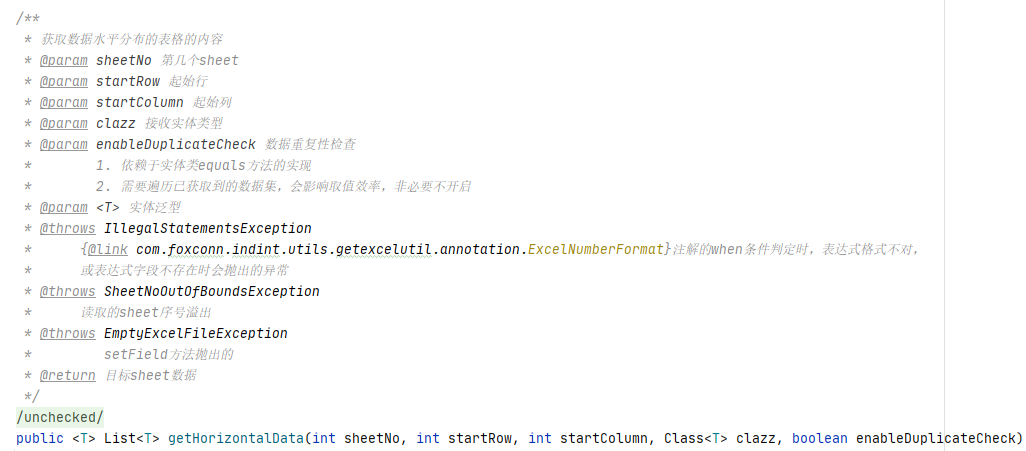
Through comparison, it can be found that version 4.2 adds a boolean type parameter:

Special attention:
(1) The rule of repeatability detection depends on the equals method of the value taking DTO. When using, you should rewrite the equals method in the value taking DTO according to your business needs. Otherwise, when enabledduplicatecheck is true, the equals method (compare Object address) of the parent Object will be called, and duplicate data in business logic will not be detected.
(2) When the amount of data is large enough, turning on repeatability detection will increase the overhead. The repeatability detection function is to traverse and compare the currently obtained data with the previously successfully obtained data List, and throw DataDuplicationException when repeating. If there are 1 million pieces of data obtained, and the 1 million pieces of data are currently obtained, it is necessary to re traverse the 999999 pieces of data previously obtained. Therefore, the requirement for data repeatability is not high, and it is not recommended to start the business with a large amount of imported data. Of course, when the requirement of data repeatability is high, the data traversal overhead is necessary.
Add a method that does not perform repeatability detection by default:

Rewrite the equals method according to business needs (@ Override can be omitted, but it is recommended to keep it and standardize it to prevent spelling errors):
@Data
public class Test1DTO {
@NotNull(message = "A Cannot be empty!")
private String a;
@NotNull(message = "B Cannot be empty!")
private String b;
@NotNull(message = "C Cannot be empty!")
private String c;
@NotNull(message = "D Cannot be empty!")
private String d;
@NotNull(message = "E Cannot be empty!")
private String e;
@NotNull(message = "F Cannot be empty!")
private String f;
@ValueLimit(limit = {"value1", "value2"}, message = "G Only for value1,value2")
@Transform(expressions = {"value1 -> 1", "value2 -> 2"})
private Integer g;
private String h;
private Integer i;
@DynamicRank(titleRank = 2, enableDuplicateCheck = true)
private List<Test2DTO> dataList;
// Customize equals according to business needs
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj instanceof Test1DTO) {
Test1DTO another = (Test1DTO) obj;
return this.a.equals(another.getA())
&& this.b.equals(another.getB())
&& this.c.equals(another.getC())
&& this.d.equals(another.getD())
&& this.e.equals(another.getE())
&& this.f.equals(another.getF())
&& this.g.equals(another.getG());
}
return false;
}
}In addition, as can be seen from the figure, the number of fields parameter cellNum in the method is removed in version 4.2, and the number of values is subject to the number of entity class fields. Therefore, when determining the DTO field, it is necessary to clarify the fields to be obtained.
3. @Transform
In order to meet the requirements of value conversion obtained by the field, version 4.2 adds the @ Transform annotation function:
/**
* excel When the value is taken, the specified value changes to another value
* Expression: a - > b
*/
@Target(value = ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface Transform {
String[] expressions();
}
instructions:
(1) The expression format of annotation parameter expressions is "a - > b", a is the value to be transformed, and B is the transformed value, which are separated by an arrow "-". The expression means that when the field value is a, it is automatically converted to B.
(2) It can be used with @ ValueLimit annotation, @ ValueLimit limits the range of values, and @ Transform specifies the transformation of values within the range. This matching scenario includes: a material has two statuses, "in stock" and "out of stock", which are represented by numbers 1 and 2 respectively. The following example of @ Transform is an example of this class.
@Use examples of Transform:
@Data
public class Test1DTO {
... ...
@ValueLimit(limit = {"value1", "value2"}, message = "G Only for value1,value2")
@Transform(expressions = {"value1 -> 1", "value2 -> 2"})
private Integer g;
... ...
}4, Optimization description
1. @ExcelNumberFormat
@Originally, ExcelNumberFormat threw an exception when encountering a null value. Instead, it directly assigned a value of 0 when encountering a null value to optimize the user experience.
2. Starting mark
The reading position of the start flag is changed from the data start column to the header column (read data start column) to prevent users from overwriting the start flag when inserting data into the template.
original:
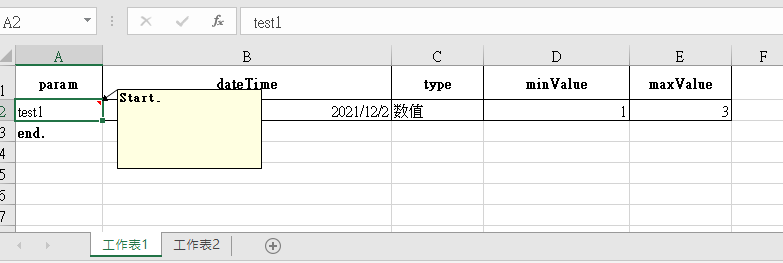
4.2 version:
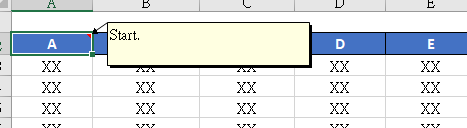
Sign Description:
1. The function of the start flag is to prevent the user from importing data after modifying the template format. For example, if the header column position is modified (for example, the header row of the template is 4, and the user changes to 1 after modifying the template format), the data field deviates from the expectation, resulting in incomplete data reading (2-4 rows of data cannot be obtained) or excessive reading of irrelevant data, which the user cannot perceive. After adding the start flag, if the start line does not correspond to the expectation, an IllegalArgumentException exception will be thrown to stop the operation. After the exception is intercepted, the prompt information will be extracted to inform the user to ensure the correctness of the data.
2. The function of the end flag is similar to that of the start flag. The end flag is used as the end of the data to prevent the user from inserting invisible irrelevant data after the end of the data and affecting the data reading accuracy (such as the font set to white). However, this situation is relatively rare. The tool class has made the processing of terminating the data and reading the returned results in case of empty lines (including all blank lines), so the end flag is rarely used.
*3. One more word, the tool class can obtain the sheet name. If necessary, set the sheet name of the template to a specific name, and judge whether the obtained sheet name is consistent with the expected name at the business layer, so as to judge whether the user uses the given template for data upload.
3. Prompt information column No
The original prompt message is similar to the following:
Line 2, column 55 of file worksheet 1: incorrect date format!
It's a little unfriendly to find the 55th column in the excel document. Now, all the prompts related to the column order and serial numbers are corresponding to the letter column order in Excel. As follows:
Row 2, column BC of file worksheet 1: incorrect date format!
5, GitHub address
https://github.com/BadGuy-Darren/MyExcelImportTool.git/4.2/
Not packaged as a jar dependency package. The packaging tutorial is available online. It's very simple.