These days, the company needs to do text classification, read some articles, various machine learning, neural network, do not understand. I have done a simple text classification function with the combination of stuttering and segmentation, which is OK in general.
Operation result:
It's written by myself. It's convenient. Anyway, it's semi-automatic and doesn't pay much attention to the process. After reading it, I can change it for myself to make it more convenient.
First of all, there must be data. I am the news website that I climb and get all kinds of data.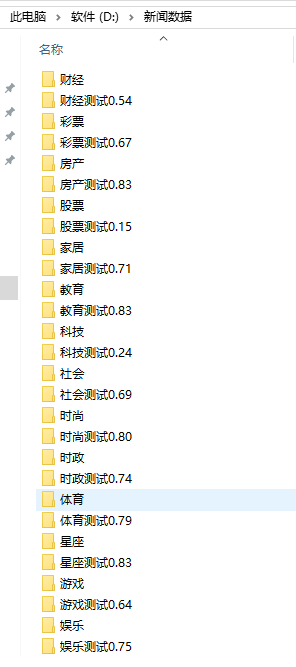
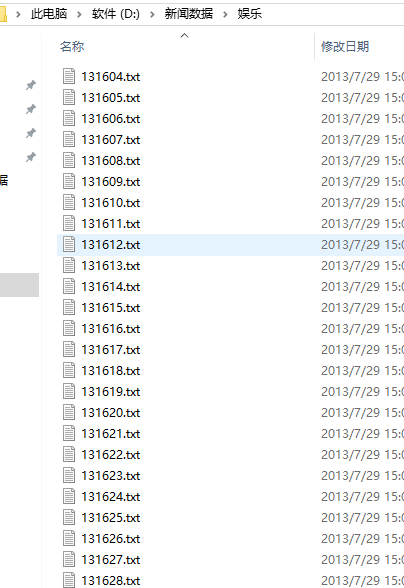
With the data, you can write this code.
The first is training data, which is to process the article into the desired format.
The first part of the code is to take out the article and then save it after stuttering the participle:
import jieba
import os
file_dir = 'D:\News data\entertainment'
for root, dirs, files in os.walk(file_dir):
# print(root) # Current directory path
# print(dirs) # All subdirectories under the current path
# print(files) # All non directory sub files under the current path
for x in files:
try:
path = root + '\\' + x
print(path)
with open(path, "r+", encoding="utf-8") as f:
content = f.read().replace('\n', '')
#There is no stopwords to download on the Internet. This is a stop word, which is used to remove those meaningless words.
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
# Full mode
test1 = jieba.cut(content, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
#Remove the words with length less than 2, because the meaning of a word is not too big, of course, it doesn't matter if you don't want to remove it.
if len(x)>=2:
if x not in stopwords:
with open("D:\Processing news data\entertainment.txt", "a+", encoding="utf-8") as f:
f.write(x + ",")
print(x)
except:
pass
Don't forget to create a folder to store the data. My job is to put the processed data in "D: \ process news data \ entertainment. txt"
then.... Hey hey, semi-automatic, the above code for ah, entertainment for financial, lottery, real estate ah, etc. The corresponding storage location is also changed into finance, lottery, real estate and so on. As shown in the figure below, I have handled the storage well. Those with \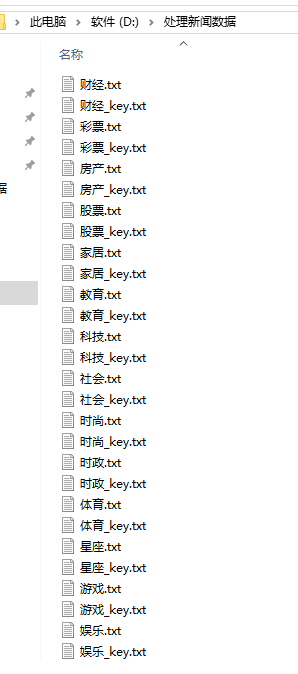
Open entertainment.txt to see what it looks like. This entertainment.txt stores the segmentation results of all the entertainment articles we get from the entertainment folder. Note here that there are not too many articles, or the entertainment. TXT file will be large. My one is so big. If it's too big, I'll run the program later. When I open it, the program will report the error of insufficient memory. So don't climb down too many articles, just a few thousand.
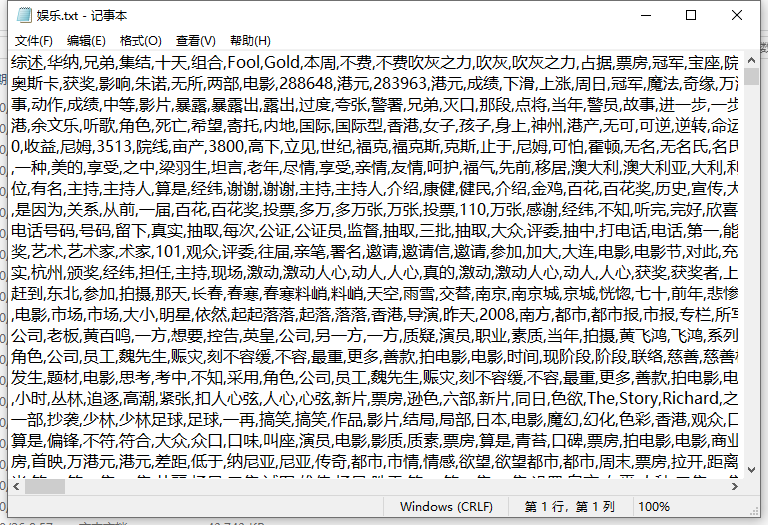
In this way, entertainment related articles are segmented and saved to a txt file.
Some students said, I don't want to change it to run it. There are several folders, which is troublesome.
Well, here you go:
Good computer cpu run full preparation, will be very stuck, anyway, my computer is very rubbish.
If you're afraid, you can run a few less at a time. I'm writing six. You can write three.
#encoding=gbk
import jieba
import os
from multiprocessing import Process
def shehui():
file_dir = 'D:\News data\Sociology'
for root, dirs, files in os.walk(file_dir):
# print(root) # Current directory path
# print(dirs) # All subdirectories under the current path
# print(files) # All non directory sub files under the current path
num=0
for x in files:
num+=1
print(file_dir,num)
try:
path = root + '\\' + x
with open(path, "r+", encoding="utf-8") as f:
content = f.read().replace('\n', '')
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
# Full mode
test1 = jieba.cut(content, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
if len(x)>=2:
if x not in stopwords:
with open("D:\Processing news data\Sociology.txt", "a+", encoding="utf-8") as f:
f.write(x + ",")
except:
pass
def shishang():
file_dir = 'D:\News data\fashion'
for root, dirs, files in os.walk(file_dir):
# print(root) # Current directory path
# print(dirs) # All subdirectories under the current path
# print(files) # All non directory sub files under the current path
num = 0
for x in files:
num += 1
print(file_dir, num)
try:
path = root + '\\' + x
with open(path, "r+", encoding="utf-8") as f:
content = f.read().replace('\n', '')
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
# Full mode
test1 = jieba.cut(content, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
if len(x)>=2:
if x not in stopwords:
with open("D:\Processing news data\fashion.txt", "a+", encoding="utf-8") as f:
f.write(x + ",")
except:
pass
def shizheng():
file_dir = 'D:\News data\Current politics'
for root, dirs, files in os.walk(file_dir):
# print(root) # Current directory path
# print(dirs) # All subdirectories under the current path
# print(files) # All non directory sub files under the current path
num = 0
for x in files:
num += 1
print(file_dir, num)
try:
path = root + '\\' + x
with open(path, "r+", encoding="utf-8") as f:
content = f.read().replace('\n', '')
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
# Full mode
test1 = jieba.cut(content, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
if len(x)>=2:
if x not in stopwords:
with open("D:\Processing news data\Current politics.txt", "a+", encoding="utf-8") as f:
f.write(x + ",")
except:
pass
def tiyu():
file_dir = 'D:\News data\Sports'
for root, dirs, files in os.walk(file_dir):
# print(root) # Current directory path
# print(dirs) # All subdirectories under the current path
# print(files) # All non directory sub files under the current path
num = 0
for x in files:
num += 1
print(file_dir, num)
try:
path = root + '\\' + x
with open(path, "r+", encoding="utf-8") as f:
content = f.read().replace('\n', '')
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
# Full mode
test1 = jieba.cut(content, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
if len(x) >= 2:
if x not in stopwords:
with open("D:\Processing news data\Sports.txt", "a+", encoding="utf-8") as f:
f.write(x + ",")
except:
pass
def xingzuo():
file_dir = 'D:\News data\constellation'
for root, dirs, files in os.walk(file_dir):
# print(root) # Current directory path
# print(dirs) # All subdirectories under the current path
# print(files) # All non directory sub files under the current path
num = 0
for x in files:
num += 1
print(file_dir, num)
try:
path = root + '\\' + x
with open(path, "r+", encoding="utf-8") as f:
content = f.read().replace('\n', '')
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
# Full mode
test1 = jieba.cut(content, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
if len(x) >= 2:
if x not in stopwords:
with open("D:\Processing news data\constellation.txt", "a+", encoding="utf-8") as f:
f.write(x + ",")
except:
pass
def youxi():
file_dir = 'D:\News data\Game'
for root, dirs, files in os.walk(file_dir):
# print(root) # Current directory path
# print(dirs) # All subdirectories under the current path
# print(files) # All non directory sub files under the current path
num = 0
for x in files:
num += 1
print(file_dir, num)
try:
path = root + '\\' + x
with open(path, "r+", encoding="utf-8") as f:
content = f.read().replace('\n', '')
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
# Full mode
test1 = jieba.cut(content, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
if len(x) >= 2:
if x not in stopwords:
with open("D:\Processing news data\Game.txt", "a+", encoding="utf-8") as f:
f.write(x + ",")
except:
pass
if __name__=='__main__':
p1=Process(target=shehui)
p2=Process(target=shishang)
p3=Process(target=shizheng)
p4=Process(target=tiyu)
p5 = Process(target=xingzuo)
p6 = Process(target=youxi)
# Running multiple processes, executing tasks
p1.start()
p2.start()
p3.start()
p4.start()
p5.start()
p6.start()
# Wait for the execution of all subprocesses to finish before executing the contents of the main process
p1.join()
p2.join()
p3.join()
p4.join()
p5.join()
p6.join()
In this way, there are six types of files under your 'D: \ process news data' folder.
ok, article processing completed successfully
Go to the next stage. This stage is to analyze the txt completed in the first stage. Those txt files are the result of segmentation of related articles in various fields, that is to say, if you have 10 entertainment articles, those entertainment. Txt files are the result of segmentation of these 10 articles. In this way, by calculating which words appear more often in this entertainment. TXT file, it means that entertainment articles prefer to use such words. In order to remember, we call it. Entertainment words (my own name). So, let's extract these words and save them. When we come across another article, let's split the words in this article and compare the words in this article with the entertainment words we used before. If many words in this article are entertainment words, we will say that it is an entertainment chapter.
This passage is a little long, I don't know how to read it several times. Here is the core idea of this code.
After understanding, code:
#Let's take out entertainment.txt
with open('D:\Processing news data\entertainment.txt', encoding='utf8') as f:
content = f.read()
data = content[:-1].split(',')
#Count the number of occurrences of all words
count = {}
for character in data:
count.setdefault(character, 0)
count[character] = count[character] + 1
#We take out all the value values stored in the count dictionary and throw them into the value list list.
value_list=[]
for key, value in count.items():
value_list.append(value)
#Then start working on the list
#Sort from small to large
value_list.sort()
#Reverse, from large to small
value_list.reverse()
#Take the first 35.
ten_list=value_list[0:35]
#These 35 are the maximum value, that is, the number of the first 35 words that appear the most times among all words.
print(ten_list)
#It's not good to know the number of words. We need to know who these 35 words are:
for key, value in count.items():
if value in ten_list:
with open("D:\Processing news data\entertainment_key.txt", "a+", encoding="utf-8") as f:
f.write(key+ ",")
print(key)
At this time, we will take out the 35 words that appear most frequently in so many articles in the entertainment field and store them in another TXT file, called entertainment _key.txt. This 35 is written by myself. It's not fixed. I can print it several times and find the most suitable quantity. If you take more than that, the words for entertainment will be less accurate. If we take less, we will use these words to match other articles later, and the chances of matching will be less. For example, you take a word, called.. "Star", later you used it to match another entertainment article, but this article didn't mention the star, so you said that this article is not an entertainment article, isn't it wrong?
The students at the top of the tou (lan) can see it again. I still need to run this part of the code once, and change the file name to generate the corresponding key file.
Well, here you are. It's the same with a multi process:
from multiprocessing import Process
def shehui():
with open('D:\Processing news data\Sociology.txt', encoding='utf8') as f:
content = f.read()
data = content[:-1].split(',')
#Calculate the number of times each word appears
count = {}
for character in data:
count.setdefault(character, 0)
count[character] = count[character] + 1
value_list=[]
for key, value in count.items():
value_list.append(value)
#Sort from small to large
value_list.sort()
#Reverse, from large to small
value_list.reverse()
#Take the first 15.
ten_list=value_list[0:20]
print(ten_list)
for key, value in count.items():
if value in ten_list:
with open("D:\Processing news data\Sociology_key.txt", "a+", encoding="utf-8") as f:
f.write(key+ ",")
print(key)
def shishang():
with open('D:\Processing news data\fashion.txt', encoding='utf8') as f:
content = f.read()
data = content[:-1].split(',')
#Calculate the number of times each word appears
count = {}
for character in data:
count.setdefault(character, 0)
count[character] = count[character] + 1
value_list=[]
for key, value in count.items():
value_list.append(value)
#Sort from small to large
value_list.sort()
#Reverse, from large to small
value_list.reverse()
#Take the first 15.
ten_list=value_list[0:35]
print(ten_list)
for key, value in count.items():
if value in ten_list:
with open("D:\Processing news data\fashion_key.txt", "a+", encoding="utf-8") as f:
f.write(key+ ",")
print(key)
def shizheng():
with open('D:\Processing news data\Current politics.txt', encoding='utf8') as f:
content = f.read()
data = content[:-1].split(',')
#Calculate the number of times each word appears
count = {}
for character in data:
count.setdefault(character, 0)
count[character] = count[character] + 1
value_list=[]
for key, value in count.items():
value_list.append(value)
#Sort from small to large
value_list.sort()
#Reverse, from large to small
value_list.reverse()
#Take the first 15.
ten_list=value_list[0:35]
print(ten_list)
for key, value in count.items():
if value in ten_list:
with open("D:\Processing news data\Current politics_key.txt", "a+", encoding="utf-8") as f:
f.write(key+ ",")
print(key)
def tiyu():
with open('D:\Processing news data\Sports.txt', encoding='utf8') as f:
content = f.read()
data = content[:-1].split(',')
#Calculate the number of times each word appears
count = {}
for character in data:
count.setdefault(character, 0)
count[character] = count[character] + 1
value_list=[]
for key, value in count.items():
value_list.append(value)
#Sort from small to large
value_list.sort()
#Reverse, from large to small
value_list.reverse()
#Take the first 15.
ten_list=value_list[0:35]
print(ten_list)
for key, value in count.items():
if value in ten_list:
with open("D:\Processing news data\Sports_key.txt", "a+", encoding="utf-8") as f:
f.write(key+ ",")
print(key)
def xingzuo():
with open('D:\Processing news data\constellation.txt', encoding='utf8') as f:
content = f.read()
data = content[:-1].split(',')
#Calculate the number of times each word appears
count = {}
for character in data:
count.setdefault(character, 0)
count[character] = count[character] + 1
value_list=[]
for key, value in count.items():
value_list.append(value)
#Sort from small to large
value_list.sort()
#Reverse, from large to small
value_list.reverse()
#Take the first 15.
ten_list=value_list[0:35]
print(ten_list)
for key, value in count.items():
if value in ten_list:
with open("D:\Processing news data\constellation_key.txt", "a+", encoding="utf-8") as f:
f.write(key+ ",")
print(key)
def youxi():
with open('D:\Processing news data\Game.txt', encoding='utf8') as f:
content = f.read()
data = content[:-1].split(',')
#Calculate the number of times each word appears
count = {}
for character in data:
count.setdefault(character, 0)
count[character] = count[character] + 1
value_list=[]
for key, value in count.items():
value_list.append(value)
#Sort from small to large
value_list.sort()
#Reverse, from large to small
value_list.reverse()
#Take the first 15.
ten_list=value_list[0:35]
print(ten_list)
for key, value in count.items():
if value in ten_list:
with open("D:\Processing news data\Game_key.txt", "a+", encoding="utf-8") as f:
f.write(key+ ",")
print(key)
if __name__=='__main__':
p1=Process(target=shehui)
p2=Process(target=shishang)
p3=Process(target=shizheng)
p4=Process(target=tiyu)
p5 = Process(target=xingzuo)
p6 = Process(target=youxi)
# Running multiple processes, executing tasks
p1.start()
p2.start()
p3.start()
p4.start()
p5.start()
p6.start()
# Wait for the execution of all subprocesses to finish before executing the contents of the main process
p1.join()
p2.join()
p3.join()
p4.join()
p5.join()
p6.join()
At this time, we take out the second stage of entertainment words, finance words, sports words, and all kinds of words, and then we end up looking for an article, and then we split up. Word segmentation, and then, compared with our various words, guess what kind of article he is.
Upper Code:
Add or delete according to your own classification. Then go to all kinds of news websites to copy all kinds of articles and put them into the test. txt file. Run it to see if the program can guess which kind of articles you are copying.
#encoding=gbk
from jieba.analyse import *
import jieba
import os
#Read test article
with open('test.txt',encoding='utf8') as f:
data = f.read()
#Read keywords of each category
with open('D:\Processing news data\Finance_key.txt',encoding='utf8') as f:
data_caijing = f.read()[:-1].split(',')
with open('D:\Processing news data\lottery_key.txt',encoding='utf8') as f:
data_caipiao= f.read()[:-1].split(',')
with open('D:\Processing news data\House property_key.txt',encoding='utf8') as f:
data_fangcan = f.read()[:-1].split(',')
with open('D:\Processing news data\shares_key.txt',encoding='utf8') as f:
data_gupiao = f.read()[:-1].split(',')
with open('D:\Processing news data\Home Furnishing_key.txt',encoding='utf8') as f:
data_jiaju = f.read()[:-1].split(',')
with open('D:\Processing news data\education_key.txt',encoding='utf8') as f:
data_jiaoyu = f.read()[:-1].split(',')
with open('D:\Processing news data\science and technology_key.txt',encoding='utf8') as f:
data_keji= f.read()[:-1].split(',')
with open('D:\Processing news data\Sociology_key.txt',encoding='utf8') as f:
data_shehui = f.read()[:-1].split(',')
with open('D:\Processing news data\fashion_key.txt',encoding='utf8') as f:
data_shishang = f.read()[:-1].split(',')
with open('D:\Processing news data\Current politics_key.txt',encoding='utf8') as f:
data_shizheng= f.read()[:-1].split(',')
with open('D:\Processing news data\Sports_key.txt',encoding='utf8') as f:
data_tiyu = f.read()[:-1].split(',')
with open('D:\Processing news data\constellation_key.txt',encoding='utf8') as f:
data_xingzuo = f.read()[:-1].split(',')
with open('D:\Processing news data\Game_key.txt',encoding='utf8') as f:
data_youxi= f.read()[:-1].split(',')
with open('D:\Processing news data\entertainment_key.txt',encoding='utf8') as f:
data_yule = f.read()[:-1].split(',')
#Define an empty list and store the same keywords as the test set later
caijing_list=[]
caipiao_list=[]
fangcan_list=[]
gupiao_list=[]
jiaju_list=[]
jiaoyu_list=[]
keji_list=[]
shehui_list=[]
shishang_list=[]
shizheng_list=[]
tiyu_list=[]
xingzuo_list=[]
youxi_list=[]
yule_list=[]
# Load stop words
stopwords = [line.strip() for line in open('stopwords.txt', 'r', encoding='utf-8').readlines()]
#Word segmentation, take out the keywords of the test data and determine which categories of keyword files these keywords are in, and then save these words in the corresponding list
test1 = jieba.cut(data, cut_all=True)
list_test1 = list(test1)
for x in list_test1:
if len(x) >= 2:
if x not in stopwords:
if x in data_keji:
print(x,'In technology')
keji_list.append(x)
if x in data_tiyu:
print(x, 'In sports')
tiyu_list.append(x)
if x in data_caijing:
print(x, 'In finance and Economics')
caijing_list.append(x)
if x in data_caipiao:
print(x, 'In the lottery')
caipiao_list.append(x)
if x in data_fangcan:
print(x, 'In real estate')
fangcan_list.append(x)
if x in data_gupiao:
print(x, 'In stocks')
gupiao_list.append(x)
if x in data_jiaju:
print(x, 'At home')
jiaju_list.append(x)
if x in data_jiaoyu:
print(x, 'In Education')
jiaoyu_list.append(x)
if x in data_shehui:
print(x, 'In society')
shehui_list.append(x)
if x in data_shishang:
print(x, 'In fashion')
shishang_list.append(x)
if x in data_shizheng:
print(x, 'In current politics')
shizheng_list.append(x)
if x in data_xingzuo:
print(x, 'Constellation')
xingzuo_list.append(x)
if x in data_youxi:
print(x, 'In game')
youxi_list.append(x)
if x in data_yule:
print(x, 'In entertainment')
yule_list.append(x)
# Len (Keji & list): so that we can know how many words in our test articles are related to technology
# dic1 ['technology'] = len: compose key value pairs and put them into the dictionary
#Build an empty dictionary
dic1={}
len_keji=len(keji_list)
dic1['science and technology']=len_keji
len_tiyu=len(tiyu_list)
dic1['Sports']=len_tiyu
len_caijing=len(caijing_list)
dic1['Finance']=len_caijing
len_caipiao=len(caipiao_list)
dic1['lottery']=len_caipiao
len_fangcan=len(fangcan_list)
dic1['House property']=len_fangcan
len_gupiao=len(gupiao_list)
dic1['shares']=len_gupiao
len_jiaju=len(jiaju_list)
dic1['Home Furnishing']=len_jiaju
len_jiaoyu=len(jiaoyu_list)
dic1['education']=len_jiaoyu
len_shehui=len(shehui_list)
dic1['Sociology']=len_shehui
len_shishang=len(shishang_list)
dic1['fashion']=len_shishang
len_shizheng=len(shizheng_list)
dic1['Current politics']=len_shizheng
len_xingzuo=len(xingzuo_list)
dic1['constellation']=len_xingzuo
len_youxi=len(youxi_list)
dic1['Game']=len_youxi
len_yule=len(yule_list)
dic1['entertainment']=len_yule
print(dic1)
#Find out the maximum value, that is to say, the corresponding category appears the most times in the test article, so you can guess that this article is the category article.
for key,value in dic1.items():
if(value == max(dic1.values()))and value!=0:
print(key,value)
if key=='science and technology':
print('This article should be classified as technology')
if key=='Sports':
print('This article should be classified as sports')
if key == 'Finance':
print('This article should be classified as finance and Economics')
if key=='lottery':
print('This article should be classified as lottery')
if key=='House property':
print('This article should be classified as real estate')
if key=='shares':
print('This article should be classified as stock')
if key=='Home Furnishing':
print('This article should be classified as home furnishing')
if key=='education':
print('This article should be classified as education')
if key=='Sociology':
print('The classification of this article should be society')
if key=='fashion':
print('This article should be classified as fashion')
if key=='Current politics':
print('This article should be classified as current affairs')
if key=='constellation':
print('The classification of this article should be constellation')
if key=='Game':
print('This article should be classified as a game')
if key == 'entertainment':
print('This article should be classified as entertainment')
else:
pass
Operation result:
Copy a piece of scientific and technological

Another Entertainment
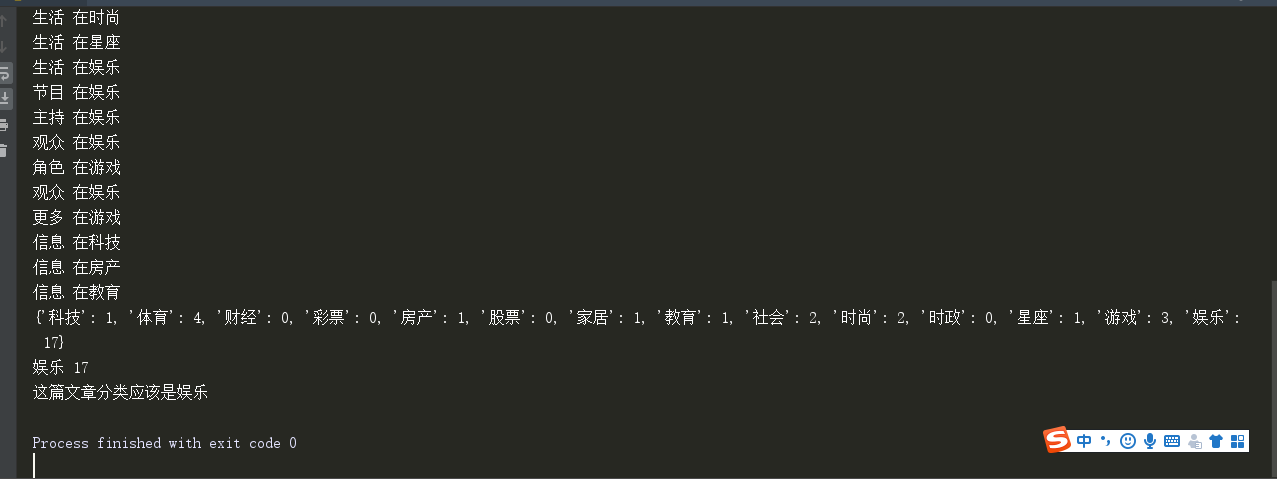
After my test, the result is OK.
The difference and number of training articles will affect the final prediction results. The prediction accuracy of my stock and technology articles is much lower.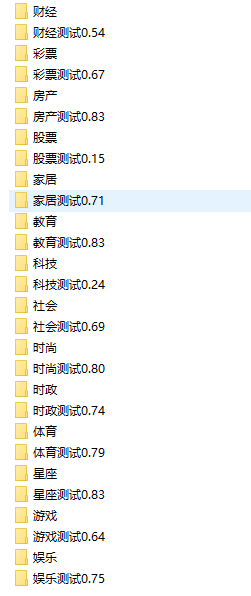
After work, I will send out the understanding of the fasttest I saw tomorrow and learn together.
If you have any suggestions or opinions, please leave a message, spray, or consult.