Hive improved chapter
Use of Hive
Hive's bucket table
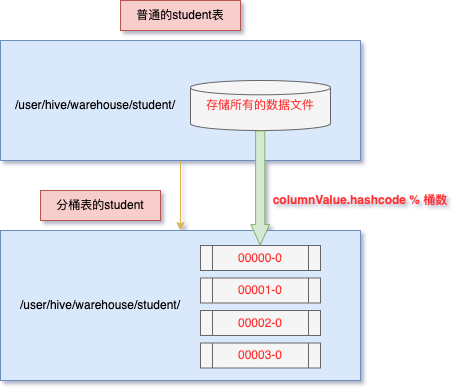
1. Principle of drum dividing table
- Bucket splitting is a more fine-grained partition relative to partition. Hive table or partition table can further divide buckets
- Divide the bucket, take the hash value of the whole data content according to a column, and determine which bucket the record is stored in by taking the modulus of the number of buckets; Data with the same hash value enters the same file
- For example, the name attribute is divided into three buckets, that is, the hash value of the name attribute value is fetched to 3, and the data bucket is divided according to the module result.
- The data record with the modulus result of 0 is stored in a file
- The data record with the mold result of 1 is stored in a file
- The data record with mold result of 2 is stored in a file
2. Function of bucket table
- sampling is more efficient. If there is no bucket division, the entire data set needs to be scanned.
- Improve the efficiency of some query operations, such as map side join.
3. Case demonstration
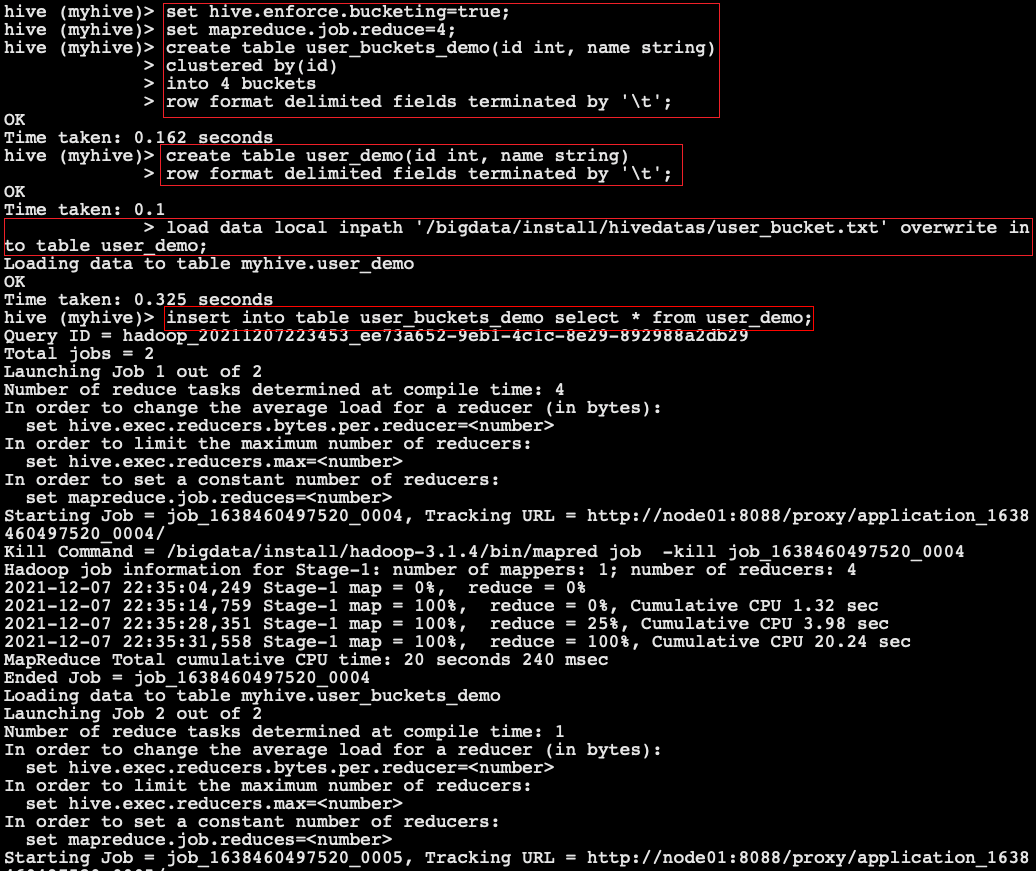
- Commands to execute before creating a bucket table
# Enable support for bucket splitting table set hive.enforce.bucketing=true; # Set the same number of reduce as the bucket (there is only one reduce by default) set mapreduce.job.reduces=4;
- Create bucket table:
use myhive; create table user_buckets_demo(id int, name string) clustered by(id) into 4 buckets row format delimited fields terminated by '\t'; -- Create normal table create table user_demo(id int, name string) row format delimited fields terminated by '\t';
- Data file user_bucket.txt
1 anzhulababy1 2 anzhulababy2 3 anzhulababy3 4 anzhulababy4 5 anzhulababy5 6 anzhulababy6 7 anzhulababy7 8 anzhulababy8 9 anzhulababy9 10 anzhulababy10
- Load data:
# Load data into normal table user_ In demo load data local inpath '/bigdata/install/hivedatas/user_bucket.txt' overwrite into table user_demo; # Load data into bucket table_ buckets_ In demo insert into table user_buckets_demo select * from user_demo;
- View the data directory of the table on hdfs:
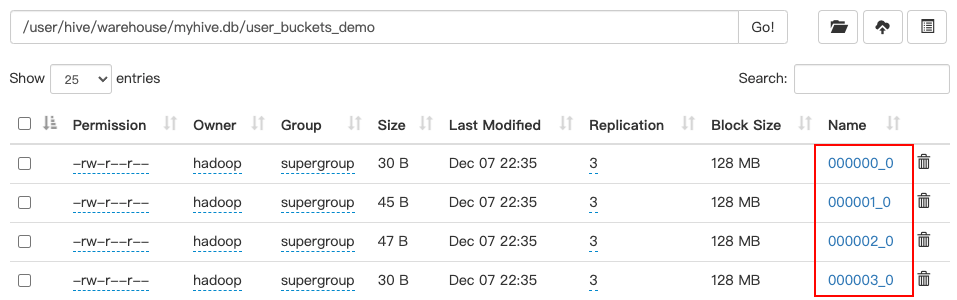
After hive3.x, you can directly load data into the bucket splitting table without inserting data into the bucket splitting table through the insert... select statement
Note: if you want to load directly into buckets, you need to load files from hdfs instead of local
load data inpath '/user/hive/warehouse/myhive.db/user_demo' overwrite into table myhive.user_buckets_demo;
Hive data import
1. Insert data directly into the table (strongly not recommended)
hive (myhive)> create table score3 like score;
hive (myhive)> insert into table score3 partition(month = '201807') values('001', '002', '100');
2. Load data through load (must master)
- Syntax:
load data [local] inpath 'dataPath' [overwrite] into table student [partition(partcol1=val1,...)];
- Load data in load mode
hive (myhive)> load data local inpath '/bigdata/install/hivedatas/score.csv' into table score partition(month='201806');
3. Load data through query (must master)
- Syntax: Official website address
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
- example:
hive (myhive)> create table score5 like score; hive (myhive)> insert overwrite table score5 partition(month = '201806') select s_id,c_id,s_score from score;
4. Create a table and load data in the query statement (as select)
- Save the query results to a table
hive (myhive)> create table score6 as select * from score;
5. Specify location when creating a table
- Create a table and specify the location on hdfs
hive (myhive)> create external table score7 (s_id string,c_id string,s_score int) row format delimited fields terminated by '\t' location '/myscore7';
- When uploading data to hdfs, we can also directly operate the data of hdfs through the dfs command under the hive client
hive (myhive)> dfs -mkdir -p /myscore7; hive (myhive)> dfs -put /bigdata/install/hivedatas/score.csv /myscore7;
- Query data
hive (myhive)> select * from score7;
6. export and import hive table data (internal table operation)
hive (myhive)> create table teacher2 like teacher; -- Export to hdfs route hive (myhive)> export table teacher to '/user/teacher'; hive (myhive)> import table teacher2 from '/user/teacher';
Hive data export
1. insert export
- Official documents
- grammar
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 [ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0) SELECT ... FROM ...
- Export query results to local
insert overwrite local directory '/bigdata/install/hivedatas/stu1' select * from stu1;
- Format and export query results to local
insert overwrite local directory '/bigdata/install/hivedatas/stu1' row format delimited fields terminated by ',' select * from stu1;
- Export query results to HDFS = = (no local)==
insert overwrite directory '/bigdata/install/hivedatas/stu' row format delimited fields terminated by ',' select * from stu;
2. Hive Shell command export (to be executed on linux terminal)
- Basic syntax:
hive -e "sql sentence" > file hive -f sql file > file
- On the linux command line, run the following command to export the data of the myhive.stu table to the local disk
hive -e 'select * from myhive.stu;' > /bigdata/install/hivedatas/student1.txt;
3 export to HDFS
export table myhive.stu to '/bigdata/install/hivedatas/stuexport';
Hive's static and dynamic partitions
1. Static partition
- The value of the partition field of the table needs to be given manually by the developer
- Data file order.txt
10001 100 2019-03-02 10002 200 2019-03-02 10003 300 2019-03-02 10004 400 2019-03-03 10005 500 2019-03-03 10006 600 2019-03-03 10007 700 2019-03-04 10008 800 2019-03-04 10009 900 2019-03-04
- Create partition table, load data and query results
use myhive; -- Create partition table create table order_partition( order_number string, order_price double, order_time string ) partitioned BY(month string) row format delimited fields terminated by '\t'; -- Load data load data local inpath '/bigdata/install/hivedatas/order.txt' overwrite into table order_partition partition(month='2019-03'); -- Query results hive (myhive)> select * from order_partition where month='2019-03'; OK order_partition.order_number order_partition.order_price order_partition.order_time order_partition.month 10001 100.0 2019-03-02 2019-03 10002 200.0 2019-03-02 2019-03 10003 300.0 2019-03-02 2019-03 10004 400.0 2019-03-03 2019-03 10005 500.0 2019-03-03 2019-03 10006 600.0 2019-03-03 2019-03 10007 700.0 2019-03-04 2019-03 10008 800.0 2019-03-04 2019-03 10009 900.0 2019-03-04 2019-03 Time taken: 2.511 seconds, Fetched: 9 row(s)
2. Dynamic zoning
- Automatically import the data into the corresponding partition of the table according to the requirements, and there is no need to manually specify the value of the partition field
- Requirement: automatically import data into different partitions of the partition table according to different values of the partition field
- Data file order_partition.txt
10001 100 2019-03-02 10002 200 2019-03-02 10003 300 2019-03-02 10004 400 2019-03-03 10005 500 2019-03-03 10006 600 2019-03-03 10007 700 2019-03-04 10008 800 2019-03-04 10009 900 2019-03-04
- Create partition table, load data and query results
-- Create normal table
create table t_order(
order_number string,
order_price double,
order_time string
)row format delimited fields terminated by '\t';
-- Create target partition table
create table order_dynamic_partition(
order_number string,
order_price double
)partitioned BY(order_time string)
row format delimited fields terminated by '\t';
-- To common table t_order Load data
load data local inpath '/bigdata/install/hivedatas/order_partition.txt' overwrite into table t_order;
-- Dynamically load data into partitioned tables
-- To dynamically partition, you need to set parameters
-- Enable dynamic partition function
hive> set hive.exec.dynamic.partition=true;
-- set up hive Non strict mode
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> insert into table order_dynamic_partition partition(order_time) select order_number, order_price, order_time from t_order;
-- Query results
hive (myhive)> show partitions order_dynamic_partition;
OK
partition
order_time=2019-03-02
order_time=2019-03-03
order_time=2019-03-04
Time taken: 0.154 seconds, Fetched: 3 row(s)
After hive3.x, you can directly import the files on hdfs through load to complete the dynamic partition without any attribute settings. The dynamic partition will be partitioned according to the last field
load data inpath '/user/hive/warehouse/myhive.db/t_order' overwrite into table myhive.order_dynamic_partition;
Hive's query syntax
1. Basic query
- SQL language is case insensitive. SQL can be written on one or more lines
- Keywords cannot be abbreviated or split. Clauses are generally written in separate lines. Indentation is used to improve the readability of statements
-- Full table query select * from stu; -- Specific column query select id, name from stu; -- List aliases select id, name as stuName from stu; -- Find the total number of rows( count) select count(*) from stu; -- Find the maximum score( max) select max(s_score) from score; -- Find the minimum value of the score( min) select min(s_score) from score; -- Sum the scores( sum) select sum(s_score) from score; -- Average the scores( avg) select avg(s_score) from score; -- limit sentence select * from score limit 5; -- where sentence select * from score where s_score > 60;
- Arithmetic operator
| operator | describe |
|---|---|
| A+B | Add A and B |
| A-B | A minus B |
| A*B | Multiply A and B |
| A/B | A divided by B |
| A%B | A to B remainder |
| A&B | A and B are bitwise AND |
| A|B | A and B take or by bit |
| A^B | A and B bitwise XOR |
| ~A | A reverse by bit |
- Comparison operator
| Operator | Supported data types | describe |
|---|---|---|
| A=B | Basic data type | If A is equal to B, it returns true; otherwise, it returns false |
| A<=>B | Basic data type | If both A and B are NULL, it returns true. The results of other operators are consistent with those of the equal sign (=) operator. If either is NULL, the result is NULL |
| A<>B, A!=B | Basic data type | If A or B is NULL, NULL is returned; if A is not equal to B, true is returned; otherwise, false is returned |
| A<B | Basic data type | If A or B is NULL, NULL is returned; if A is less than B, true is returned; otherwise, false is returned |
| A<=B | Basic data type | If A or B is NULL, NULL is returned; if A is less than or equal to B, true is returned; otherwise, false is returned |
| A>B | Basic data type | If A or B is NULL, NULL is returned; if A is greater than B, true is returned; otherwise, false is returned |
| A>=B | Basic data type | If A or B is NULL, NULL is returned; if A is greater than or equal to B, true is returned; otherwise, false is returned |
| A [NOT] BETWEEN B AND C | Basic data type | If any of A, B or C is NULL, the result is NULL. If the value of A is greater than or equal to B and less than or equal to C, the result is true, otherwise it is false. If you use the NOT keyword, the opposite effect can be achieved. |
| A IS NULL | All data types | If A is equal to NULL, it returns true; otherwise, it returns false |
| A IS NOT NULL | All data types | If A is not equal to NULL, it returns true; otherwise, it returns false |
| In (value 1, value 2) | All data types | Use the IN operation to display the values IN the list |
| A [NOT] LIKE B | STRING type | B is A simple regular expression under SQL. If A matches it, it returns true; otherwise, it returns false. The expression description of B is as follows: 'x%' means that A must start with the letter 'x', '% X' means that A must end with the letter 'x', and '% X%' means that A contains the letter 'x', which can be located at the beginning, end or in the middle of the string. If NOT keyword is used, it can be used like is NOT A regular, but A wildcard |
| A RLIKE B, A REGEXP B | STRING type | B is A regular expression. If A matches it, it returns true; otherwise, it returns false. The matching is implemented by the regular expression interface in JDK, because the regular expression is also based on its rules. For example, the regular expression must match the whole string A, not just its string. |
- Logical operator
| Operator | operation | describe |
|---|---|---|
| A AND B | Logical Union | True if both A and B are true, otherwise false |
| A OR B | Logical or | True if A or B or both are true, otherwise false |
| NOT A | Logical no | true if A is false, otherwise false |
2. Grouping
-- group by Statement: usually and==Aggregate function==Use together to group the results by one or more columns, and then aggregate each group -- Calculate the average score of each student select s_id, avg(s_score) from score group by s_id; -- Calculate the highest score for each student select s_id, max(s_score) from score group by s_id; -- having sentence -- where in the light of==The columns in the table work==,Query data;==having For columns in query results==Play a role in filtering data -- where behind==Cannot write aggregate function==,and having Back can==Using aggregate functions== -- having Only for group by Grouping statistics statement -- Find the average score of each student select s_id, avg(s_score) from score group by s_id; -- Ask each student whose average score is greater than 60 select s_id, avg(s_score) as avgScore from score group by s_id having avgScore > 60; -- Equivalent to select s_id, avg(s_score) as avgScore from score group by s_id having avg(s_score) > 60;
3. join statement
- Hive supports common SQL JOIN statements, but only supports equivalent connections, not non equivalent connections.
- Equivalent join
-- According to the student and grade sheet, query the grade corresponding to the student's name select * from stu left join score on stu.id = score.s_id; -- Merging teachers and Curriculum -- hive Middle creation course Table and load data create table course (c_id string, c_name string, t_id string) row format delimited fields terminated by '\t'; load data local inpath '/bigdata/install/hivedatas/course.csv' overwrite into table course; select * from teacher t join course c on t.t_id = c.t_id;
- inner join: only the data matching the join conditions in the two tables to be joined will be retained.
select * from teacher t inner join course c on t.t_id = c.t_id;
- left outer join: all records matching the where clause in the left table of the join operator will be returned. If there is no qualified value for the specified field in the right table, null value will be used instead.
-- Query the course corresponding to the teacher select * from teacher t left outer join course c on t.t_id = c.t_id;
- right outer join:
select * from teacher t right outer join course c on t.t_id = c.t_id;
- full outer join: all records in all tables that meet the conditions of the where statement will be returned. If there is no qualified value in the specified field of any table, null value will be used instead.
select * from teacher t full outer join course c on t.t_id = c.t_id;
- Multi table connection: to connect n tables, at least n-1 connection conditions are required. For example, connecting three tables requires at least two connection conditions.
-- Multi table connection query to query the corresponding brand and category information of goods select * from products p left join brands b on p.brand_id = b.id left join categorys c on p.category_id = c.id;
4. Sorting
-
ORDER BY global sorting: there is only one reduce, and the ORDER BY clause is used for sorting
-
ASC (ascend) ascending (default), desc (descend) descending
-- Query students' scores and arrange them in descending order select * from score s order by s_score desc; s.s_id s.c_id s.s_score s.month 01 03 99 201806 07 03 98 201806 01 02 90 201806 07 02 89 201806 05 02 87 201806 03 03 80 201806 03 02 80 201806 03 01 80 201806 02 03 80 201806 01 01 80 201806 05 01 76 201806 02 01 70 201806 02 02 60 201806 04 01 50 201806 06 03 34 201806 06 01 31 201806 04 02 30 201806 04 03 20 201806
- Sort by alias
select s_id, avg(s_score) avgscore from score group by s_id order by avgscore desc; s_id avgscore 07 93.5 01 89.66666666666667 05 81.5 03 80.0 02 70.0 04 33.333333333333336 06 32.5
- Each MapReduce internal sorting (Sort By) local sorting: each MapReduce internal sorting (local ordering), which is not global ordering for the global result set.
-- set up reduce number set mapreduce.job.reduces=3; -- see reduce Number of set mapreduce.job.reduces; -- Query results are arranged in descending order select * from score s sort by s.s_score; -- Import the query results into a file (in descending order of grades) insert overwrite local directory '/bigdata/install/hivedatas/sort' select * from score s sort by s.s_score;
- distribute by partition sorting: similar to partition in MR, it collects hash algorithm and distributes the results with the same hash value in the query results to the corresponding reduce file on the map side.
- Combined with sort by;
- Hive requires that the distribute by statement be written before the sort by statement.
-- First according to the students sid Divide the areas and sort them according to the students' grades set mapreduce.job.reduces=3; -- adopt distribute by Partition data,,Will be different sid Divided into corresponding reduce Go in the middle insert overwrite local directory '/bigdata/install/hivedatas/distribute' select * from score distribute by s_id sort by s_score;
- Cluster by: when the distribution by and sort by fields are the same, cluster by can be used instead
- In addition to the function of distribute by, this field will also be sorted, so cluster by s_score = distribute by s_score + sort by s_score
--The following two expressions are equivalent insert overwrite local directory '/bigdata/install/hivedatas/distribute_sort' select * from score distribute by s_score sort by s_score; insert overwrite local directory '/bigdata/install/hivedatas/cluster' select * from score cluster by s_score;
Data compression of Hive table
1. Data compression comparison
-
Compression mode evaluation:
- Compression ratio: the higher the compression ratio, the smaller the compressed file, so the higher the compression ratio, the better
- Compression time: the faster the better
- Separable: the separable format allows a single file to be processed by multiple Mapper programs, which can be better parallelized
-
Common compression formats
| Compression mode | Compression ratio | Compression speed | Decompression speed | Is it separable |
|---|---|---|---|---|
| gzip | 13.4% | 21 MB/s | 118 MB/s | no |
| bzip2 | 13.2% | 2.4MB/s | 9.5MB/s | yes |
| lzo | 20.5% | 135 MB/s | 410 MB/s | no |
| snappy | 22.2% | 172 MB/s | 409 MB/s | no |
- Hadoop codec mode
| Compression format | Corresponding encoder / decoder |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| BZip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compress.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
- Comparison of compression performance
| compression algorithm | Original file size | Compressed file size | Compression speed | Decompression speed |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
2. Compression configuration parameters
- To enable compression in Hadoop, you can configure the following parameters (in mapred-site.xml file):
| parameter | Value | stage | proposal |
|---|---|---|---|
| Io.compression.codecs (configured in core-site.xml) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | Input compression | Hadoop uses file extensions to determine whether a codec is supported |
| mapreduce.map.output.compress | true | mapper output | Set this parameter to true to enable compression |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper output | Use LZO, LZ4, or snappy codecs to compress data at this stage |
| mapreduce.output.fileoutputformat.compress | true | reducer output | Set this parameter to true to enable compression |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer output | Use standard tools or codecs such as gzip and bzip2 |
| mapreduce.output.fileoutputformat.compress.type | NONE|RECORD | reducer output | Compression types used for SequenceFile output: NONE and BLOCK |
3. Enable Map output phase compression
- Turning on map output compression can reduce the amount of data transfer between map and Reduce task in the job. The specific configuration is as follows:
-- hql The statement may be converted to more than one job,as job1 As a result of job2 Input of...open job Compression function of inter result data; default false hive (default)> set hive.exec.compress.intermediate=true; -- open mapreduce in map Output compression function; default false hive (default)> set mapreduce.map.output.compress=true; -- set up mapreduce in map Compression mode of output data; default DefaultCodec hive (default)> set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec; -- Execute query statement hive (default)> select count(1) from score;
4. Enable the Reduce output phase compression
- When Hive writes the output to the table, the output can also be compressed. The attribute hive.exec.compress.output controls this function. Users may need to keep the default value false in the default settings file, so that the default output is an uncompressed plain text file. You can set this value to true in the query statement or execution script to enable the output result compression function.
-- open hive Compression function of final output data; default false hive (default)>set hive.exec.compress.output=true; -- open mapreduce Final output data compression; default false hive (default)>set mapreduce.output.fileoutputformat.compress=true; -- set up mapreduce Final data output compression mode; default DefaultCodec hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; -- set up mapreduce The final data output is compressed into block compression; default RECORD hive (default)>set mapreduce.output.fileoutputformat.compress.type=BLOCK; -- Test whether the output is a compressed file insert overwrite local directory '/bigdata/install/hivedatas/snappy' select * from teacher;
File storage format of Hive table
- Hive supports the following formats for storing data: TEXTFILE (row storage), sequencefile (row storage), ORC (column storage) and PARQUET (column storage).
1. Column storage and row storage
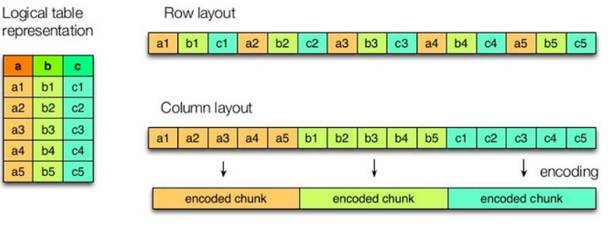
- The left side of the figure above is a logical table, the first one on the right is row storage, and the second one is column storage.
- **Characteristics of row storage: * * when querying a whole row of data that meets the conditions, column storage needs to find the corresponding value of each column in each aggregated field. Row storage only needs to find one value, and the rest values are in adjacent places, so the speed of row storage query is faster.
- Characteristics of column storage:
- Because the data of each field is aggregated and stored, when only a few fields are required for query, the amount of data read can be greatly reduced;
- The data type of each field must be the same. Column storage can be targeted to design better compression algorithms. select some fields are more efficient.
- The storage formats of TEXTFILE and SEQUENCEFILE are based on row storage, and ORC and PARQUET are based on column storage.
2. TEXTFILE format
- In the default format, data is not compressed, resulting in high disk overhead and high data parsing overhead. It can be used in combination with gzip and Bzip2 (the system automatically checks and automatically decompresses when executing queries), but with gzip, hive will not segment the data, so it is impossible to operate the data in parallel.
3. ORC format
- Orc (Optimized Row Columnar) is a new storage format introduced in hive version 0.11.
- You can see that each Orc file is composed of one or more strings, each of which is 250MB in size. This stripe is actually equivalent to the RowGroup concept, but the size is 4MB - > 250MB, which can improve the throughput of sequential reading. Each stripe consists of three parts: Index Data, Row Data and Stripe Footer:
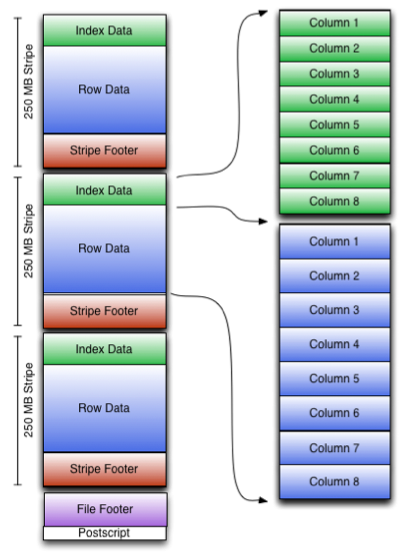
- An orc file can be divided into several stripes, and a stripe can be divided into three parts:
- IndexData: index data for some columns. A lightweight index. By default, an index is made every 1W rows. The index here only records the offset of each field of a row in Row Data.
- RowData: real data storage. What is stored is specific data. First take some rows, and then store these rows by column. Each column is encoded and divided into multiple streams for storage.
- StripFooter: stores the metadata information of each stripe.
- Each file has a File Footer, where the number of rows of each Stripe and the data type information of each Column are stored.
- At the end of each file is a PostScript, which records the compression type of the whole file and the length information of FileFooter. When reading a file, you will seek to read PostScript at the end of the file, parse the length of File Footer from the inside, read FileFooter again, parse the information of each Stripe from the inside, and then read each Stripe, that is, read from back to front.
4. PARQUET format (impala)
- Parquet is a columnar storage format for analytical business. It was jointly developed by Twitter and Cloudera. In May 2015, parquet graduated from the Apache incubator and became the top project of Apache.
- Parquet file is stored in binary mode, so it can not be read directly. The file includes the data and metadata of the file. Therefore, parquet format file is self parsed.
- Generally, when storing Parquet data, the size of row groups will be set according to the Block size. Generally, the minimum unit of data processed by each Mapper task is a Block, so each row group can be processed by one Mapper task to increase the parallelism of task execution. The format of Parquet file is shown in the following figure.
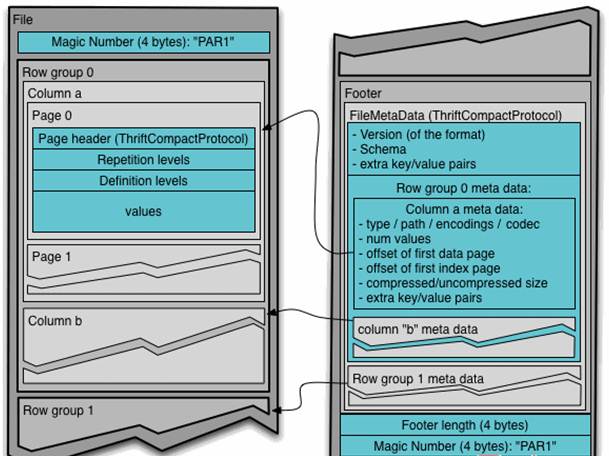
- The above figure shows the contents of a Parquet file. Multiple line groups can be stored in a file. The first part of the file is the Magic Code of the file, which is used to verify whether it is a Parquet file. Footer length records the size of the file metadata. The offset of the metadata can be calculated from this value and the file length, The metadata of the file includes the metadata information of each row group and the Schema information of the data stored in the file. In addition to the metadata of each row group in the file, the metadata of the page is stored at the beginning of each page. In Parquet, there are three types of pages: data page, dictionary page and index page. The data page is used to store the value of the column in the current row group. The dictionary page stores the encoding Dictionary of the column value. Each column block contains at most one dictionary page. The index page is used to store the index of the column under the current row group. At present, the index page is not supported in Parquet.
5. Comparison experiment of mainstream file storage formats
- The compression ratio of stored files and query speed are compared.
- Test data: https://download.csdn.net/download/yangwei234/58301049
TextFile
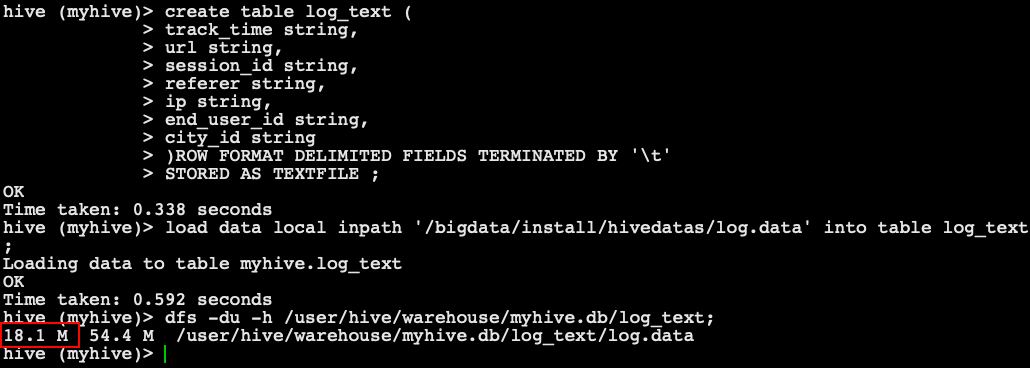
use myhive; -- Create a table and store data in the format TEXTFILE create table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; -- Loading data into a table load data local inpath '/bigdata/install/hivedatas/log.data' into table log_text; -- View data size in table dfs -du -h /user/hive/warehouse/myhive.db/log_text;
ORC
-- Create a table and store data in the format ORC create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc ; -- Loading data into a table insert into table log_orc select * from log_text ; -- View data size in table dfs -du -h /user/hive/warehouse/myhive.db/log_orc;
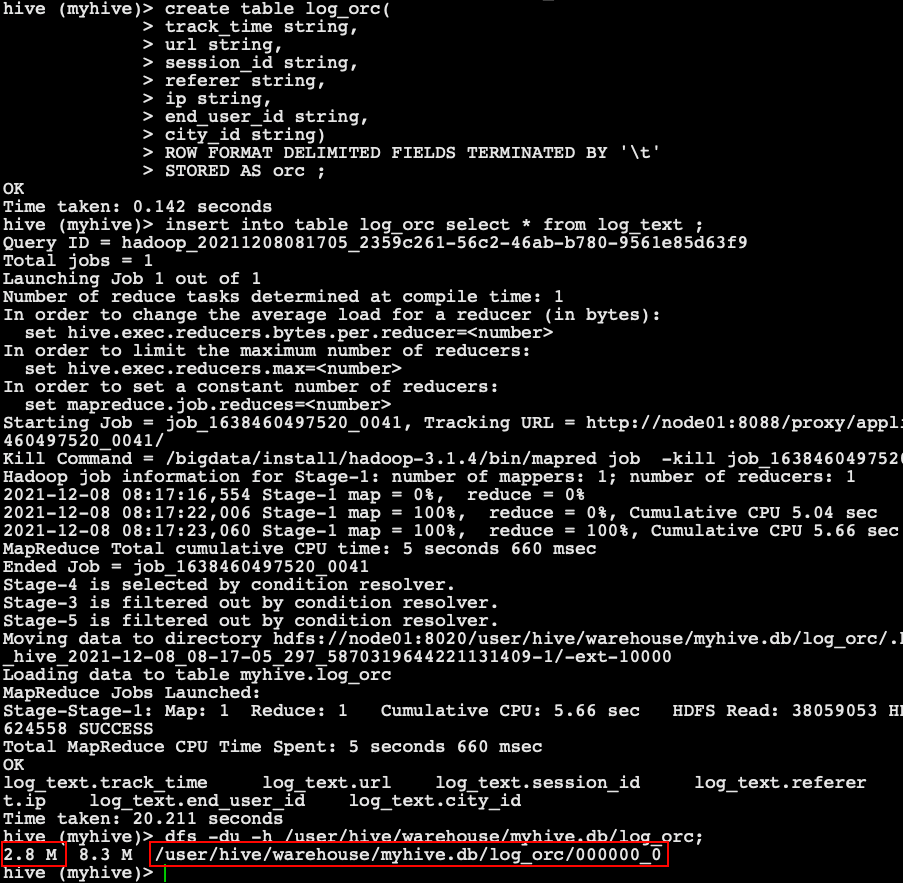
- orc, the storage format, uses zlib compression by default to compress the data, so the data will become 2.8M, which is very small
Parquet
-- Create a table and store data in the format parquet create table log_parquet( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS PARQUET ; -- Loading data into a table insert into table log_parquet select * from log_text ; -- View data size in table dfs -du -h /user/hive/warehouse/myhive.db/log_parquet;
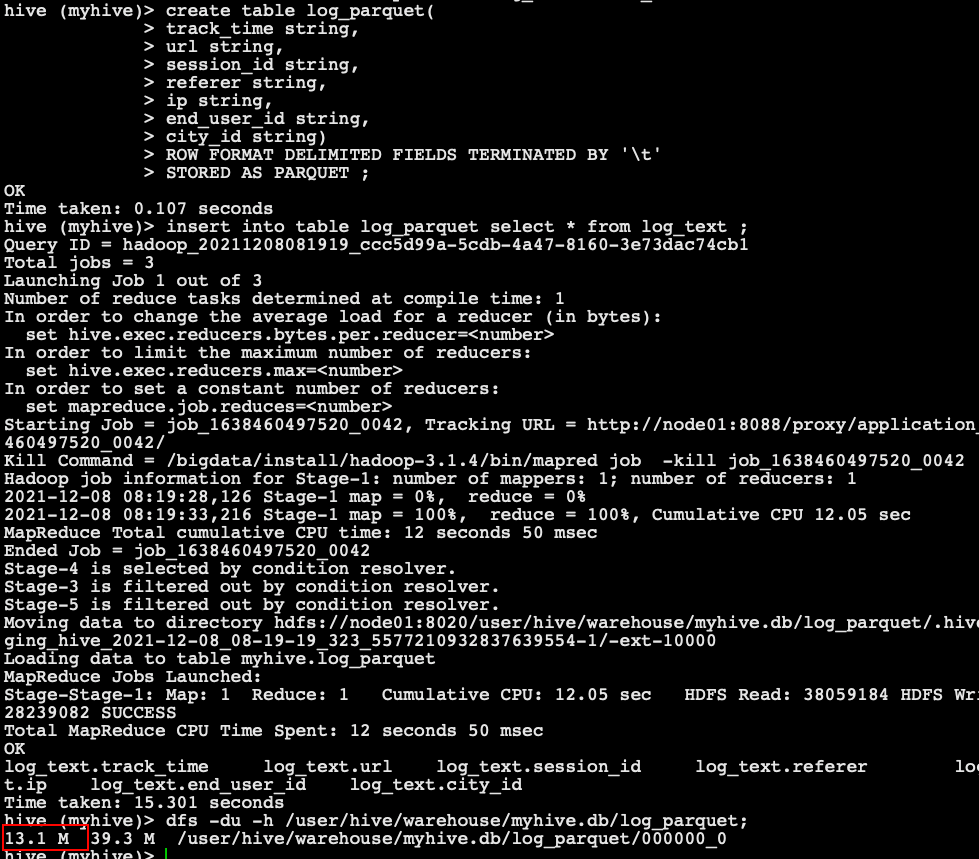
- Conclusion: the compression ratio of stored files
ORC > Parquet > textFile
Query speed test of stored files
select count(*) from log_text; select count(*) from log_orc; select count(*) from log_parquet;
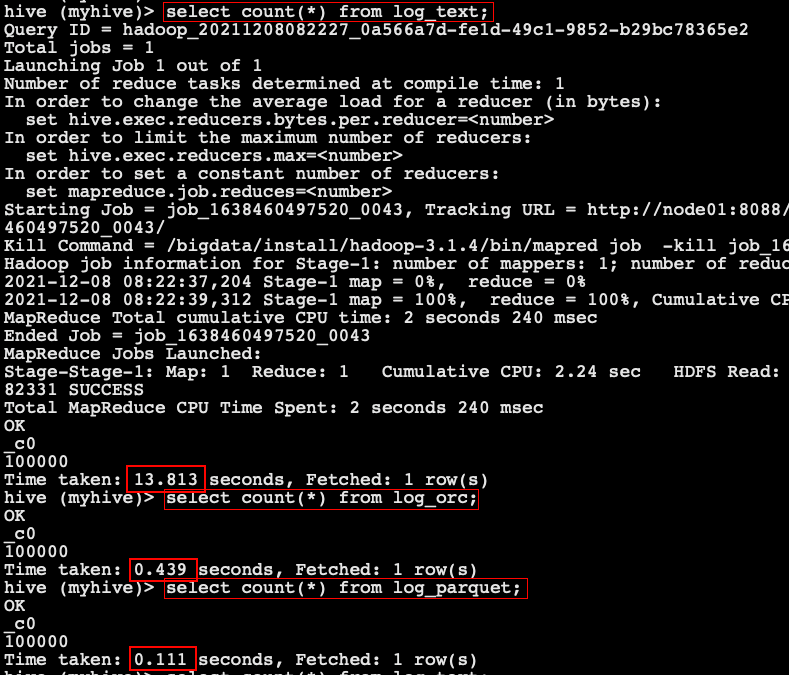
- Summary of query speed of stored files:
Parquet > ORC > TextFile
Combination of storage and compression
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk;256kB |
| orc.stripe.size | 67,108,864 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
| orc.bloom.filter.columns | "" | comma separated list of column names for which bloom filter should be created |
| orc.bloom.filter.fpp | 0.05 | false positive probability for bloom filter (must >0.0 and <1.0) |
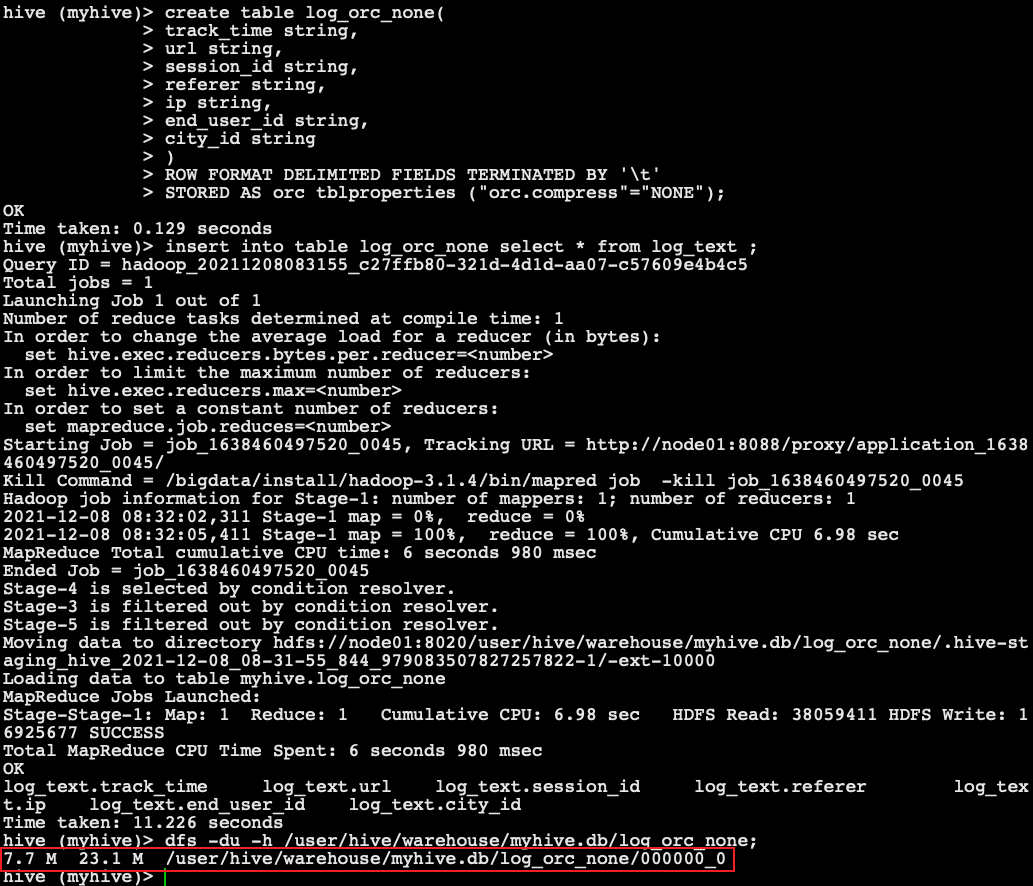
1. Create an uncompressed ORC storage method
-- Create table statement
create table log_orc_none(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="NONE");
-- insert data
insert into table log_orc_none select * from log_text ;
-- View Post insert data
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_none;
2. Create a SNAPPY compressed ORC storage method
-- Create table statement
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
-- insert data
insert into table log_orc_snappy select * from log_text ;
-- View Post insert data
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_snappy ;
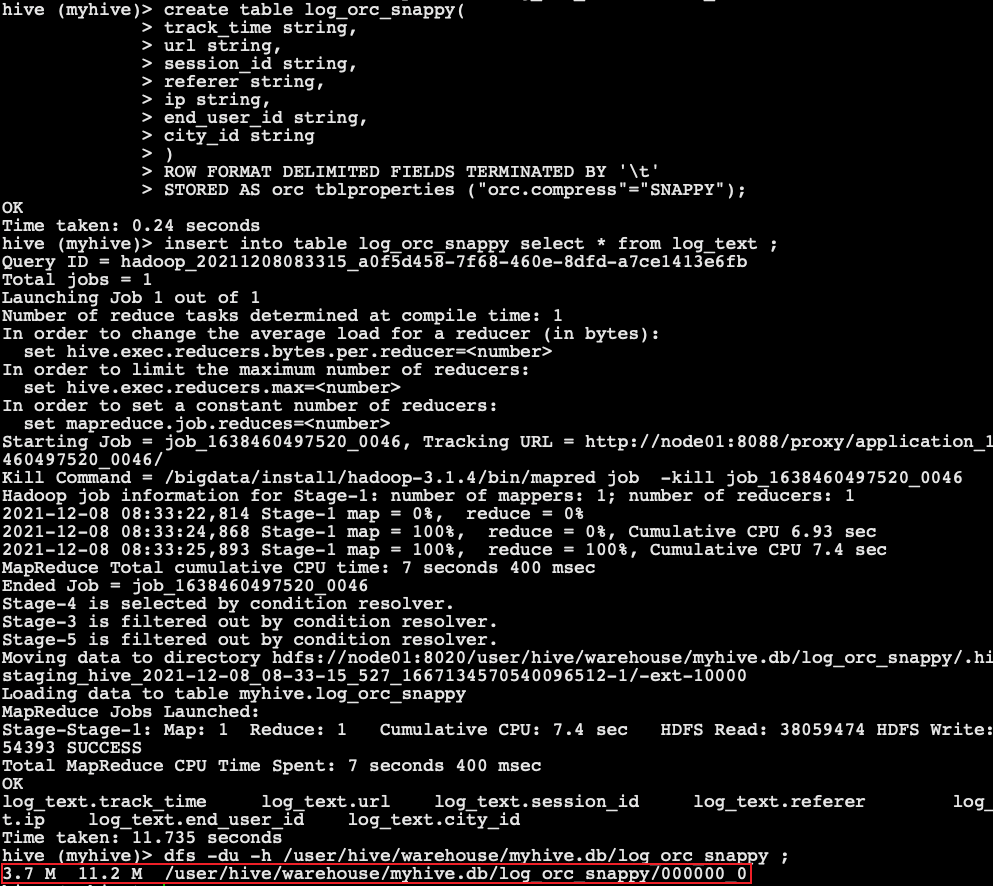 -The ORC storage method created by default in the previous section. The size after importing data is
-The ORC storage method created by default in the previous section. The size after importing data is
2.8 M 8.3 M /user/hive/warehouse/myhive.db/log_orc/000000_0
- Smaller than snappy compression: the reason is that the orc storage file adopts ZLIB compression by default, which is smaller than snappy compression.
- Storage method and compression summary: in the actual project development, the data storage format of hive table is generally orc or parquet, and the compression method is generally snappy.
3. Enterprise practice
Solve multi character segmentation scenarios through MultiDelimitSerDe
- Official website table creation syntax reference
- MultiDelimitSerDe reference
- Test data file t1.txt
1##xiaoming 2##xiaowang 3##xiaozhang
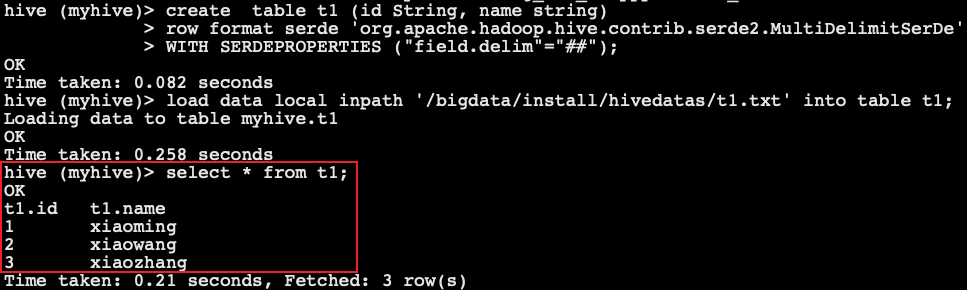
-- Create table
create table t1 (id String, name string)
row format serde 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES ("field.delim"="##");
-- Load data
load data local inpath '/bigdata/install/hivedatas/t1.txt' into table t1;
-- Query data
select * from t1;
+--------+------------+--+
| t1.id | t1.name |
+--------+------------+--+
| 1 | xiaoming |
| 2 | xiaowang |
| 3 | xiaozhang |
+--------+------------+--+
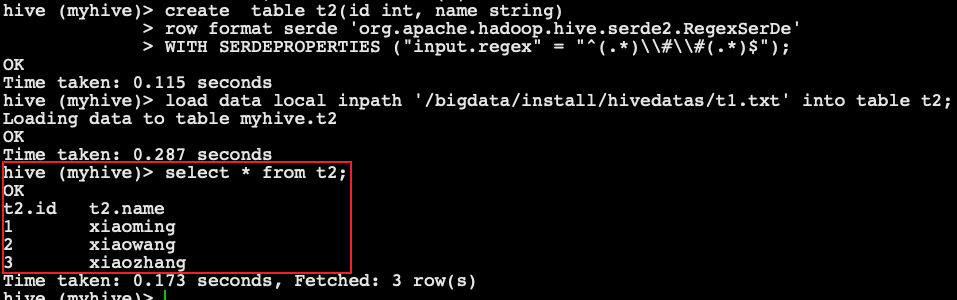
Solve multi character segmentation scenarios through RegexSerDe
-- Create table
create table t2(id int, name string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "^(.*)\\#\\#(.*)$");
-- Load data
load data local inpath '/bigdata/install/hivedatas/t1.txt' into table t2;
-- Query data
select * from t2;
+--------+------------+--+
| t2.id | t2.name |
+--------+------------+--+
| 1 | xiaoming |
| 2 | xiaowang |
| 3 | xiaozhang |
+--------+------------+--+