This article is about Learning Guide for Big Data Specialists from Zero (Full Upgrade) Added in part by Haop.
1. Template Virtual Machine Environment Preparation
0) Install template virtual machine, IP address 192.168.10.100, host name hadoop100, memory 4G, hard disk 50G
1) The configuration requirements for hadoop100 virtual machine are as follows (All Linux systems in this paper take CentOS-7.5-x86-1804 as an example)
(1) Using Yum installation requires virtual machines to be able to connect to the Internet normally. Before installing yum, you can test the networking status of virtual machines.
[root@hadoop100 ~]# ping www.baidu.com PING www.baidu.com (14.215.177.39) 56(84) bytes of data. 64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=1 ttl=128 time=8.60 ms 64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=2 ttl=128 time=7.72 ms
(2) Install epel-release
Note: Extra Packages for Enterprise Linux is an additional package for the Red Hat operating system, suitable for RHEL, CentOS, and Scientfic Linux. Equivalent to a software repository, most rpm packages are not found in the official repository)
[root@hadoop100 ~]# yum install -y epel-release
(3) Note: If Linux is installed in the minimum system version, you also need to install the following tools; if you are installing the standard Linux desktop version, you do not need to do the following
- net-tool: A collection of toolkits containing commands such as ifconfig
[root@hadoop100 ~]# yum install -y net-tools
- vim: Editor
[root@hadoop100 ~]# yum install -y vim
2) Turn off the firewall, turn off the firewall and turn it on
[root@hadoop100 ~]# systemctl stop firewalld [root@hadoop100 ~]# systemctl disable firewalld.service
Note: In enterprise development, firewalls for individual servers are usually turned off. The company as a whole sets up very secure firewalls for the external world
3) Create atguigu users and modify their passwords
[root@hadoop100 ~]# useradd atguigu [root@hadoop100 ~]# passwd atguigu
4) Configure that atguigu users have root privileges to allow sudo to execute root privileges later on
[root@hadoop100 ~]# vim /etc/sudoers
Modify the /etc/sudoers file and add a line below the line%wheel as follows:
## Allow root to run any commands anywhere root ALL=(ALL) ALL ## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL atguigu ALL=(ALL) NOPASSWD:ALL
Note: This line of atguigu should not be placed directly below the root line because all users belong to the wheel group. You configure atguigu to be secret-free, but when the program reaches the%wheel line, it is overwritten to require a password. So atguigu should be placed below the%wheel line.
5) Create folders in the / opt directory and modify the owner and group
(1) Create module, software folder under / opt directory
[root@hadoop100 ~]# mkdir /opt/module [root@hadoop100 ~]# mkdir /opt/software
(2) The owner and group of the modified module, software folder are atguigu users;
[root@hadoop100 ~]# chown atguigu:atguigu /opt/module [root@hadoop100 ~]# chown atguigu:atguigu /opt/software
(3) View the owner and group of the module, software folder
[root@hadoop100 ~]# cd /opt/ [root@hadoop100 opt]# ll Total usage 12 drwxr-xr-x. 2 atguigu atguigu 4096 5 28/17:18 module drwxr-xr-x. 2 root root 4096 9 Month 7, 2017 rh drwxr-xr-x. 2 atguigu atguigu 4096 5 28/17:18 software
6) Uninstall the JDK that comes with the virtual machine
Note: This step is not required if your virtual machine is a minimal installation.
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
- rpm-qa: Query all installed rpm packages
- Grep-i: Ignore case
- Xargs-n1: Indicates that only one parameter is passed at a time
- Rpm-e-nodeps: Force software uninstallation
7) Restart Virtual Machine
[root@hadoop100 ~]# reboot
2. Clone Virtual Machine
1) Using the template machine hadoop100, clone three virtual machines: hadoop102 hadoop103 hadoop104
Note: When cloning, first turn off hadoop100
2) Modify clone IP, as illustrated below with hadoop102
(1) Modify the static IP of the cloned virtual machine
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
Change to
DEVICE=ens33 TYPE=Ethernet ONBOOT=yes BOOTPROTO=static NAME="ens33" IPADDR=192.168.10.102 PREFIX=24 GATEWAY=192.168.10.2 DNS1=192.168.10.2
(2) View the virtual network editor for the Linux virtual machine, Edit->Virtual Network Editor->VMnet8
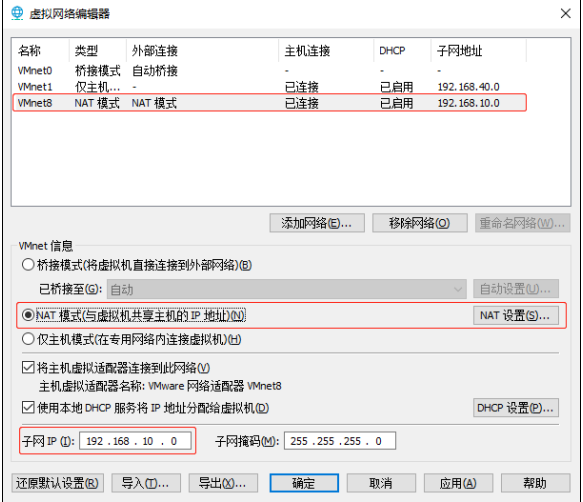
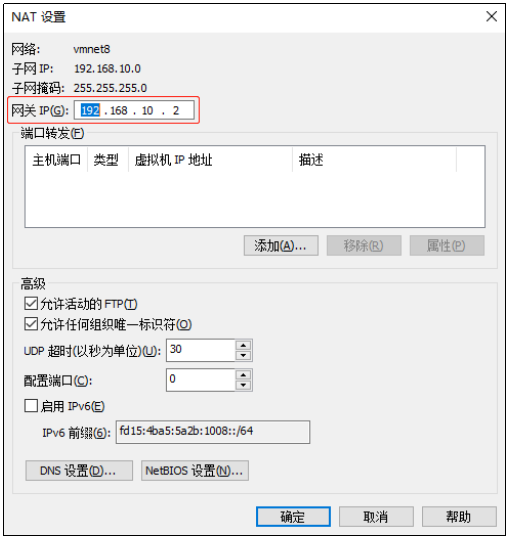
(3) View the IP address of the Windows system adapter VMware Network Adapter VMnet8
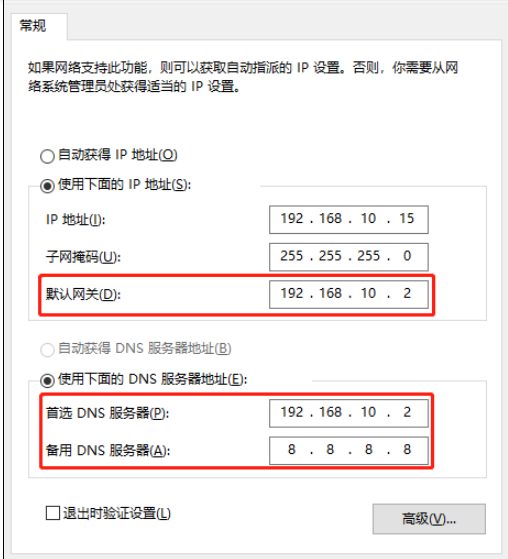
(4) Ensure that the IP address in the ifcfg-ens33 file of the Linux system, the virtual network editor address and the VM8 network IP address of the Windows system are the same.
3) Modify the clone host name, as illustrated below with hadoop102
(1) Modify host name
[root@hadoop100 ~]# vim /etc/hostname hadoop102
(2) Configure Linux clone host name mapping hosts file, open/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
Add the following
192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108
4) Restart clone machine hadoop102
[root@hadoop100 ~]# reboot
5) Modify the host mapping file (hosts file) of windows
(1) If the operating system is window7, it can be modified directly.
(a) Enter the C:\Windows\System32\drivers\etc path
(b) Open the hosts file and add the following, then save
192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108
(2) If the operating system is Windows 10, copy it first, save the changes, and then overwrite it
(a) Enter the C:\Windows\System32\drivers\etc path
(b) Copy hosts file to desktop
(c) Open the desktop hosts file and add the following
192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 192.168.10.108 hadoop108