Hash table
Such as HashMap in Java, a (K,V) data storage structure. The bottom layer of HashMap uses array + linked list, mainly array, not all hash tables.
When adding an element to the hash table, get a hash value from the key of the element through a specific hash function and calculate the storage location stored in the current array.
Hash function
A function that calculates the corresponding hash value through a specific function. Also called hash function.
Hash conflict
After hashing the keys of the same elements, the same hash value will be obtained.
Different keys should get different hash values through hash calculation theory, but such a "perfect" hash function has not been used in reality, so different keys may calculate the same hash value; In addition, the stored array is not large. When there are too many elements, multiple elements may be calculated to the same position of the array. This is hash conflict, also known as hash conflict.
resolvent
The following only introduces several methods. There are many solutions in reality. Please refer to relevant materials for details.
open addressing
The underlying storage is an array:
(p.s. hasn't understood this solution before. In fact, it's just a few words.)
- After hash calculation, find the position in the array
- If an element already exists in this location, continue to find an idle location
The existing element in the location is a hash conflict. Continue to detect the next free location as follows:
- Linear detection
- Secondary detection
- double hashing
- ...
The process of adding, querying and deleting is described by linear detection, as follows:

The position of the black number indicates the existing element, and the blue indicates the free position.
increase
When adding an element, there is a conflict. Look back in sequence until a spatial location is found, as shown in the above figure. If the new element is located in element 1, it already exists, continue to look back, 2 also exists, and then look back and find 3.
If the new element is 10, look for 10 - > 11 - > 1 - > 2 - > 3 in turn. 3 is the free position.
query
After hash, the position is 1. After comparison, it is found that it is not. Continue to look down. If 2 is, it is found. If 2 is not yet, look back and 3 is an idle position, indicating that the element does not exist. If it is empty, it is over.
delete
When deleting an element, you cannot delete it directly because it will affect the query. The judgment condition for the end of the query may be that it is empty. Therefore, when deleting, only mark the element as deleted (if the mark is deleted during query, it must not be).
The difference between other detection methods is that the step length of continuous detection is different. For example, the linear detection above is one step at a time, the secondary detection is the square of the current number of steps, and the double Hash is to use multiple Hash functions to replace the next Hash function in case of conflict.
Example
The ThreadLocalMap in java uses linear detection. If the hash conflicts, look down until a suitable location is found.
This is part of the code during set:
for (Entry e = tab[i];
e != null;
// nextIndex is i+1 or 0: (i+1 < len)? i+1 : 0
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
// Replace existing
e.value = value;
return;
}
// Write if it does not exist
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}Linked list method
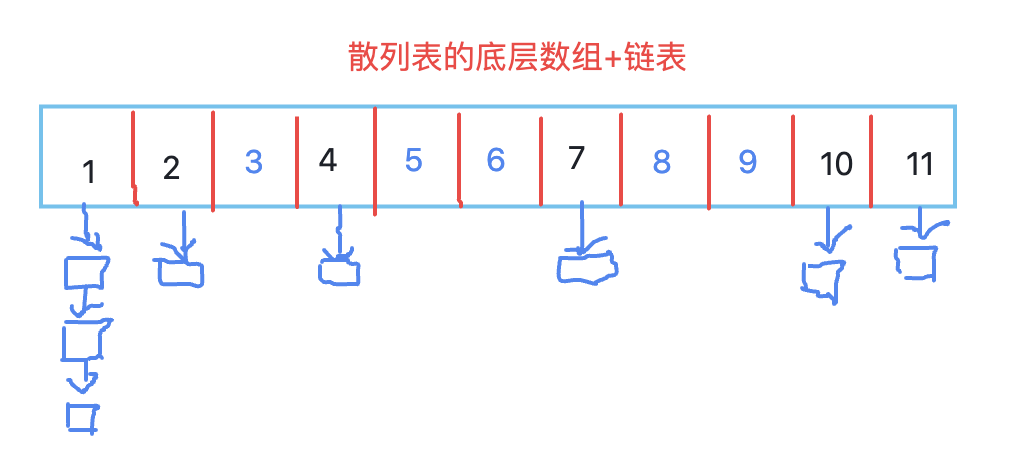
The underlying storage is still an array, but each location actually stores a linked list. When an element is added, it is a new node on the linked list at this location.
newly added
After hash ing the key, calculate the position in the array. After comparison, if there is no such element in the current link, the element will be added as a node of the linked list. If it exists, it will be replaced.
query
After the key hash, calculate the position in the array, and compare the nodes on the linked list one by one until they are found or empty.
delete
If the node is found, it is a conventional linked list to delete a node, and there is no need to deal with it.
Example
HashMap in Java is basically the implementation of this method. The difference is that it is not necessarily a pure linked list. In the implementation of jdk8 (no specific attention in other versions), when there are 8 nodes on the chain, it becomes a red black tree.
In order to visually see the implementation, copy part of the source code:
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}