Introduction: For the enhancement of seven segment nixie tube pictures, LeNet is used to establish the recognition model of the data set. Based on this model, it will be used to recognize the numbers in actual pictures in the future.
Key words: LCD, LENET
§ 01 seven segment digital identification
1.1 data collection preparation
1.1.1 pictures in the paper
(1) Original picture
the following is from 7 segment LCD Optical Character Recognition A set of ten character data. Divide them into their own pictures.
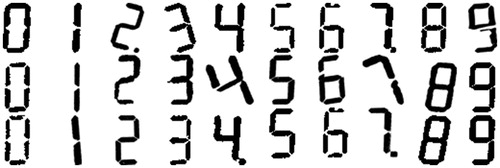

(2) Split digital picture
from headm import * # =
import cv2
iddim = [8, 11, 9, 10]
outdir = r'd:\temp\lcd2seg'
if not os.path.isdir(outdir):
os.makedirs(outdir)
def pic2num(picid, boxid, rownum, headstr):
global outdir
imgfile = tspgetdopfile(picid)
printt(imgfile:)
img = cv2.imread(imgfile)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
printt(img.shape, gray.shape)
plt.imshow(gray, plt.cm.gray)
plt.savefig(r'd:\temp\figure1.jpg')
tspshowimage(image=r'd:\temp\figure1.jpg')
imgrect = tspgetrange(picid)
boxrect = tspgetrange(boxid)
imgwidth = gray.shape[1]
imgheight = gray.shape[0]
boxheight = boxrect[3] - boxrect[1]
boxwidth = boxrect[2] - boxrect[0]
for i in range(rownum):
rowstart = boxrect[1] - imgrect[1] + boxheight * i / rownum
rowend = boxrect[1] - imgrect[1] + boxheight * (i+1) / rownum
imgtop = int(rowstart * imgheight / (imgrect[3] - imgrect[1]))
imgbottom = int(rowend * imgheight / (imgrect[3] - imgrect[1]))
for j in range(10):
colstart = boxrect[0] - imgrect[0] + boxwidth * j / 10
colend = boxrect[0] - imgrect[0] + boxwidth * (j + 1) / 10
imgleft = int(colstart * imgwidth / (imgrect[2] - imgrect[0]))
imgright = int(colend * imgwidth / (imgrect[2] - imgrect[0]))
imgdata = gray[imgtop:imgbottom+1, imgleft:imgright+1]
fn = os.path.join(outdir, '%s_%d_%d.jpg'%(headstr, i, j))
cv2.imwrite(fn, imgdata)
pic2num(iddim[2], iddim[3], 4, '2')

a total of 70 pictures were obtained. Naming standard of pictures: the last letter represents a number.
1.2 data set expansion
amplify the picture. Amplification method:
- Rotation: - 25 ~ 25
- Scale: 0.9 ~ 1.1
- Translation: x,y: -5,5
each picture is expanded to the original 225.
1.2.1 picture amplification procedure
from headm import * # =
import cv2
import paddle
from paddle.vision.transforms import Resize,rotate,adjust_brightness,adjust_contrast
from PIL import Image
from tqdm import tqdm
from tqdm import tqdm
indir = '/home/aistudio/work/lcd7seg/lcd2seg'
outdir = '/home/aistudio/work/lcd7seg/lcdaugment'
infile = os.listdir(indir)
printt(infile:)
BUF_SIZE = 512
def rotateimg(img, degree, ratio, shift_x, shift_y):
imgavg = mean(img.flatten())
if imgavg < 100:
img[img >= 200] = imgavg
imgavg = mean(img.flatten())
img[img >= 200] = imgavg
else: imgavg = 255
whiteimg = ones((BUF_SIZE, BUF_SIZE, 3))*(imgavg/255)
imgshape = img.shape
imgwidth = imgshape[0]
imgheight = imgshape[1]
left = (BUF_SIZE - imgwidth) // 2
top = (BUF_SIZE - imgheight) // 2
whiteimg[left:left+imgwidth, top:top+imgheight, :] = img/255
img1 = rotate(whiteimg, degree)
centerx = BUF_SIZE//2+shift_x
centery = BUF_SIZE//2+shift_y
imgwidth1 = int(imgwidth * ratio)
imgheight1 = int(imgheight * ratio)
imgleft = centerx - imgwidth1//2
imgtop = centery - imgheight1//2
imgnew = img1[imgleft:imgwidth1+imgleft, imgtop:imgtop+imgheight1, :]
imgnew = cv2.resize(imgnew, (32,32))
return imgnew*255
gifpath = '/home/aistudio/GIF'
if not os.path.isdir(gifpath):
os.makedirs(gifpath)
gifdim = os.listdir(gifpath)
for f in gifdim:
fn = os.path.join(gifpath, f)
if os.path.isfile(fn):
os.remove(fn)
count = 0
def outimg(fn):
global count
imgfile = os.path.join(indir, fn)
img = cv2.imread(imgfile)
num = fn.split('.')[0][-1]
rotate = linspace(-25, 25, 5).astype(int)
ratio = linspace(0.8, 1.2, 5)
shiftxy = linspace(-5, 5, 3).astype(int)
for r in rotate:
for t in ratio:
for s in shiftxy:
for h in shiftxy:
imgout = rotateimg(img, r, t, s, h)
outfilename = os.path.join(gifpath, '%04d_%s.jpg'%(count, num))
count += 1
cv2.imwrite(outfilename, imgout)
outfilename = os.path.join(gifpath, '%04d_%s.jpg'%(count, num))
count += 1
cv2.imwrite(outfilename, 255-imgout)
for id,f in tqdm(enumerate(infile)):
if f.find('jpg') < 0: continue
outimg(f)
1.2.2 amplification results
after each picture is amplified, it is 225, plus the color reversal, 70 pictures, and finally 31500 digital pictures are obtained.
Database parameters: Number: 0 ~ 9Number: 31500
Size: 32 × thirty-two × three
1.3 storing data files
1.3.1 conversion code
from headm import * # =
import cv2
lcddir = '/home/aistudio/work/lcd7seg/GIF'
filedim = os.listdir(lcddir)
printt(len(filedim))
imagedim = []
labeldim = []
for f in filedim:
fn = os.path.join(lcddir, f)
if fn.find('.jpg') < 0: continue
gray = cv2.cvtColor(cv2.imread(fn), cv2.COLOR_BGR2GRAY)
imagedim.append(gray)
num = int(f.split('.')[0][-1])
labeldim.append(num)
imgarray = array(imagedim)
label = array(labeldim)
savez('/home/aistudio/work/lcddata', lcd=imgarray, label=label)
printt("Save lcd data.")
1.3.2 data files
Data file: File name: lcddata npzlcd: (31500,32,32)
label: (31500)
§ 02 building LeNet
2.1 building LeNet network
from headm import * # =
import paddle
import paddle.fluid as fluid
from paddle import to_tensor as TT
from paddle.nn.functional import square_error_cost as SQRC
datafile = '/home/aistudio/work/lcddata.npz'
data = load(datafile)
lcd = data['lcd']
llabel = data['label']
printt(lcd.shape, llabel.shape)
class Dataset(paddle.io.Dataset):
def __init__(self, num_samples):
super(Dataset, self).__init__()
self.num_samples = num_samples
def __getitem__(self, index):
data = lcd[index][newaxis,:,:]
label = llabel[index]
return paddle.to_tensor(data,dtype='float32'), paddle.to_tensor(label,dtype='int64')
def __len__(self):
return self.num_samples
_dataset = Dataset(len(llabel))
train_loader = paddle.io.DataLoader(_dataset, batch_size=100, shuffle=True)
imgwidth = 32
imgheight = 32
inputchannel = 1
kernelsize = 5
targetsize = 10
ftwidth = ((imgwidth-kernelsize+1)//2-kernelsize+1)//2
ftheight = ((imgheight-kernelsize+1)//2-kernelsize+1)//2
class lenet(paddle.nn.Layer):
def __init__(self, ):
super(lenet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=inputchannel, out_channels=6, kernel_size=kernelsize, stride=1, padding=0)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=kernelsize, stride=1, padding=0)
self.mp1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.mp2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.L1 = paddle.nn.Linear(in_features=ftwidth*ftheight*16, out_features=120)
self.L2 = paddle.nn.Linear(in_features=120, out_features=86)
self.L3 = paddle.nn.Linear(in_features=86, out_features=targetsize)
def forward(self, x):
x = self.conv1(x)
x = paddle.nn.functional.relu(x)
x = self.mp1(x)
x = self.conv2(x)
x = paddle.nn.functional.relu(x)
x = self.mp2(x)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self.L1(x)
x = paddle.nn.functional.relu(x)
x = self.L2(x)
x = paddle.nn.functional.relu(x)
x = self.L3(x)
return x
model = lenet()
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
def train(model):
model.train()
epochs = 100
for epoch in range(epochs):
for batch, data in enumerate(train_loader()):
out = model(data[0])
loss = paddle.nn.functional.cross_entropy(out, data[1])
acc = paddle.metric.accuracy(out, data[1])
loss.backward()
optimizer.step()
optimizer.clear_grad()
print('Epoch:{}, Accuracys:{}'.format(epoch, acc.numpy()))
train(model)
paddle.save(model.state_dict(), './work/model.pdparams')
2.2 training results
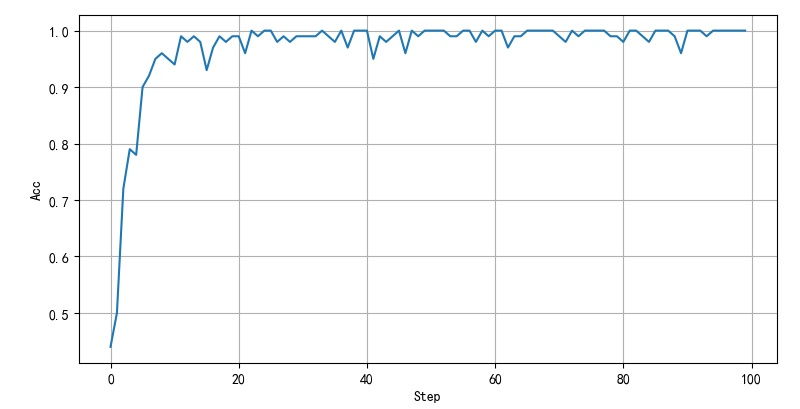
2.2.1 first training
Training parameters: Lr=0.001:BatchSize=100:
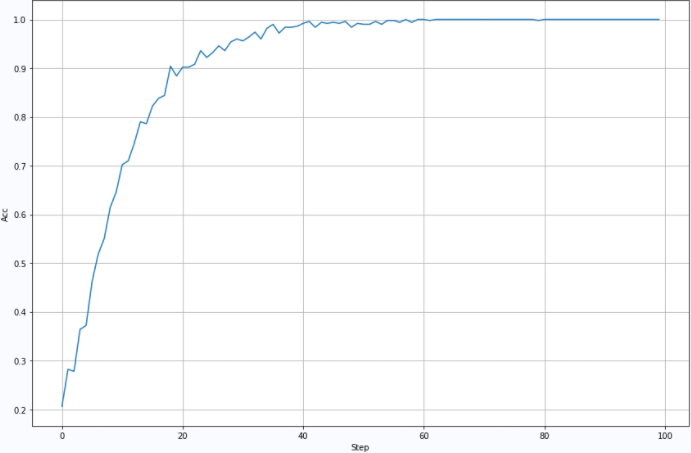
2.2.2 second training
Training parameters: BatchSize=1000:Lr=0.001:
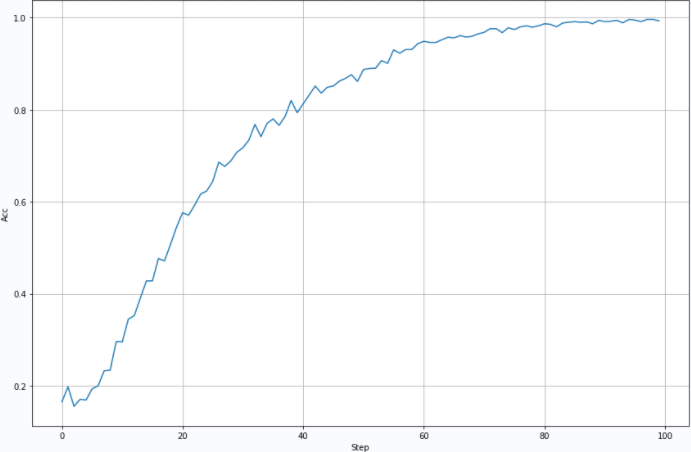
2.2.3 the third training
Training parameters: BatchSize=5000:Lr=0.005:
2.2.4 the fourth training
Training parameters: BatchSize: 2000Lr=0.002:
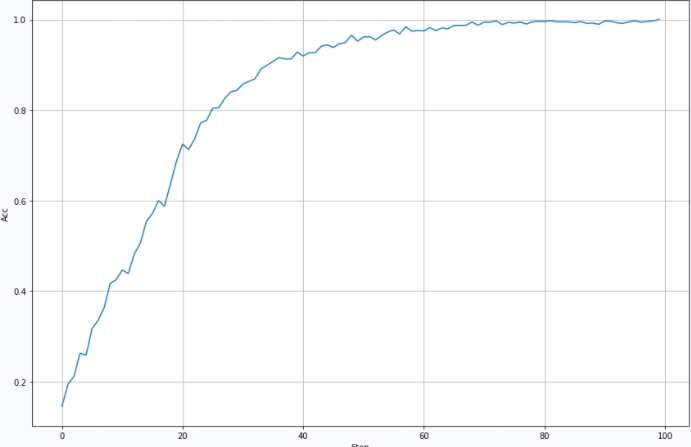
2.2.5 the fifth training
Training parameters: BatchSize: 2000Lr=0.001:
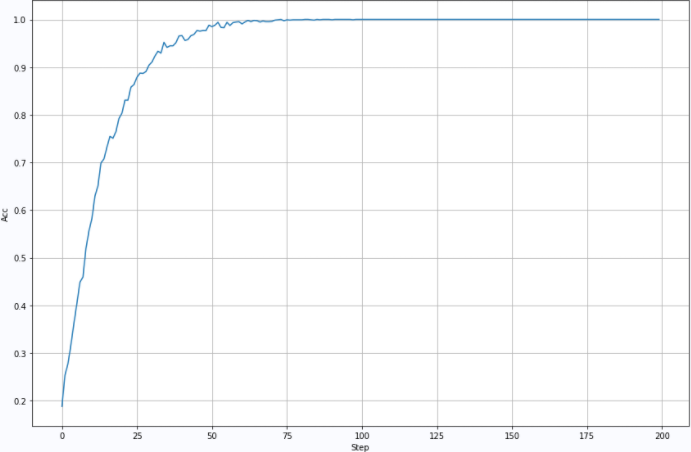
※ treatment summary ※
for the enhancement of seven segment nixie tube pictures, LeNet is used to establish a recognition model for the data set. Based on this model, it will be used to recognize the numbers in actual pictures in the future.
3.1 appendix: handling procedure
3.1.1 LCDLENET
from headm import * # =
import paddle
import paddle.fluid as fluid
from paddle import to_tensor as TT
from paddle.nn.functional import square_error_cost as SQRC
datafile = '/home/aistudio/work/lcddata.npz'
data = load(datafile)
lcd = data['lcd']
llabel = data['label']
printt(lcd.shape, llabel.shape)
class Dataset(paddle.io.Dataset):
def __init__(self, num_samples):
super(Dataset, self).__init__()
self.num_samples = num_samples
def __getitem__(self, index):
data = lcd[index][newaxis,:,:]
label = llabel[index]
return paddle.to_tensor(data,dtype='float32'), paddle.to_tensor(label,dtype='int64')
def __len__(self):
return self.num_samples
_dataset = Dataset(len(llabel))
train_loader = paddle.io.DataLoader(_dataset, batch_size=2000, shuffle=True)
imgwidth = 32
imgheight = 32
inputchannel = 1
kernelsize = 5
targetsize = 10
ftwidth = ((imgwidth-kernelsize+1)//2-kernelsize+1)//2
ftheight = ((imgheight-kernelsize+1)//2-kernelsize+1)//2
class lenet(paddle.nn.Layer):
def __init__(self, ):
super(lenet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=inputchannel, out_channels=6, kernel_size=kernelsize, stride=1, padding=0)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=kernelsize, stride=1, padding=0)
self.mp1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.mp2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.L1 = paddle.nn.Linear(in_features=ftwidth*ftheight*16, out_features=120)
self.L2 = paddle.nn.Linear(in_features=120, out_features=86)
self.L3 = paddle.nn.Linear(in_features=86, out_features=targetsize)
def forward(self, x):
x = self.conv1(x)
x = paddle.nn.functional.relu(x)
x = self.mp1(x)
x = self.conv2(x)
x = paddle.nn.functional.relu(x)
x = self.mp2(x)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self.L1(x)
x = paddle.nn.functional.relu(x)
x = self.L2(x)
x = paddle.nn.functional.relu(x)
x = self.L3(x)
return x
model = lenet()
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
def train(model):
model.train()
epochs = 200
for epoch in range(epochs):
for batch, data in enumerate(train_loader()):
out = model(data[0])
loss = paddle.nn.functional.cross_entropy(out, data[1])
acc = paddle.metric.accuracy(out, data[1])
loss.backward()
optimizer.step()
optimizer.clear_grad()
printt('Epoch:{}, Accuracys:{}'.format(epoch, acc.numpy()))
train(model)
paddle.save(model.state_dict(), './work/model3.pdparams')
filename = '/home/aistudio/stdout.txt'
accdim = []
with open(filename, 'r') as f:
for l in f.readlines():
ll = l.split('[')
if len(ll) < 2: continue
ll = ll[-1].split(']')
if len(ll) < 2: continue
accdim.append(float(ll[0]))
plt.figure(figsize=(12, 8))
plt.plot(accdim)
plt.xlabel("Step")
plt.ylabel("Acc")
plt.grid(True)
plt.tight_layout()
plt.show()
3.1.2 DrawCurve
accdim = []
with open(filename, 'r') as f:
for l in f.readlines():
ll = l.split('[')
if len(ll) < 2: continue
ll = ll[-1].split(']')
if len(ll) < 2: continue
accdim.append(float(ll[0]))
plt.figure(figsize=(12, 8))
plt.plot(accdim)
plt.xlabel("Step")
plt.ylabel("Acc")
plt.grid(True)
plt.tight_layout()
plt.show()
3.1.3 data processing program
from headm import * # =
import cv2
lcddir = '/home/aistudio/work/lcd7seg/GIF'
filedim = os.listdir(lcddir)
printt(len(filedim))
imagedim = []
labeldim = []
for f in filedim:
fn = os.path.join(lcddir, f)
if fn.find('.jpg') < 0: continue
gray = cv2.cvtColor(cv2.imread(fn), cv2.COLOR_BGR2GRAY)
imagedim.append(gray)
num = int(f.split('.')[0][-1])
labeldim.append(num)
imgarray = array(imagedim)
label = array(labeldim)
savez('/home/aistudio/work/lcddata', lcd=imgarray, label=label)
printt("Save lcd data.")
■ links to relevant literature:
● relevant chart links:
- Figure 1.1 seven segment digital deformation picture
- Figure 1.1.2 segmented digital picture
- Figure image of each image after multiplication
- Figure image of each image after multiplication
- Figure 2.2.1 training accuracy
- Figure 2.2.2 recognition accuracy during training
- Figure 2.2.3 recognition accuracy during training
- Figure 2.2.4 recognition accuracy during training
- Figure 2.2.5 recognition accuracy during training