Set up hadoop,zookeeper,kafka in the environment of data warehouse collection
Previous Aliyun ECS environment has been installed, now start to formally set up the project environment
hadoop installation configuration
1. Cluster Planning
| Server hadoop102 | Server hadoop103 | Server hadoop104 | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | DataNodeSecondaryNameNode |
| Yarn | NodeManager | ResourcemanagerNodeManager | NodeManager |
2. Deployment and installation
The version I'm using here is hadoop-3.1.3.tar.gz
# decompression [atguigu@hadoop102 software]$ pwd /opt/software [atguigu@hadoop102 software]$ ll |grep hadoop -rw-rw-r-- 1 atguigu atguigu 338075860 Oct 16 21:37 hadoop-3.1.3.tar.gz [atguigu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C ../module/ # Configure the environment variable/etc/profile.d/my_env.sh, then source/etc/profile export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # hadoop version checks if hadoop was installed successfully
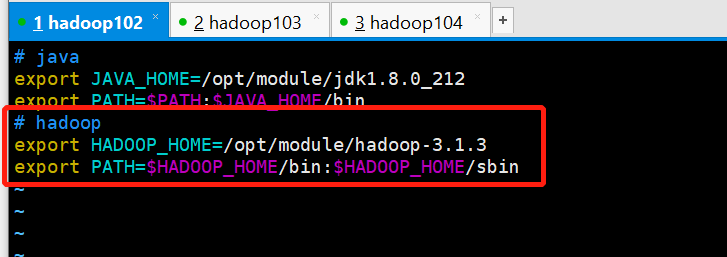
3. Configuring clusters
core-site.xml, add the following configuration to the configuration
<!-- Appoint NameNode Address -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- Appoint hadoop Storage directory for data -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- To configure HDFS The static user used for Web page login is atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!-- Configure this atguigu(superUser)Host Node Allowed Access through Proxy -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- Configure this atguigu(superUser)Allow users to belong to groups through proxy -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- Configure this atguigu(superUser)Allow users through proxy-->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
hdfs-site.xml
<!-- nn web End Access Address-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web End Access Address-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
yarn-site.xml
<!-- Appoint MR go shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Appoint ResourceManager Address-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- Inheritance of environment variables -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn Maximum and minimum memory allowed for allocation by container -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn Container's allowed managed physical memory size defaults to 8 G-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- Close yarn Limitation checks for physical and virtual memory -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
mapred-site.xml
<!-- Appoint MapReduce The program runs on Yarn upper -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
Configure works
hadoop102 hadoop103 hadoop104
4. Configure the history server
mapred-site.xml
<!-- History server-side address -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- History Server web End Address -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
5. Configure Log Aggregation
yarn-site.xml
<!-- Turn on log aggregation -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- Set Log Aggregation Server Address -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- Set log retention time to 7 days -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
ok, now that all the configurations are configured, we will distribute the entire Hadoop installation directory to hadoop103,hadoop104 machines, and environment variables.
[atguigu@hadoop102 module]$ pwd /opt/module # Distribute hadoop installation directory [atguigu@hadoop102 module]$ my_rsync.sh hadoop-3.1.3 # Distributing environment variables [atguigu@hadoop102 module]$ my_rsync.sh /etc/profile.d/my_env.sh # See if the hadoop environment variable for each machine is valid [atguigu@hadoop102 module]$ all.sh hadoop version
Testing is complete and the hadoop environment for all machines is now installed
6. Start hadoop
# 102 [atguigu@hadoop102 module]$ hdfs namenode -format # 102 [atguigu@hadoop102 module]$ start-dfs.sh # 103 [atguigu@hadoop102 module]$ start-yarn.sh
ok.Start successfully,
# namenode web address hadoop102:9870 # yarn web address hadoop103:8088
7. Take a simple mr test
hadoop fs -mkdir /input hadoop fs -put READ.txt /input hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output # Start History Server mapred --daemon start historyserver
Multi-directory storage
Familiarize yourself with the fact that the production environment will certainly be used in the future
1. Production environment server disk condition
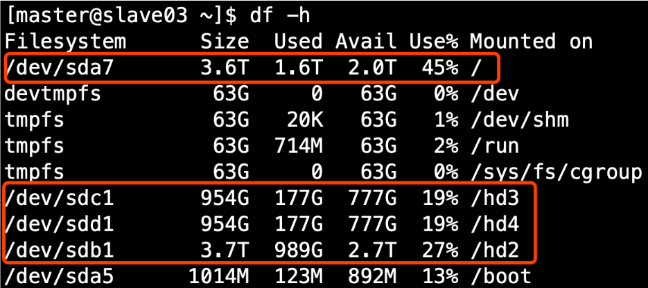
2. Configure multiple directories in the hdfs-site.xml file, and note the access permissions of newly mounted disks.
HDFS Of DataNode The path where the node saves data is dfs.datanode.data.dir The parameter determines which default value is file://${hadoop.tmp.dir}/dfs/data, this parameter must be modified if the server has multiple disks. As shown in the figure above, the parameter should be modified to the following value.
<property> <name>dfs.datanode.data.dir</name> <value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value> </property>
Note: Disks mounted on each server are different, so the multi-directory configuration of each node can be inconsistent. A separate configuration is sufficient. Don't panic, look at the disk mount then datanode attribute dfs.datanode.data.dir Configuration is OK
Note: Disks mounted on each server are different, so the multi-directory configuration of each node can be inconsistent. A separate configuration is sufficient.
Cluster data balance
Data Balance Between Nodes
Turn on Data Balance command: start-balancer.sh -threshold 10 For parameter 10, this means that the disk space utilization of each node in the cluster differs by no more than 10%,It can be adjusted according to the actual situation. Stop Data Balance command: stop-balancer.sh
Data Balance Between Disks
(1)Generate Balance Plan (we only have one disk, no plan will be generated) hdfs diskbalancer -plan hadoop103 (2)Execute balanced plan hdfs diskbalancer -execute hadoop103.plan.json (3)View current balanced task execution hdfs diskbalancer -query hadoop103 (4)Cancel Balance Task hdfs diskbalancer -cancel hadoop103.plan.json
LZO Compression Configuration
Hadoop does not support LZO compression by itself, so you need to use the hadoop-lzo open source component provided by twitter. hadoop-lzo relies on both Hadoop and LZO for compilation. The compilation step is omitted and the package is jar: hadoop-lzo-0.4.20.jar
# 1. Place the compiled hadoop-lzo-0.4.20.jar in hadoop-3.1.3/share/hadoop/common/
[atguigu@hadoop102 common]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/common
[atguigu@hadoop102 common]$ ls
hadoop-lzo-0.4.20.jar
# 2. Synchronize hadoop-lzo-0.4.20.jar to hadoop103, hadoop104
[atguigu@hadoop102 common]$ my_rsync.sh hadoop-lzo-0.4.20.jar
# 3.core-site.xml Add configuration to support LZO compression
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
# 4. Synchronize core-site.xml to hadoop103, hadoop104
[atguigu@hadoop102 hadoop]$ my_rsync.sh core-site.xml
# 5. Start and view clusters
[atguigu@hadoop102 hadoop-3.1.3]$ start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ start-yarn.sh
# 5. Testing lzo compression
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /lzo-output
# 5. Testing lzo slices
# Note: lzo slices must be indexed and a new file suffixed with.index will be created after execution
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /lzo-input/bigtable.lzo
# Test the lzo slice (replace the default TextInputFormat with LzoInputFormat)
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount - Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /lzo-input /lzo-output
Benchmarking
Testing HDFS write performance
# Test command (-nrFiles set to cpu count-2) Hadoop jar/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO-write-nrFiles 4-fileSize 128MB
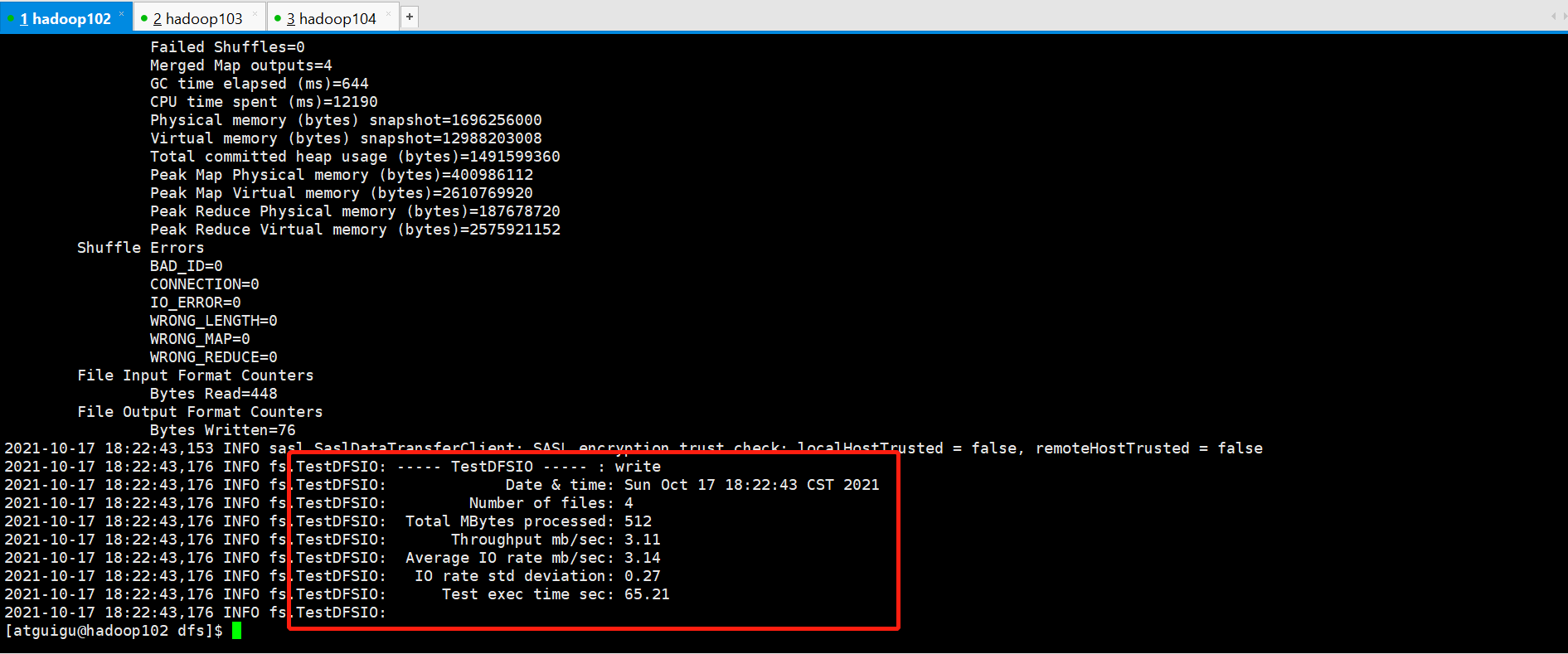
Testing HDFS Read Performance
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 4 -fileSize 128MB
Delete test generated data
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
hadoop parameter tuning
HDFS parameter tuning hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode There is a pool of worker threads to handle differences DataNode Concurrent heartbeats and client-side concurrent metadata operations.
For large clusters or clusters with a large number of clients, you typically need to increase parameters dfs.namenode.handler.count Default value of 10.
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
Calculation formula:

YARN parameter tuning yarn-site.xml
(1)Scenario description: A total of 7 machines, hundreds of millions of data per day, data source->Flume->Kafka->HDFS->Hive Problem: Data statistics are mainly used HiveSQL,No data skew, small files have been merged, open JVM Reuse, and IO No blocking, less than 50 memory used%. But it's still very slow, and when data rushes in, the entire cluster will be down. Is there an optimization plan based on this? (2)Solution: Memory utilization is insufficient. This is generally Yarn The maximum memory size a single task can request due to two configurations, and Hadoop Available memory size for a single node. Adjusting these two parameters can improve system memory utilization. (a)yarn.nodemanager.resource.memory-mb Represents on this node YARN The total amount of physical memory available is 8192 by default. MB),Note that if your node has insufficient memory resources of 8 GB,You need to adjust the value to decrease it, and YARN The total amount of physical memory of probing nodes that will not be intelligent. (b)yarn.scheduler.maximum-allocation-mb The maximum amount of physical memory a single task can request is 8192 by default. MB).
zookeeper installation configuration
Cluster Planning
| Server hadoop102 | Server hadoop103 | Server hadoop104 | |
|---|---|---|---|
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
Unzip installation
# decompression [atguigu@hadoop102 module]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C ../module/ # Configuring environment variables # zookeeper export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7 export PATH=$PATH:$ZOOKEEPER_HOME/bin # Modify zookeeper's configuration file (create zkData folder, myid file, do not repeat id:2,3,4,) # Also rename zoo.sample.conf to zoo.cfg dataDir=/opt/module/zookeeper-3.5.7/zkData server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 server.4=hadoop104:2888:3888 # Files distributed to 103,104 [atguigu@hadoop102 module]$ my_rsync.sh zookeeper-3.5.7/ # Change myid file 3,4 after distribution # Distributing environment variables [atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/ [atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop104:/etc/profile.d/
ZK group startup script zk_cluster.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: zk.sh {start|stop|status}"
exit
fi
case $1 in
start)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> START $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
done
;;
stop)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> STOP $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
done
;;
status)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> STATUS $i ZK <================="
ssh $i /opt/module/zookeeper-3.5.7/bin/zkServer.sh status
done
;;
*)
echo "USAGE: zk.sh {start|stop|status}"
exit
;;
esac
kafka installation configuration
Cluster Planning
| Server hadoop102 | Server hadoop103 | Server hadoop104 | |
|---|---|---|---|
| Kafka | Kafka | Kafka | Kafka |
Unzip installation
# decompression [atguigu@hadoop102 config]$ tar -zxvf kafka_2.11-2.4.1.tgz -C ../module/ # Create a new data directory in the installation directory to store message data # Modify Profile broker.id=2 log.dirs=/opt/module/kafka_2.11-2.4.1/datas zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka # Writing environment variables #kafka export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1 export PATH=$PATH:$KAFKA_HOME/bin # Distribute the kafka installation directory (each modifying broker.id) and environment variables [atguigu@hadoop102 module]$ my_rsync.sh kafka_2.11-2.4.1/ [atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop103:/etc/profile [atguigu@hadoop102 module]$ scp /etc/profile.d/my_env.sh root@hadoop104:/etc/profile
kafka group startup script
#!/bin/bash
if [ $# -lt 1 ]
then
echo "USAGE: kafka.sh {start|stop}"
exit
fi
case $1 in
start)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> START $i KF <================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties
done
;;
stop)
for i in hadoop102 hadoop103 hadoop104
do
echo "=================> STOP $i KF <================="
ssh $i /opt/module/kafka_2.11-2.4.1/bin/kafka-server-stop.sh
done
;;
*)
echo "USAGE: kafka.sh {start|stop}"
exit
;;
esac
kafka pressure test
Use Kafka's official script to test Kafka. During Kafka's test, you can see where there is a bottleneck (CPU, memory, network IO). Network IO is generally the bottleneck.
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
# Kafka Producer Pressure Test (1)stay/opt/module/kafka/bin There are two files under the directory. Let's test them [atguigu@hadoop102 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 # Explain: record-size Is the size of the information in bytes. num-records Is the total number of messages sent. throughput How many messages per second, set to-1,Represents an unlimited flow that measures the maximum throughput of a producer. (2)Kafka The following information will be printed 100000 records sent, 95877.277085 records/sec (9.14 MB/sec), 187.68 ms avg latency, 424.00 ms max latency, 155 ms 50th, 411 ms 95th, 423 ms 99th, 424 ms 99.9th. Parameter parsing: In this case, a total of 10 are written w Messages, throughput 9.14 MB/sec,The average latency per write is 187.68 Milliseconds, maximum delay 424.00 Millisecond. # Kafka Consumer Pressure Test Consumer Test if these four indicators ( IO,CPU,Memory, network) cannot be changed, consider increasing the number of partitions to improve performance. [atguigu@hadoop102 kafka]$ bin/kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1 Parameter description: --zookeeper Appoint zookeeper Link information for --topic Appoint topic Name of --fetch-size Specify each time fetch Size of data --messages Total number of messages to consume Test result description: start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec 2019-02-19 20:29:07:566, 2019-02-19 20:29:12:170, 9.5368, 2.0714, 100010, 21722.4153 Start test time, end test data, total consumption data 9.5368MB,Throughput 2.0714MB/s,Total consumption 10,000, average consumption 21,722 per second.4153 Bar.
Number calculation of kafka machines
Empirical formula
Kafka Number of machines (empirical formula)=2*(Peak production rate*Number of copies/100)+1 Get peak production speed first, then estimate deployment based on the number of copies set Kafka Quantity. For example, our peak production rate is 50 M/s. The number of copies is 2. Kafka Number of machines=2*(50*2/100)+ 1=3 platform
kafka partition formula
https://blog.csdn.net/weixin_42641909/article/details/89294698
1)Create a partition-only topic 2)Test this topic Of producer Throughput and throughput consumer Throughput. 3)Assume their values are Tp and Tc,Units can be MB/s. 4)Then assume that the total target throughput is Tt,So the number of partitions=Tt / min(Tp,Tc) For example: producer throughput=20m/s;consumer throughput=50m/s,Expected throughput 100 m/s; Number of partitions=100 / 20 =5 partition The number of partitions is generally set to:3-10 individual