9 cases
9.1 requirements description
The list of goods on the e-commerce platform is displayed. In addition to the basic information and description information of the goods, each list item also includes the store information to which the goods belong, as follows:
The functions of this case are as follows:
- Add item
- Product paging query
- Commodity Statistics
9.2 database design
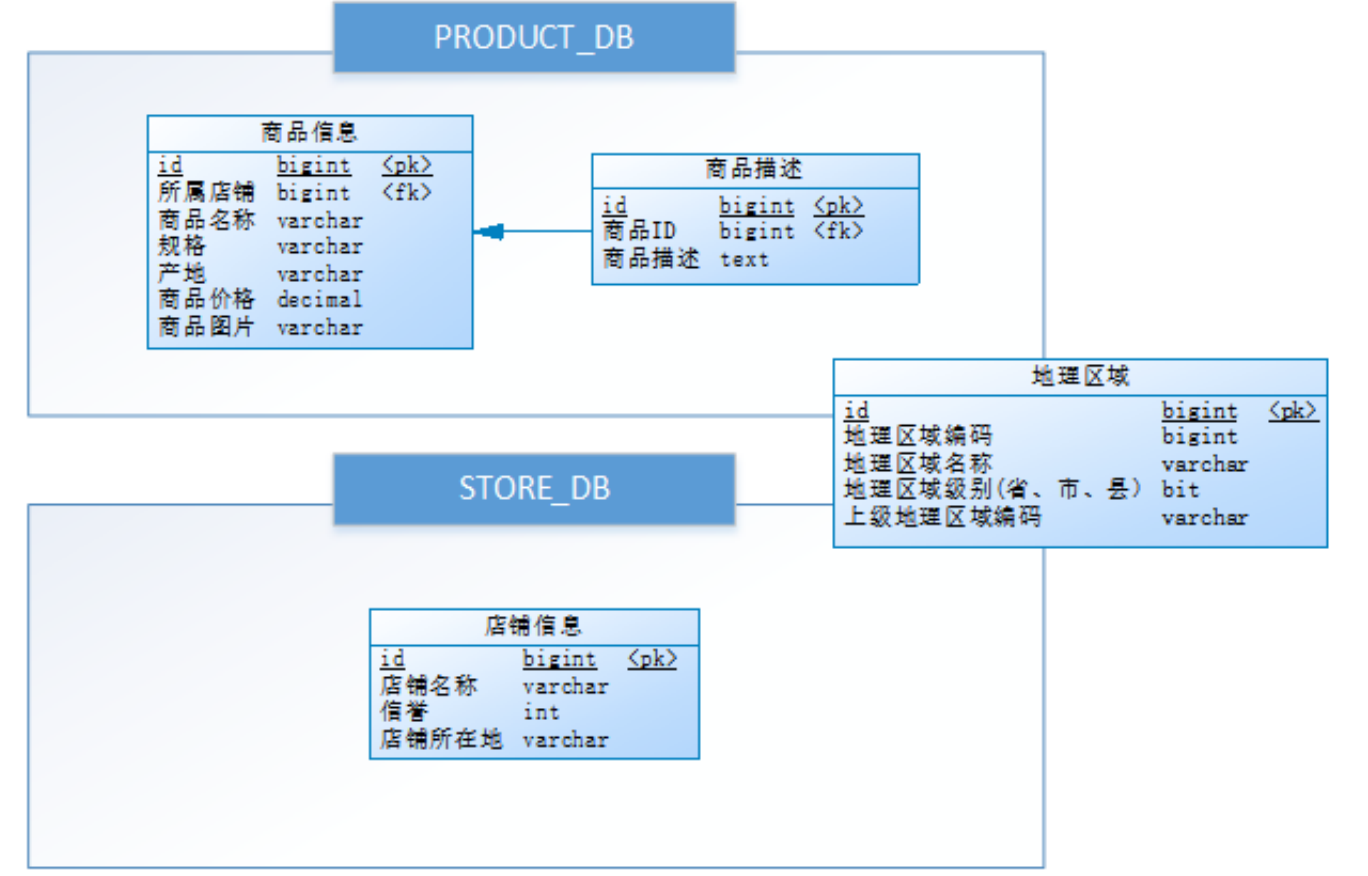
The database design is as follows, in which there is a vertical sub database between goods and store information, which is divided into product_ DB and store_ DB (store library); Commodity information is also divided into vertical tables, which are divided into product_info and product_description. Geographic region information is used as a common table and redundant in two databases:
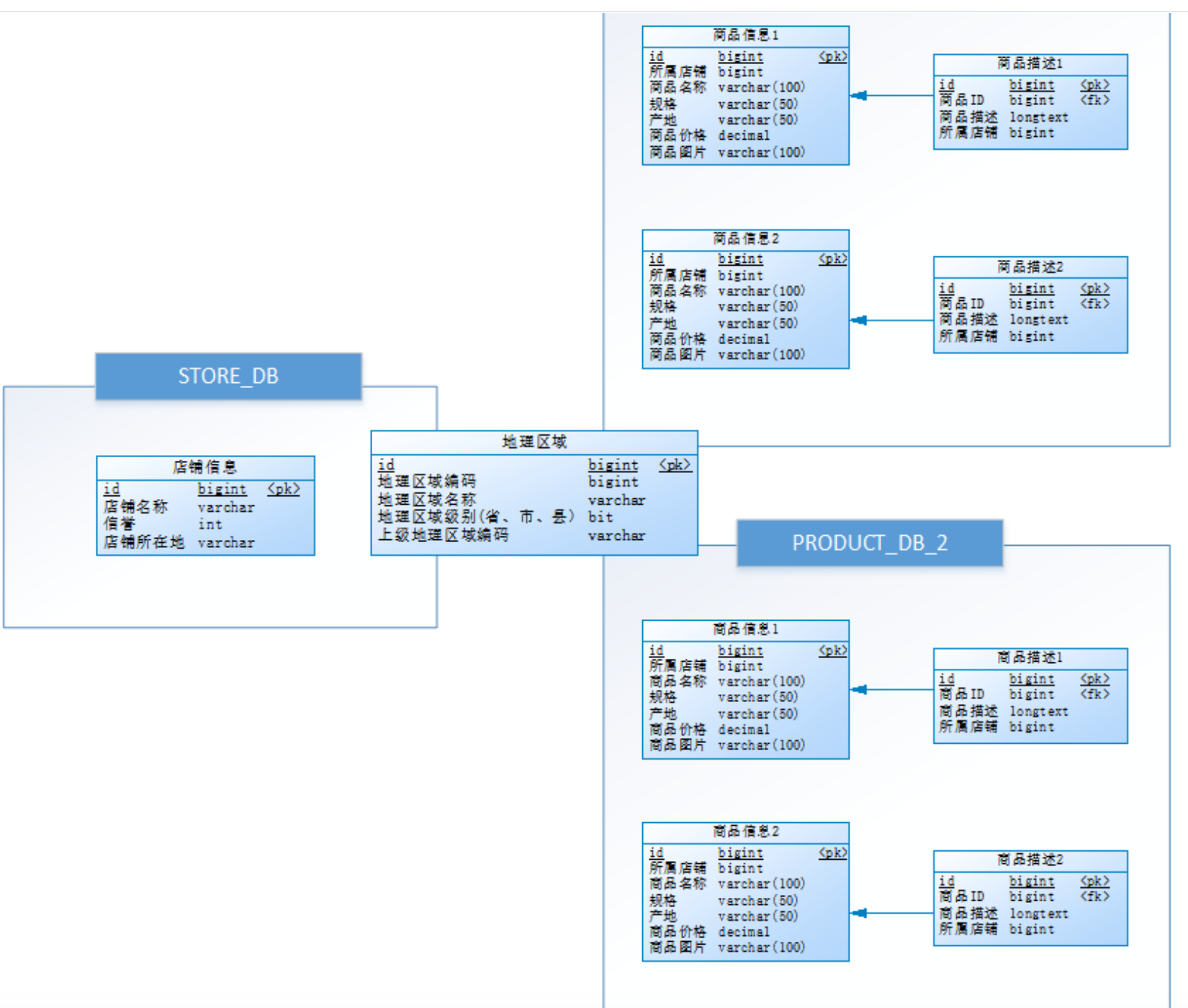
- Considering the data growth of commodity information, product_ The DB (commodity Library) has a horizontal sub library. The partition key uses the store ID, and the partition strategy is store ID%2 + 1. Therefore, the commodity description information is redundant to the store ID;
- The basic information (product_info) and product_description (product_description) of products are horizontally divided into tables. The partition key uses the product id, and the partition strategy is product ID%2 + 1. These two tables are set as binding tables to avoid Cartesian product join;
- In order to avoid primary key conflict, D generation strategy uses snowflake algorithm to generate globally unique ID. the final database design is as follows:
It is required to use read-write separation to improve performance and availability.
9.3 environmental description
Operating system: Win10 database: MySQL-5.7.25
JDK: 64 bit jdk1 8.0_ two hundred and one
Application framework: spring-boot-2.1.3 RELEASE,Mybatis3. five
Sharding-JDBC: sharding-jdbc-spring-boot-starter-4.0.0-RC1
9.4 environmental preparation
9.4.1 mysql master-slave synchronization (windows)
Refer to the read-write separation section to configure the master-slave synchronization of the following libraries:
#Set the database to be synchronized
binlog‐do‐db=store_db
binlog‐do‐db=product_db_1
binlog‐do‐db=product_db_2
9.4.2 initializing the database
Create store_db database and execute the following script to create the table:
create database store_db charset utf8; DROP TABLE IF EXISTS `region`; CREATE TABLE `region` ( `id` bigint(20) NOT NULL COMMENT 'id', `region_code` varchar(50) DEFAULT NULL COMMENT 'Geographical area coding', `region_name` varchar(100) DEFAULT NULL COMMENT 'Geographical area name', `level` tinyint(1) DEFAULT NULL COMMENT 'Geographic region level(Province, city and county)', `parent_region_code` varchar(50) DEFAULT NULL COMMENT 'Superior geographic area code', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; INSERT INTO `region` VALUES (1, '110000', 'Beijing', 0, NULL); INSERT INTO `region` VALUES (2, '410000', 'Henan Province', 0, NULL); INSERT INTO `region` VALUES (3, '110100', 'Beijing', 1, '110000'); INSERT INTO `region` VALUES (4, '410100', 'Zhengzhou City', 1, '410000'); DROP TABLE IF EXISTS `store_info`; CREATE TABLE `store_info` ( `id` bigint(20) NOT NULL COMMENT 'id', `store_name` varchar(100) DEFAULT NULL COMMENT 'Shop name', `reputation` int(11) DEFAULT NULL COMMENT 'Credit rating', `region_code` varchar(50) DEFAULT NULL COMMENT 'Store location', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; INSERT INTO `store_info` VALUES (1, 'XX snack shop', 4, '110100'); INSERT INTO `store_info` VALUES (2, 'XX Beverage shop', 3, '410100');
Create product_db_1,product_db_2 database, and execute the following scripts for the two databases to create tables:
create database product_db_1 charset utf8; create database product_db_2 charset utf8;
DROP TABLE IF EXISTS `product_descript_1`; CREATE TABLE `product_descript_1` ( `id` bigint(20) NOT NULL COMMENT 'id', `product_info_id` bigint(20) DEFAULT NULL COMMENT 'Commodity id', `descript` longtext COMMENT 'Product description', `store_info_id` bigint(20) DEFAULT NULL COMMENT 'Store id', PRIMARY KEY (`id`) USING BTREE, KEY `FK_Reference_2` (`product_info_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; DROP TABLE IF EXISTS `product_descript_2`; CREATE TABLE `product_descript_2` ( `id` bigint(20) NOT NULL COMMENT 'id', `product_info_id` bigint(20) DEFAULT NULL COMMENT 'Commodity id', `descript` longtext COMMENT 'Product description', `store_info_id` bigint(20) DEFAULT NULL COMMENT 'Store id', PRIMARY KEY (`id`) USING BTREE, KEY `FK_Reference_2` (`product_info_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; DROP TABLE IF EXISTS `product_info_1`; CREATE TABLE `product_info_1` ( `product_info_id` bigint(20) NOT NULL COMMENT 'id', `store_info_id` bigint(20) DEFAULT NULL COMMENT 'Store id', `product_name` varchar(100) DEFAULT NULL COMMENT 'Trade name', `spec` varchar(50) DEFAULT NULL COMMENT 'Specifications', `region_code` varchar(50) DEFAULT NULL COMMENT 'Place of Origin', `price` decimal(10,0) DEFAULT NULL COMMENT 'commodity price', `image_url` varchar(100) DEFAULT NULL COMMENT 'Product picture', PRIMARY KEY (`product_info_id`) USING BTREE, KEY `FK_Reference_1` (`store_info_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; DROP TABLE IF EXISTS `product_info_2`; CREATE TABLE `product_info_2` ( `product_info_id` bigint(20) NOT NULL COMMENT 'id', `store_info_id` bigint(20) DEFAULT NULL COMMENT 'Store id', `product_name` varchar(100) DEFAULT NULL COMMENT 'Trade name', `spec` varchar(50) DEFAULT NULL COMMENT 'Specifications', `region_code` varchar(50) DEFAULT NULL COMMENT 'Place of Origin', `price` decimal(10,0) DEFAULT NULL COMMENT 'commodity price', `image_url` varchar(100) DEFAULT NULL COMMENT 'Product picture', PRIMARY KEY (`product_info_id`) USING BTREE, KEY `FK_Reference_1` (`store_info_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; DROP TABLE IF EXISTS `region`; CREATE TABLE `region` ( `id` bigint(20) NOT NULL COMMENT 'id', `region_code` varchar(50) DEFAULT NULL COMMENT 'Geographical area coding', `region_name` varchar(100) DEFAULT NULL COMMENT 'Geographical area name', `level` tinyint(1) DEFAULT NULL COMMENT 'Geographic region level(Province, city and county)', `parent_region_code` varchar(50) DEFAULT NULL COMMENT 'Superior geographic area code', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; INSERT INTO `region` VALUES (1, '110000', 'Beijing', 0, NULL); INSERT INTO `region` VALUES (2, '410000', 'Henan Province', 0, NULL); INSERT INTO `region` VALUES (3, '110100', 'Beijing', 1, '110000'); INSERT INTO `region` VALUES (4, '410100', 'Zhengzhou City', 1, '410000');
9.5 implementation steps
9.5.1 building maven project
(1) Build the project maven project shopping, import the basic code shopping in the data, take dbsharding as the overall parent project, and make the spring boot related configuration.
(2) Introducing maven dependency
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding‐jdbc‐spring‐boot‐starter</artifactId>
<version>4.0.0‐RC1</version>
</dependency>
9.5.2 slice configuration
Since it is divided into databases and tables, multiple real data sources need to be defined. Each database link information is a data source definition, such as:
spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/store_db?useUnicode=true&useSSL=false spring.shardingsphere.datasource.m0.username = root spring.shardingsphere.datasource.m0.password = 123456
m0 is the name of the real data source. Then we need to tell sharding JDBC which real data sources we have, such as:
spring.shardingsphere.datasource.names = m0,m1,m2,s0,s1,s2
If you need to configure read-write separation, you also need to tell sharding JDBC that there are so many real data sources, which are a set of read-write separation? That is to define the master-slave logical data source:
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0 spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0 spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=m1 spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=s1 spring.shardingsphere.sharding.master-slave-rules.ds2.master-data-source-name=m2 spring.shardingsphere.sharding.master-slave-rules.ds2.slave-data-source-names=s2
#The real data source defines m as the master database and s as the slave database
server.port=56082
spring.application.name = shopping
spring.profiles.active = local
server.servlet.context-path = /shopping
spring.http.encoding.enabled = true
spring.http.encoding.charset = UTF-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
#Sharding JDBC sharding rules
#Configure data sources m0,m1,m2,s0,s1,s2
spring.shardingsphere.datasource.names = m0,m1,m2,s0,s1,s2
spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/store_db?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = 123456
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/product_db_1?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 123456
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/product_db_2?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 123456
spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url = jdbc:mysql://localhost:3307/store_db?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = 123456
spring.shardingsphere.datasource.s1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s1.url = jdbc:mysql://localhost:3307/product_db_1?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.s1.username = root
spring.shardingsphere.datasource.s1.password = 123456
spring.shardingsphere.datasource.s2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s2.url = jdbc:mysql://localhost:3307/product_db_2?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.s2.username = root
spring.shardingsphere.datasource.s2.password = 123456
#Master-slave relationship
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=m1
spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=s1
spring.shardingsphere.sharding.master-slave-rules.ds2.master-data-source-name=m2
spring.shardingsphere.sharding.master-slave-rules.ds2.slave-data-source-names=s2
#Warehouse distribution strategy (horizontal)_ info_ ID stores are divided horizontally
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = store_info_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{store_info_id % 2 + 1}
#Table splitting strategy
# store_info sub table strategy
spring.shardingsphere.sharding.tables.store_info.actual-data-nodes = ds$->{0}.store_info
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.algorithm-expression = store_info
# product_info sub table strategy
#Data nodes include, DS1 product_ info_ 1,ds1.product_info_2,ds2.product_info_1,ds2. product_ info_ two
spring.shardingsphere.sharding.tables.product_info.actual-data-nodes = ds$->{1..2}.product_info_$->{1..2}
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.algorithm-expression = product_info_$->{product_info_id%2+1}
spring.shardingsphere.sharding.tables.product_info.key-generator.column=product_info_id
spring.shardingsphere.sharding.tables.product_info.key-generator.type=SNOWFLAKE
#product_ Describe sub table strategy
spring.shardingsphere.sharding.tables.product_descript.actual-data-nodes = ds$->{1..2}.product_descript_$->{1..2}
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.algorithm-expression = product_descript_$->{product_info_id % 2 + 1}
spring.shardingsphere.sharding.tables.product_descript.key-generator.column=id
spring.shardingsphere.sharding.tables.product_descript.key-generator.type=SNOWFLAKE
# Set product_ info,product_ Describe is the binding table
spring.shardingsphere.sharding.binding-tables[0] = product_info,product_descript
# Set region as broadcast table (public table), and each update operation will be sent to all data sources
spring.shardingsphere.sharding.broadcast-tables=region
# Open sql output log
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
9.5.3 adding goods
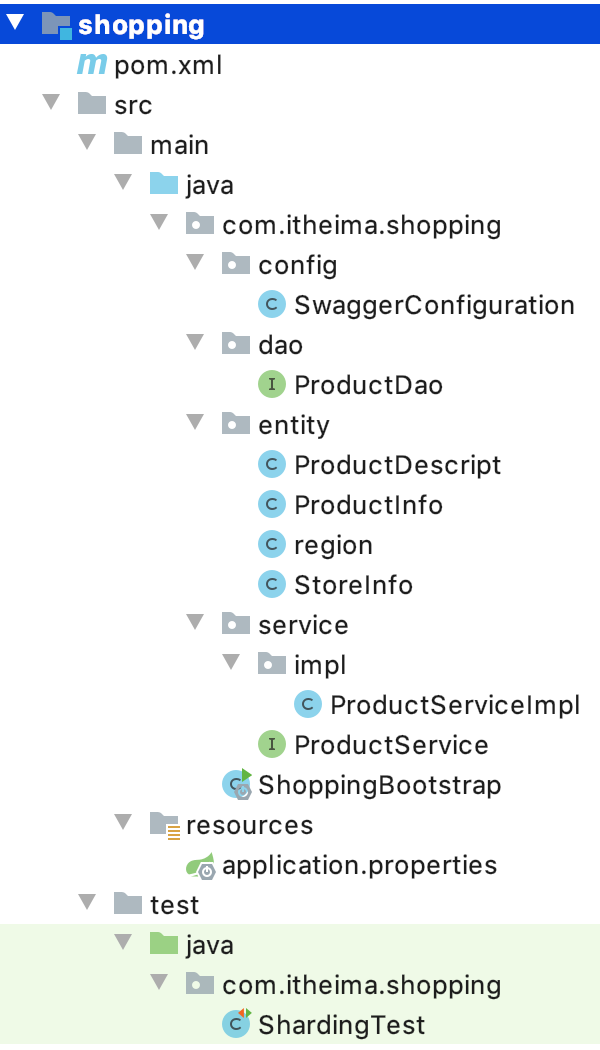
Entity class, refer to basic engineering:
DAO implementation
@Mapper
@Component
public interface ProductDao {
//Add basic information of goods
@Insert("insert into product_info(store_info_id,product_name,spec,region_code,price)
value(#{storeInfoId},#{productName},#{spec},#{regionCode},#{price})")
@Options(useGeneratedKeys = true,keyProperty = "productInfoId",keyColumn = "id")
int insertProductInfo(ProductInfo productInfo);
//Add item description information
@Insert("insert into product_descript(product_info_id,descript,store_info_id) value(#
{productInfoId},#{descript},#{storeInfoId})")
@Options(useGeneratedKeys = true,keyProperty = "id",keyColumn = "id")
int insertProductDescript(ProductDescript productDescript);
}
Service implementation: store service and commodity service are realized respectively for the two vertical sub libraries
package com.itheima.shopping.service.impl;
import com.itheima.shopping.dao.ProductDao;
import com.itheima.shopping.entity.ProductDescript;
import com.itheima.shopping.entity.ProductInfo;
import com.itheima.shopping.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
/**
* @author Administrator
* @version 1.0
**/
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
ProductDao productDao;
//Add item
@Override
@Transactional
public void createProduct(ProductInfo productInfo) {
ProductDescript productDescript = new ProductDescript();
//Set item description information
productDescript.setDescript(productInfo.getDescript());
//Call dao to send goods information table
productDao.insertProductInfo(productInfo);
//Set the product information id to productdescription
productDescript.setProductInfoId(productInfo.getProductInfoId());
//Set store id
productDescript.setStoreInfoId(productInfo.getStoreInfoId());
//Insert data into the item description information table
productDao.insertProductDescript(productDescript);
}
}
controller implementation:
/**
* Seller's product display
*/
@RestController
public class SellerController {
@Autowired
private ProductService productService;
@PostMapping("/products")
public String createProject(@RequestBody ProductInfo productInfo) {
productService.createProduct(productInfo);
return "Created successfully!";
}
Unit test:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ShardingJdbcDemoBootstrap.class)
public class ShardingTest {
@Autowired
ProductService productService;
@Test
public void testCreateProduct(){
for(long i=1;i<10;i++){
//store_info_id,product_name,spec,region_code,price,image_url
ProductInfo productInfo = new ProductInfo();
productInfo.setProductName("Java Programming thought"+i);
productInfo.setDescript("Java Programming ideas is a very good book Java course"+i);
productInfo.setRegionCode("110000");
productInfo.setStoreInfoId(1);
productInfo.setPrice(new BigDecimal(i));
productService.createProduct(productInfo);
}
}
...
Unit test:
@Test
public void testCreateProduct() {
for (int i = 1; i < 10; i++) {
ProductInfo productInfo = new ProductInfo();
productInfo.setStoreInfoId(1L);//Store id
productInfo.setProductName("Java" + i);//Trade name
productInfo.setSpec("big");
productInfo.setPrice(new BigDecimal(60));
productInfo.setRegionCode("110100");
productInfo.setDescript("Java good" + i);//Product description
productService.createProduct(productInfo);
}
}
- The snowflake algorithm, one of the global primary key generation methods provided by sharding JDBC, is used to generate the global business unique primary key.
- Through the add goods interface, add goods for sub warehouse verification, store_ info_ Data with even ID is displayed in product_db_1. Odd data in product_db_2.
- Through the add goods interface, the new goods are verified by table. Product_ Data with even ID is displayed in product_info_1,product_descript_1. Odd data in product_info_2,product_descript_2.
9.5.4 inquiry of goods
Dao implementation:
Define the product query method in ProductDao:
@Select("select i.*,d.descript,r.region_name placeOfOrigin from product_info i join product_descript d on i.product_info_id = d.product_info_id " +
" join region r on i.region_code = r.region_code order by product_info_id desc limit #{start},#{pageSize}")
List<ProductInfo> selectProductList(@Param("start") int start, @Param("pageSize") int pageSize);
Service implementation:
Define the product query method in ProductServiceImpl:
@Override
public List<ProductInfo> queryProduct(int page, int pageSize) {
int start = (page - 1) * pageSize;
return productDao.selectProductList(start, pageSize);
}
Controller implementation:
@GetMapping(value = "/products/{page}/{pageSize}")
public List<ProductInfo> queryProduct(@PathVariable("page")int page,@PathVariable("pageSize")int
pageSize){
return productService.queryProduct(page,pageSize);
}
Unit test:
//Query goods
@Test
public void testQueryProduct() {
List<ProductInfo> productInfos = productService.queryProduct(2, 2);
System.out.println(productInfos);
}
Through the query commodity list interface, you can query the commodity information of all segments, the associated geographical area and the correct store information.
Summary:
Paging query is the most common scenario in business. Sharding JDBC supports paging query of common relational databases. However, the paging function of sharding JDBC is easy to be misunderstood by users. Users usually think that paging merging will occupy a lot of memory. In the distributed scenario, the correctness of the data can be guaranteed only by rewriting LIMIT 10000000, 10 to LIMIT 0, 100000010. Users are very likely to have the illusion that ShardingSphere will load a large amount of meaningless data into memory, resulting in the risk of memory overflow. In fact, in most cases, the data result set is obtained through streaming merging. Therefore, ShardingSphere will skip all the data that does not need to be taken out through the next method of the result set and will not store it in memory. But at the same time, it should be noted that due to the need of sorting, a large amount of data still needs to be transferred to the memory space of sharding JDBC. Therefore, pagination with LIMIT is not a best practice. Since LIMIT cannot query data through index, if the continuity of ID can be guaranteed, paging through ID is a better solution, for example:
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
Or query the next page through the ID of the last record recording the last query result, for example:
SELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
The sorting function is completed by sorting and merging of sharding JDBC. Due to the ORDER BY statement in SQL, each data result set itself is ordered. Therefore, it is only necessary to sort the data value pointed by the current cursor of the data result set. This is equivalent to sorting multiple ordered arrays. Merging sorting is the most suitable sorting algorithm for this scenario.
9.5.5 statistical goods
This section realizes the statistics of the total number of commodities and the statistics of commodity groups
Dao implementation, defined in ProductDao:
//Total number of goods
@Select("select count(1) from product_info")
int selectCount();
//Commodity grouping statistics
@Select("select t.region_code,count(1) as num from product_info t group by t.region_code having num > 1 order by region_code ")
List<Map> selectProductGroupList();
Unit test:
//Total number of statistical commodities
@Test
public void testSelectCount() {
int i = productDao.selectCount();
System.out.println(i);
}
//Group statistical products
@Test
public void testSelectProductGroupList() {
List<Map> maps = productDao.selectProductGroupList();
System.out.println(maps);
}
Summary:
Grouping statistics is also a common scenario in business. The realization of grouping function is completed by sharding JDBC grouping and merging. The situation of packet merging is the most complex. It is divided into streaming packet merging and memory packet merging. Streaming grouping merging requires that the sorting items of SQL must be consistent with the fields of grouping items, otherwise the correctness of its data can only be guaranteed through memory merging.
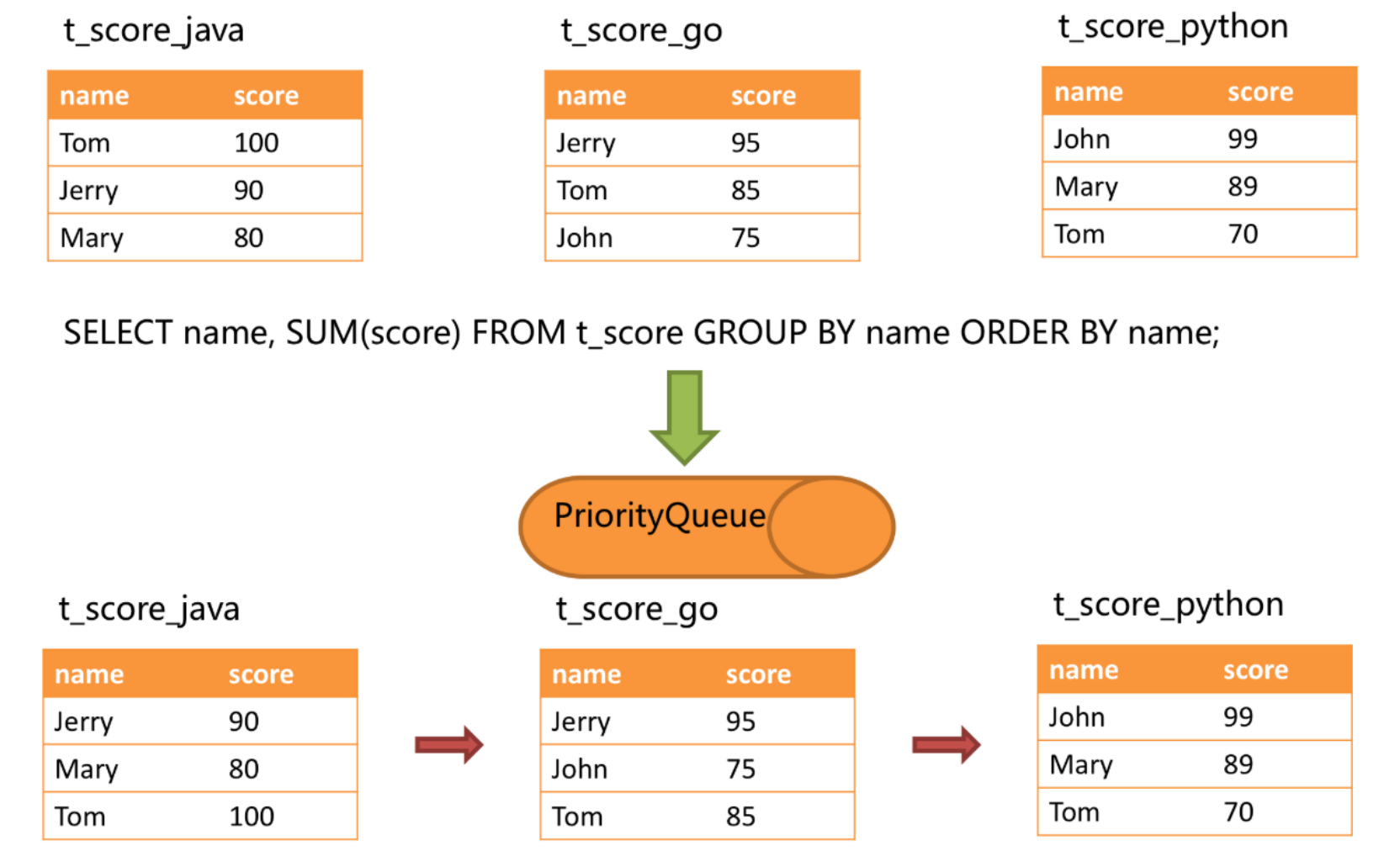
For example, suppose that according to the subject segmentation, the table structure includes the examinee's name (for simplicity, do not consider the case of duplicate names) and score. Obtain the total score of each candidate through SQL, which can be obtained through the following SQL:
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY name;
When the grouping items are completely consistent with the sorting items, the data obtained is continuous, and all the data required for grouping exists in the data value pointed to by the current cursor of each data result set. Therefore, streaming merging can be adopted. As shown in the figure below.
When merging, the logic is similar to sorting merging. The following figure shows how to merge streaming packets when calling next.
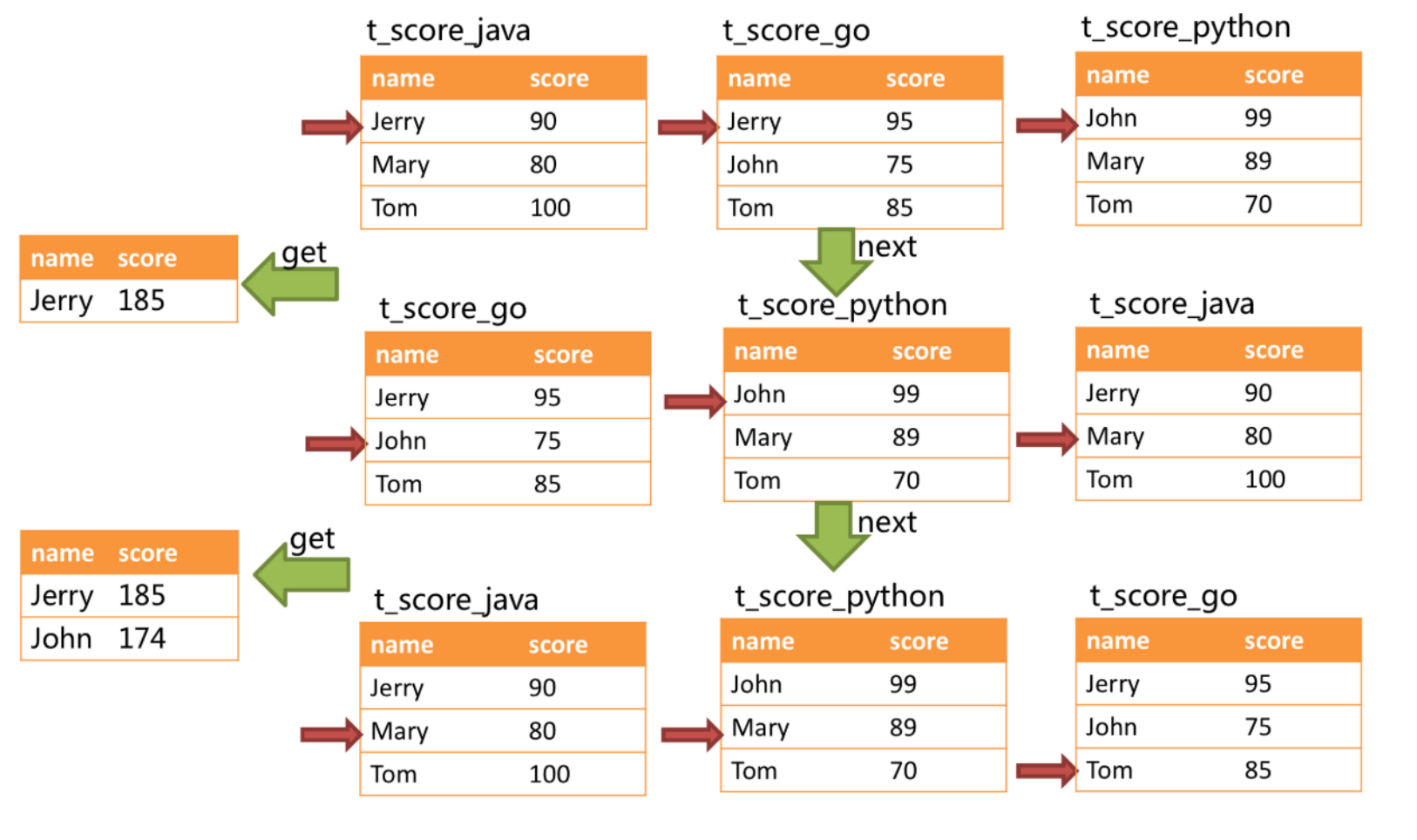
From the figure, we can see that when the next call is made for the first time, t is at the top of the queue_ score_ Java will be popped out of the queue, and the grouping value will be popped out of the queue together with the data in other result sets with "Jetty". After obtaining the scores of all students named "Jetty", carry out the accumulation operation. Then, after the first next call, the result set taken out is the sum of the scores of "Jetty". At the same time, all cursors in the data result set will move down to the next different data value of the data value "Jetty", and reorder according to the value pointed to by the current cursor in the data result set. Therefore, the relevant data result set containing "John" with the second name is at the top of the queue.
9.5.6 complete code
DAO
package com.itheima.shopping.dao;
import com.itheima.shopping.entity.ProductDescript;
import com.itheima.shopping.entity.ProductInfo;
import org.apache.ibatis.annotations.*;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
/**
* Created by Administrator.
*/
@Mapper
@Component
public interface ProductDao {
//Add basic information of goods
@Insert("insert into product_info(store_info_id,product_name,spec,region_code,price) " +
" values (#{storeInfoId},#{productName},#{spec},#{regionCode},#{price})")
@Options(useGeneratedKeys = true, keyProperty = "productInfoId", keyColumn = "product_info_id")
int insertProductInfo(ProductInfo productInfo);
//Add item description information
@Insert("insert into product_descript(product_info_id,descript,store_info_id) " +
" value(#{productInfoId},#{descript},#{storeInfoId})")
@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")
int insertProductDescript(ProductDescript productDescript);
@Select("select i.*,d.descript,r.region_name placeOfOrigin from product_info i join product_descript d on i.product_info_id = d.product_info_id " +
" join region r on i.region_code = r.region_code order by product_info_id desc limit #{start},#{pageSize}")
List<ProductInfo> selectProductList(@Param("start") int start, @Param("pageSize") int pageSize);
//Total number of goods
@Select("select count(1) from product_info")
int selectCount();
//Commodity grouping statistics
@Select("select t.region_code,count(1) as num from product_info t group by t.region_code having num > 1 order by region_code ")
List<Map> selectProductGroupList();
}
Entity:
package com.itheima.shopping.entity;
import lombok.Data;
/**
* Product description
*/
@Data
public class ProductDescript {
private Long id;
/**
* Commodity id
*/
private Long productInfoId;
/**
* Product description
*/
private String descript;
/**
* Store id
*/
private Long storeInfoId;
}
package com.itheima.shopping.entity;
import lombok.Data;
import java.math.BigDecimal;
/**
* Basic information of goods
*/
@Data
public class ProductInfo {
private Long productInfoId;
/**
* Store id
*/
private Long storeInfoId;
/**
* Trade name
*/
private String productName;
/**
* Specifications
*/
private String spec;
/**
* Place of Origin
*/
private String regionCode;
/**
* commodity price
*/
private BigDecimal price;
/**
* Product picture
*/
private String imageUrl;
Related information/
/**
* Product description
*/
private String descript;
/**
* name of origin
*/
private String placeOfOrigin;
/**
* Shop name
*/
private String storeName;
/**
* Store reputation level
*/
private int reputation;
/**
* Store location name
*/
private String storeRegionName;
}
package com.itheima.shopping.entity;
import lombok.Data;
/**
* Geographic area information
*/
@Data
public class region {
private Long id;
/**
* Geographical area coding
*/
private String regionCode;
/**
* Geographical area name
*/
private String regionName;
/**
* Geographical region level (province, city and county)
*/
private int level;
/**
* Superior geographic area code
*/
private String parentRegionCode;
}
package com.itheima.shopping.entity;
import lombok.Data;
/**
* Store information
*/
@Data
public class StoreInfo {
private Long id;
/**
* Shop name
*/
private String storeName;
/**
* Credit rating
*/
private int reputation;
/**
* Store location
*/
private String regionCode;
/**
* Store location name
*/
private String regionName;
}
service
package com.itheima.shopping.service;
import com.itheima.shopping.entity.ProductInfo;
import java.util.List;
/**
* Created by Administrator.
*/
public interface ProductService {
//Add item
public void createProduct(ProductInfo product);
//Query goods
public List<ProductInfo> queryProduct(int page, int pageSize);
}
package com.itheima.shopping.service.impl;
import com.itheima.shopping.dao.ProductDao;
import com.itheima.shopping.entity.ProductDescript;
import com.itheima.shopping.entity.ProductInfo;
import com.itheima.shopping.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
/**
* @author Administrator
* @version 1.0
**/
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
ProductDao productDao;
//Add item
@Override
@Transactional
public void createProduct(ProductInfo productInfo) {
ProductDescript productDescript = new ProductDescript();
//Set item description information
productDescript.setDescript(productInfo.getDescript());
//Call dao to send goods information table
productDao.insertProductInfo(productInfo);
//Set the product information id to productdescription
productDescript.setProductInfoId(productInfo.getProductInfoId());
//Set store id
productDescript.setStoreInfoId(productInfo.getStoreInfoId());
//Insert data into the item description information table
productDao.insertProductDescript(productDescript);
}
@Override
public List<ProductInfo> queryProduct(int page, int pageSize) {
int start = (page - 1) * pageSize;
return productDao.selectProductList(start, pageSize);
}
}
Test class
package com.itheima.shopping;
import com.itheima.shopping.dao.ProductDao;
import com.itheima.shopping.entity.ProductInfo;
import com.itheima.shopping.service.ProductService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
/**
* @author Administrator
* @version 1.0
**/
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ShoppingBootstrap.class)
public class ShardingTest {
@Autowired
ProductService productService;
@Autowired
ProductDao productDao;
//Add item
@Test
public void testCreateProduct() {
for (int i = 1; i < 10; i++) {
ProductInfo productInfo = new ProductInfo();
productInfo.setStoreInfoId(1L);//Store id
productInfo.setProductName("Java" + i);//Trade name
productInfo.setSpec("big");
productInfo.setPrice(new BigDecimal(60));
productInfo.setRegionCode("110100");
productInfo.setDescript("Java good" + i);//Product description
productService.createProduct(productInfo);
}
}
//Query goods
@Test
public void testQueryProduct() {
List<ProductInfo> productInfos = productService.queryProduct(2, 2);
System.out.println(productInfos);
}
//Total number of statistical commodities
@Test
public void testSelectCount() {
int i = productDao.selectCount();
System.out.println(i);
}
//Group statistical products
@Test
public void testSelectProductGroupList() {
List<Map> maps = productDao.selectProductGroupList();
System.out.println(maps);
}
}
application.properties
server.port=56082
spring.application.name = shopping
spring.profiles.active = local
server.servlet.context-path = /shopping
spring.http.encoding.enabled = true
spring.http.encoding.charset = UTF-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
#Sharding JDBC sharding rules
#Configure data sources m0,m1,m2,s0,s1,s2
spring.shardingsphere.datasource.names = m0,m1,m2,s0,s1,s2
spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/store_db?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = 123456
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/product_db_1?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 123456
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/product_db_2?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 123456
spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url = jdbc:mysql://localhost:3307/store_db?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = 123456
spring.shardingsphere.datasource.s1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s1.url = jdbc:mysql://localhost:3307/product_db_1?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.s1.username = root
spring.shardingsphere.datasource.s1.password = 123456
spring.shardingsphere.datasource.s2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s2.url = jdbc:mysql://localhost:3307/product_db_2?useUnicode=true&useSSL=false
spring.shardingsphere.datasource.s2.username = root
spring.shardingsphere.datasource.s2.password = 123456
#Master-slave relationship
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=s0
spring.shardingsphere.sharding.master-slave-rules.ds1.master-data-source-name=m1
spring.shardingsphere.sharding.master-slave-rules.ds1.slave-data-source-names=s1
spring.shardingsphere.sharding.master-slave-rules.ds2.master-data-source-name=m2
spring.shardingsphere.sharding.master-slave-rules.ds2.slave-data-source-names=s2
#Warehouse distribution strategy (horizontal)_ info_ ID stores are divided horizontally
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = store_info_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{store_info_id % 2 + 1}
#Table splitting strategy
# store_info sub table strategy
spring.shardingsphere.sharding.tables.store_info.actual-data-nodes = ds$->{0}.store_info
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.tables.store_info.table-strategy.inline.algorithm-expression = store_info
# product_info sub table strategy
#Data nodes include, DS1 product_ info_ 1,ds1.product_info_2,ds2.product_info_1,ds2. product_ info_ two
spring.shardingsphere.sharding.tables.product_info.actual-data-nodes = ds$->{1..2}.product_info_$->{1..2}
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_info.table-strategy.inline.algorithm-expression = product_info_$->{product_info_id%2+1}
spring.shardingsphere.sharding.tables.product_info.key-generator.column=product_info_id
spring.shardingsphere.sharding.tables.product_info.key-generator.type=SNOWFLAKE
#product_ Describe sub table strategy
spring.shardingsphere.sharding.tables.product_descript.actual-data-nodes = ds$->{1..2}.product_descript_$->{1..2}
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.sharding-column = product_info_id
spring.shardingsphere.sharding.tables.product_descript.table-strategy.inline.algorithm-expression = product_descript_$->{product_info_id % 2 + 1}
spring.shardingsphere.sharding.tables.product_descript.key-generator.column=id
spring.shardingsphere.sharding.tables.product_descript.key-generator.type=SNOWFLAKE
# Set product_ info,product_ Describe is the binding table
spring.shardingsphere.sharding.binding-tables[0] = product_info,product_descript
# Set region as broadcast table (public table), and each update operation will be sent to all data sources
spring.shardingsphere.sharding.broadcast-tables=region
# Open sql output log
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.com.itheima.dbsharding = debug
10 summary
Why divide the database into tables?
-
Database and table splitting is to solve the problem of database performance degradation due to excessive amount of data. The original independent database is divided into several databases, and the large data table is divided into several data tables, so as to reduce the amount of data in a single database and single data table, so as to improve the performance of the database.
-
Warehouse and table splitting methods: vertical table splitting, vertical table splitting, horizontal table splitting and horizontal table splitting
-
Problems caused by database and table separation: because the data is scattered in multiple databases, the server leads to transaction consistency problems, cross node join problems, cross node paging, sorting and functions. The primary key needs to be globally unique and public tables.
-
Basic concepts of sharding JDBC: logical table, real table, data node, binding table, broadcast table, sharding key, sharding algorithm, sharding strategy, and primary key generation strategy
-
Sharding JDBC core functions: data fragmentation, read-write separation
-
Sharding JDBC execution process: SQL parsing = > query optimization = > sql routing = > sql rewriting = > sql execution = > result merging
-
Best practice: the system should consider the coupling tightness of business data at the beginning of design, so as to divide the database and table vertically, so as to make the data layer architecture clear. If it is not necessary, there is no need for horizontal segmentation. We should start with caching technology to reduce the access pressure to the database. If the database access volume is still very large after the cache is used, the principle of separating database read and write can be considered. If the current database pressure is still high and the continuous growth of business data is incalculable, finally, horizontal database and table splitting can be considered, and the split data of single table can be controlled within 10 million.